最近手上有个项目,对流畅度要求到极致。就是要满60fps的那种。所以针对各个模块的渲染都有一些改进。文字渲染加速就式其中之一。趁着记忆尤新把这个给记录下来
SIMD 介绍
SIMD(单指令多数据)是一种计算机指令集架构,它允许处理器同时对多个数据元素执行相同的操作。这种指令集架构可以显著提高数据并行计算的性能,特别是在处理大规模数据集时。
就如下图中,SIMD可以同时执行多个运算,并且不会相互影响
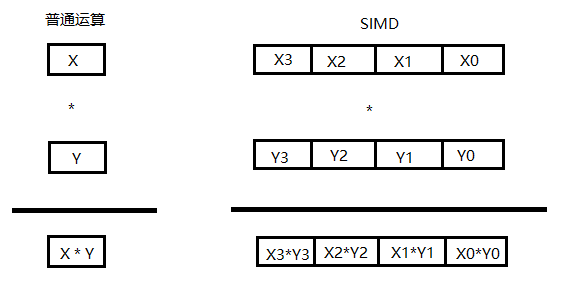
cortex m55 有一个128位的寄存器,可以同时执行4个32位或者8个16位或者16个8位的并行计算。 这个寄存器通常可以分好几种用途。
刚刚好我们的项目的MCU 式ARM cortex m55的芯片,也是支持 SIMD 指令的。
纯软件渲染一个A8格式的文字
A8格式图片文字,渲染包括颜色信息,和目标颜色公式如下:
上面这个公式就是实现一个像素点的文本渲染。我们只需要把文字高x宽的所有像素点都执行一遍上面的公式就完成了一个文字的渲染。但是上面的公式只是原理,实际上颜色是3个通道。
1 //A8 格式渲染伪代码 2 void render_A8_to_fb(uint32_t* fb, int fb_w, int fb_h, int pos_x, int pos_y, 3 uint8_t* a8_buf, int a8_w, int a8_h, uint32_t color) { 5 //伪代码不考虑越界等细节 6 for (int y = 0; y < a8_h; y++) { 7 for (int x = 0; x < a8_w; x++) { 8 // 获取当前像素的A8值 9 uint8_t a8_value = a8_buf[y * a8_w + x]; 10 11 // 计算像素在fb中的位置 12 uint32_t *Cd = &fb[(pos_y + y) * fb_w + pos_x + x]; 13 14 // 如果像素在剪切窗口内,则将RGBA值写入fb的像素数据中 15 *Cd = mix_color(color, *Cd, a8_value); 16 } 17 } 18 } 19 20 uint32_t mix_color(uint32_t c, uint32_t d, uint8_t alpha) 21 { 22 //将颜色的三个通道分别混合,然后再将三个颜色合并 23 .... 24 //这里就把混合的过程变成了3倍。 25 }
通过伪代码可以看出一个文字渲染是一个大量运算的过程。我们最关键的是SIMD可以减少循环的次数,比如之前循环的次数是 w * h * 3。 3是因为三种颜色要分开计算。
通过SIMD可以减少循环的次数到 w*h/4。 因为一次运算了16个U8.
SIMD 优化
针对循环体内的算式就可以优化
-
1.
Color * alpha 乘法, 但是需要分成3次乘(r,g,b)。 ARM cortex M4 SIMD一次就能完成 4 次 U8的乘法。 我们今天的M55的架构可以一次完成16次U8的乘法。所以我们可以优化的更多,一次完成4个像素的渲染。这个就是我们能加速的核心。
m55的指令是 vmulhq_u8 完成两个16个u8的向量的乘法,执行了16次乘法。8x8 结果应该是个16位,这个指令是取乘出结果的高8位。正好是我们想要的。
-
1.
255 - alpha 这个操作我们可以替换成 按位取反的操作。m55有按位取反的指令
vmvnq_u8 -
2.
将(255 - alpha)*Cd 与 Color*alpha 的结果相加。 SIMD的加法指令是
vaddq_u8
最后的核心代码如下:
1 uint8x16_t vec_a = {a[0],a[0],a[0],0xff,a[1],a[1],a[1],0xff,...}//alpha 赋值 2 //... 前面步骤省略。后面有实际代码 3 *dst_vec = vaddq_u8(vmulhq_u8(vec_a, vec_color), 4 vmulhq_u8(vmvnq_u8(vec_a), *dst_vec));
最终的代码
最后给出基于LVGL的实际代码
1 //实现给LVGL的例子 2 #include "arm_mve.h" //需要包含这个头,arm的向量运算C封装 3 void render_a8_to_fb(lv_draw_ctx_t *ctx, int pos_x, int pos_y, 4 uint8_t *a8_buf, int a8_w, int a8_h, lv_color_t color) 5 { 6 lv_area_t area; 7 lv_area_t box_area = {pos_x, pos_y, pos_x + a8_w -1, pos_y + a8_h - 1}; 8 bool ok = _lv_area_intersect(&area, &box_area, ctx->clip_area); 9 if (ok == false)return; 10 11 lv_area_move(&area, -ctx->buf_area->x1, -ctx->buf_area->y1); 12 13 lv_color_t *fb = (lv_color_t *)ctx->buf; 14 lv_coord_t fb_w = lv_area_get_width(ctx->buf_area); 15 16 uint8x16_t vec_color = {//颜色向量初始化 17 color.ch.blue, color.ch.green, color.ch.red, color.ch.alpha, 18 color.ch.blue, color.ch.green, color.ch.red, color.ch.alpha, 19 color.ch.blue, color.ch.green, color.ch.red, color.ch.alpha, 20 color.ch.blue, color.ch.green, color.ch.red, color.ch.alpha}; 21 22 for(int y = area.y1; y <= area.y2; y++){ 23 uint8_t *a8 = &a8_buf[(y - pos_y + ctx->buf_area->y1)*a8_w + area.x1 - pos_x + ctx->buf_area->x1]; 24 uint8x16_t *dst_color = (uint8x16_t *)&fb[y*fb_w + area.x1]; 25 for(int x = area.x1; x <= area.x2; x += 4){ 26 uint8x16_t vec_a = {a8[0], a8[0], a8[0], 0xff, 27 a8[1], a8[1], a8[1], 0xff, 28 a8[2], a8[2], a8[2], 0xff, 29 a8[3], a8[3], a8[3], 0xff}; 30 *dst_color = vaqqq_u8(vmulhq_u8(vec_a, vec_color), 31 vmulhq_u8(vmvnq_u8(vec_a), *dst_color)); 32 dst_color++; 33 a8 += 4; 34 } 35 } 36 }
最终实际验证结果没有4倍的性能,大概是原版文字渲染速度的两倍性能。 之前渲染100个34号字大概需要40ms。 使用SIMD指令优化后性能可以到20ms。也在疑惑性能提升没有到4倍。有其它优化心得的朋友欢迎交流。这个只是本人摸索的并不是很了解。