1)进入http://yuyin.baidu.com/app,在弹出的界面中单击要针对哪个应用开通语音识别服务,个人测试可全选
(开通个人认证,白嫖)
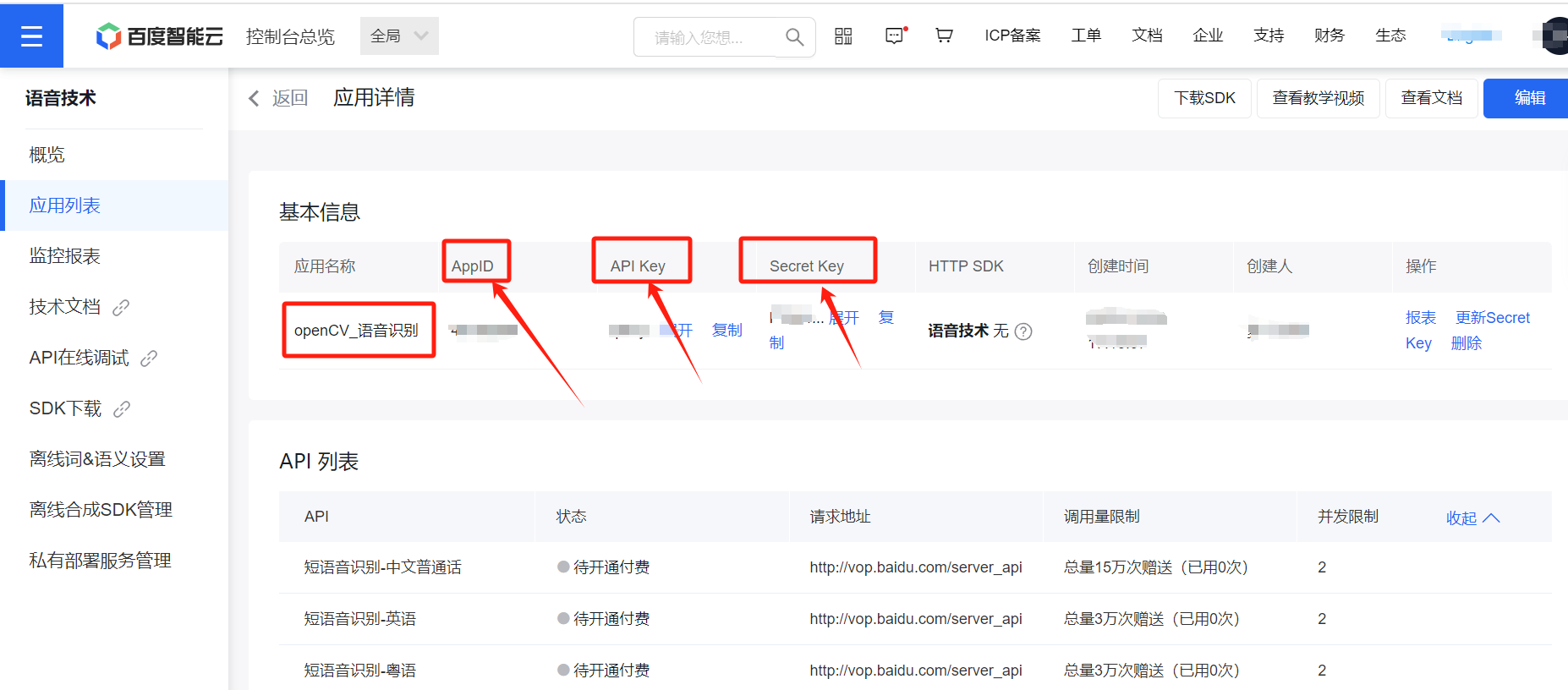
注意:
1、百度语音识别API对于要识别的音频源是有要求的:原始PCM的录音参数必须符合8k/16k采样率、16位深、单声道,支持的压缩格式有:pcm(不压缩)、wav、opus、amr、x-flac。
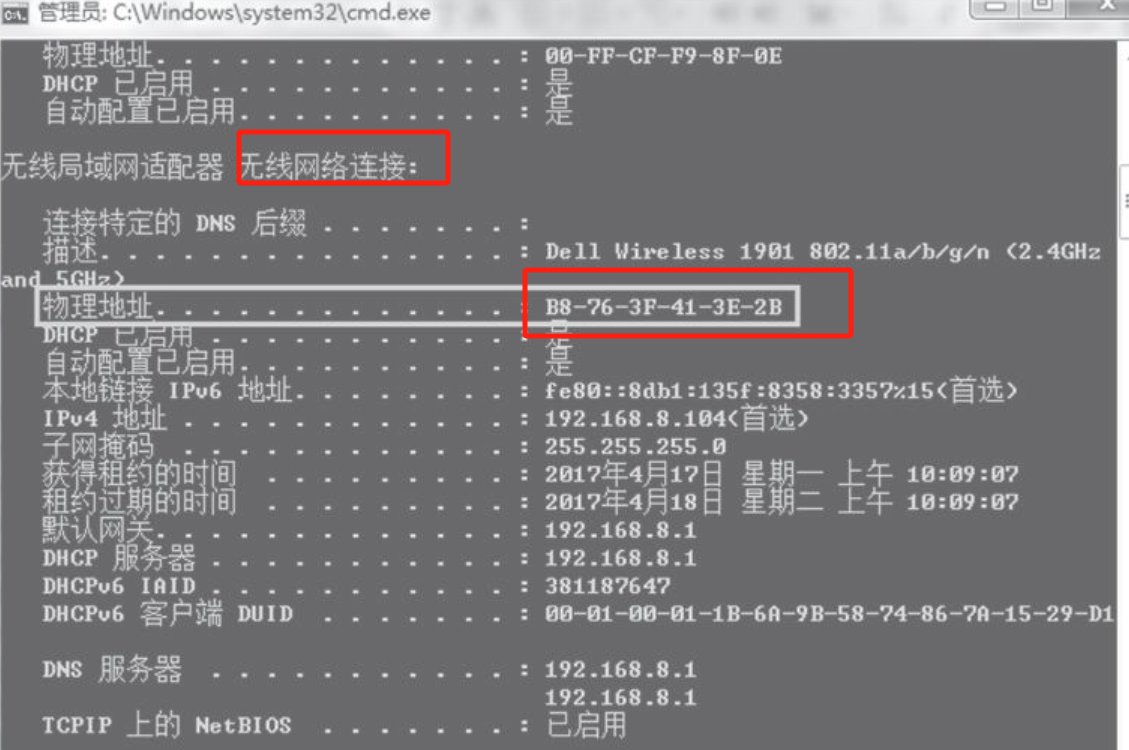
2、在本地计算机上测试的,因此使用的是MAC地址。获取MAC地址的方法是:打开系统终端命令行窗口(Win+R,输入cmd并按Enter键),在命令行中输入命令ipconfig/all
3、关闭防火墙,网络限时
参考代码如下:
1 # -*- coding: utf-8 -*- 2 import json # 用来转换JSON字符串 3 import base64 # 用来做语音文件的Base64编码 4 import requests # 用来发送服务器请求 5 6 # 获得token 7 API_Key = '********' # 从申请应用的key信息中获得 8 Secret_Key = '********' # 从申请应用的key信息中获得 9 token_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s" 10 # 获得token的地址 11 res = requests.get(token_url % (API_Key, Secret_Key)) # 发送请求 12 res_text = res.text # 获得请求中的文字信息 13 token = json.loads(res_text)['access_token'] # 提取token信息 14 15 # 定义要发送的语音 16 voice_file = 'D:\Users\m07013a\Downloads\05. Ancient of Wind.wav' # 要识别的语音文件 17 voice_fn = open(voice_file, 'rb') # 以二进制的方式打开文件 18 org_voice_data = voice_fn.read() # 读取文件内容 19 org_voice_len = len(org_voice_data) # 获得文件长度 20 base64_voice_data = base64.b64encode(org_voice_data).decode('utf-8') 21 # 将语音内容转换为base64编码格式 22 # 发送信息 23 # 定义要发送的数据主体信息 24 headers = {'content-type': 'application/json'} # 定义header信息 25 payload = { 26 'format': 'pcm', # 以具体要识别的语音扩展名为准 27 'rate': 8000, # 支持8000或16000两种采样率 28 'channel': 1, # 固定值,单声道 29 'token': token, # 上述获取的token 30 'cuid': '90-65-84-C1-70-32', # 本机的MAC地址或设备唯一识别标志,要修改 31 'len': org_voice_len, # 上述获取的原始文件内容长度 32 'speech': base64_voice_data # 转码后的语音数据 33 } 34 data = json.dumps(payload) # 将数据转换为JSON格式 35 vop_url = 'http://vop.baidu.com/server_api' # 语音识别的API 36 voice_res = requests.post(vop_url, data=data, headers=headers) # 发送语音识别请求 37 api_data = voice_res.text # 获得语音识别文字返回结果 38 text_data = json.loads(api_data)['result'] 39 print(api_data) # 打印输出整体返回结果 40 print(text_data) # 打印输出语音识别的文件
返回结果如下:

总结:上述语音识别仅提供了关于语音转文字的方法。其实语音本身包括非常多的信息,除了相对浅层的生理和物理特征,例如语速、音调、音长、音色、音强等外,还包括更深层次的社会属性,这部分内容需要自然语音理解的深层次应用。目前的语音数据读取后主要应用方向包括:
·语音转文字。这也是广义上语音识别的一种,直接将语音信息转为文字信息,例如微信中就有这个小功能。
·语音识别。语音识别指的是对说话者通过选取语音识别单元、提取语音特征参数、模型训练、模型匹配等阶段,实现其角色识别和个体识别的过程,例如通过某段语音识别出是哪个人说的话。
·语音语义理解。在语音识别的基础上,需要对语义特征进行分析,目的是通过计算得到语音对应的潜在知识或意图,然后提供对应的响应内容或方法。语音识别和语音理解的差异之处在于,语音识别重在确定语音表达的字面含义,属于表层意义;而语音理解重在挖掘语音的背后含义,属于深层意义。
·语音合成。语音合成就是让计算机能够“开口说话”,这是一种拟人的技术方法。语音合成,又称文本转语音(Text to Speech)技术,它通过机械的、电子的方法将文字信息转变为人类可以听得懂的语音。
·应用集成。经过分析、识别后的信息可以与硬件集成,直接通过语音发送指令。例如通过跟Siri(苹果手机上的语音助理)的“沟通”,除了可以进行日常对话,还可以告诉你天气情况、帮你设置系统日程、介绍餐厅等。这是智能机器人在模式识别方面的典型应用。
基于上述的复杂应用场景,通常语音后续分析、处理和建模等过程都无法由数据工程师单独完成,还需要大量的语料库素材,以及社会学、信号工程、语言语法、语音学、自然语音处理、机器学习、知识搜索、知识处理等交叉学科和相关领域才有可能解开其中的密码。