13.Linux中fork函数详解(附图解与代码实现)
我们先来看个代码,判断一下这个代码的输出结果会是什么样的,先不要去看运行结果,判断好后再去看看是否和你的预期结果一致。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main(void)
{
pid_t pid;
pid = fork();
printf("xxxxxxxxxx\n");
while (1)
{
sleep(1);
}
return 0;
}
输出:
运行结果:
xxxxxxxxxx
xxxxxxxxxx
是不是和你预想的结果不太一样呢?为什么会是输出两遍呢?这是什么原理呢?
抱着这样的问题,让我们来研究一下fork函数的奥秘吧。
fork函数
功能:创建一个与原来进程几乎完全相同的进程
这也就代表着,父进程可通过调用该函数创建一个子进程,两个进程可以做完全相同的事
返回值:pid_t类型的变量,也就是进程id类型的变量
这里有个非常让人惊讶的地方,fork函数的返回值是2个!!!
想想自己学了那么久的编程,好像没有返回值是两个的函数啊。别慌,接着往下看
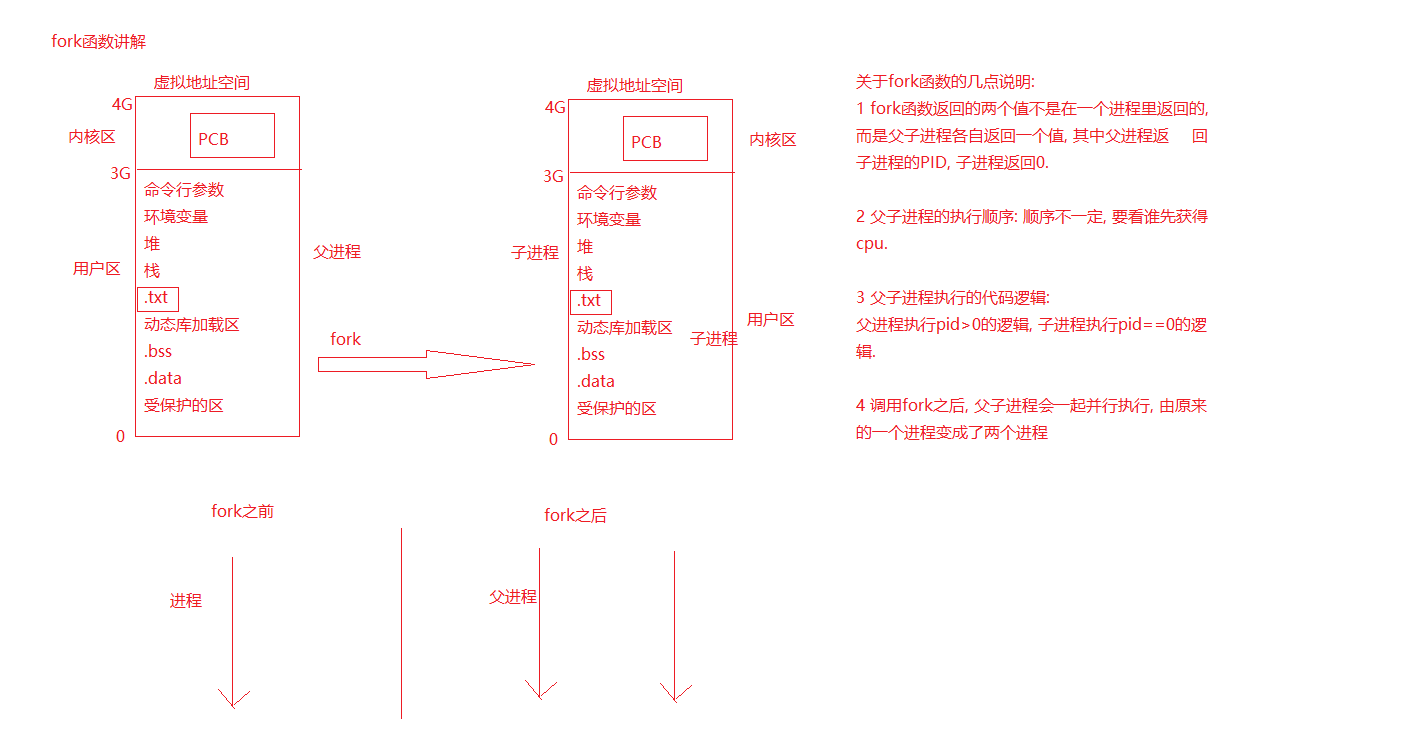
我们来对父进程通过fork函数创建子进程的过程做个具体的说明,上图!
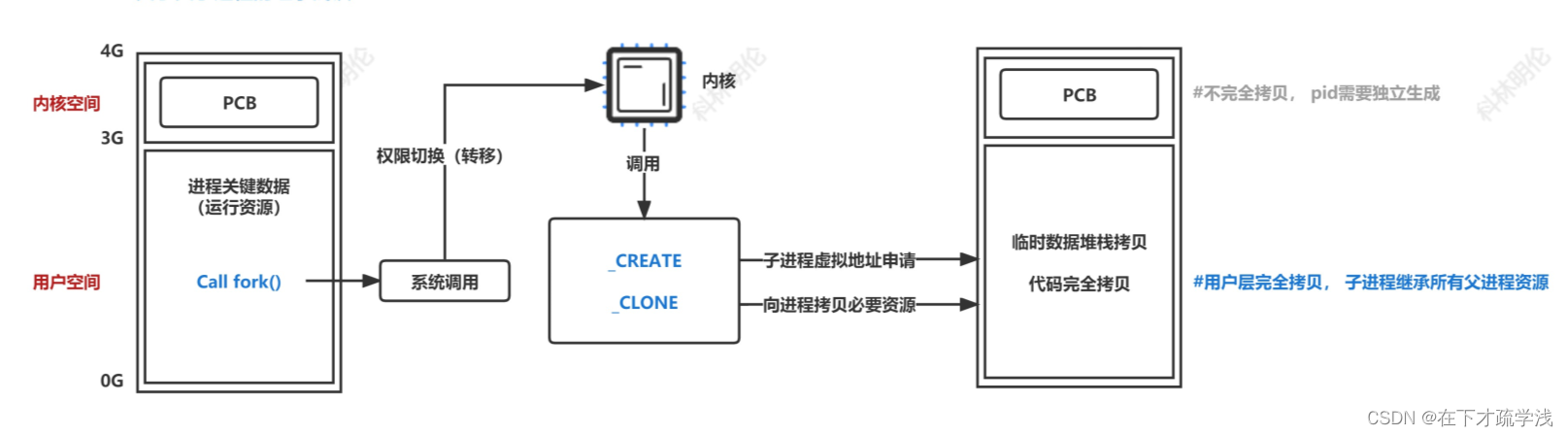
在上述这个图中,当调用fork函数时,操作系统会从用户态切换回内核态来进行进程的创建,会调用fork函数中的_CREATE函数和_CLONE函数。
首先调用_CREATE函数,子进程进行虚拟地址申请,在子进程的内核空间中进行不完全拷贝,为什么是不完全拷贝呢?就像父亲和儿子的关系一样,你可以和你爸爸的民族,籍贯所在地一样,但你不能和你爸的年龄,身份证号都一样吧。PCB作为每个进程的唯一标识符,就像每个人的身份证一样,是不可能完全一样的,所以这个地方时不完全拷贝,如pid就需要自己生成。这个地方的子进程是新生态。
之后调用_CLONE函数,向父进程拷贝必要资源,子进程的用户空间进行完全拷贝,子进程继承所有父进程资源,如临时数据堆栈拷贝,代码完全拷贝。
这个时候就有善于思考的同学会发现,并提出以下问题:
诶诶诶,你这父进程创建一个子进程,你这子进程把你的代码完全拷贝走了。
-
那子进程不是把fork函数也拷贝走了吗?
-
那子进程不也可以通过fork函数创建孙线程了吗?
-
那你这不是子又生孙,孙又生子吗?
-
那你这不无限创造进程了吗?
-
那为什么上面的代码的运行结果只有两个输出?
-
考虑的非常好啊,这也是我们下面要讲的问题
讲解完父进程如何通过fork函数创建子进程,接下来我们就要讲解父子进程如何执行fork函数
上图!
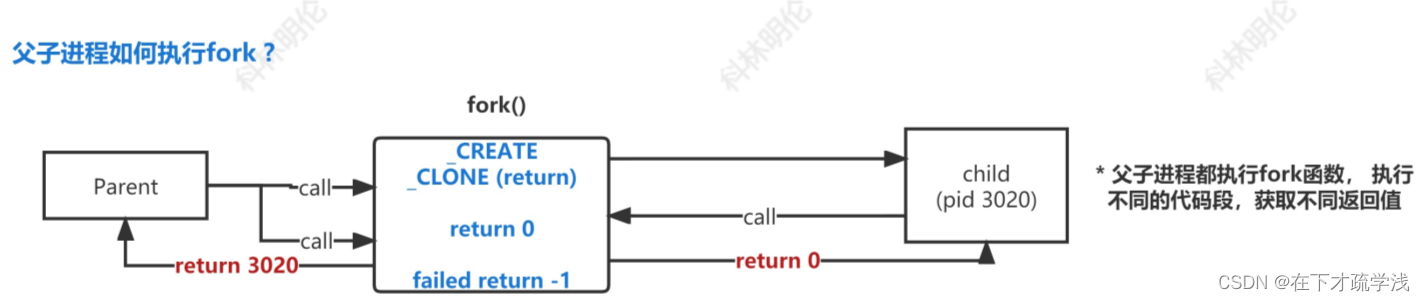
其实大体来说,我们可以将fork函数分为三步
1.调用_CREATE函数,也就是进程创建部分
2.调用_CLONE函数,也就是资源拷贝部分
3.进程创建成功,return 0; 失败,return -1:
前2步也就是父进程通过fork函数创建子进程的步骤,在执行完_CLONE函数后,fork函数会有第一次返回,子进程的pid会返回给父进程。要注意的是,在第3步中,fork函数不是由父进程来执行,而是由子进程来执行,当父进程执行完_CLONE函数后,子进程会执行fork函数的剩余部分,执行最后这个语句,fork函数就会有第二次返回,如果成功就返回0,失败就返回-1。
我们就可以总结得出,父子进程都执行fork函数,但执行不同的代码段,获取不同的返回值。所以fork函数的返回值情况如下:
父进程调用fork,返回子线程pid(>0)
子进程调用fork,子进程返回0,调用失败的话就返回-1
这也就说明了fork函数的返回值是2个
可以通过下面的代码来验证该过程
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main(void)
{
//Parent Start
pid_t pid;
pid = fork();
if (pid > 0)
{
printf("parent running\n");
while (1)
{
sleep(1);
}
}
else if (pid == 0)
{
//Child Start
printf("Child Running\n");
while (1)
{
sleep(1);
}
//Child End
}
else
{
perror("fork call failed\n");
}
while (1)
{
sleep(1);
}
return 0;
}
//Parent End
输出:
运行结果:
parent running
Child Running
该程序首先包含了四个头文件,这些头文件提供了程序中使用的各种函数和功能。关键函数是fork(),它来自于unistd.h,用于在UNIX和Linux系统上创建新进程。
接下来,我们逐步解析程序的运行流程:
- 主进程开始:当程序开始执行时,它是在一个称为“主进程”或“父进程”中运行的。
- 创建子进程:程序使用
fork()函数创建一个新进程,这个新进程称为“子进程”。这个子进程是父进程的副本,继承了父进程的数据和代码。 - 父进程执行:如果
fork()调用成功,对于父进程,fork()返回子进程的进程ID,它肯定是一个大于0的值。于是,程序进入if (pid > 0)分支,打印parent running,然后进入一个无限循环,在该循环中,每秒都会休眠一次。 - 子进程执行:对于子进程,
fork()返回0。所以,程序进入else if (pid == 0)分支,打印Child Running,然后进入其自己的无限循环,并每秒休眠一次。 - fork失败:如果
fork()调用失败,它返回-1。在这种情况下,程序进入else分支,并使用perror打印一个错误消息。 - 程序结束:无论
fork()的结果如何,程序都会进入最后的while循环,并开始另一个无限循环。但实际上,由于之前的逻辑(父进程、子进程、或fork失败的错误处理),这个循环是不可达的,也就是说,程序永远不会执行到这里。
总结:
- 父进程会打印
parent running并进入一个无限循环。 - 子进程会打印
Child Running并进入一个无限循环。 - 如果
fork失败,程序会打印一个错误消息。
如果你运行这个程序,你会发现父进程和子进程都在无限循环中运行,且都可以在进程列表中看到(例如,使用ps命令在UNIX/Linux系统上)。
为什么 最后的while (1)不会运行?
在上述代码中,fork()调用后,根据其返回值,程序流会进入其对应的条件分支:父进程、子进程或fork失败。
-
父进程:对于父进程,
fork()返回子进程的PID(一个大于0的值),所以程序会进入if (pid > 0)分支,并在那里遇到一个无限循环(while(1))。由于这是一个无限循环,程序将永远停留在这里,不会退出该循环。 -
子进程:对于子进程,
fork()返回0。因此,程序会进入else if (pid == 0)分支,同样地,它也会在这里遇到一个无限循环。子进程将永远停留在这个循环中。 -
fork失败:如果
fork()失败,它返回-1。程序将进入else分支,并打印一个错误消息。然后,它会到达函数的末尾并退出,而不会执行最后的while(1)循环。
因此,不论程序执行路径如何,它都会在最后的while(1)循环之前进入一个其他的无限循环或者完全结束运行,这就是为什么最后的while(1)循环不会被执行的原因。
另外和大家说一个小知识点
整个Linux操作系统都是由父子进程结构构成
每个进程都有创建者,也就是父进程,但是有一个进程例外,也就是init进程
init进程(0 or 1),init进程是系统启动初始化后的第一个进程
例子:
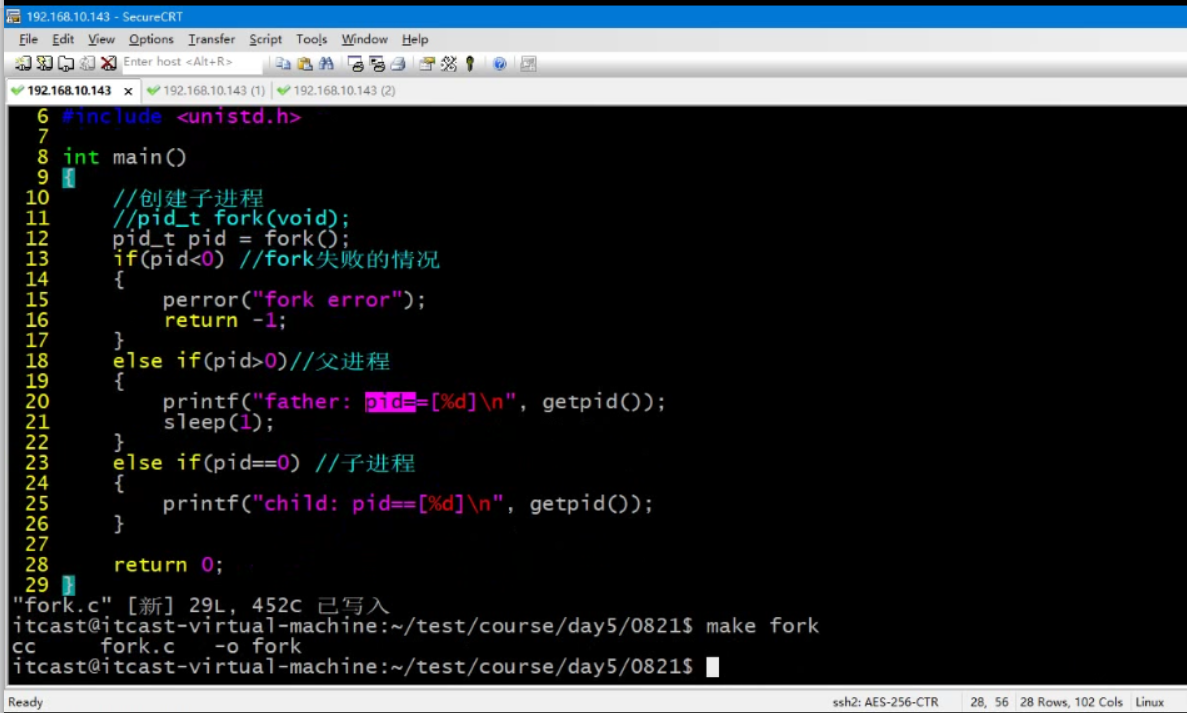

先创建的PID小,后创建的大。
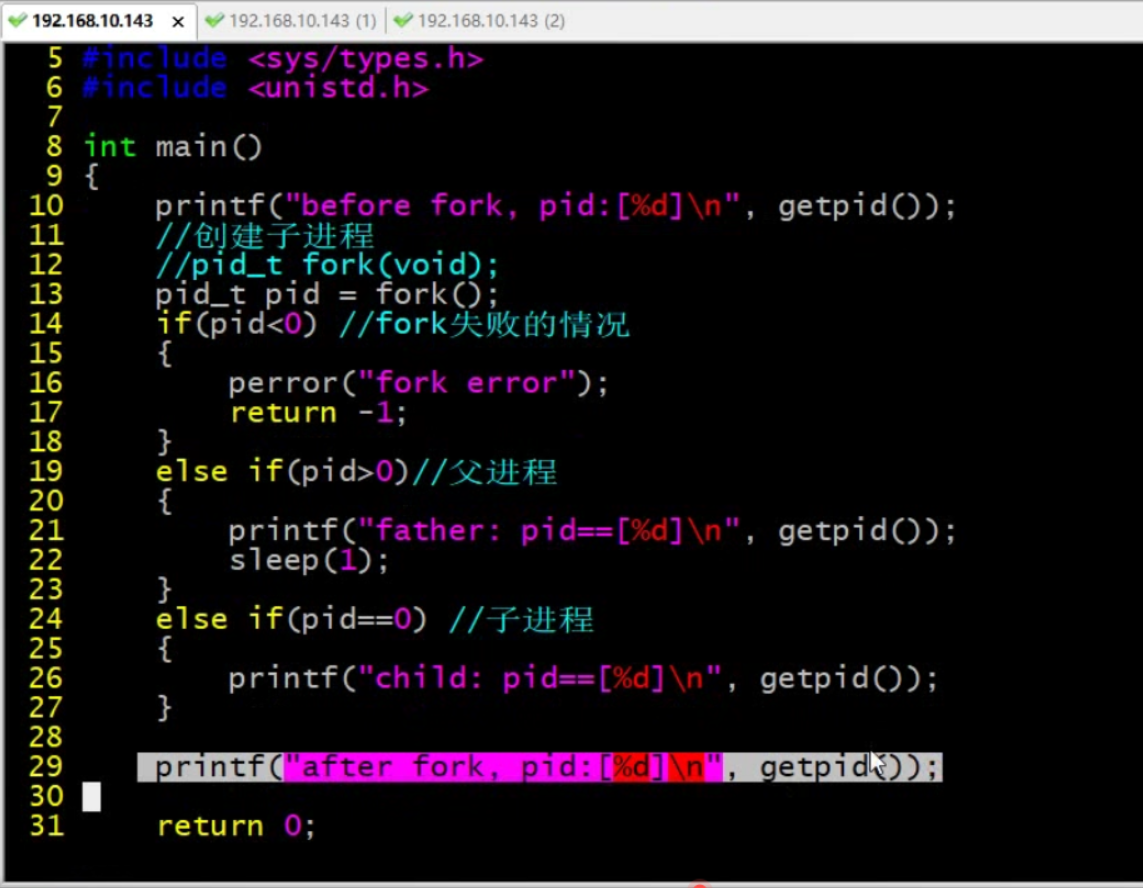
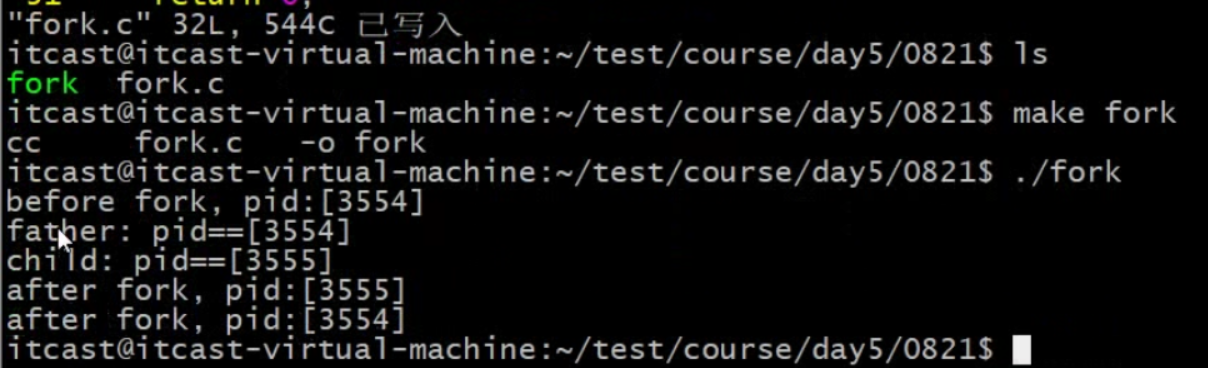
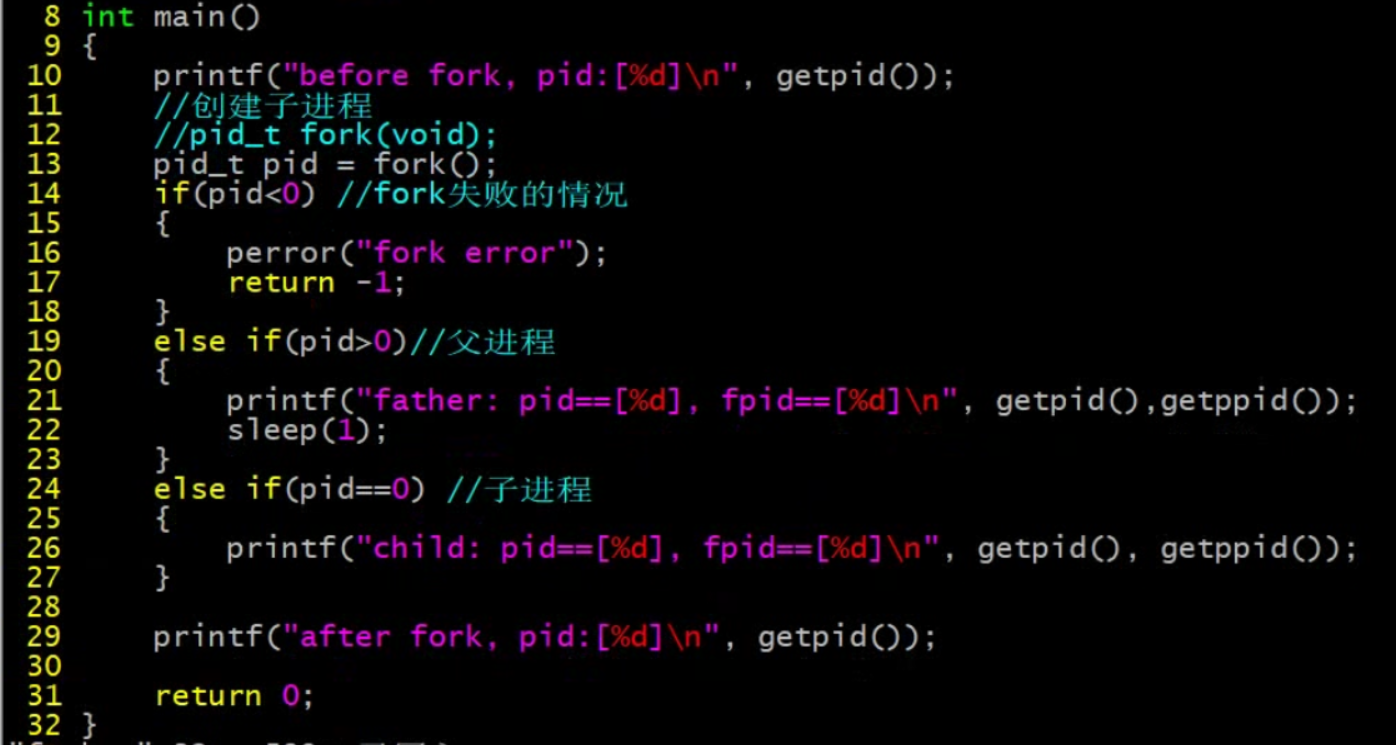
if...else之外的雨具父子进程都有。
父进程返回值大于0,子进程返回0(创建子进程成功)。父子谁先执行用户无法控制。sleep(1)让父进程后退出(子进程也不见得先执行,概率高一点而已)。
如果父进程先退出,子进程后退出,子进程PID会变化吗?
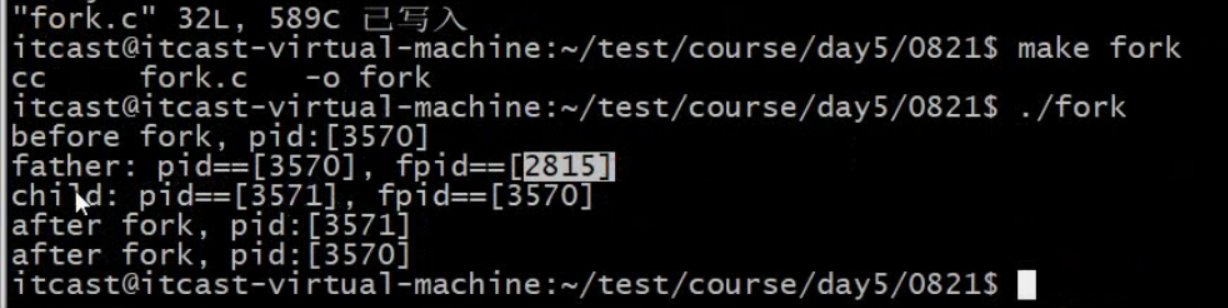
2815是当前shell,

注释sleep(1)
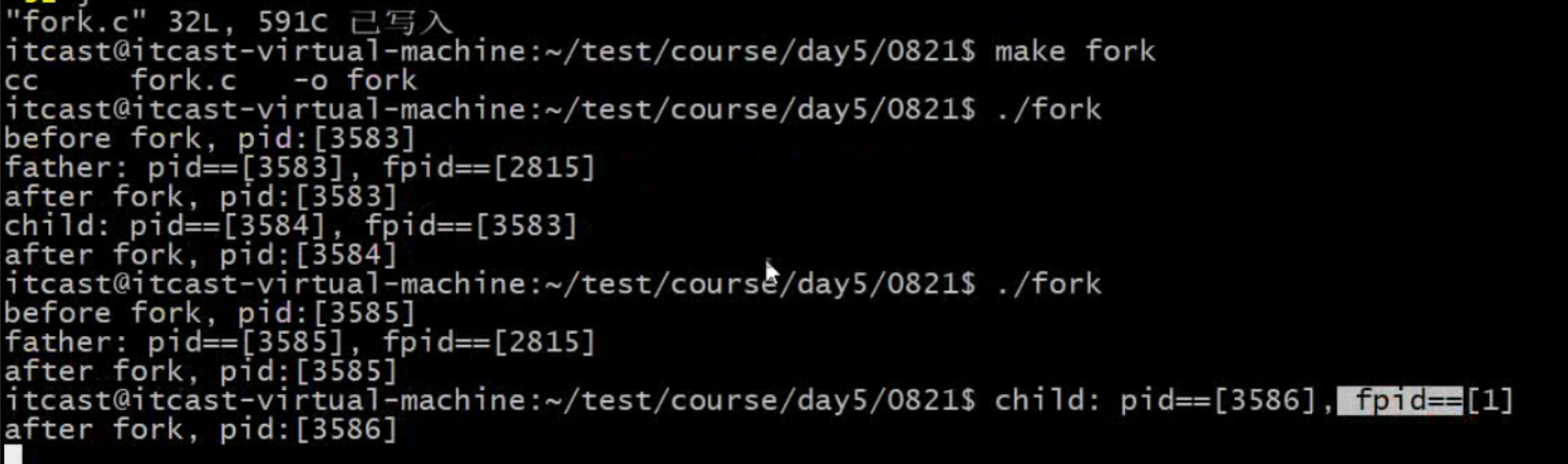
在Linux系统中,进程号1(PID 1)通常是init进程,或者在现代系统上是systemd进程。这个进程在系统启动时由内核启动,并且是所有其他用户空间进程的祖先。很多进程的父进程,很多进程是被它拉起来的。
./fork是被当前shell拉起来的
第一个fork中,父进程后退出,第二个fork中子进程后退出
子进程被1号进程领养,进程号1(PID 1)通常是init进程


有可能在这阻塞了

敲回车立刻退出,说明没有阻塞。
父进程结束,子进程后结束。子进程还在占用,父进程先回到当前shell

回到shell
PCB里有文件描述符表存放打开的文件的信息,父子文件共享标准输出