1、采集网址url:https://data.wenzhou.gov.cn/jdop_front/index.do
需求:获取数据资源-数据来源单位(龙湾区50)的信息
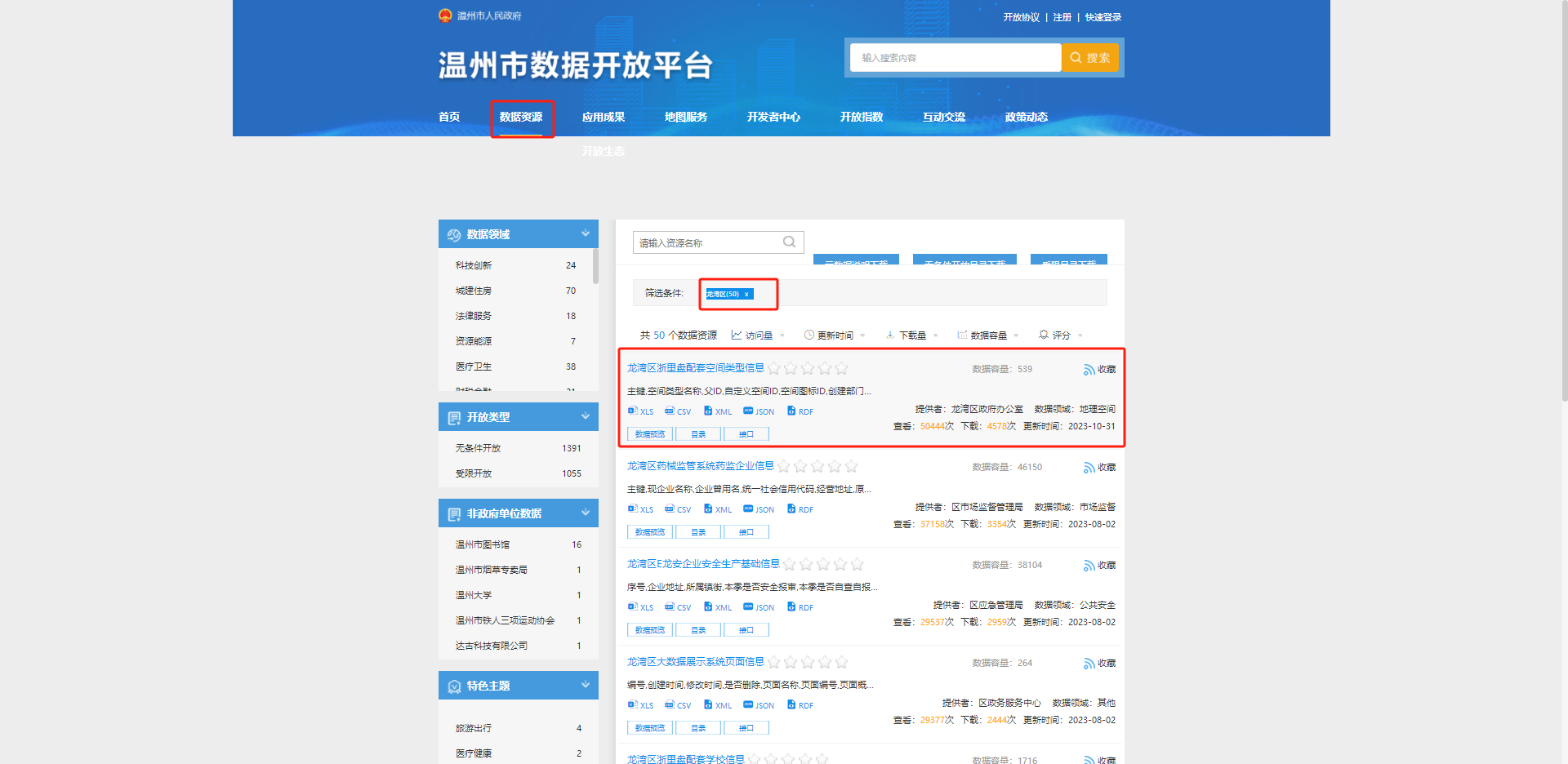
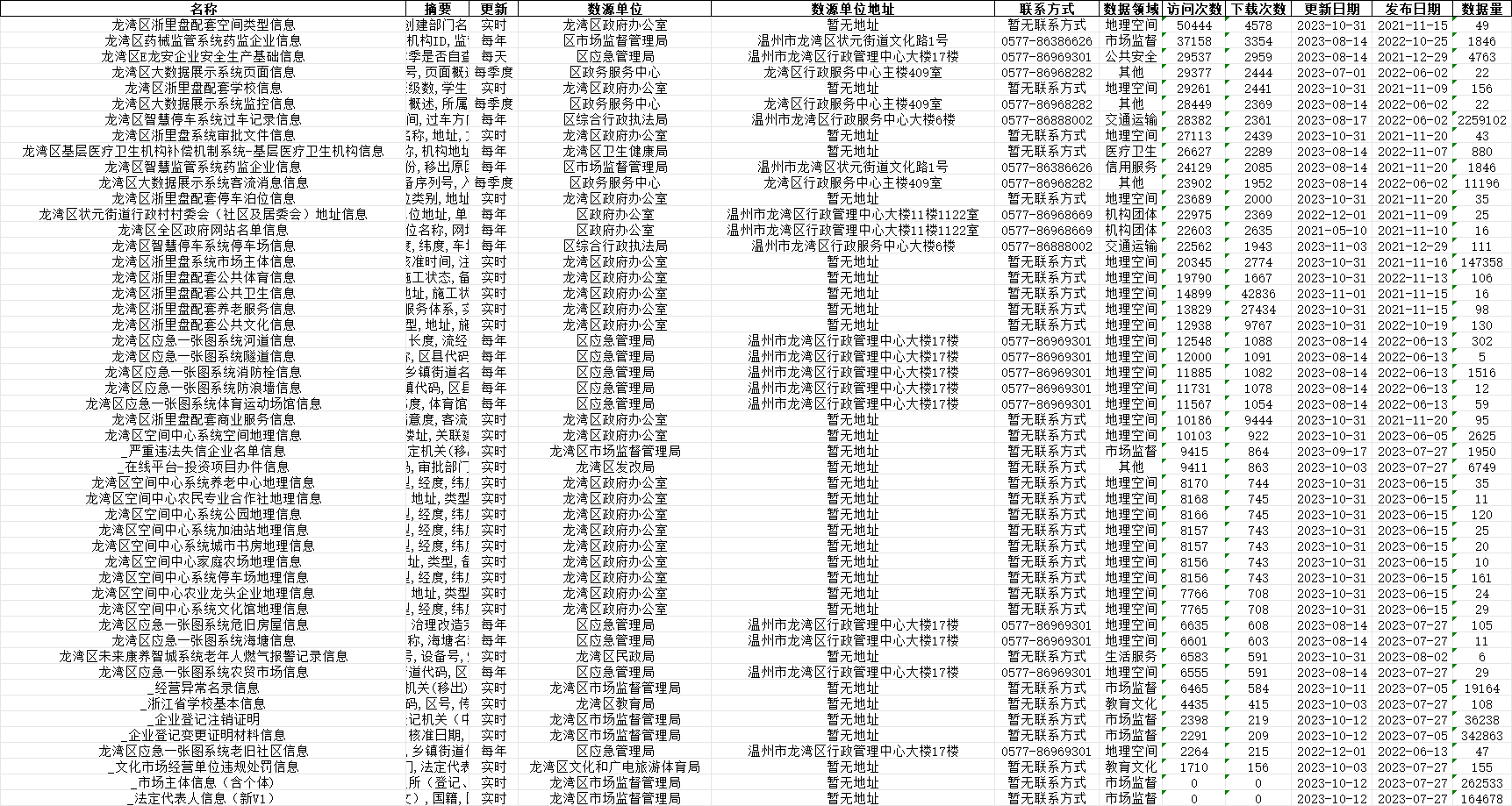
具体要获取的信息如下:名称、摘要、更新、数源单位、地址、联系方式、数据领域、访问次数、下载次数、更新日期、发布日期、数据量。
2、浏览器审查页面返回的数据进行分析,通过点击翻页,从页面返回中获取信息。
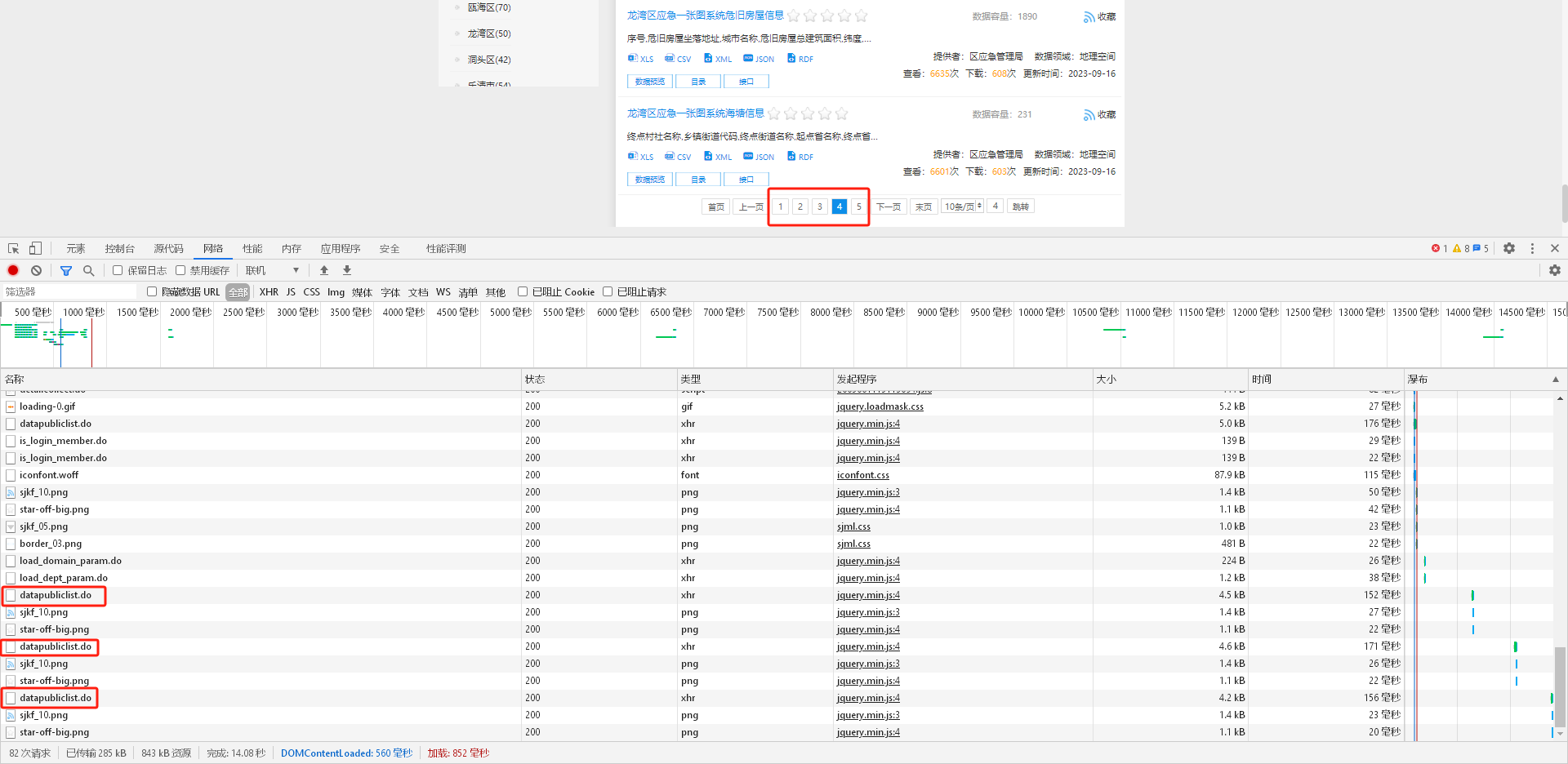
点击连接获取相关信息:
完整代码如下:
# -*- coding: utf-8 -*- # 温州市公共数据开发平台数据资源模块-温州市龙湾区-数源单位信息爬取 import requests from lxml import etree import json import jsonpath import re import pandas as pd url="https://data.wenzhou.gov.cn/jdop_front/channal/datapubliclist.do" #请求头信息 header={ "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Connection": "keep-alive", "Cookie": "JSESSIONID=B1912F728FE269FA5F80A952567EFD98; ZJZWFWSESSIONID=45a118fc-f9db-4a61-a0e9-e76ca877de6b; arialoadData=false", "Host": "data.wenzhou.gov.cn", "Origin": "https://data.wenzhou.gov.cn", "Referer": "https://data.wenzhou.gov.cn/jdop_front/channal/data_public.do", "Sec-Fetch-Dest": "empty", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Site": "same-origin", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36", "X-Requested-With": "XMLHttpRequest" } #post请求需要发送的url参数 params = { "pageNumber": 1, "pageSize": 100, "type": "", "domainId": 0, "deptId": "", "regionId": "0303", "keyword": "", "content": "", "searchString": "", "orderDefault": "", "isDownload": "1", "dimensionId": "0", "openState": "" } datas=requests.post(url,headers=header,params=params).text# 创建一个空表存储数据 datas_list = [] for iid in datas_herf: datas_url=(f"https://data.wenzhou.gov.cn/jdop_front/detail/data.do?iid={iid}&searchString=") response = requests.get(datas_url).text # print(response) #数据目录 datas_directory=re.findall(r' <span class="sjxqTit1">(.*?)</span>',response,re.S)[0] #摘要 datas_summary=re.findall(r'<td colspan="3">(.*?)</td>',response,re.S)[0] #更新周期 datas_update_period=re.findall(r'<td>更新周期:</td>.*?<td>(.*?)</td>',response,re.S)[0] #数源单位 datas_unit=re.findall(r'<td>数源单位:</td>.*?<td>(.*?)</td>',response,re.S)[0] #数源单位地址 datas_unit_address=re.findall(r'<td>数源单位地址:</td>.*?<td>(.*?)</td>',response,re.S)[0] #联系方式 datas_telephone=re.findall(r'<td>联系方式:</td>.*?<td>(.*?)</td>',response,re.S)[0] #数据领域 datas_field=re.findall(r'<td>数据领域:</td>.*?<td>(.*?)</td>',response,re.S)[0] #查看次数 datas_view=re.findall(r'<td>访问/下载次数:</td>.*?<td>(.*?)/.*?</td>',response,re.S)[0] #下载次数 datas_download=re.findall(r'<td>访问/下载次数:</td>.*?<td>.*?/(.*?)</td>',response,re.S)[0] #更新时间 datas_update=re.findall(r'<td>更新日期:</td>.*?<td>(.*?)</td>',response,re.S)[0] #发布日期 datas_releasedate=re.findall(r'<td>发布日期:</td>.*?<td>(.*?)</td>',response,re.S)[0] #数据容量 datas_capacity=re.findall(r'<td>数据量:</td>.*?<td>(.*?)</td>',response,re.S)[0] # 创建一个Pandas DataFrame来存储数据 data_dict = { '名称': [datas_directory], '摘要': [datas_summary], '更新': [datas_update_period], '数源单位': [datas_unit], '数源单位地址': [datas_unit_address], '联系方式': [datas_telephone], '数据领域': [datas_field], '访问次数': [datas_view], '下载次数': [datas_download], '更新日期': [datas_update], '发布日期': [datas_releasedate], '数据量': [datas_capacity] } df = pd.DataFrame(data_dict) datas_list.append(df) # 合并所有数据DataFrame final_df = pd.concat(datas_list, ignore_index=True) # 保存到Excel文件 final_df.to_excel('公共数据平台数据源信息.xlsx', index=False) print('执行完毕')