Thrift 格式解析
https://www.cnblogs.com/Forever-Kenlen-Ja/p/9649724.html
常用数据格式包括 CSV JSON XML,这些格式有缺点:
- CSV没有指定数据类型,如可能将数字开头的字符串无认为数字
- 使用文本存储会浪费空间
- JSON XML 注重可读,提高程序员效率,但数据存储传输效率不高,尤其大数据低时延场景
使用二进制序列化可有效解决此问题,但是:
- 数据格式隐含在代码中,对于每个格式都要手动写序列化反序列化代码
- 数据格式变化时,版本不兼容
TBinaryProtocol
- 通过一个Schema文件定义一个结构体,定义字段顺序、类型、名称
- 使用已有的程序解析Schema文件,自动生成序列化代码
struct SearchClick
{
1:string user_id,
2:string search_term,
3:i16 rank,
4:string landing_url,
// 5:i32 click_timestamp, 已废弃
6:i64 click_long_timestamp,
7:string ip_address
}不仅写入数据的值,还写入编号和类型,每条纪律结束时都写下一个标志位。旧版本程序看到没见过的编号就跳过,新版本程序对于旧版本数据中没有的字段只会读不到不会不兼容。这个机制下编号就起到版本作用,无需版本管理。编号保证无需每个字段都填上,废弃的字段直接注释即可。整个struct变成一个稀疏结构,无需每个字段都填值
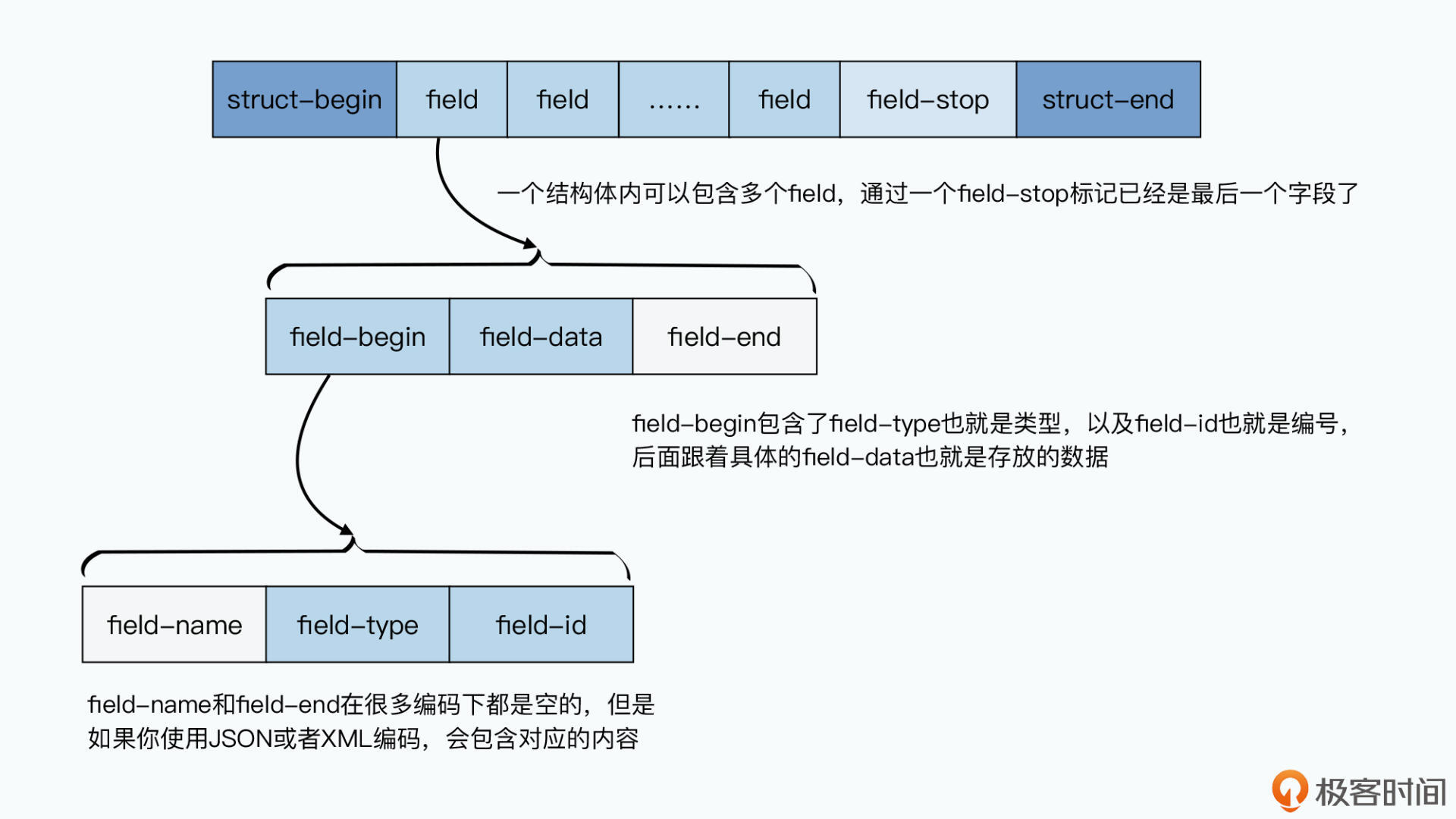
TCompactProtocol
论文发布后,又做出了优化。编号和类型实现了向前向后兼容,但是数据冗余变大了。如一个数字,从string转为i32,节约了部分字节,但是加的编号又会占用。使用 Delta Encoding 解决问题,这个协议存储的不是编号的值,而是与上一个编号的差。如第一个是1,第二个是5,那么第二个编号的存储直接对应4。使用4bit存储差值,再用4bit存储类型。通常类型不到16种,字段间的差也不到15。
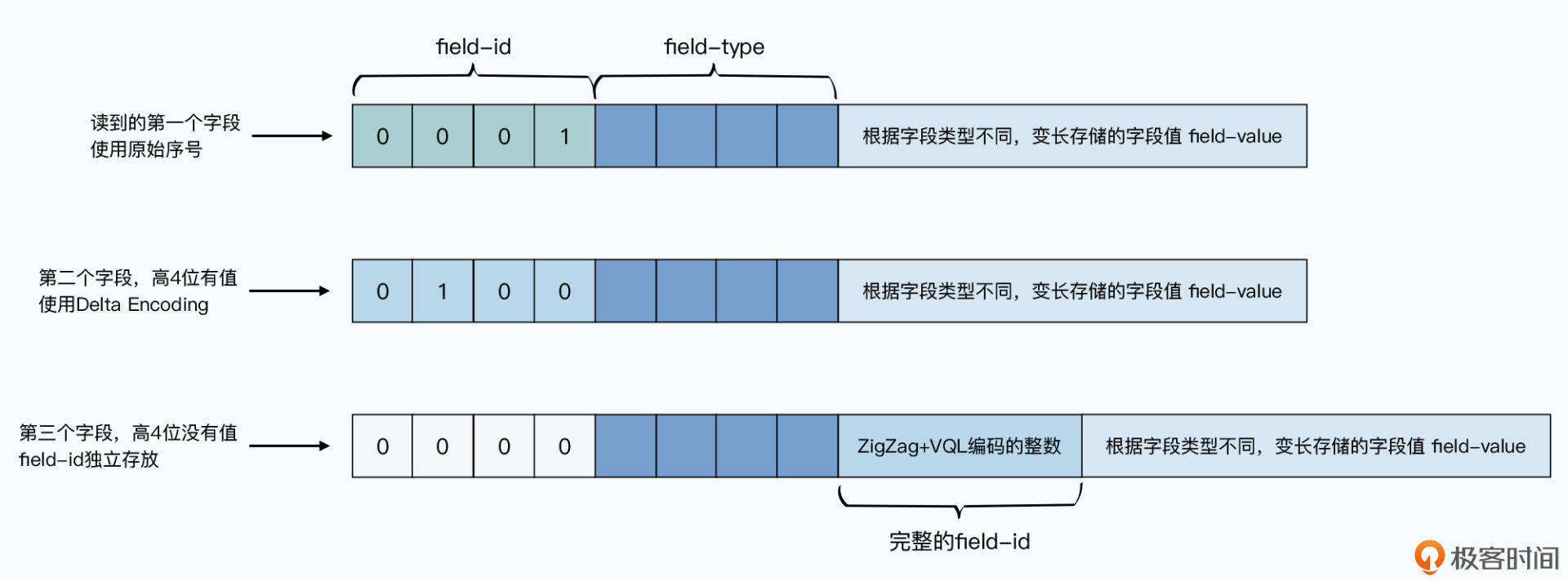
如果序号间的差超过15怎么办?要使用1字节表示类型,再用 ZigZag+VQL 编码表示序号差。
ZigZag 编码 + VQL 可变长数值表示
TCompactProtocol 对所有整型使用可边长数值(VQL,Variable-length quantity)表示。每个字节高位使用1bit标记整个整数是否需要读取下一字节,后面7bit存放实际数据。一个32位整数最少要1字节,最多5字节。
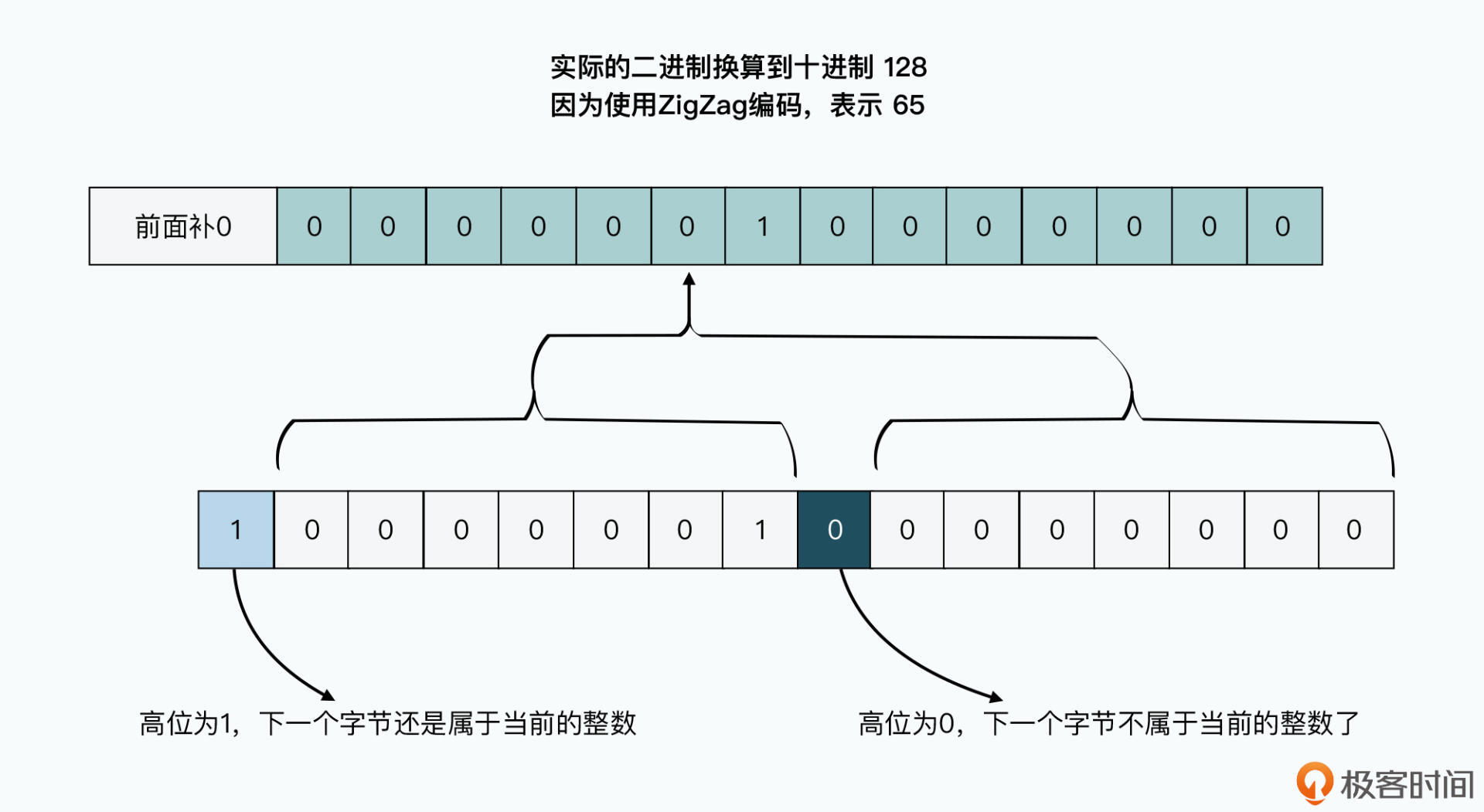
整型负数首位一定是1,如-1表示位 0XFFFFFFFF。所以没有采用普通16进制编码,而是使用 ZigZag 编码方式:负数变为正数,而正数乘以2,这样7个bit可表示-64到63这128个数。只要整型数绝对值小,占用的空间就小。
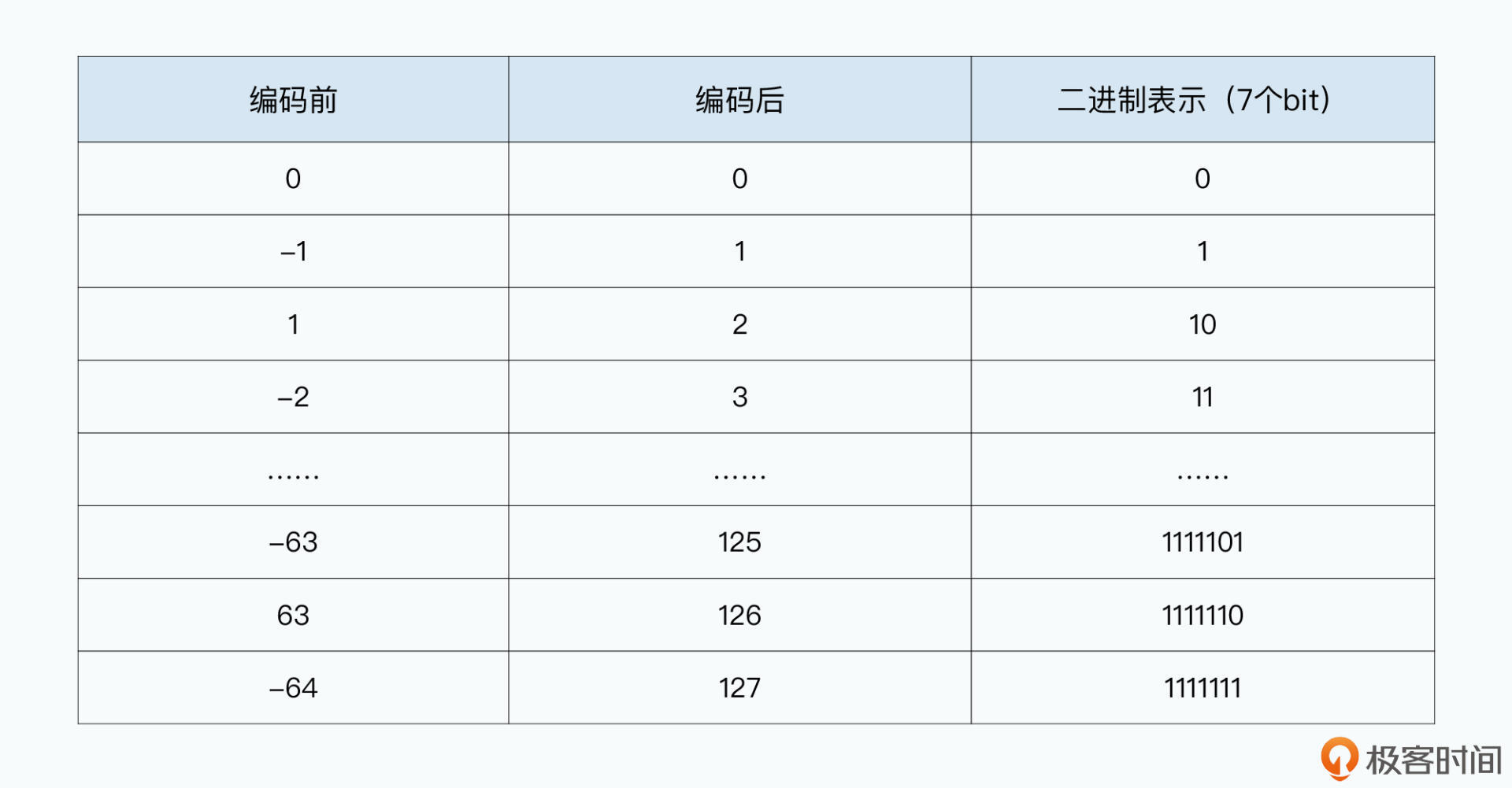
使用 ZigZag+VQL 后存储一个整型通常只要2个字节
Thrift实现了 跨语言+序列化+RPC
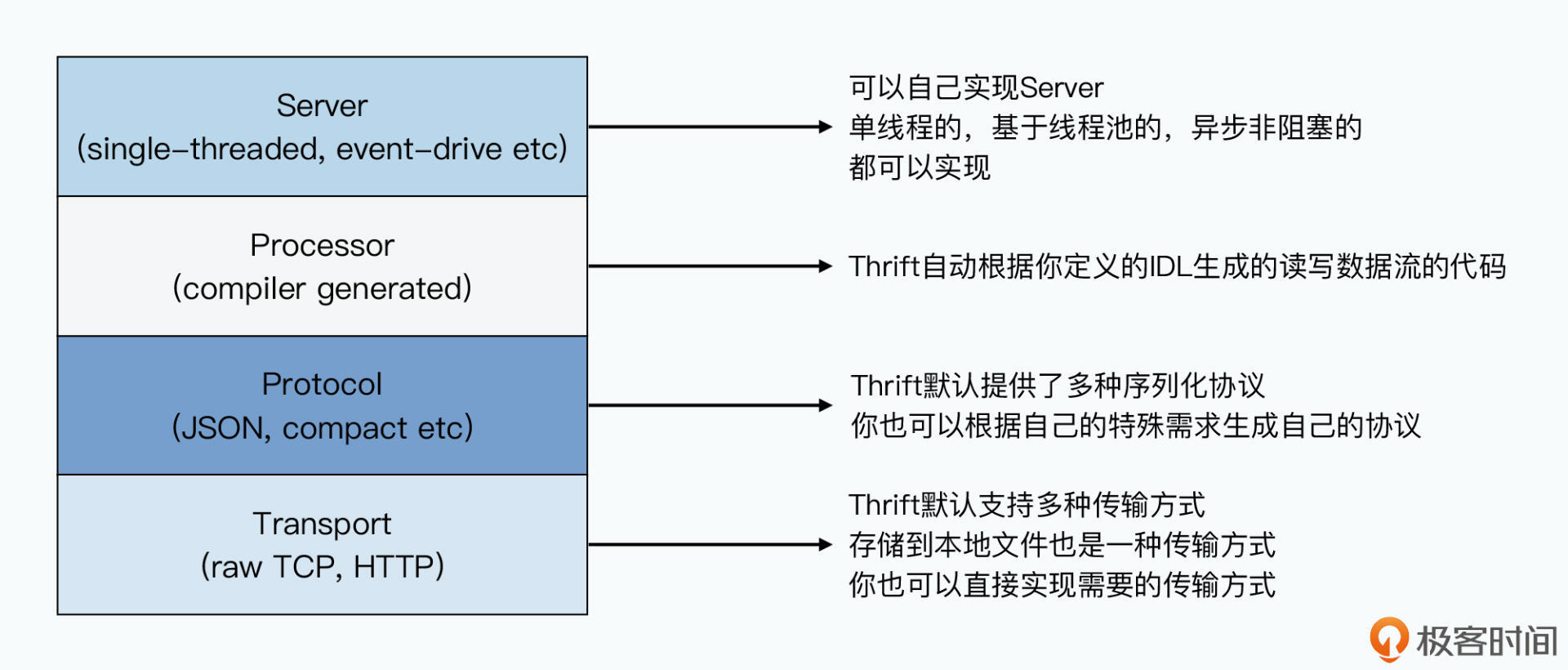
Thrift是protobuf和gPRC的结合,而Apache Avro对比这二者无需预先进行代码生成,也无需指定数据编号