Vision Transformer with Super Token Sampling
* Authors: [[Huaibo Huang]], [[Xiaoqiang Zhou]], [[Jie Cao]], [[Ran He]], [[Tieniu Tan]]
初读印象
comment:: ViT在捕捉浅层局部特征时可能会出现高冗余度的问题,使用strong super token提供具有语义意义的视觉内容细分,并在保留全局建模的同时减少自注意力的token数量。
Why
- 自注意力的计算复杂度与标记数呈二次方关系,因此在高分辨率视觉任务(如物体检测和分割)中会产生巨大的计算成本。
- ViTs 倾向于捕捉浅层的局部特征,冗余度较高。
- 浅层的全局注意力会集中在相邻的几个标记上(用红色填充),而忽略距离较远的大部分标记。因此,在捕捉这种局部相关性时,对所有token进行全局比较会产生大量不必要的计算成本。
- 局部注意力中冗余有所减少,但是仍然只有几个邻近的标记有比较高的权重。
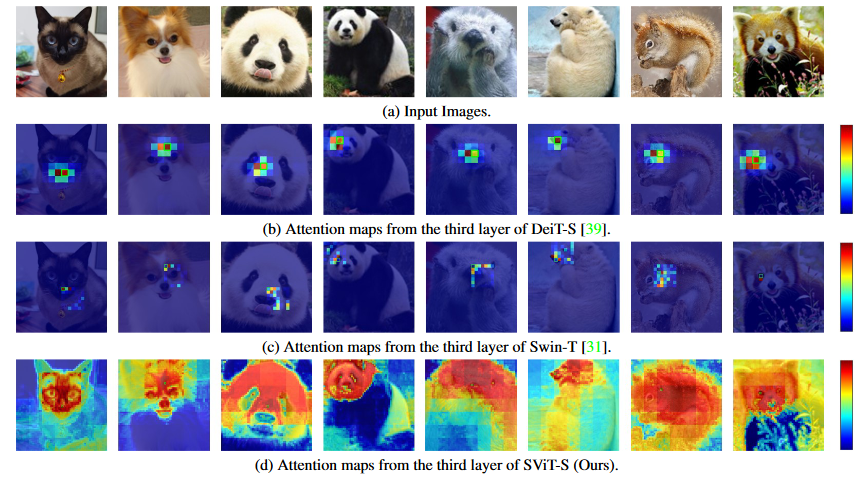


- 局部注意力和浅层卷积特征提取方案都牺牲了捕捉全局依赖性的能力。
目的:在神经网络的早期阶段获得高效和有效的全局表征。
What
Super Pixel能从感知上将相似的像素组合在一起,从而减少后续处理所需的图像基元数量。将Super Pixe的概念从像素空间借鉴到标记空间,提出Super Token。
- super token采样 (STS):应用快速采样算法通过学习token和super token之间的稀疏关联来预测super token。
- 多头自我注意 (MHSA):在super token空间中执行自我注意力,以捕捉super token之间的远程依赖关系。
- token上采样 (TU):使用从第一步中学到的关联将super token映射回原始token空间。
总体架构
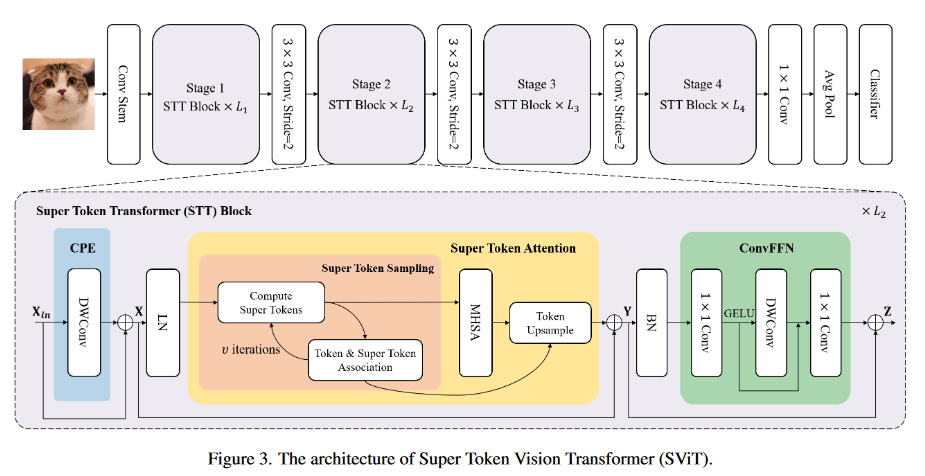
Super Token Transformer(STT) Block:
- Convolutional Position Embedding (CPE):CPE 模块使用深度卷积以较低的计算成本增强了局部特征的代表能力。
- Super Token Attention (STA):将普通的全局注意力分解为稀疏关联图和低维注意力的乘法,从而有效地捕捉全局依赖关系。
- Convolutional Feed-Forward-Network (ConvFFN):具有深度卷积的 ConvFFN 模块进一步增强了局部特征的代表能力,同时保持了较低的计算成本。
Super Token Attention
Super Token Sample
给定token \(X\in R^{N×C}\) (其中 N = H × W 为标记数),假设每个token \(X_i \in R^{1×C}\) 都属于 m 个超级标记 \(S∈R^{m×C}\) 中的一个,因此有必要计算 X-S 关联图\(Q\in R^{N×m}\) 。
初始:通过对规则网格区域内的标记取平均值,对初始super token \(S^0\) 进行采样。如果网格大小为 h×w,则super token数量为 m = H/h ∗W/w,后经两步迭代:
-
Token & Super Token Association:计算关联图\(Q^t\in R^{N×m}\)
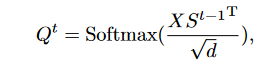 d是通道数C。* Super Token Update:super token更新为token的加权和
d是通道数C。* Super Token Update:super token更新为token的加权和
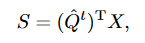
\(\hat{Q}^t\)是列标准化的\(Q^t\)。为了加快采样过程,将每个token的关联计算限制在周边 9 个super token上。
 *Self-Attention for Super Tokens:
*Self-Attention for Super Tokens:
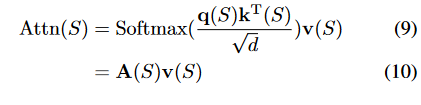
-
Token Upsampling:恢复超采样过程中的局部细节
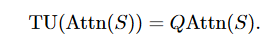 ###How
###How
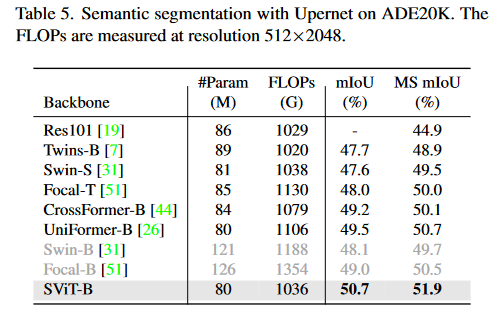
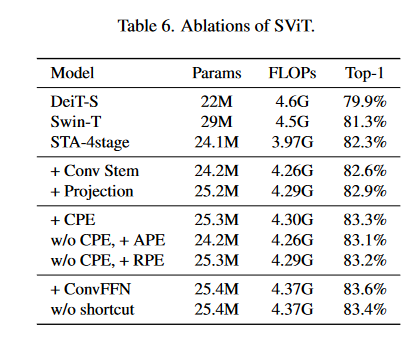
Enlightenment
OCRNet的翻版,使用了更加先进的架构。
从传统算法得到的思想,类似于EMANet。
映射Q迭代的过程没有经过任何可学习变量的修改