本文使用《使用ResponseSelector实现校园招聘FAQ机器人》中的例子,主要详解介绍train_nlu()函数中变量的具体值。
一.rasa/model_training.py/train_nlu()函数
train_nlu()函数实现,如下所示:
def train_nlu(
config: Text,
nlu_data: Optional[Text],
output: Text,
fixed_model_name: Optional[Text] = None,
persist_nlu_training_data: bool = False,
additional_arguments: Optional[Dict] = None,
domain: Optional[Union[Domain, Text]] = None,
model_to_finetune: Optional[Text] = None,
finetuning_epoch_fraction: float = 1.0,
) -> Optional[Text]:
"""Trains an NLU model. # 训练一个NLU模型。
Args:
config: Path to the config file for NLU. # NLU的配置文件路径。
nlu_data: Path to the NLU training data. # NLU训练数据的路径。
output: Output path. # 输出路径。
fixed_model_name: Name of the model to be stored. # 要存储的模型的名称。
persist_nlu_training_data: `True` if the NLU training data should be persisted with the model. # 如果NLU训练数据应该与模型一起持久化,则为`True`。
additional_arguments: Additional training parameters which will be passed to the `train` method of each component. # 将传递给每个组件的`train`方法的其他训练参数。
domain: Path to the optional domain file/Domain object. # 可选domain文件/domain对象的路径。
model_to_finetune: Optional path to a model which should be finetuned or a directory in case the latest trained model should be used. # 可选路径,指向应该进行微调的模型,或者在应该使用最新训练的模型的情况下指向一个目录。
finetuning_epoch_fraction: The fraction currently specified training epochs in the model configuration which should be used for finetuning. # 模型配置中当前指定的训练时期的fraction,应该用于微调。
Returns:
Path to the model archive. # 模型归档的路径。
"""
if not nlu_data: # 没有NLU数据
rasa.shared.utils.cli.print_error( # 打印错误
"No NLU data given. Please provide NLU data in order to train " # 没有给出NLU数据。请提供NLU数据以训练
"a Rasa NLU model using the '--nlu' argument." # 使用--nlu参数训练Rasa NLU模型
)
return None
# 只训练NLU,因此仍然必须选择训练文件
file_importer = TrainingDataImporter.load_nlu_importer_from_config(
config, domain, training_data_paths=[nlu_data], args=additional_arguments
)
training_data = file_importer.get_nlu_data() # 获取NLU数据
if training_data.contains_no_pure_nlu_data(): # 如果没有纯NLU数据
rasa.shared.utils.cli.print_error( # 打印错误
f"Path '{nlu_data}' doesn't contain valid NLU data in it. " # 路径{nlu_data}中不包含有效的NLU数据
f"Please verify the data format. " # 请验证数据格式
f"The NLU model training will be skipped now." # 现在将跳过NLU模型训练
)
return None
return _train_graph( # 训练图
file_importer, # 文件导入器
training_type=TrainingType.NLU, # 训练类型
output_path=output, # 输出路径
model_to_finetune=model_to_finetune, # 模型微调
fixed_model_name=fixed_model_name, # 固定模型名称
finetuning_epoch_fraction=finetuning_epoch_fraction, # 微调时期fraction
persist_nlu_training_data=persist_nlu_training_data, # 持久化NLU训练数据
**(additional_arguments or {}), # 额外的参数
).model # 模型
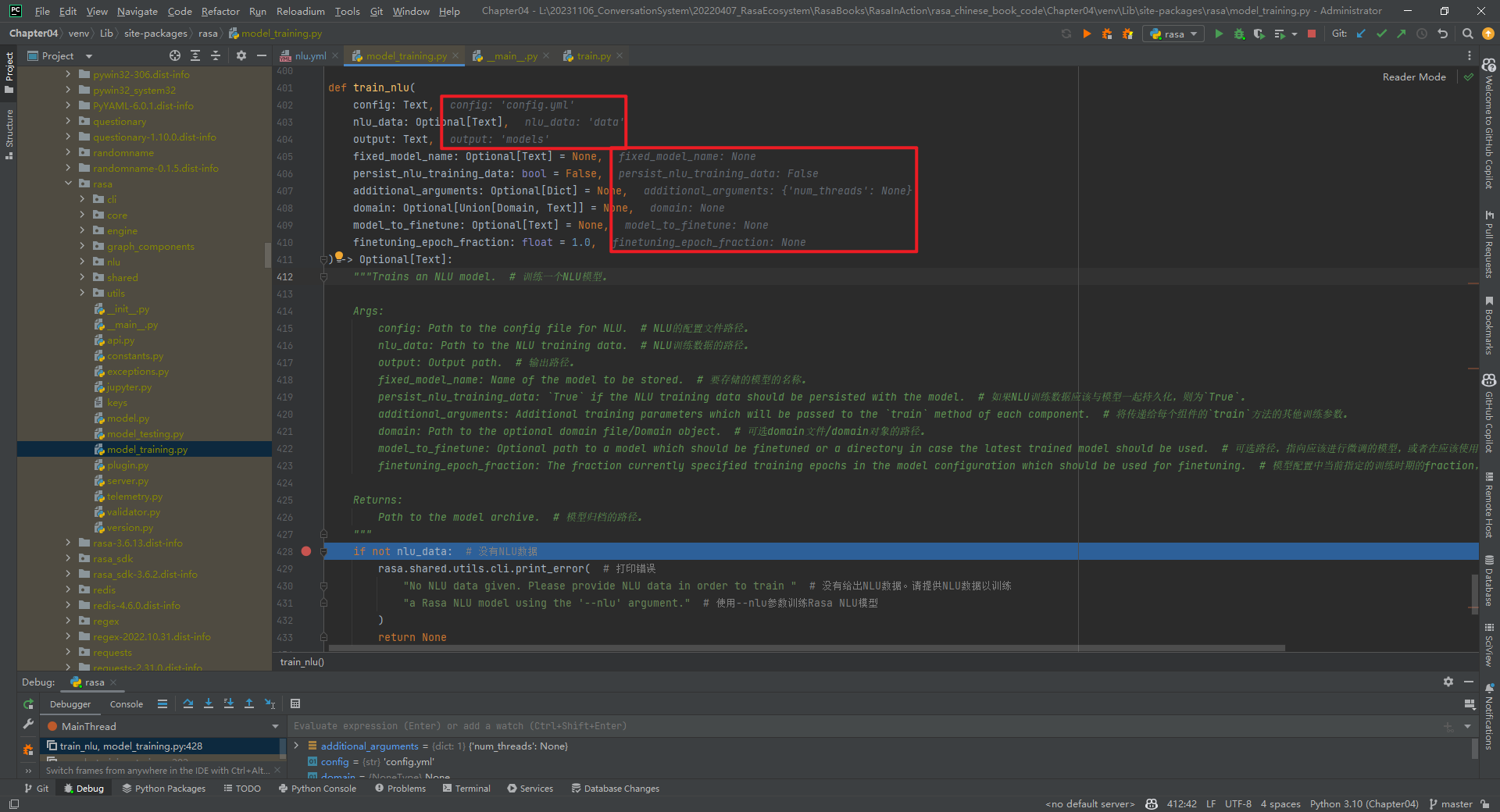
1.传递来的形参数据
形参config="config.yml",nlu_data="data",output="models",persist_nlu_training_data=False,其它的都是None,如下所示:
2.train_nlu()函数组成
该函数主要由3个方法组成,如下所示:
- file_importer = TrainingDataImporter.load_nlu_importer_from_config(*) #file_importer数据类型为NluDataImporter
- training_data = file_importer.get_nlu_data() #根据nlu数据创建一个TrainingData类对象
- return _train_graph(*) #训练config.yml文件中pipline对应的图
二.training_data数据类型
training_data数据类型为rasa.shared.nlu.training_data.training_data.TrainingData,如下所示:
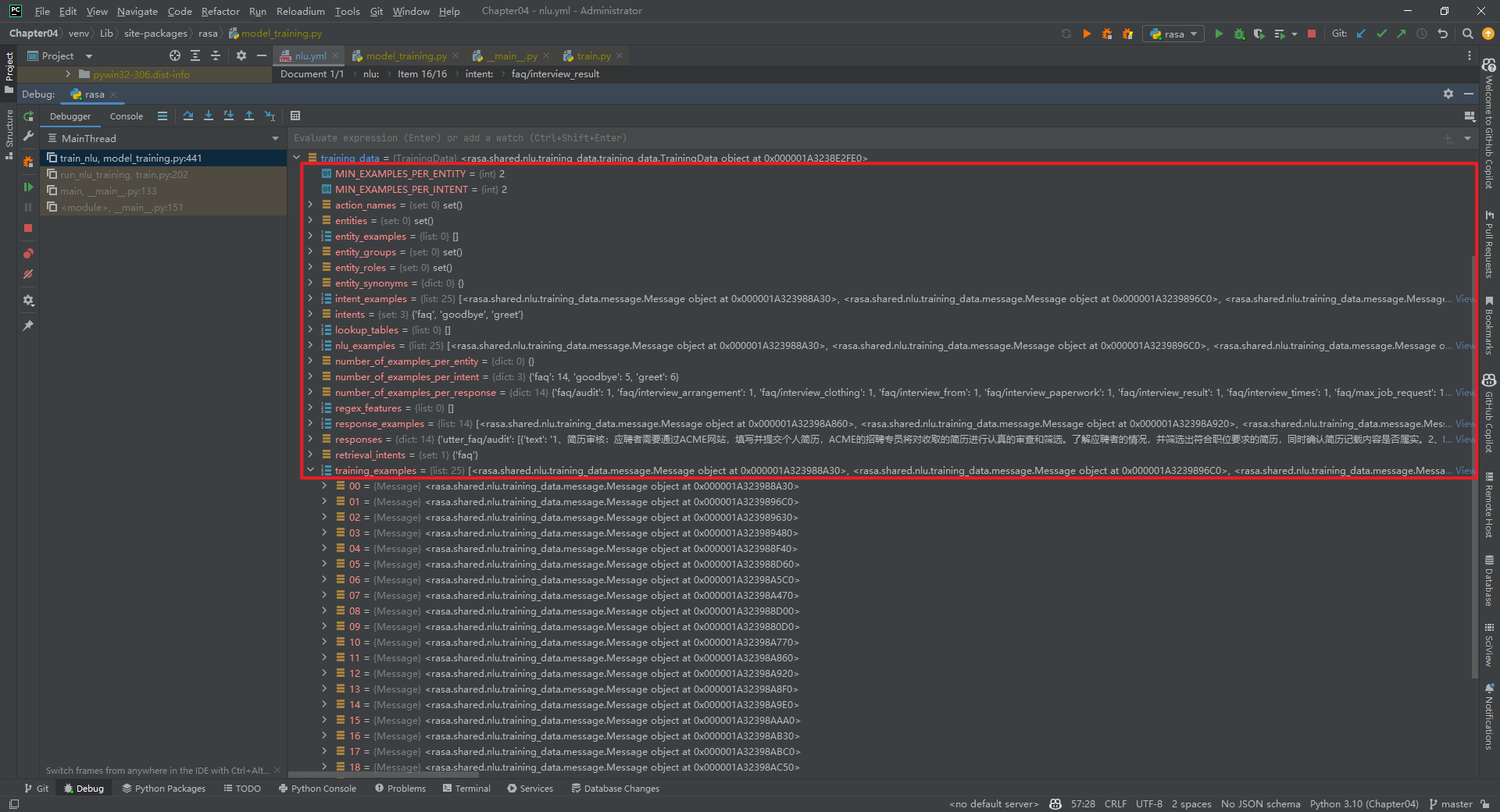
1.MIN_EXAMPLES_PER_ENTITY=2
每个实体的最小样本数量。
2.MIN_EXAMPLES_PER_INTENT=2
每个意图的最小样本数量。
3.action_names=set()
action名字集合。
4.entities=set()
entity集合。
5.entity_examples=[]
entity例子集合。
6.entity_groups=set()
entity组的集合。
7.entity_roles=set()
entity角色集合。
8.entity_synonyms=set()
entity近义词集合。
9.intent_examples=[25*Message]
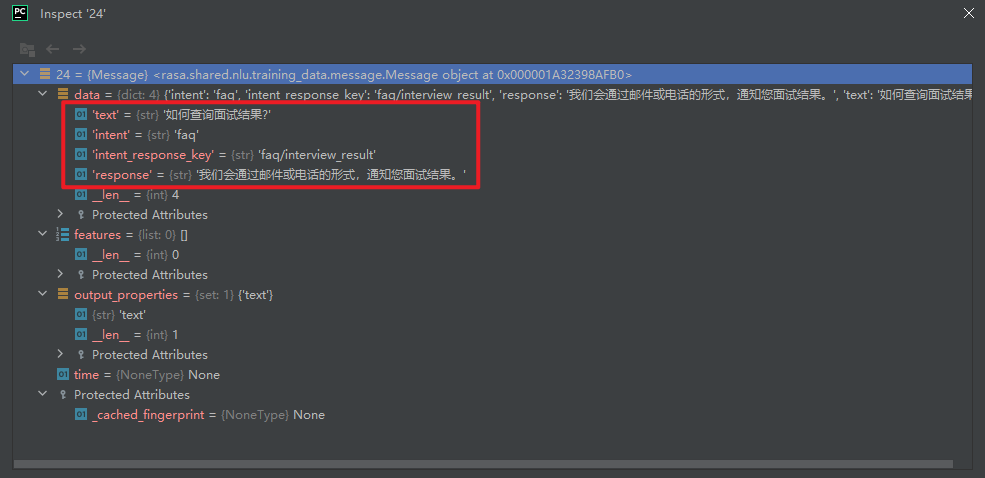
intent例子列表,列表中数据为rasa.shared.nlu.training_data.message.Message数据结构。对于普通意图,Message数据结构如下所示:

对于检索意图,Message数据结构如下所示:
10.intents
具体数值为set('faq', 'goodbye', 'greet')。
11.lookup_tables=[]
查找表。
12.nlu_examples=[25*Message]
内容和intent_examples相同,不再介绍。
13.number_of_examples_per_entity
每个entity例子的数量。
14.number_of_examples_per_intent
每个intent例子的数量,即{'faq': 14, 'goodbye': 5, 'greet': 6}。
15.number_of_examples_per_response
每个response例子的数量,如下所示:
{'faq/notes': 1, 'faq/work_location': 1, 'faq/max_job_request': 1, 'faq/audit': 1, 'faq/write_exam_participate': 1, 'faq/write_exam_location': 1, 'faq/write_exam_again': 1, 'faq/write_exam_with-out-offer': 1, 'faq/interview_arrangement': 1, 'faq/interview_times': 1, 'faq/interview_from': 1, 'faq/interview_clothing': 1, 'faq/interview_paperwork': 1, 'faq/interview_result': 1}
16.regex_features=[]
正则特征。
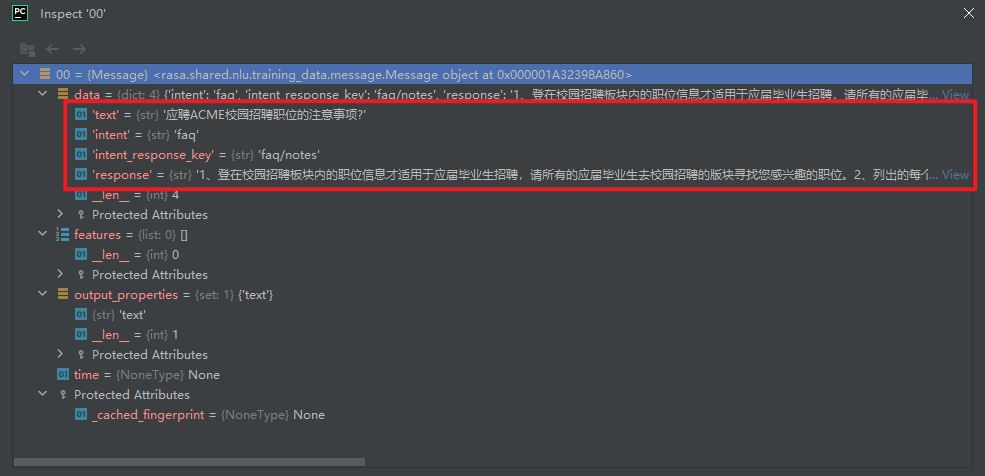
17.response_examples=[14*Message]
response例子,如下所示:
18.responses
response例子,如下所示:

19.retrieval_intents=set('faq')
检索意图。
20.training_examples=[25*Message]
内容和intent_examples相同,不再介绍。
参考文献:
[1]https://github.com/RasaHQ/rasa
[2]rasa 3.2.10 NLU模块的训练:https://zhuanlan.zhihu.com/p/574935615