3.1.1 认识Pandas库¶
- 基于Numpy的一种工具,为解决数据分析任务而创建的,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具
- 基本上你能用Excel或者Bi工具进行的数据处理,Pandas也都能实现,而且更快
In [ ]:
pip install pandas
Requirement already satisfied: pandas in c:\users\dengzl\.conda\envs\data_analysis\lib\site-packages (2.1.1) Requirement already satisfied: numpy>=1.22.4 in c:\users\dengzl\.conda\envs\data_analysis\lib\site-packages (from pandas) (1.26.0) Requirement already satisfied: python-dateutil>=2.8.2 in c:\users\dengzl\.conda\envs\data_analysis\lib\site-packages (from pandas) (2.8.2) Requirement already satisfied: pytz>=2020.1 in c:\users\dengzl\.conda\envs\data_analysis\lib\site-packages (from pandas) (2023.3.post1) Requirement already satisfied: tzdata>=2022.1 in c:\users\dengzl\.conda\envs\data_analysis\lib\site-packages (from pandas) (2023.3) Requirement already satisfied: six>=1.5 in c:\users\dengzl\.conda\envs\data_analysis\lib\site-packages (from python-dateutil>=2.8.2->pandas) (1.16.0) Note: you may need to restart the kernel to use updated packages.
3.1.2 数据结构:Series、DataFrame¶
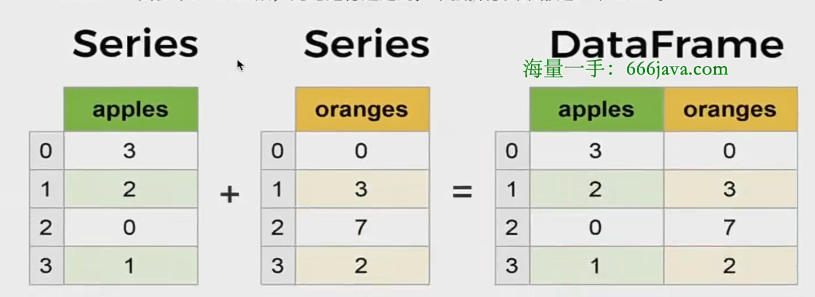
区别
- series,只是一个一维数据结构,它由index和value组成
- dataframe,是一个二维结构,处理拥有index和value之外,还拥有column. 联系
- dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series
In [ ]:
# 创建一张二维表格 ---> 判断数据结构/属性
data = {'apples':[3,2,0,1],'oranges':[0,3,7,2]}
data
Out[ ]:
{'apples': [3, 2, 0, 1], 'oranges': [0, 3, 7, 2]}
In [ ]:
type(data)
Out[ ]:
dict
In [ ]:
import pandas as pd
data = pd.DataFrame(data)
data
Out[ ]:
| apples | oranges | |
|---|---|---|
| 0 | 3 | 0 |
| 1 | 2 | 3 |
| 2 | 0 | 7 |
| 3 | 1 | 2 |
In [ ]:
type(data)
Out[ ]:
pandas.core.frame.DataFrame
In [ ]:
apple = data['apples']
apple
Out[ ]:
0 3 1 2 2 0 3 1 Name: apples, dtype: int64
In [ ]:
type(apple)
Out[ ]:
pandas.core.series.Series
In [ ]:
apple = pd.Series(apple, index=[3,2,1,0])
apple
Out[ ]:
3 1 2 0 1 2 0 3 Name: apples, dtype: int64
In [ ]:
apple.reset_index() # 重置索引
Out[ ]:
| index | apples | |
|---|---|---|
| 0 | 3 | 1 |
| 1 | 2 | 0 |
| 2 | 1 | 2 |
| 3 | 0 | 3 |
In [ ]:
apple.reset_index(drop=True) # 重置索引并删除原有索引
Out[ ]:
0 1 1 0 2 2 3 3 Name: apples, dtype: int64
3.1.3 Numpy v.s. Pandas¶
In [ ]:
# 两者的互相转换
import numpy as np
data2 = np.arange(15).reshape(3,5)
data2
Out[ ]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [ ]:
pd.DataFrame(data2)
Out[ ]:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
In [ ]:
data3 = pd.DataFrame(data2,columns=['a','b','c','d','e']) # numpy转为pandans
data3
Out[ ]:
| a | b | c | d | e | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
In [ ]:
data3.values # pandans转为numpy
Out[ ]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])