一、什么是jupyter
介绍:
jupyter notebook是一种 Web 应用,能让用户将说明文本、数学方程、代码和可视化内容全部组合到一个易于共享的文档中。它可以直接在代码旁写出叙述性文档,而不是另外编写单独的文档。也就是它可以能将代码、文档等这一切集中到一处,让用户一目了然。
Jupyter这个名字是它要服务的三种语言的缩写:Julia,PYThon和R,这个名字与“木星(jupiter)”谐音。Jupyter Notebook 已迅速成为数据分析,机器学习的必备工具。因为它可以让数据分析师集中精力向用户解释整个分析过程。我们可以通过Jupyter notebook写出了我们的学习笔记。但是jupyter远远不止支持上面的三种语言,目前能够使用的语言他基本上都能支持,包括C、C++、C#,java、Go等等。
jupyter notebook和我们前面所讲的两篇系列文章ipython其实都是来自同一个产品族,它的前身叫做ipython notebook,至于后面为什么更名这不得而知,这也就是为什么很多文章总是默认将ipython就说成是ipython notebook的原因了。但是既然已经更名了,我们还是区别对待ipython和jupyter notebook。
二、jupyter的作用
jupyter到底有一些什么功能呢?
在介绍 Jupyter Notebook 的功能之前,让我们先来看一个概念:文学编程 ( Literate programming ),这是由 Donald Knuth 提出的编程方法。传统的结构化编程,人们需要按计算机的逻辑顺序来编写代码;与此相反,文学编程则可以让人们按照自己的思维逻辑来开发程序。
简单来说,文学编程的读者不是机器,而是人。 我们从写出让机器读懂的代码,过渡到向人们解说如何让机器实现我们的想法,其中除了代码,更多的是叙述性的文字、图表等内容。这么一看,这不正是数据分析人员所需要的编码风格么?不仅要当好一个程序员,还得当好一个作家。那么 Jupyter Notebook 就是不可或缺的一款集编程和写作于一体的效率工具。
以下列举了 Jupyter Notebook 的众多优点:
(1)极其适合数据分析,想象一下如下混乱的场景:你在终端中运行程序,可视化结果却显示在另一个窗口中,包含函数和类的脚本存在其他文档中,更可恶的是你还需另外写一份说明文档来解释程序如何执行以及结果如何。此时 Jupyter Notebook 从天而降,将所有内容收归一处,你是不是顿觉灵台清明,思路更加清晰了呢?
(2)支持多语言,也许你习惯使用 R 语言来做数据分析,或者是想用学术界常用的 MATLAB 和 Mathematica,这些都不成问题,只要安装相对应的核(kernel)即可。这里列出了 Jupyter 支持的所有语言,供您参考。
分享便捷,支持以网页的形式分享,GitHub 中天然支持 Notebook 展示,也可以通过 nbviewer 分享你的文档。当然也支持导出成 HTML、Markdown 、PDF 等多种格式的文档。
(3)远程运行,在任何地点都可以通过网络链接远程服务器来实现运算
(4)交互式展现,不仅可以输出图片、视频、数学公式,甚至可以呈现一些互动的可视化内容,比如可以缩放的地图或者是可以旋转的三维模型。这就需要交互式插件(Interactive widgets)来支持。
三、jupyter notebook的简单使用
1.cmd命令
jupyter notebook常用的子命令——subcommand
list :列出当前的所打开的jupyter notebook的一些信息
stop:关闭所给定的端口号的那一个jupyter
password :给某一个打开的jupyter notebook 服务设置密码,后面直接输入所要添加的密码即可。
jupyter notebook --help-all 查看jupyter命令的详细信息:
--generate-config 产生默认的配置文件()这个是重点,后面会讲到)
--no-browser 启动jupyter notebook之后不打开浏览器(默认情况下是会打开一个浏览器界面的)
--pylab 同前面讲解ipython的时候很类似,在jupyter notebook里面集成,也可以在jupyter notebook里面使用
%pylab 或者是%matplotlib魔术命令(这是最常用的,后面也会讲到)
--config=<Unicode> 制定一个完全路径的配置文件名称,关于配置文件后面会详解,默认是default,即系统指定的默认配置文件
--ip=<Unicode> 默认是: 'localhost',从前面的现实中也可以看出来,表示的是notebook服务器会监听的IP地址,我们也可以手动指定
--port=<Int> 指定jupyter notebook打开浏览器的端口号,默认是: 8888,也可以手动输入
--notebook-dir=<Unicode> 默认使用默认的目录,表示的是notebook和kernels的目录
--browser=<Unicode> 还可以指定某一个特定的浏览器打开,默认使用系统默认的浏览器打开,是可以自己选定浏览器的。
2.打开jupyter 浏览器界面

仔细观察就会发现,这里面现实的一些文件夹就是电脑用户目录下面的文件夹,这是为什么呢?那是因为jupyter notebook在启动的时候总是有一个默认的目录,一般情况下,使用户的目录。
3.修改默认目录
不一定每个人都需要的是默认目录,想要修改默认目录该怎么做呢?
a.查看配置文件,在cmd中使用如下命令:jupyter-notebook --generate-config
b.有的有两个井号开头 ##,这才是注释文本,而那些以一个井号#开头的实际上就是默认的配置信息,也就是我们要修改的
四、jupyter运行环境的配置——一python运行环境为例
jupyter notebook本质上是一个web应用程序,我们可以在上面书写代码,但是代码本身的运行环境是需要自己安装的,没有运行环境,即使是在jupyter notebook里面书写的代码怡然没有办法运行。因为代码本身,web应用程序是不认识的。
幸运的是,在使用anaconda安装的时候,会默认将安装jupyter,而且会安装一个Python的运行环境,所以打开jupyter的时候,可以直接看见这个运行环境,在jupyter里面称之为内核kernel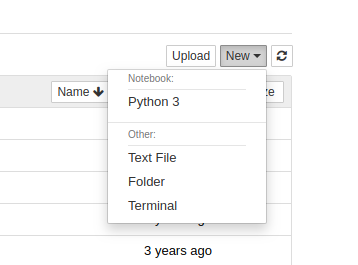
第一个python3 ,表示的就是默认的python3 kernel,它是随着anaconda一起安装的;
Text File ,表示的是新建一个文本文件
Folder ,表示的是新建一个文件夹
Terminal ,表示的是在浏览器中新建一个用户终端,即类似于cmd的shell。
但是,这是远远不够的,因为我不可能所有的程序都是使用这一个python kernel,使用过TensorFlow的人都知道如何创建一个新的运行环境,打包TensorFlow所依赖的各种包。本文以python为例,我还有另外两个环境,一个是TensorFlow,一个是pytorch,还有一个是,mxnet。他们都是使用conda创建的python运行环境。其实就一句话:
conda create -n tensorflow python=3.6
conda创建运行环境的方法这里就不详细说明了,可以参阅相关文章。注意:因为anaconda的服务器在国外,上面的执行速度实在是太慢,甚至等了半天,然后连接失败,所以,我们可以使用清华大学的镜像进行下载,在使用上面执行命令之前,添加一句:conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
再使用:conda create -n tensorflow python=3.6
这会快非常多!!!
注意:
TUNA 还提供了 Anaconda 仓库的镜像,运行以下命令:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
即可添加 Anaconda Python 免费仓库。
直接粘贴复制以上代码即可。另外,要一行一行运行,并且每一行运行完没有任何结果,直接运行下一行即可。
三行代码运行完,可以运行 conda install numpy 测试一下吧。
1、原始的方法解决多个Python运行环境问题
就是走在每一个python的运行环境里面都使用conda install notebook 安装一个与之对应的notebook,然后我在做开发的时候,需要用什么环境,我就在每一个Python环境中的script文件夹下面打开对应的哪个jupyter notebook,这当然没问题。但这样做不是很高级,我需要安装很多次,而且每次在使用jupyter notebook的时候都只能使用一个环境,局限性很大。
2、更高级的办法
现在,比如我已经在anaconda里面创建了一个名为tensorflow的环境,但是,怎么把它添加到jupyter里面呢?
(1)方法一:
首先在anaconda prompt里面激活我们需要的环境,然后执行下面一个命令:
(base) C:\Users\lenovo>activate python27
(python27) C:\Users\lenovo>python -m ipykernel install --name python27
Installed kernelspec python27 in C:\ProgramData\jupyter\kernels\python27
和
(base) C:\Users\lenovo>activate tensorflow
(tensorflow) C:\Users\lenovo>python -m ipykernel install --name tensorflow
Installed kernelspec tensorflow in C:\ProgramData\jupyter\kernels\tensorflow
总结:两步走,
第一步:激活相应的环境
第二步:执行命令 python -m ipykernel install --name 环境名称
补充:也有人用下面的方法:
先激活某一个Python环境:然后再执行下面两个语句:
conda install -n 环境名称 ipykernel
python -m ipykernel install --user
注意:上面这种方式都是可以的,但问题是还是需要针对每一个环境安装一次ipykernel,而且有时候不知怎么回事,总是会遇见一些乱七八糟的错误,我还没搞清楚是为什么,如果谁知道,望告知。
(2) 方法二——一步到位的方法
在我创建完我需要的运行环境之后,然后只需要在base运行环境中执行一个命令即可。
(base) C:\Users\lenovo>conda install nb_conda
将会将所有的kernel全部添加进去,这种方法是最快的,而且最不容易出错,推荐使用。
(3)补充方法——综合前面两者
1.一步到位:
(base) C:\Users\lenovo>conda install nb_conda
(base) C:\Users\lenovo>conda install nb_conda_kernels
两种方法均可以
2.分步完成:
第一步:激活某一个环境activate mxnet
第二步:在环境中安装ipykernel:pip install ipykernel
第三步:再执行命令:
python -m ipykernel install --user --name mxnet --display-name mymxnet
后面的蓝色部分可以省略。第一个mxnet指的是我激活的那一个环境名,这里是mxnet;第二个mymxnet是我要在jupyter里面显示的内核名称,是自己自定义的,我定义为mymxnet。
感谢CSDN博主。
转载自CSDN链接:https://blog.csdn.net/qq_27825451/article/details/84427269