幽灵和熔断
幽灵和熔断是基于瞬态指令流的缓存侧信道攻击。在瞬态指令流中被执行的内存加载指令如果将一个数据带入了缓存,则即使流水线回滚期间处理器丢弃了该指令返回的访存结果,已经被修改的缓存状态却无法撤销。由此,攻击者可以通过监测缓存的变化来推断受害者程序的访存地址,如果该地址本身包含敏感信息,就会引发信息泄露。
幽灵利用的是分支预测机制。
熔断利用的是乱序执行机制。
解决的办法可以是软件插入fence,硬件修改cache等。
代码复现:
https://github.com/Eugnis/spectre-attack
参考:
https://www.wenhui.space/docs/08-ic-design/cpu/meltdown-and-spectre/
https://zhuanlan.zhihu.com/p/583851306
LR/SC的实现和使用
- L3层不负责LR、SC指令的lock的monitor。LR、SC指令出现的lock bit一般存储在L1 cache中,每个核心都有。初始上电以后,当核心0和核心1同时发起LR访问,同时经过L3层,L3层进行仲裁,只能将数据存储在核心0或者核心1上,而另外一个核心虽然也拿到了数据,但影响到了第一个拿到数据的核心,从此两个核心中的L1 cache变成Shared Clean状态。但是只有第一个核心能获取到对该地址的lock位置写1。第二个core尝试作出的SC指令必定是失败的。后续无论第二个核心再执行多少条LR指令,都不会让第二个核心将第一个核心的lock位置变成1,因为第二个核心通过L3层观察到第一个core没有清除lock位置。
- LR、SC指令在多核之间,每个核心都有一个lock位置,因此其它核心拿到LR指令以后,不论LR和SC执行多少次,lock位置都不会为1,保证了独占性。
- LR和SC在单个核心上的使用会出现一致性问题,因为lock位置共享。对于单个核心的数据共享,不应该使用LR和SC,否则会存在一致性问题;而是手动设定软件的lock bit,拿到lock bit的线程可以执行。对于单个核心的软件lock,其实可以模拟cache的MESIbit,使得多个线程共享该bit,实现类似LR、SC的操作。
Consistent和Coherent
Consistent是由于多个Master对同一块内存区域的读写顺序造成的问题,只能由硬件提供相关的机制,由软件来保证。 而Coherent则是由于同一块内存区域可能有多份拷贝(主要是Cache)而造成的数据的不一致性,可以由硬件来保证。
参阅:
https://zhuanlan.zhihu.com/p/21387258
memory 属性 Device-nGnRnE
如何划分shareable domain是和系统设计相关,我们假设一个系统的domain分配如下:
(1)所有的cpu core属于一个inner shareable domain
(2)所有的cpu core和dma controller属于一个outer shareable domain。(这个如果硬件不支持就没有)
在ARM architecture中,对一个normal memory location而言,是否是coherent是和它的页表中的shareability attribute的设定相关。
(1)non-shareable。根本不会再多个agent之间共享,不存在coherent的问题。
(2)inner-shareable。说明inner shareable domain中的所有的agent在对该内存进行数据访问的时候,硬件会保证coherent。
(3)outer-shareable。说明outer shareable domain中的所有的agent在对该内存进行数据访问的时候,硬件会保证coherent。
对于device type,其总是non cacheable的,而且是outer shareable,因此它的attribute不多,主要有下面几种附加的特性:
(1)Gathering 或者non Gathering (G or nG)。这个特性表示对多个memory的访问是否可以合并,如果是nG,表示处理器必须严格按照代码中内存访问来进行,不能把两次访问合并成一次。例如:代码中有2次对同样的一个地址的读访问,那么处理器必须严格进行两次read transaction。
(2)Re-ordering (R or nR)。这个特性用来表示是否允许处理器对内存访问指令进行重排。nR表示必须严格执行program order。
(3)Early Write Acknowledgement (E or nE)。PE(Processor Element/Engine)访问memory是有问有答的(更专业的术语叫做transaction),对于write而言,PE需要write ack操作以便确定完成一个write transaction。为了加快写的速度,系统的中间环节可能会设定一些write buffer。nE表示写操作的ack必须来自最终的目的地而不是中间的write buffer。
https://blog.csdn.net/shenhuxi_yu/article/details/90617675
http://www.wowotech.net/kernel_synchronization/Why-Memory-Barriers.html
DMA和CPU访问一致性的方法
使用描述符。
描述符是的本质就是4个32位的内存,描述符的Status表示该描述符的状态和控制信息。因为描述符是DMA和CPU二者之间的共享内存,既然是共享资源,就需要进行保护,当DMA在使用的时候,CPU就不能使用,当CPU在使用的时候,DMA就不能使用。这个使用权的控制,就通过TDES0寄存器中的OWN位体现出来,对应到发送描述符结构体就是Status变量的最高位。

当OWN位为0的时候,表示CPU可以将要发送的数据拷贝到描述符中,拷贝完成以后,CPU手动将描述符的OWN位设置为1,以此来告诉DMA控制器,CPU已经拷贝完数据了,DMA可以从描述符中取出数据进行发送了。这时候DMA就会取出描述符中的数据,将数据发送出去,DMA在操作完描述符以后,自动将OWN位设置为0,告诉CPU,DMA已经发送完数据,CPU可以拷贝下一帧数据到描述符上了。
https://blog.csdn.net/qq_22902757/article/details/104275441
IP-XACT
xml格式的IP生成后的规格表,比如ralgen软件可以利用这个xml或者ralf,生成寄存器模型
https://www.ip-soc.com/jishu/213.html
IP-XACT首先由SPIRIT Consortium发布的标准,其唯一目标是在设计社区内促进IP的可重用性。它使IP提供商能够为组件和设计提供可读和可机器处理的IP的单一描述,并与其他所需的数据一起分享给IP用户。IP-XACT还描述了系统设计和IP之间的互连以及其他细节,如地址映射、接口等。提供了一个通用的设计表示,可供IP供应商、设计集成商和EDA工具提供商在其流程内进行交换。
vcs token is "until"
vcs的一些sva使用拓展的形式,因此需要额外的编译命令:
-assert svaext
vcs编译解决 module名重复的冲突问题
https://blog.csdn.net/cy413026/article/details/102738194
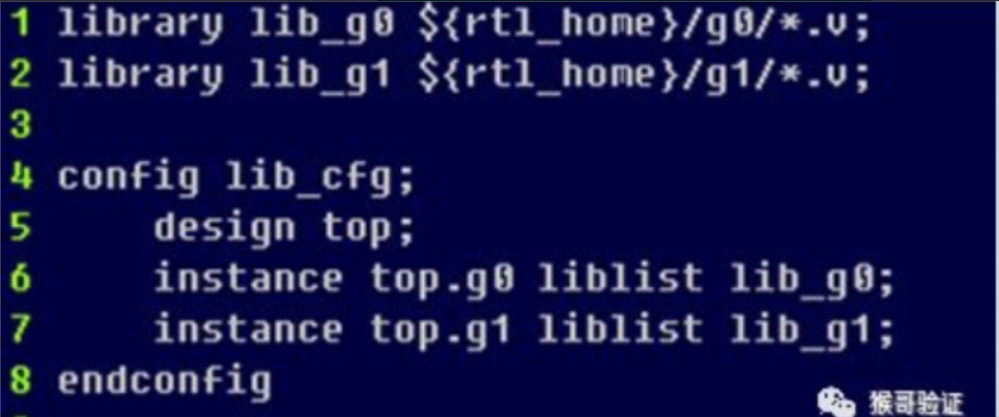
在工作目录下,顶层是top.v,下面两个文件夹guest0和guest1,每个文件夹是相同名字的module,为不同的add.v。在顶层集成的时候,如果是要编译成以下的形式,需要借助lib_map。其中的g0用guest0下的,g1用guest1下的内容。
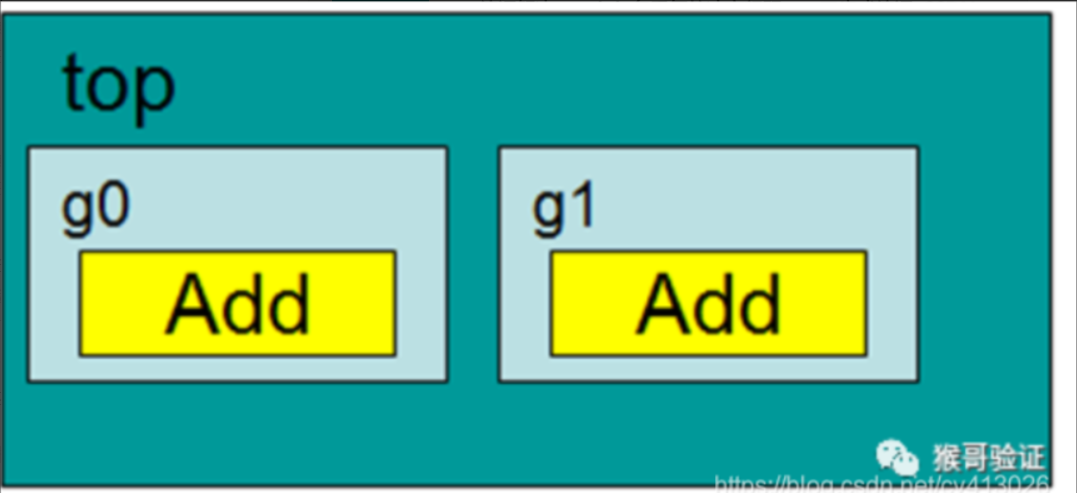
编译的时候,使用的filelist.f,不能将两个add模块编译成库(cell,否则检测到重复后只会编译某个而不是报错),而是要让它们编译成module。
需要编写lib_map,lib_map格式如下,可以使用相对路径,但是语句要增补分号。
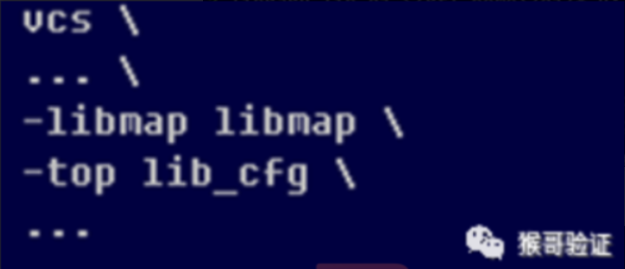
两步法编译选项需要增补的命令,指定lib_map文件。三步法没有尝试,两步法可用。
Webhook
和Jenkins、CI、CD等可以联动。
https://zhuanlan.zhihu.com/p/580322982
- 企业微信群机器人提供一个Webhook地址,通过这个地址,就可以自动触发企业微信群机器人发出对应的消息。
- 腾讯兔小巢提供一个Webhook地址,对应的Webhook地址就可以把消息和企业微信群机器人打通,发送对应的用户反馈消息。
- 腾讯云Hiflow场景连接器提供Webhook地址,可以通过这个这个地址连接企业自己的系统/数据库/手机快捷指令等应用,并向后连接腾讯文档/企业微信机器人等300+应用。