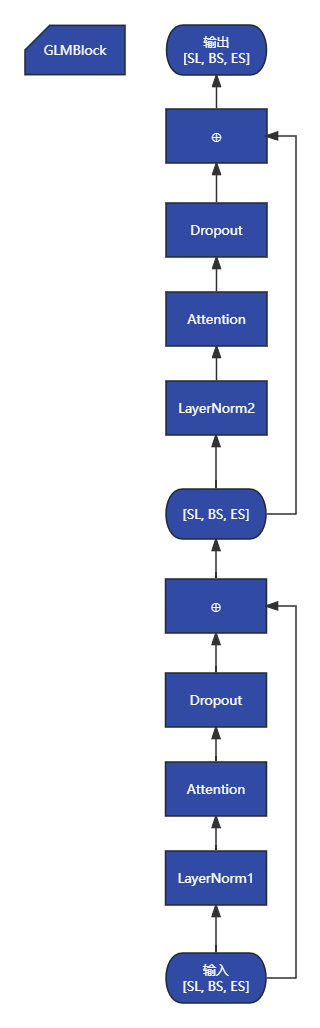
# GLM 块包括注意力层、FFN层和之间的残差
class GLMBlock(torch.nn.Module):
"""A single transformer layer.
Transformer layer takes input with size [s, b, h] and returns an
output of the same size.
"""
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
super(GLMBlock, self).__init__()
self.layer_number = layer_number
self.apply_residual_connection_post_layernorm = config.apply_residual_connection_post_layernorm
self.fp32_residual_connection = config.fp32_residual_connection
# 判断使用 RMS 还是 LN
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
# LN1
self.input_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
# 注意力层
self.self_attention = SelfAttention(config, layer_number, device=device)
# Dropout
self.hidden_dropout = config.hidden_dropout
# LLN2
self.post_attention_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
# FFN
self.mlp = MLP(config, device=device)
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True,
):
# hidden_states: [s, b, h]
# 输入 -> LN1 -> 注意力层 -> ...
layernorm_output = self.input_layernorm(hidden_states)
attention_output, kv_cache = self.self_attention(
layernorm_output,
attention_mask,
rotary_pos_emb,
kv_cache=kv_cache,
use_cache=use_cache
)
# 判断残差是否在LN1后面
# 如果为真,那么:
# 输入 -> LN1 -> 注意力 -> Dropout -> ⊕ -> ...
# | ↑
# +----------------------------------+
# 否则:
# 输入 -> LN1 -> 注意力 -> Dropout -> ⊕ -> ...
# | ↑
# +--------------------------+
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = hidden_states
layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
layernorm_input = residual + layernorm_input
# ... -> LN2 -> FFN -> ...
layernorm_output = self.post_attention_layernorm(layernorm_input)
mlp_output = self.mlp(layernorm_output)
# 判断残差是否在LN1后面
# 如果为真,那么:
# ... -> LN2 -> FFN -> Dropout -> ⊕ -> 输出
# | ↑
# +-------------------------------+
# 否则:
# ... -> LN2 -> FFN -> Dropout -> ⊕ -> 输出
# | ↑
# +------------------------+
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = layernorm_input
output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
output = residual + output
return output, kv_cache