1 合并和分割
▪ tf.concat 拼接
▪ tf.split 分割
▪ tf.stack 堆叠
▪ tf.unstack
1.1 concat(拼接)
tf.concat([a,b,....],axis=)
这个就是a,b按照第axis维进行合并,注意,比如说在第1维度进行合并的话,其他维度一定要相等

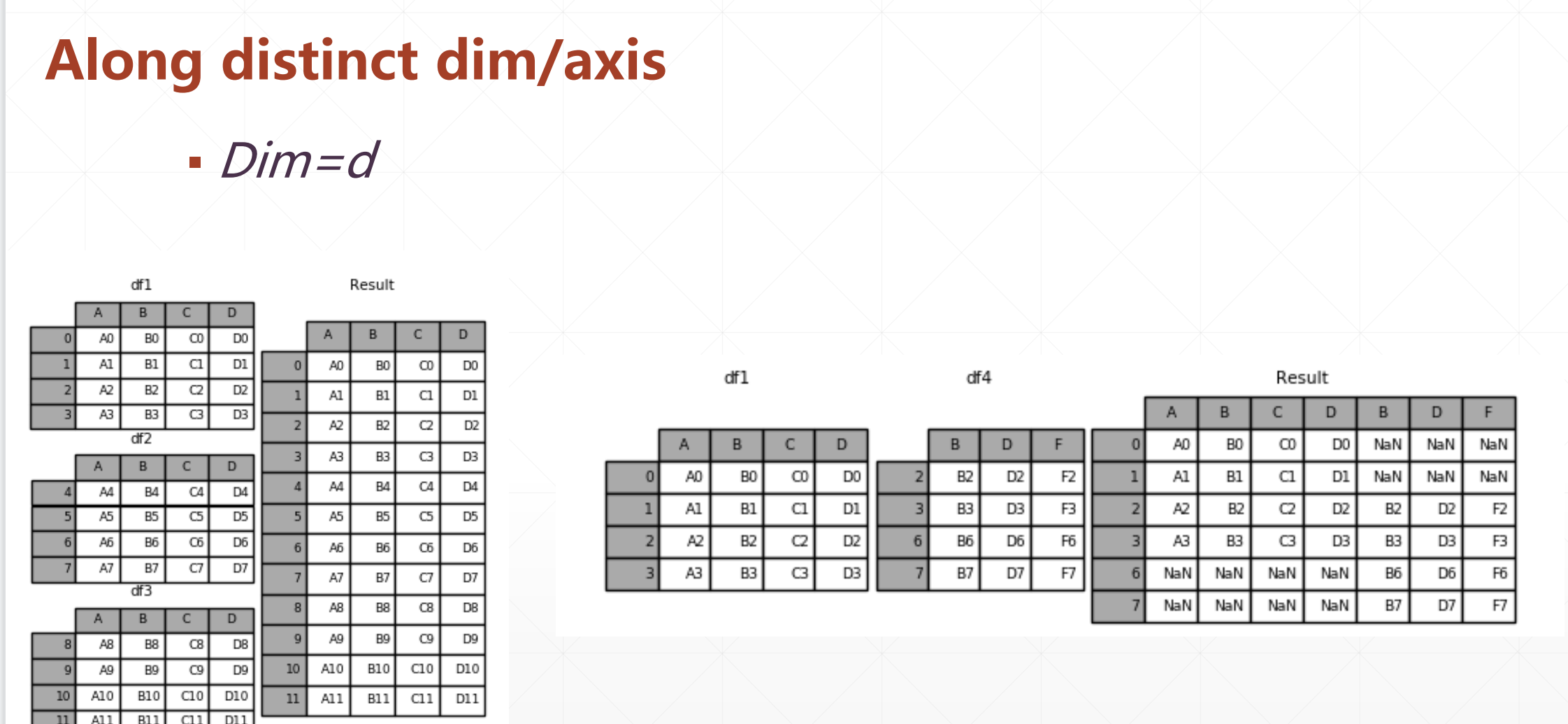
这里合并不会增加一个维度。下面的stack: create new dim
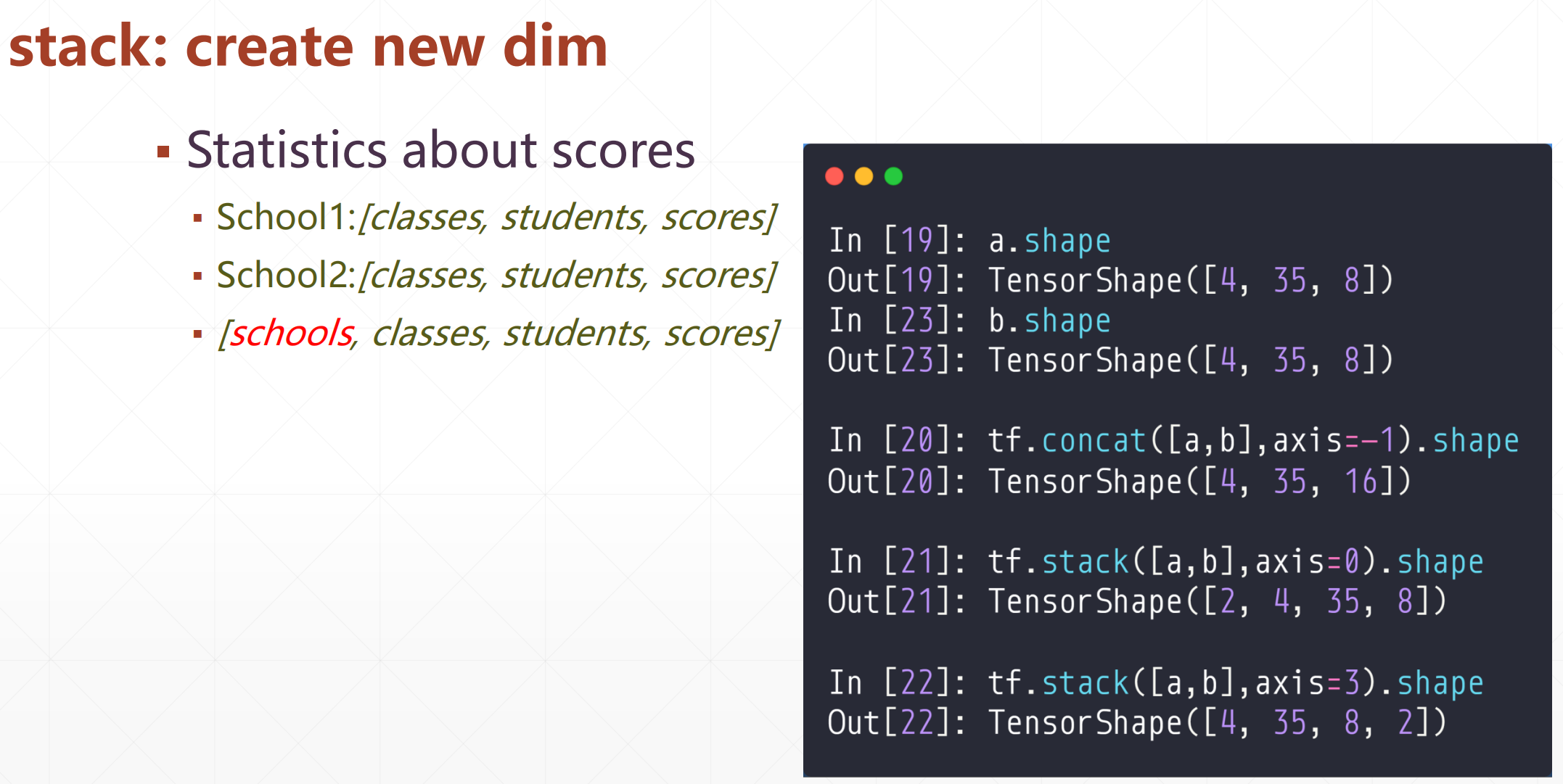
1.2 stack(堆叠)
tf.stack([a,b,...],axis=)
这个就是合并里面的矩阵,然后在axis轴创造一个新的维度
要求全部的维度都要相等
比如这个:
a=tf.ones([4,35,8])
b=tf.ones([4,35,8])
c=tf.ones([4,35,8])
tf.stack([a,b,c],axis=0).shape
#TensorShape([3, 4, 35, 8])
tf.stack([a,b,c],axis=2).shape
TensorShape([4, 35, 3, 8])

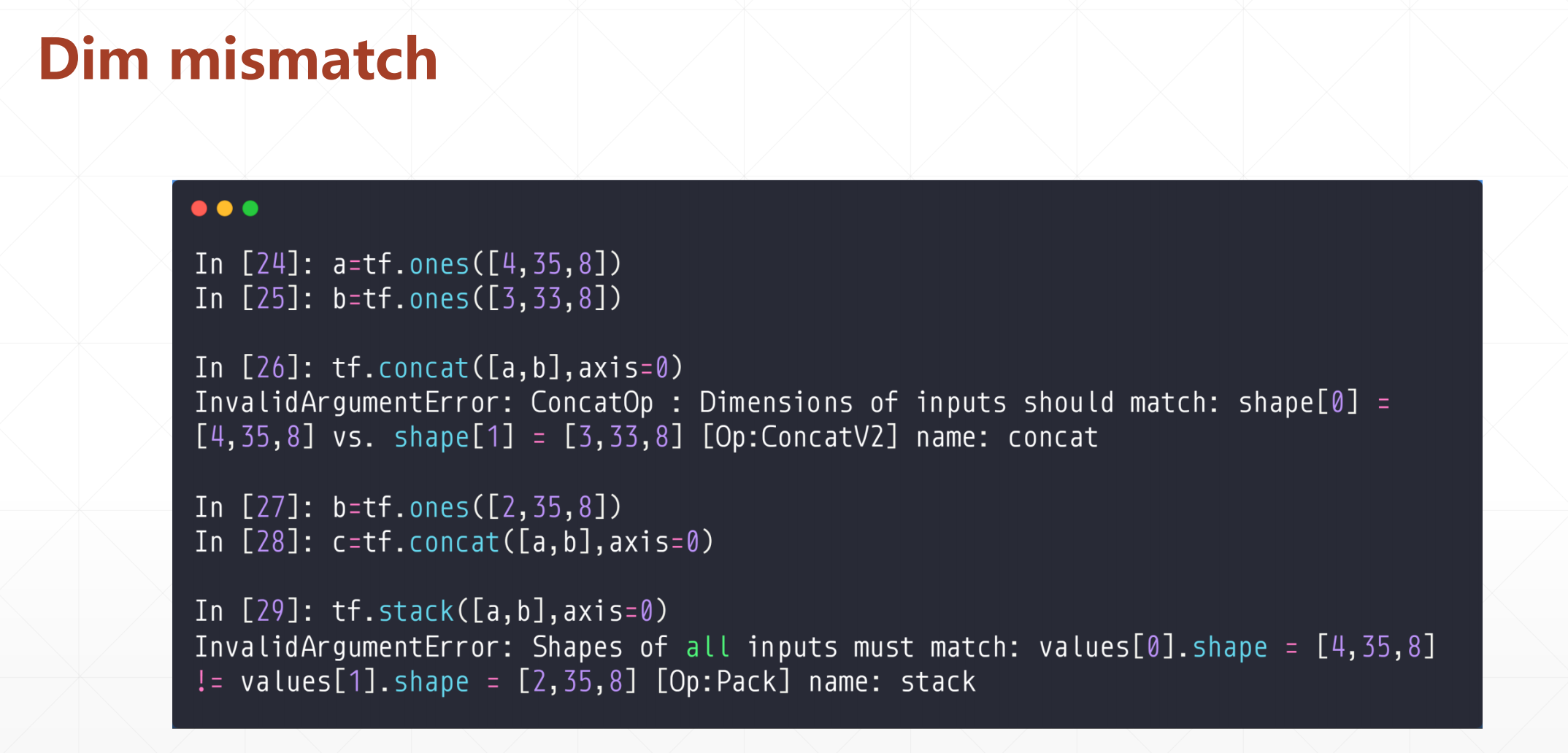
在这里注意一下concat操作的时候可以一个维度不相等,然后stack操作的时候必须全部维度都要相等
1.3 unstack(拆分)
tf.unstack(a,axis=)
这个和上面一个是相反的,这个就是对于指定一个张量,然后在axis维度进行拆分
注意:如果axis轴那个数组是8,就会打成8个
例如:
[2,4,34,8],axis=3的话,会打成8个[2,4,34]
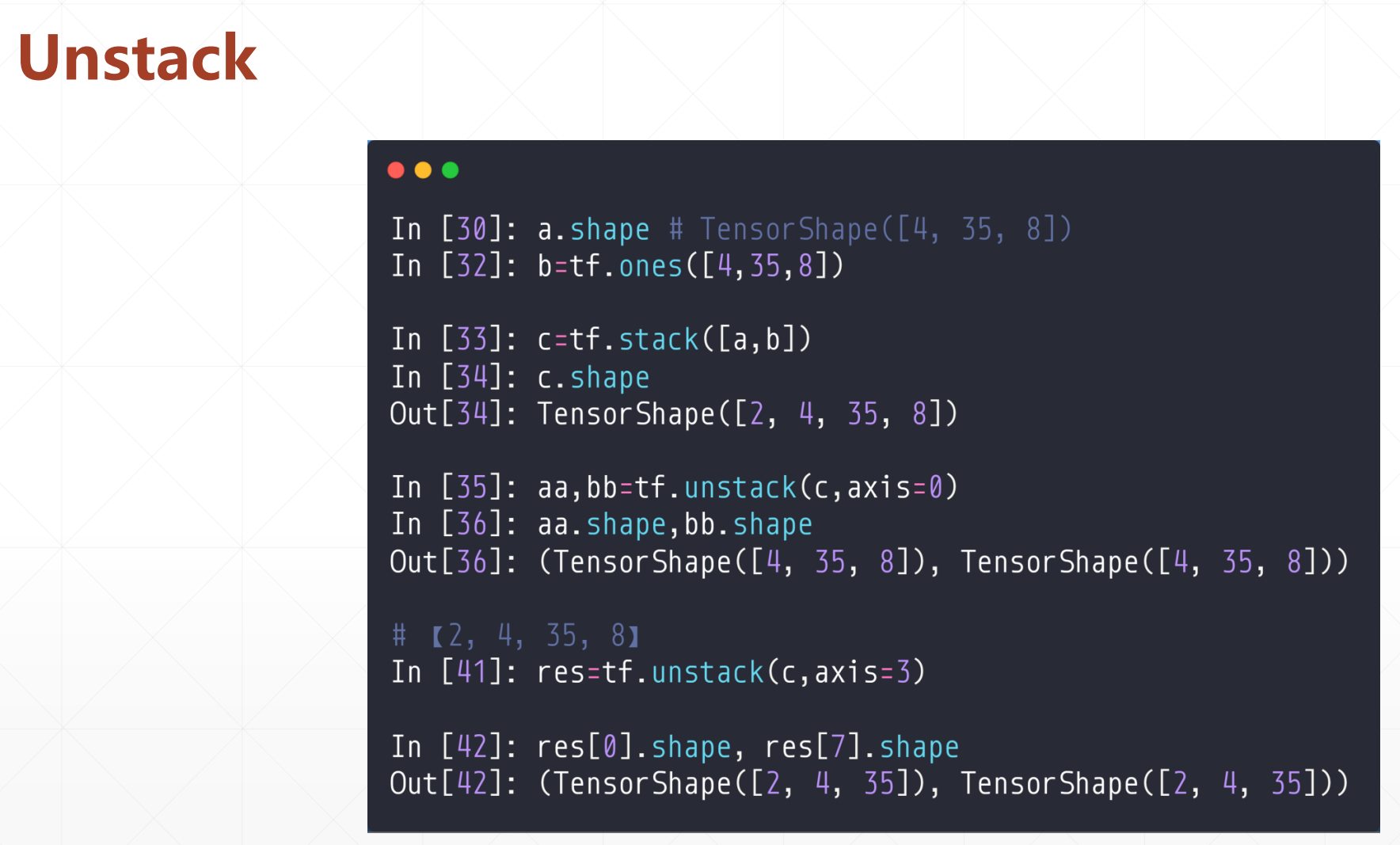
这个很不灵活,就是你想打散成两个[2,4,34,4]的话,你需要split函数
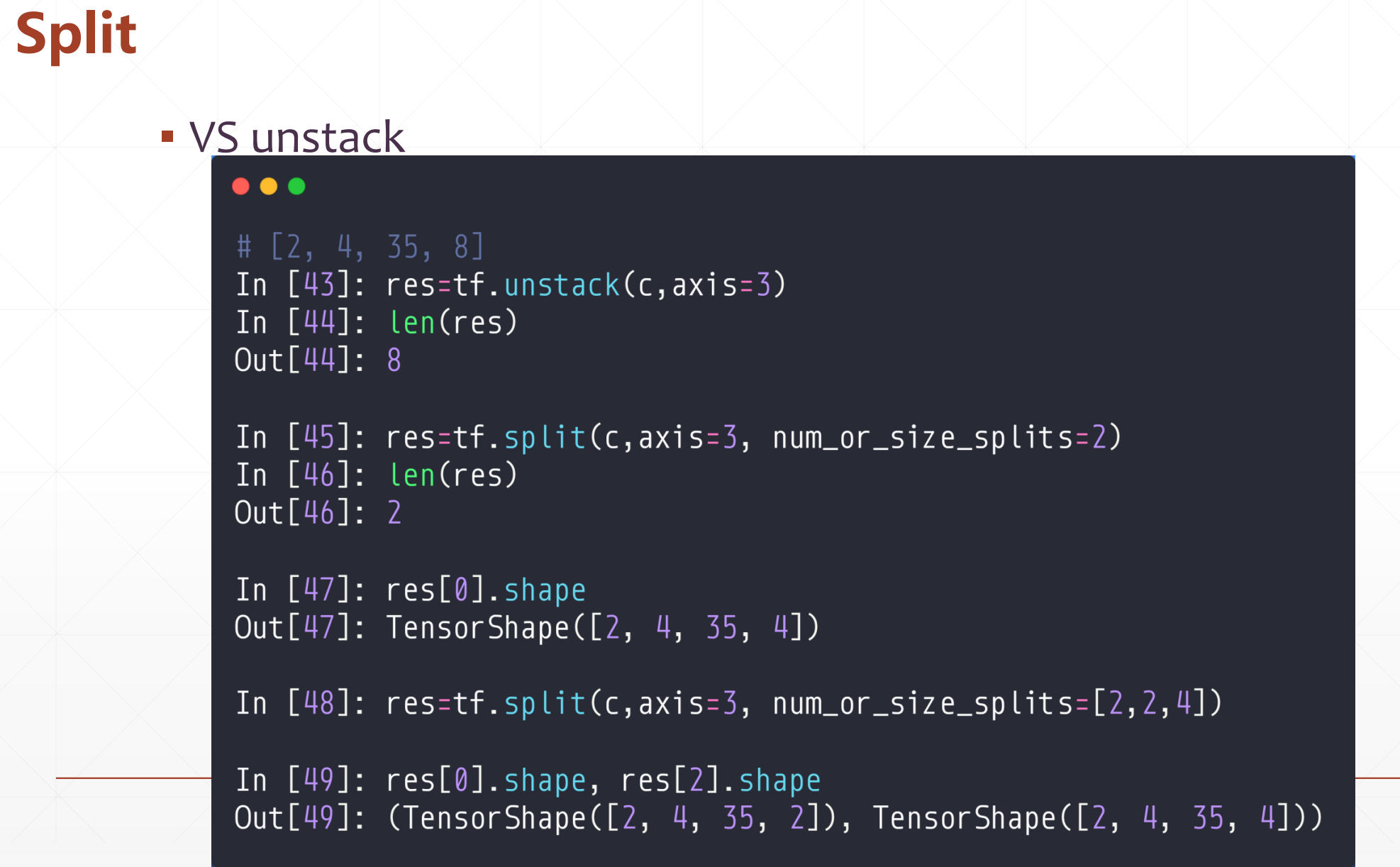
1.4 split(打散)
tf.split(
value, num_or_size_splits=, axis=, num=None, name='split'
)
value:需要打散的张量
num_or_size_splits:表示沿轴分割数的整数或一维整数张量或 包含沿轴每个输出张量大小的Python列表。如果是标量,则必须均匀分割value.shape[axis];否则,沿拆分轴的大小之和必须与值的大小之和匹配。
axis:需要切分的维度
num:可选,用于指定,当不能从size_split的形状推断输出的数量。
name:操作的名称(可选)。
2 数据统计
▪ tf.norm(范数)
▪ tf.reduce_min/max(最大/最小值)
▪ tf.argmax/argmin(最大最小值的位置)
▪ tf.equal(是否相等)
▪ tf.unique(独特值)
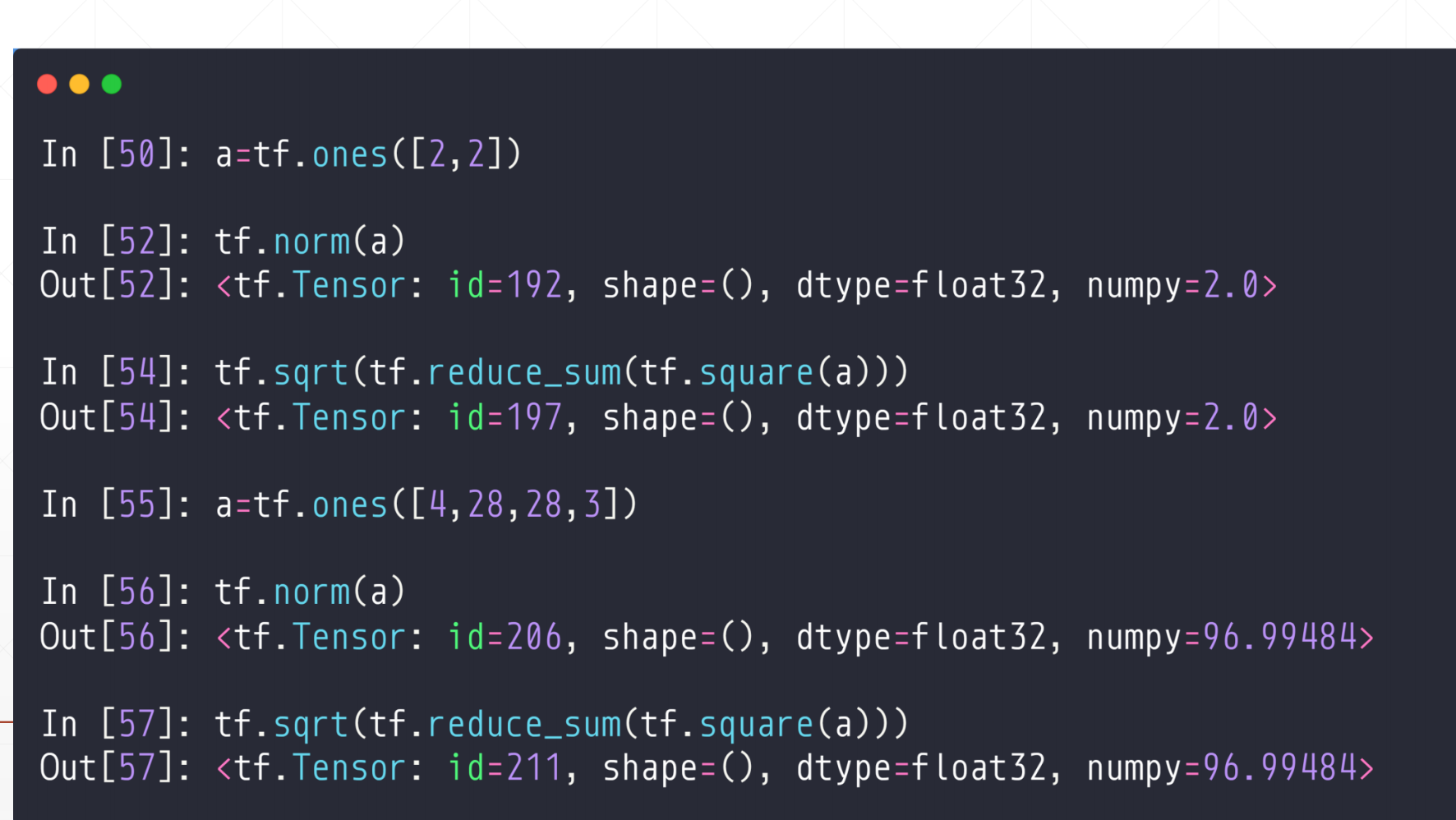
2.1 tf.norm(范数)
这里有三个范数:(二范数、无穷范数、一范数)

tf.norm(a,ord=,axis=)
这里ord取得1/2,ord=1是1范数
ord=2是二范数,不加ord也默认二范数
axis是维度
2.1.1 二范数
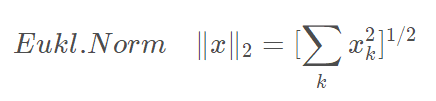
其等价于tf.sqrt(tf.reduce_sum(tf.square(a)))
2.1.2 一范数
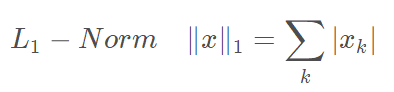
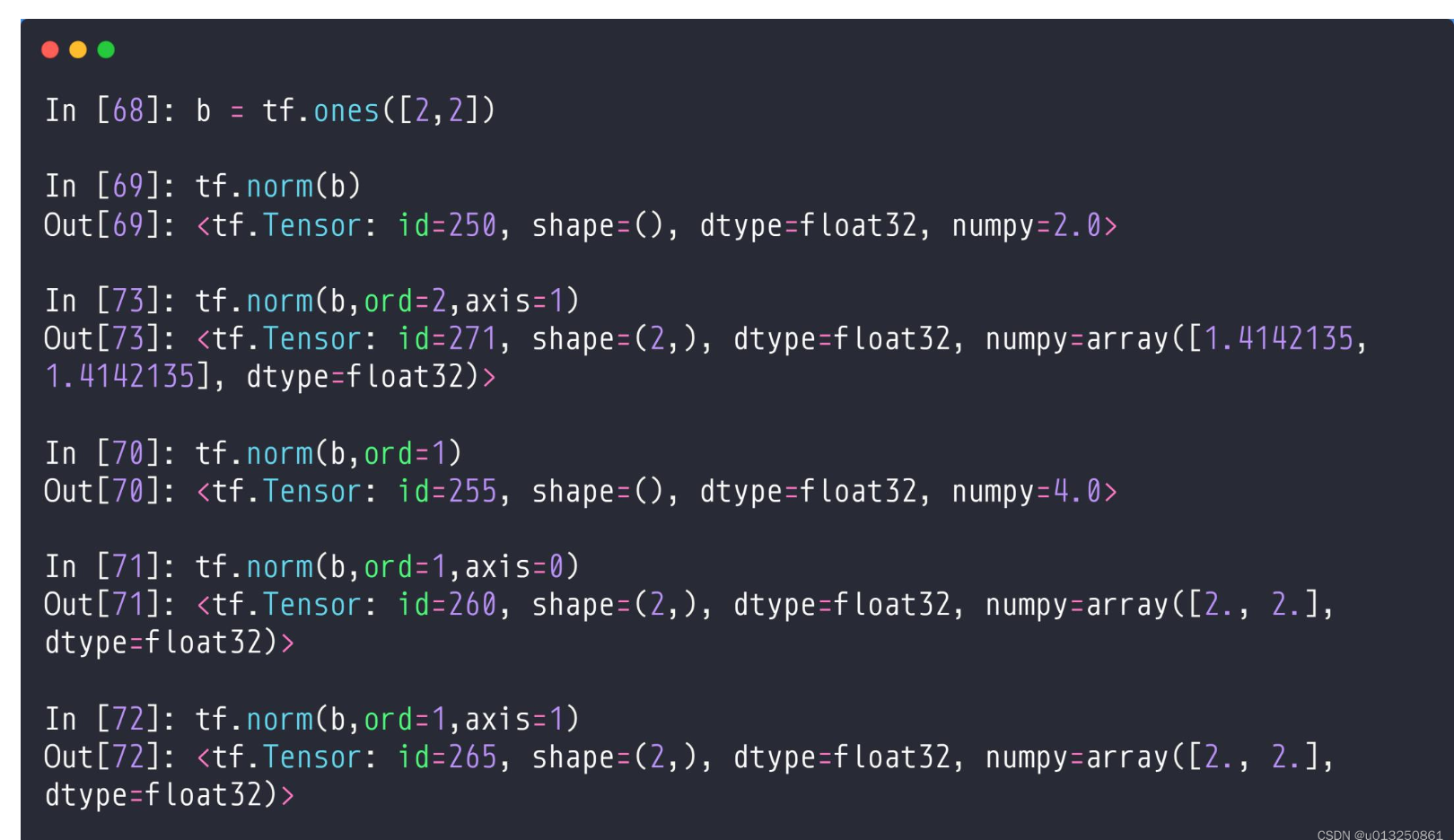
1.这个求b的二范数很好理解
sqrt(1^2+1^2+1^2+1^2)=2
2.tf.norm(b, ord=2, axis=1): ord=2表示求b的二范数,axis=1表示求b中第2个维度的二范数,即:
sqrt(1^2+1^2)=sqrt(2)
但是一共有两个维度,所以得到一个Tensor:[sqrt(2),sqrt(2)]
如果这个tensor=
[[1,2],
[3,4]]是,如果axios=0时,(1,3)是一个整体,(2,4)是一个,
如果axios=1时,(1,2)是一个整体,(3,4)是一个整体
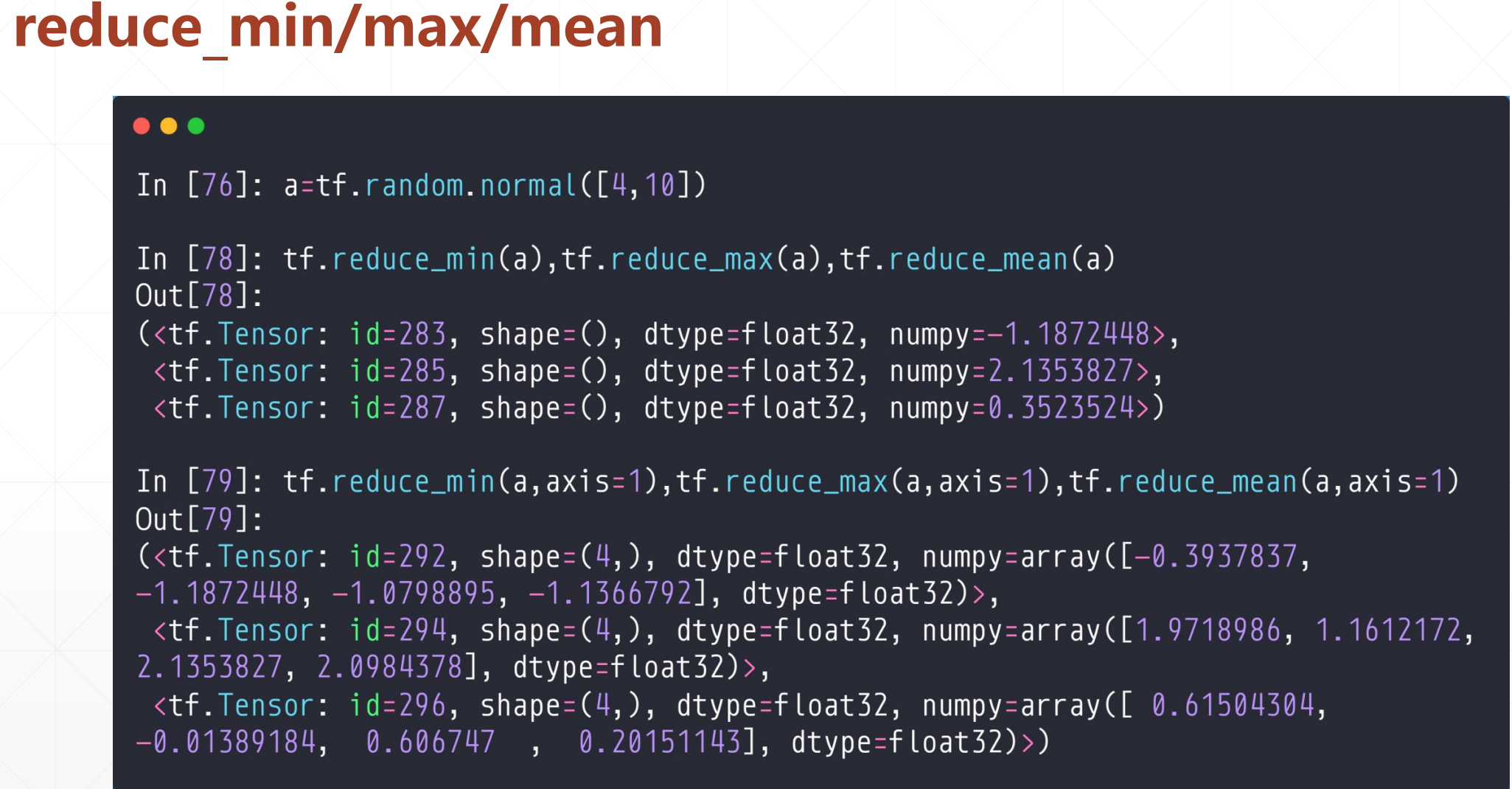
2.2 tf.rduce_min/max/mean
加一个reuce是提醒你有一个降维的操作
tf.random.min(a,axis=)
这个axis如果不加的话,默认求所有的最大值,最小值,平均值
但是如果指定了axis的话会有一个降维的过程,如果axis=0的话,返回每一列的最值,然后一个有多少列,返回多少个
其实就是这样一个操作
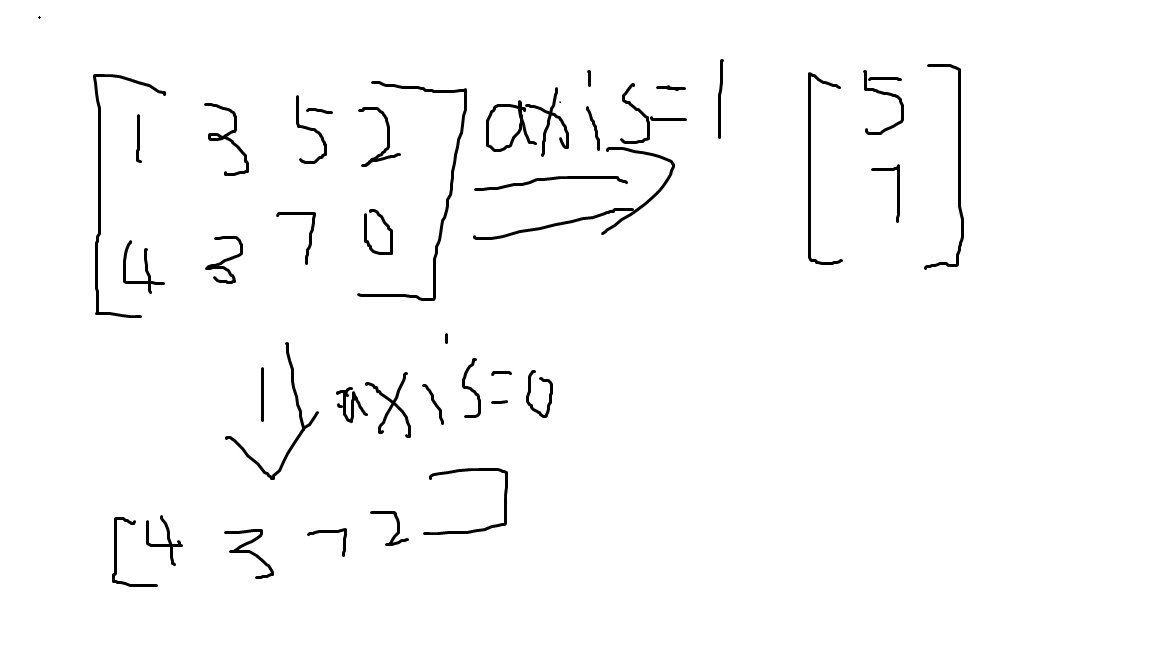
2.3 tf.rduce_min/max/mean
返回最小/最大值所在的位置
这个用法和上面一样,也是需要指定一个维度
如果不指定的话,默认axis=0

2.4 tf.equal
这个是比较两个张量的各个位置是否相等,返回一个Ture/False的相同维度的张量
tf.equal(a,b)
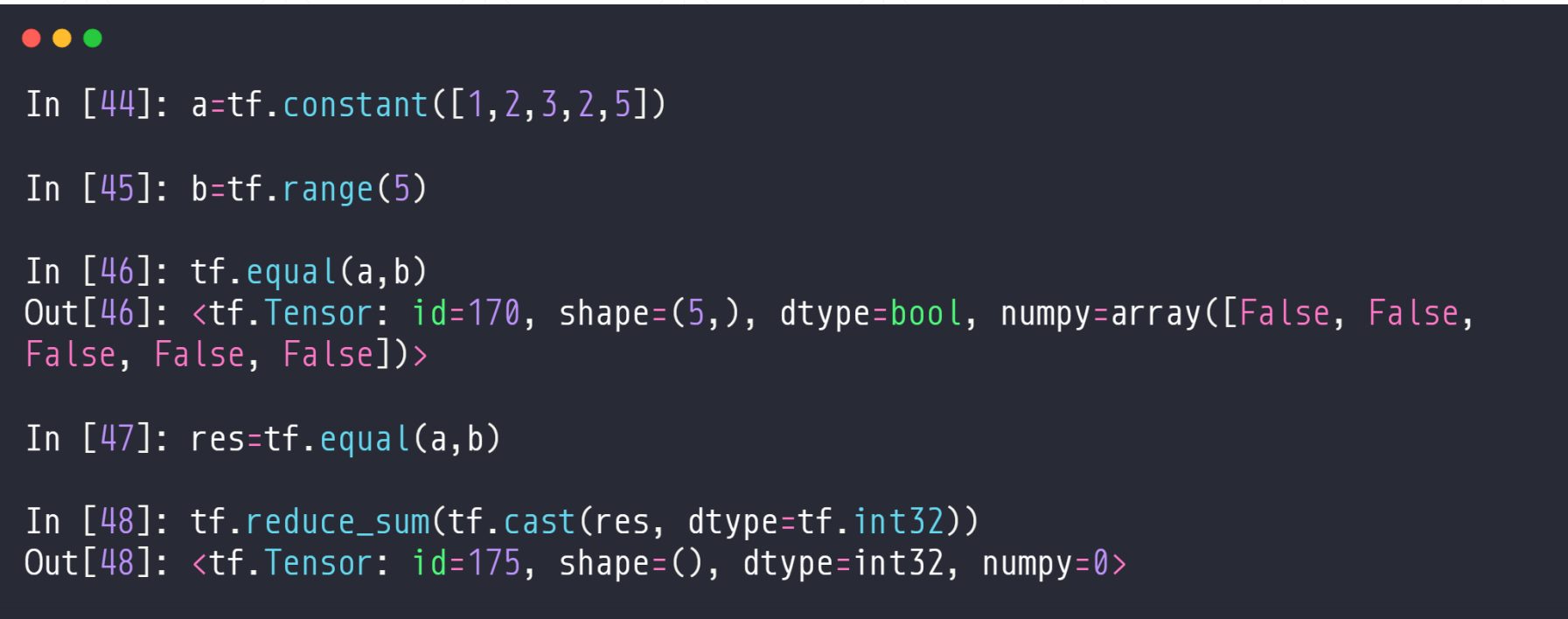
这个tf.cast 是类型转化
2.5 计算Accuracy
这是一个例子:
例如:计算Accuracy:
首先这里
a[[0.1,0.2,0.7],
[0.9,0.05,0.05]]这个是两个样本每个类别的概率,我们去最大的那个。
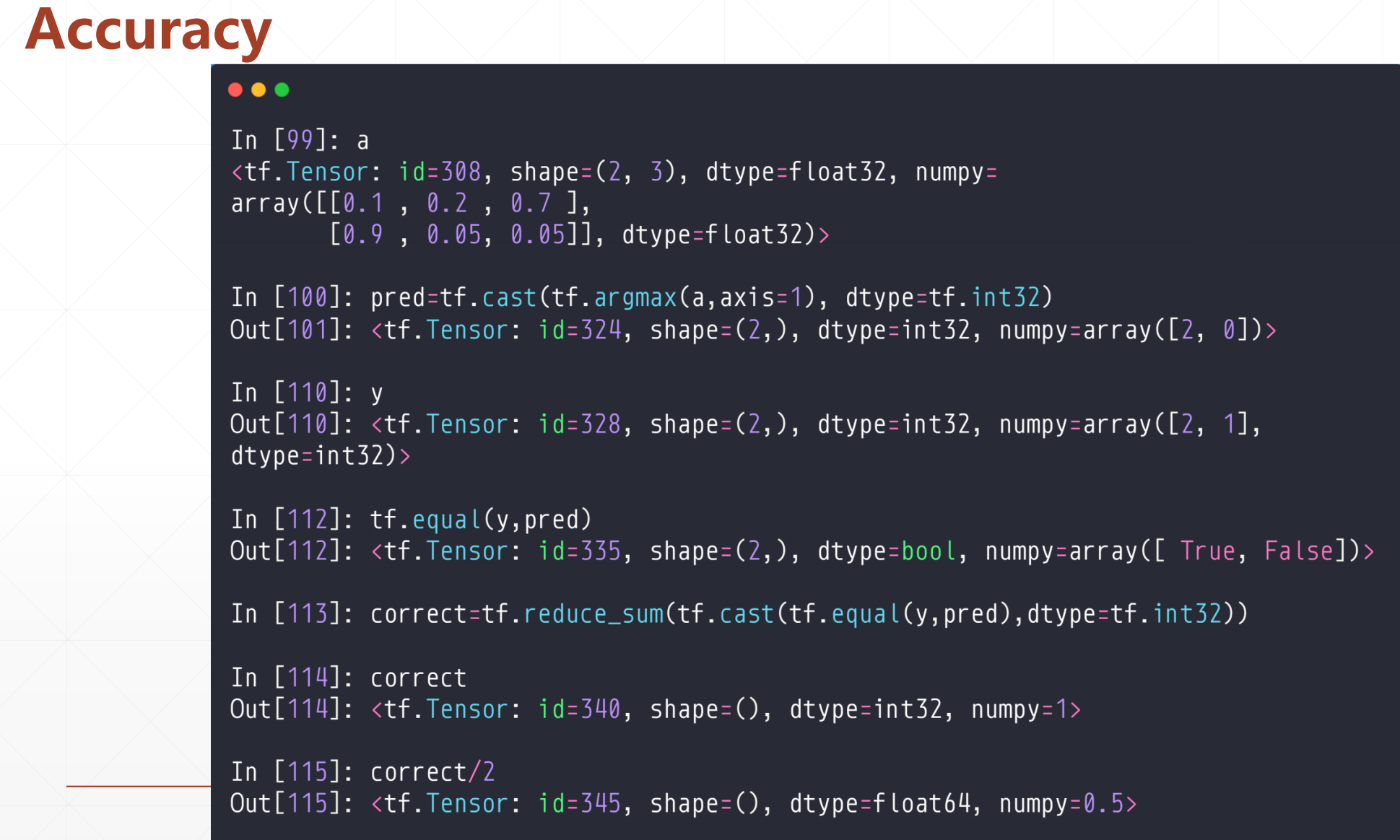
这个tf.cast 是类型转化
2.6 tf.unique
tf.unique(a)
return :两部分
第一部分是:去重之后的数组
第二部分是:原数组在去重之后的数组的下标
例如:
a=tf.constant([4,2,2,4,3])
tf.unique(a)
这里返回两个:
一个是[4,2,3]
另一个是[0,1,1,0,2]
就是原数组在去重之后的数组的下标

这个过程是可逆的,就是:
tf.gather(unique,idx)就可以恢复原来的数组
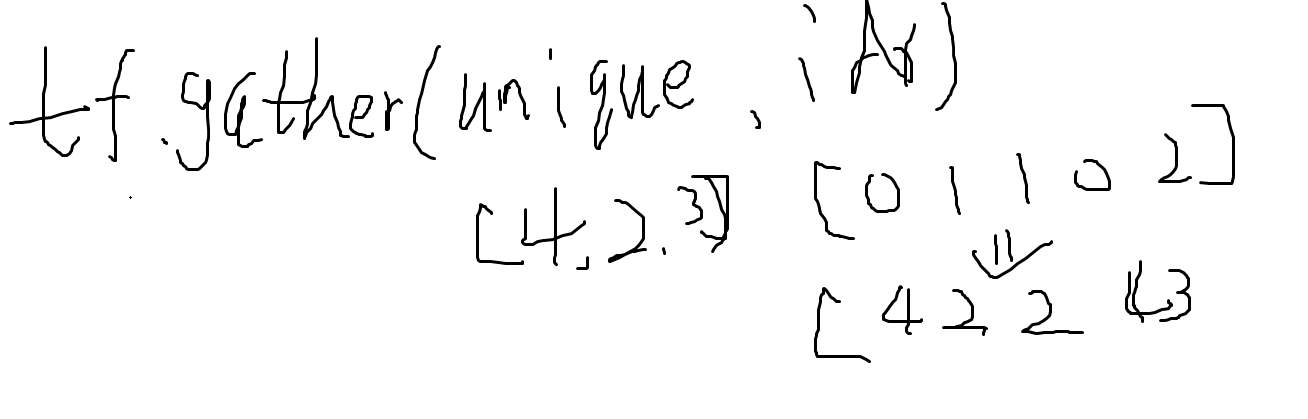
3.张量的排序
▪ Sort/argsort(得到排序后张量/得到排序后位置)
▪ Top_k(前n个排序)
3.1 sort/argsort
这两个都是完全排序,返回的都是对所有的进行排序的。argsort:是返回的最大值所在位置,次大值所在位置,。。。。。最小值所在位置
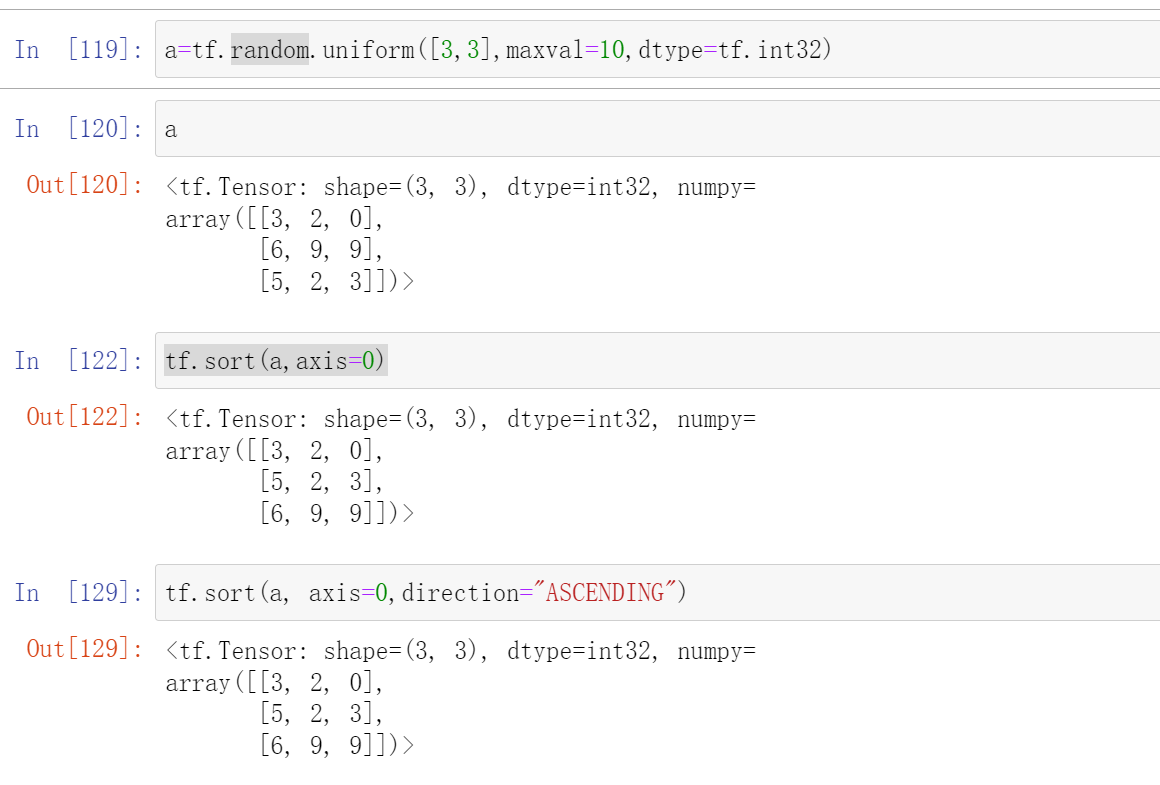
tf.sort(a,axis=,direciton='')
axis是要排序的轴,默认是1,就是对横轴进行排序,如果指定axis=0的话就是按照竖轴进行排序
direction对值进行排序的方向('ASCENDING' 或 'DESCENDING'),增/减
首先我们先看一个简单一点的,一维的:
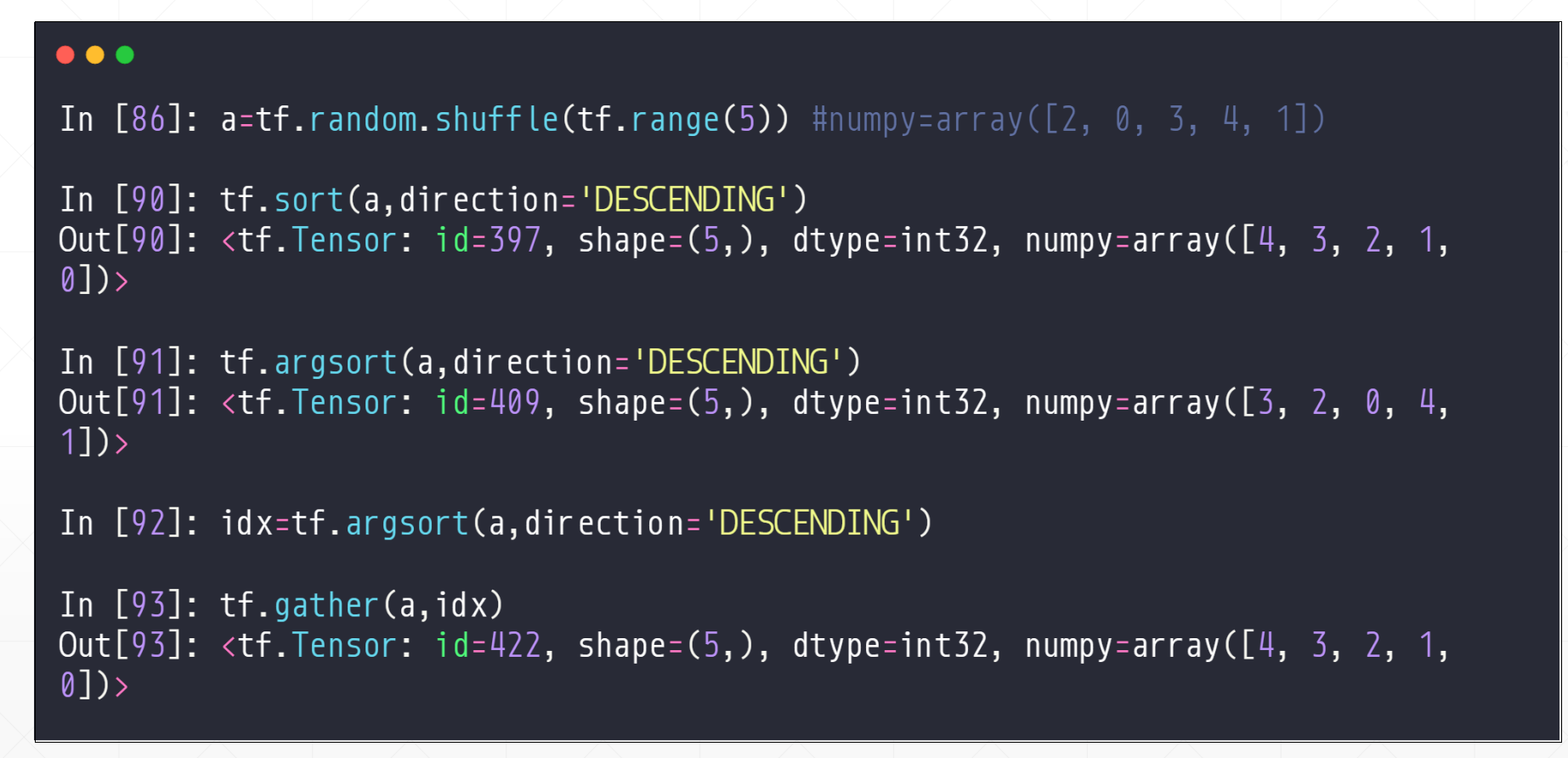
然后就是高维的
3.2 Top_k
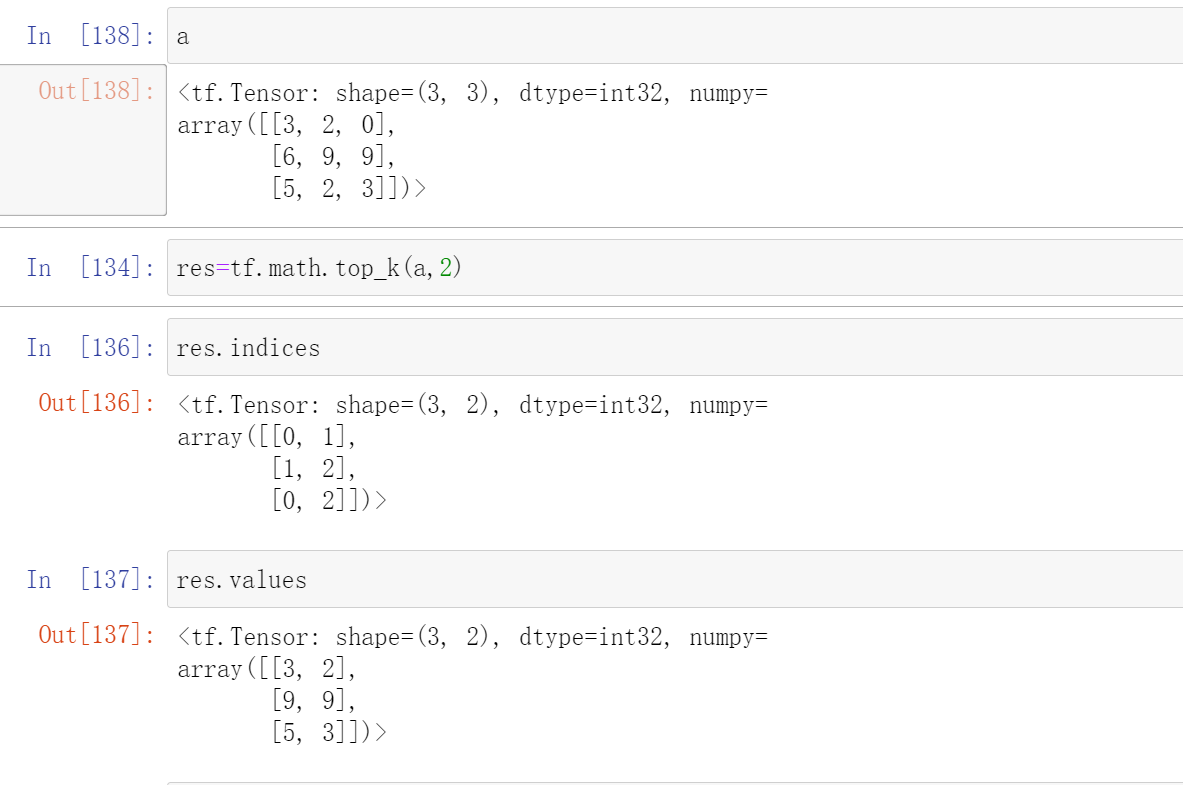
res=tf.math.top_k(a,k)
k是前k个最大值
然后返回的res中两个(res.values和res.indices)
这个res.values是返回的数值
这个res.indices是返回最大值的下标
最有用的一个就是Top-k accuracy

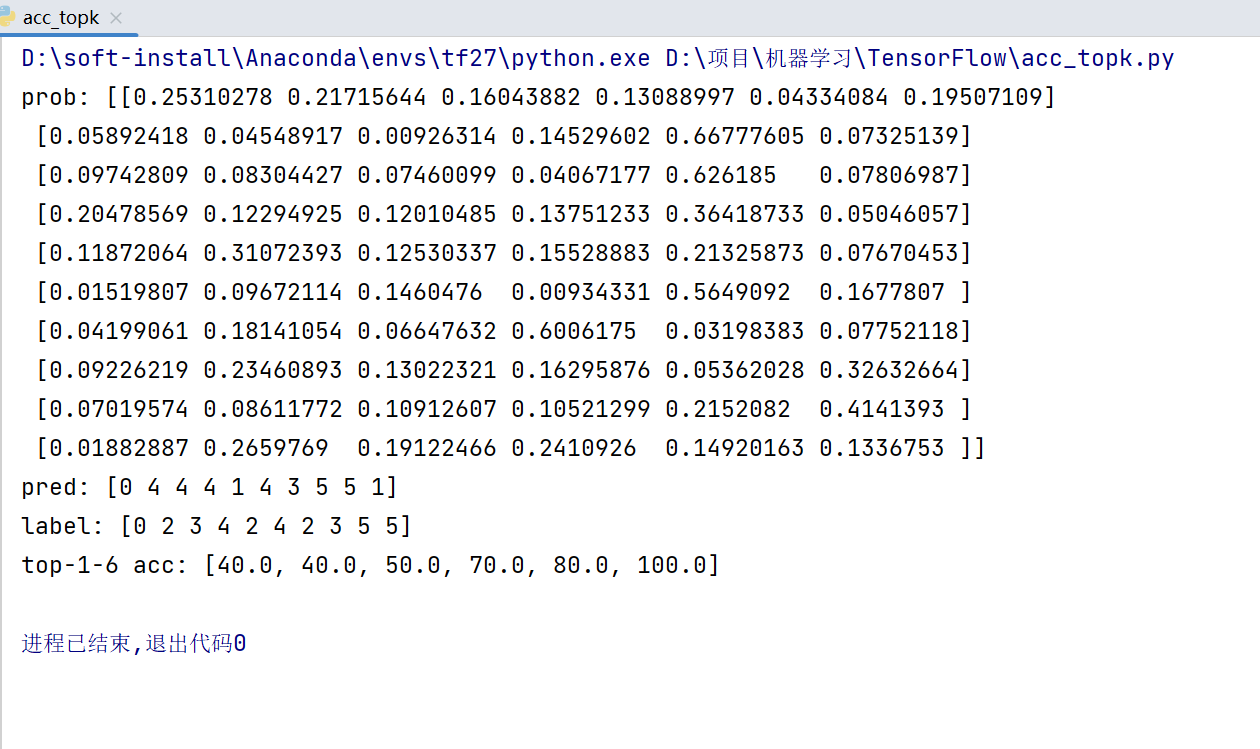
3.3 计算Top-k accuracy(实战)
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(2467)
def accuracy(output, target, topk=()):
maxk = max(topk)
batch_size = target.shape[0]
pred = tf.math.top_k(output, maxk).indices
pred = tf.transpose(pred, perm=[1, 0])
target_ = tf.broadcast_to(target, pred.shape)
# [10, b]
correct = tf.equal(pred, target_)
res = []
for k in topk:
correct_k = tf.cast(tf.reshape(correct[:k], [-1]), dtype=tf.float32)
correct_k = tf.reduce_sum(correct_k)
acc = float(correct_k* (100.0 / batch_size) )
res.append(acc)
return res
output = tf.random.normal([10, 6])
output = tf.math.softmax(output, axis=1)
target = tf.random.uniform([10], maxval=6, dtype=tf.int32)
print('prob:', output.numpy())
pred = tf.argmax(output, axis=1)
print('pred:', pred.numpy())
print('label:', target.numpy())
acc = accuracy(output, target, topk=(1,2,3,4,5,6))
print('top-1-6 acc:', acc)
4 数据的填充与复制
▪ pad(填充)
▪ tile(复制)
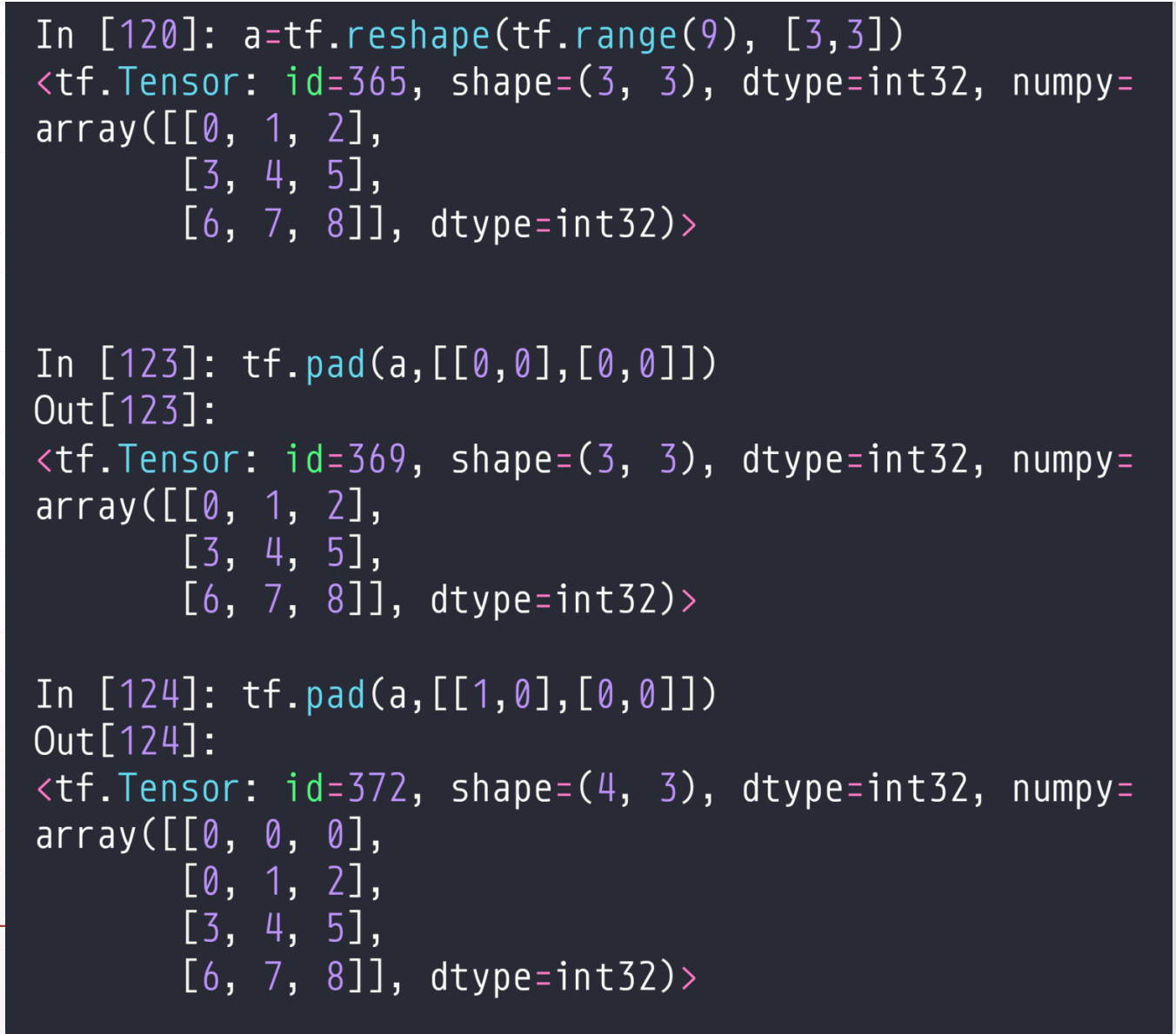
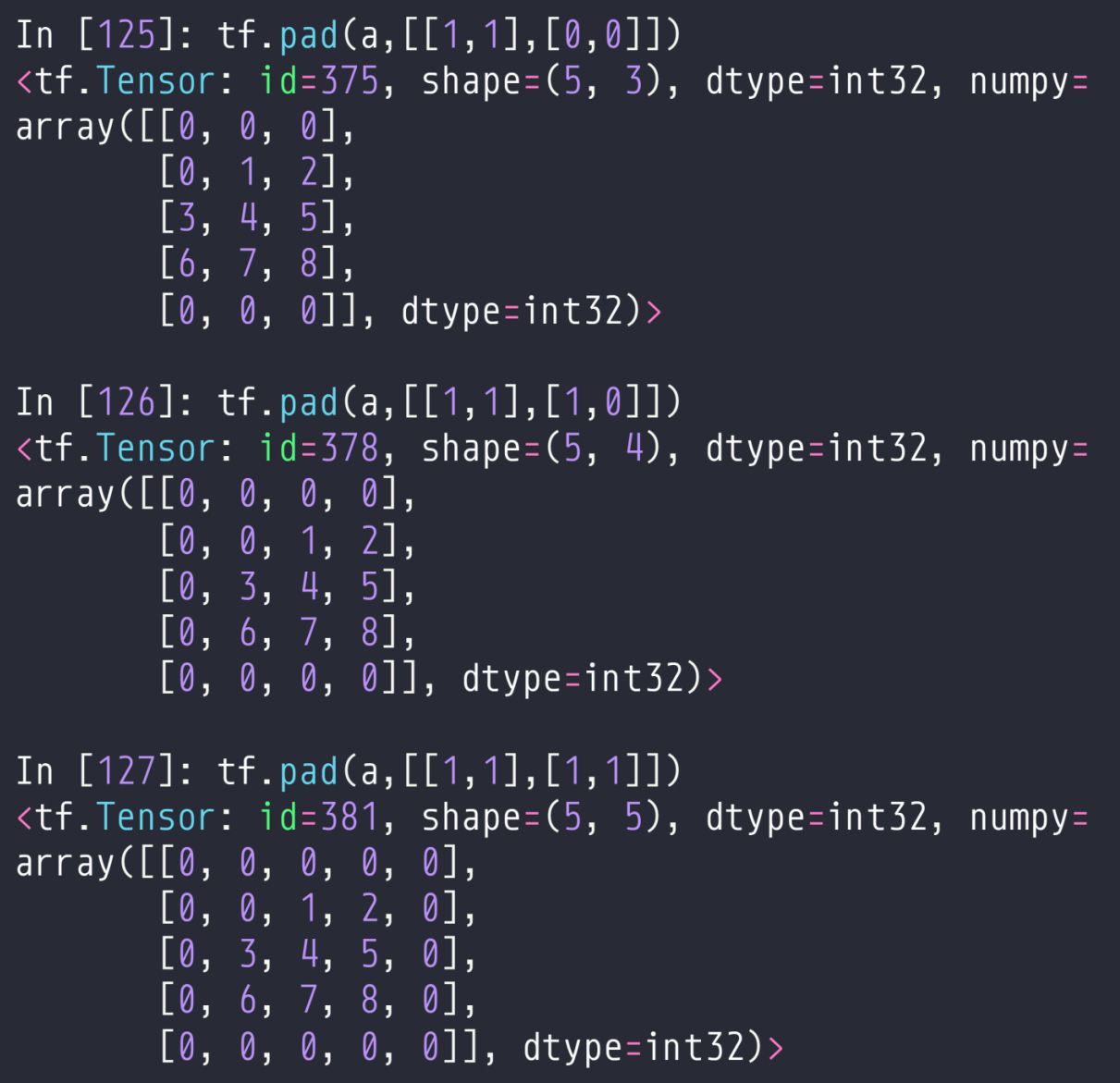
4.1 tf.pad
tf.pad(a,[[],[]])
这个a是待补充的张量,然后就是后面的参数,
如果是一维的[[A,B]],就是左边补充A行,有右边补充B行,
[[A,B],[C,D]],就是上面补充A行,下面补充B行,左边补充C行,右边补充D行
例如:
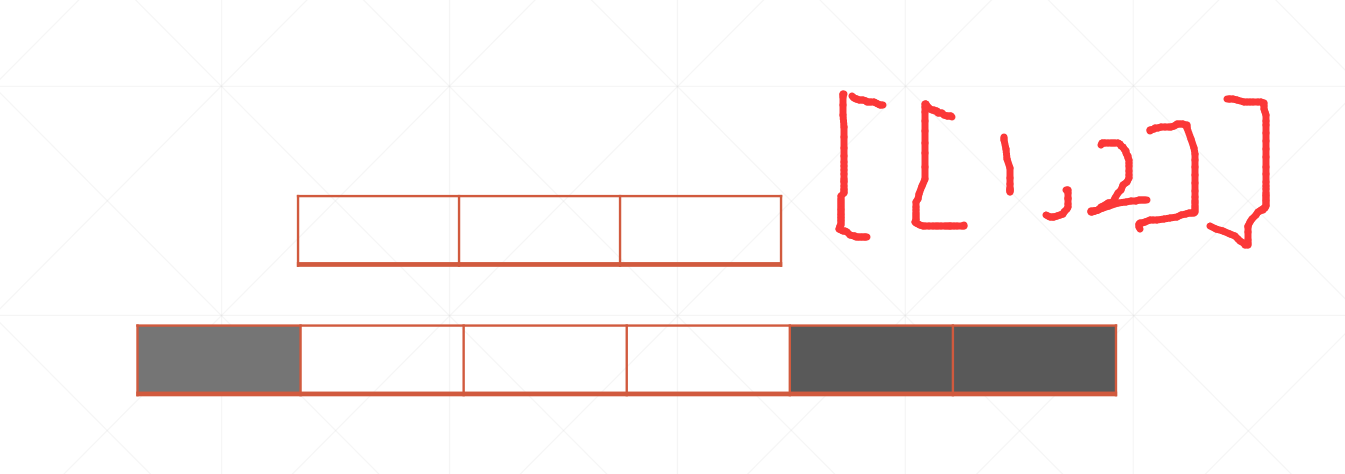
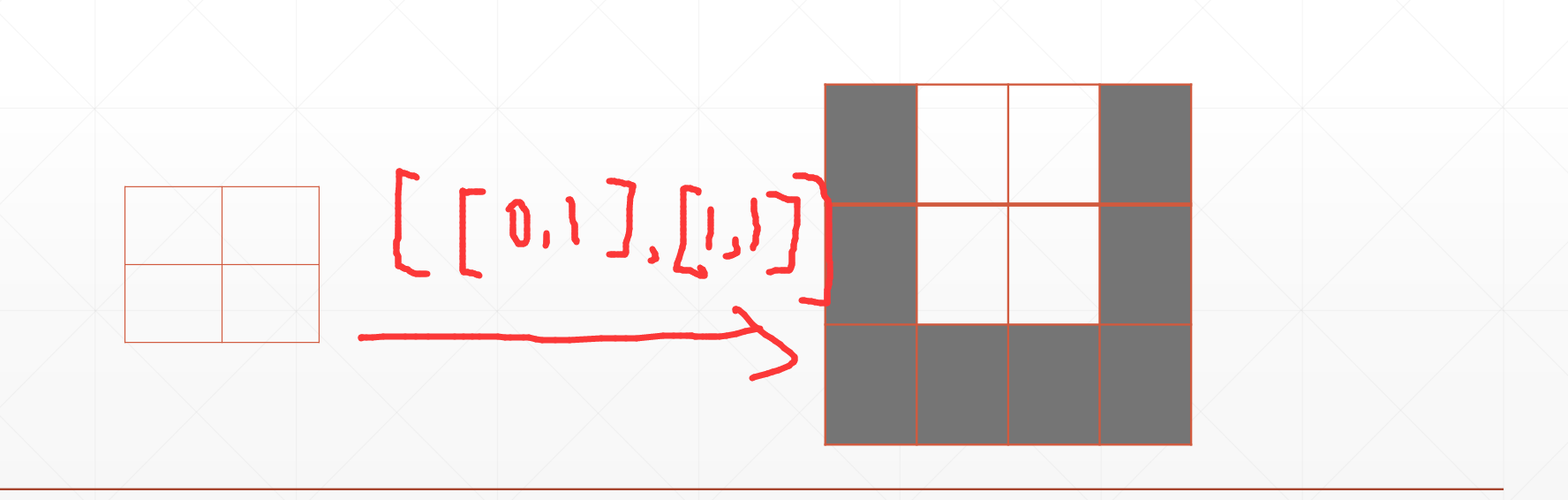
具体实例:
[[上,下],[左,右]]
我们在做NLP是经常用到这个:

4.2 tf.tile
tf.tile(value,[a,b])
这个a代表这个按行复制a倍,b代表按列复制b倍,
如果时1的话,不复制
例如:

tile VS broadcast_to
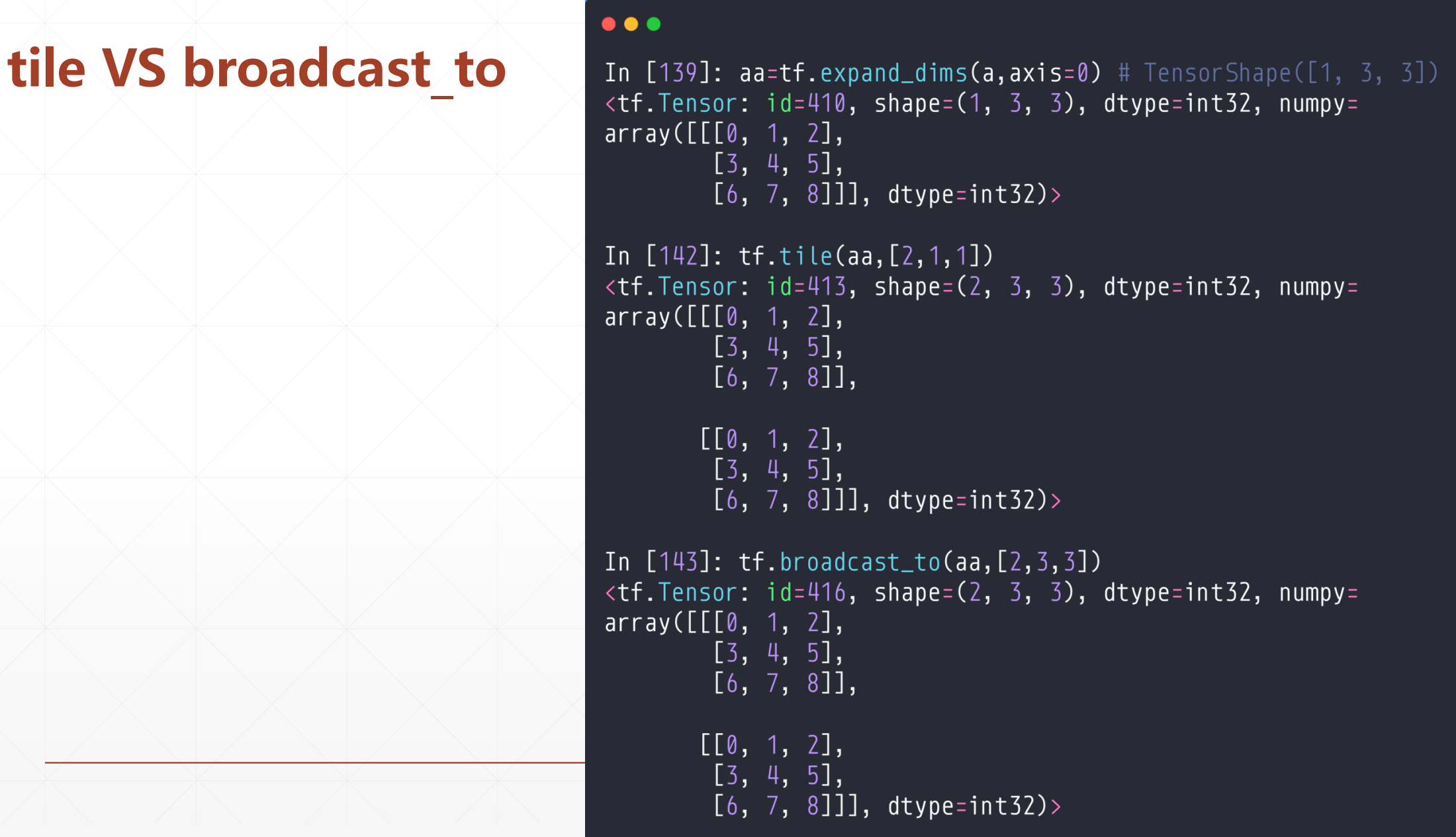
一般用broadcast_to,这个效率更高。对于两个张量相+就支持broadcast_to的,所以对于我们的[5,3]+[3]我们可以直接加
5 张量限幅
▪ clip_by_value(通过数值裁剪掉)
▪ relu
▪ clip_by_norm
▪ gradient clipping
这个relu就是一个经典的张量限幅函数。
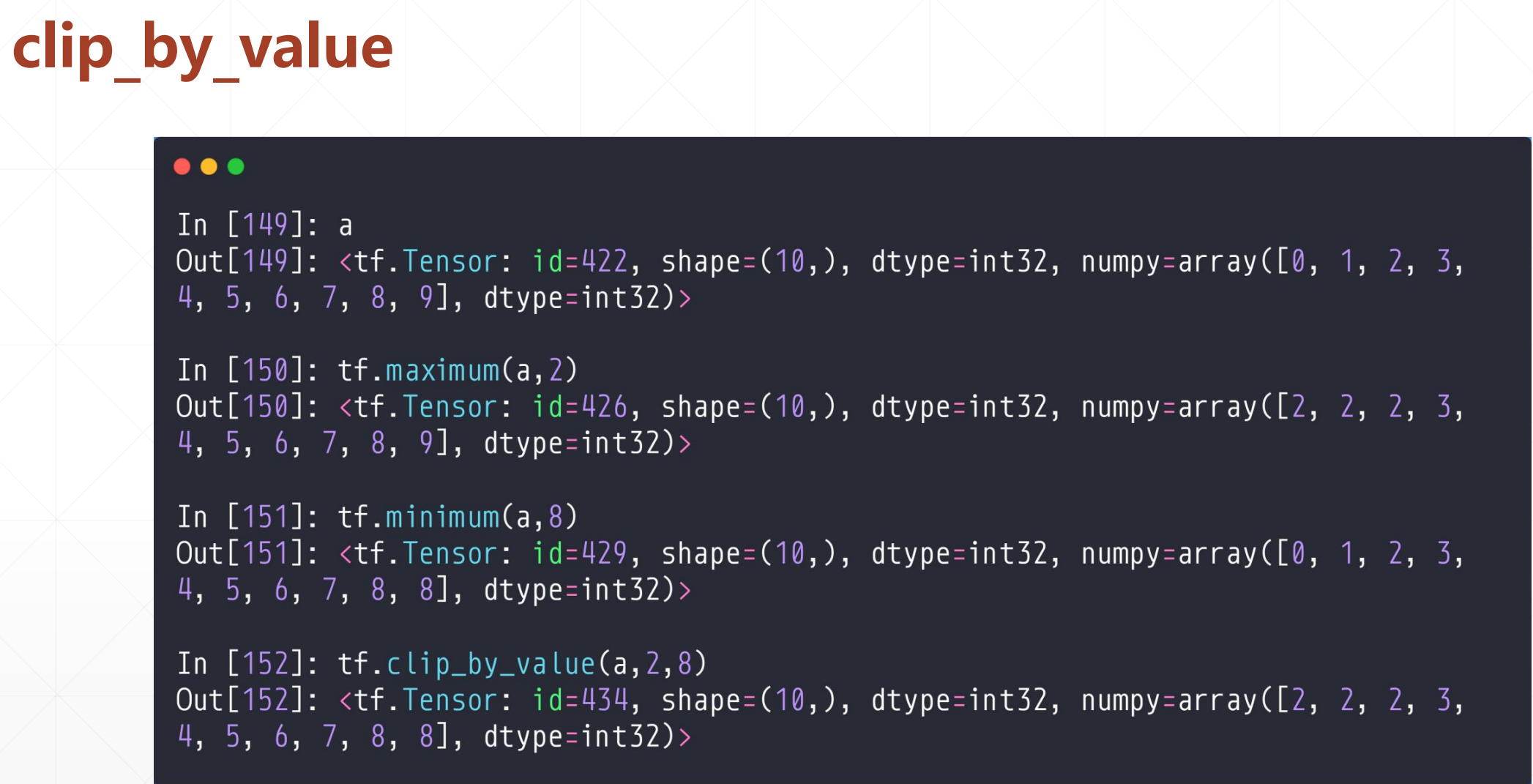
5.1 clip_by_value
tf.maximum(value,2),返回value中如果大于2的话还是原来的数,否则都变成2。
tf.minimum(value,8),返回value中如果小于8的话,还是原来的数,否则变成8
tf.clip_by_value(value,a,b),如果value中大于a和小于b的数不变,小于a的值变成a,大于b的值变成b
5.2 relu
tf.nn.relu(value)
这个就等价于tf.maximum(a,0)
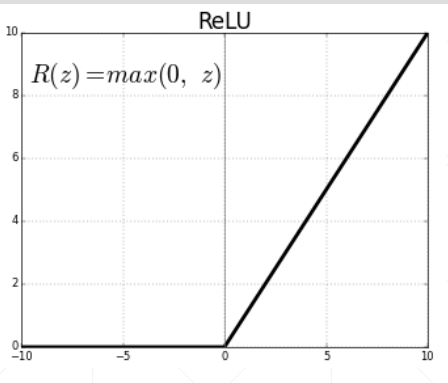
这个relu函数就是小于0的都变成0,否则就是原数。

5.3 clip_by_norm
这个函数就是一个等比例放缩函数([2,4,8]=>[1,2,4]),就是好比一个向量带方向的,然后我们想把这个值变小一点,但是我们不希望改变他的方向,我们就可以用这个函数。
tf.clip_by_norm(a,k)
这个k是新的morm(二范式,也就是每一维的平方和),会在k的左右

这里就是我们变化之后新的norm会在k的左右
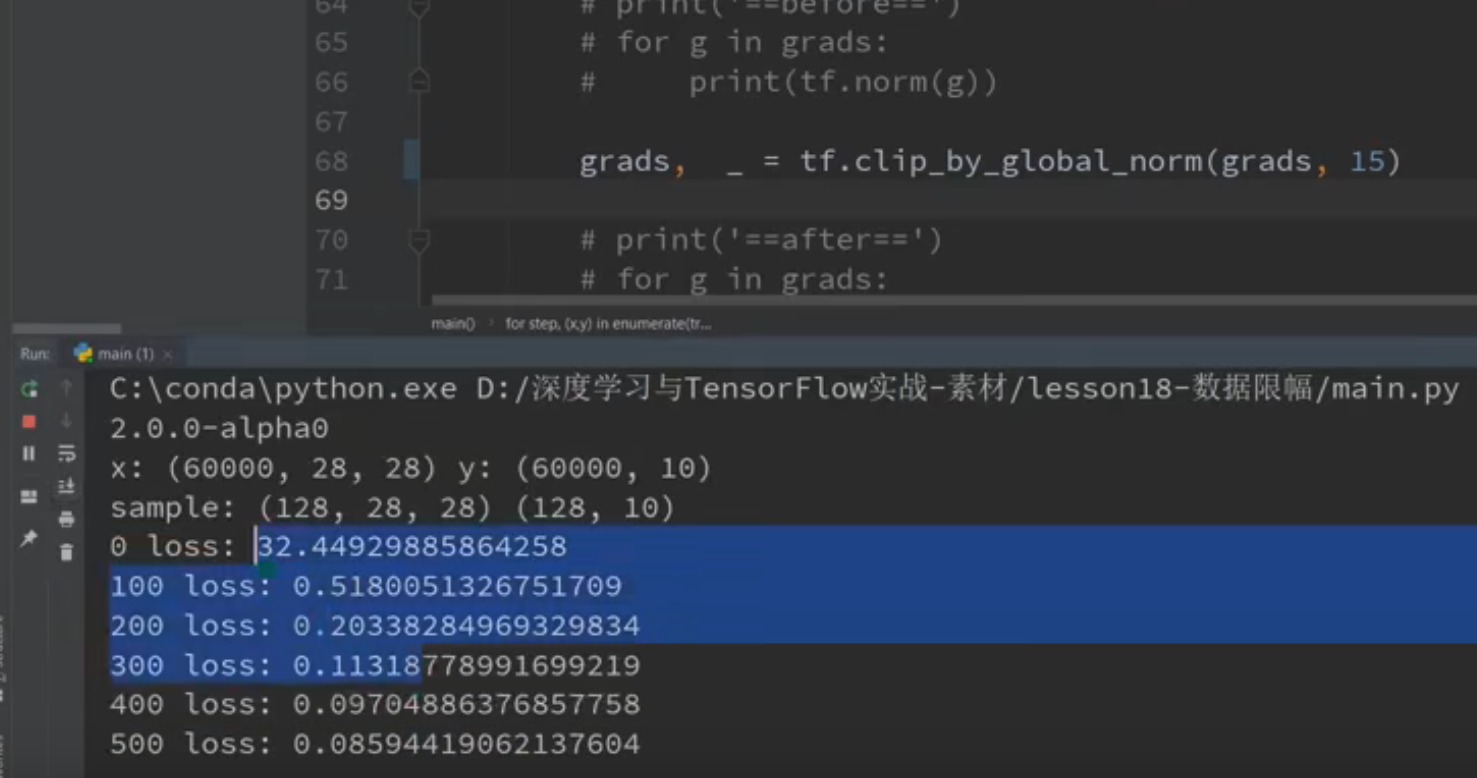
Gradient clipping:
我们在做优化的时候就是让loss不断变小的过程,其中会遇到一些问题:
▪ Gradient Exploding or vanishing(梯度太大或者太小)
这时候我们可以用clip_by_global_norm来进行优化,使得这个网络很稳定
▪ new_grads, total_norm = tf.clip_by_global_norm(grads, 25)
例如:
就是如果不加这个的话他可能会出现梯度爆炸的情况:
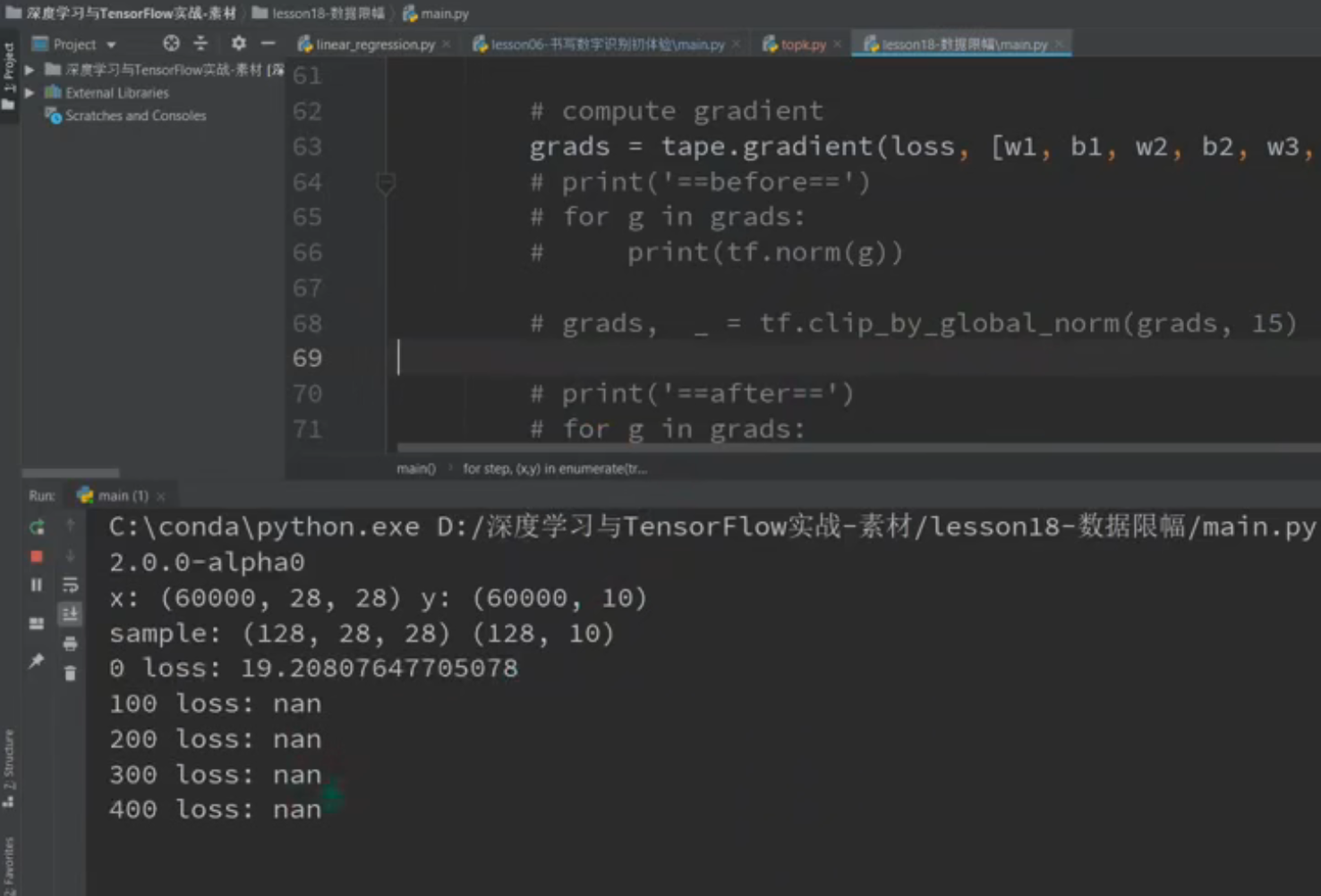
但是我们加了这一句话的话可能会很稳定
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
print(tf.__version__)
(x, y), _ = datasets.mnist.load_data()
x = tf.convert_to_tensor(x, dtype=tf.float32) / 50.
y = tf.convert_to_tensor(y)
y = tf.one_hot(y, depth=10)
print('x:', x.shape, 'y:', y.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128).repeat(30)
x,y = next(iter(train_db))
print('sample:', x.shape, y.shape)
# print(x[0], y[0])
def main():
# 784 => 512
w1, b1 = tf.Variable(tf.random.truncated_normal([784, 512], stddev=0.1)), tf.Variable(tf.zeros([512]))
# 512 => 256
w2, b2 = tf.Variable(tf.random.truncated_normal([512, 256], stddev=0.1)), tf.Variable(tf.zeros([256]))
# 256 => 10
w3, b3 = tf.Variable(tf.random.truncated_normal([256, 10], stddev=0.1)), tf.Variable(tf.zeros([10]))
optimizer = optimizers.SGD(lr=0.01)
for step, (x,y) in enumerate(train_db):
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 784))
with tf.GradientTape() as tape:
# layer1.
h1 = x @ w1 + b1
h1 = tf.nn.relu(h1)
# layer2
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
# output
out = h2 @ w3 + b3
# out = tf.nn.relu(out)
# compute loss
# [b, 10] - [b, 10]
loss = tf.square(y-out)
# [b, 10] => [b]
loss = tf.reduce_mean(loss, axis=1)
# [b] => scalar
loss = tf.reduce_mean(loss)
# compute gradient
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# print('==before==')
# for g in grads:
# print(tf.norm(g))
# grads, _ = tf.clip_by_global_norm(grads, 15)
# print('==after==')
# for g in grads:
# print(tf.norm(g))
# update w' = w - lr*grad
optimizer.apply_gradients(zip(grads, [w1, b1, w2, b2, w3, b3]))
if step % 100 == 0:
print(step, 'loss:', float(loss))
if __name__ == '__main__':
main()
6 高级操作
▪ where(根据坐标目的性的选择)
▪ scatter_nd(根据坐标目的性的跟新)
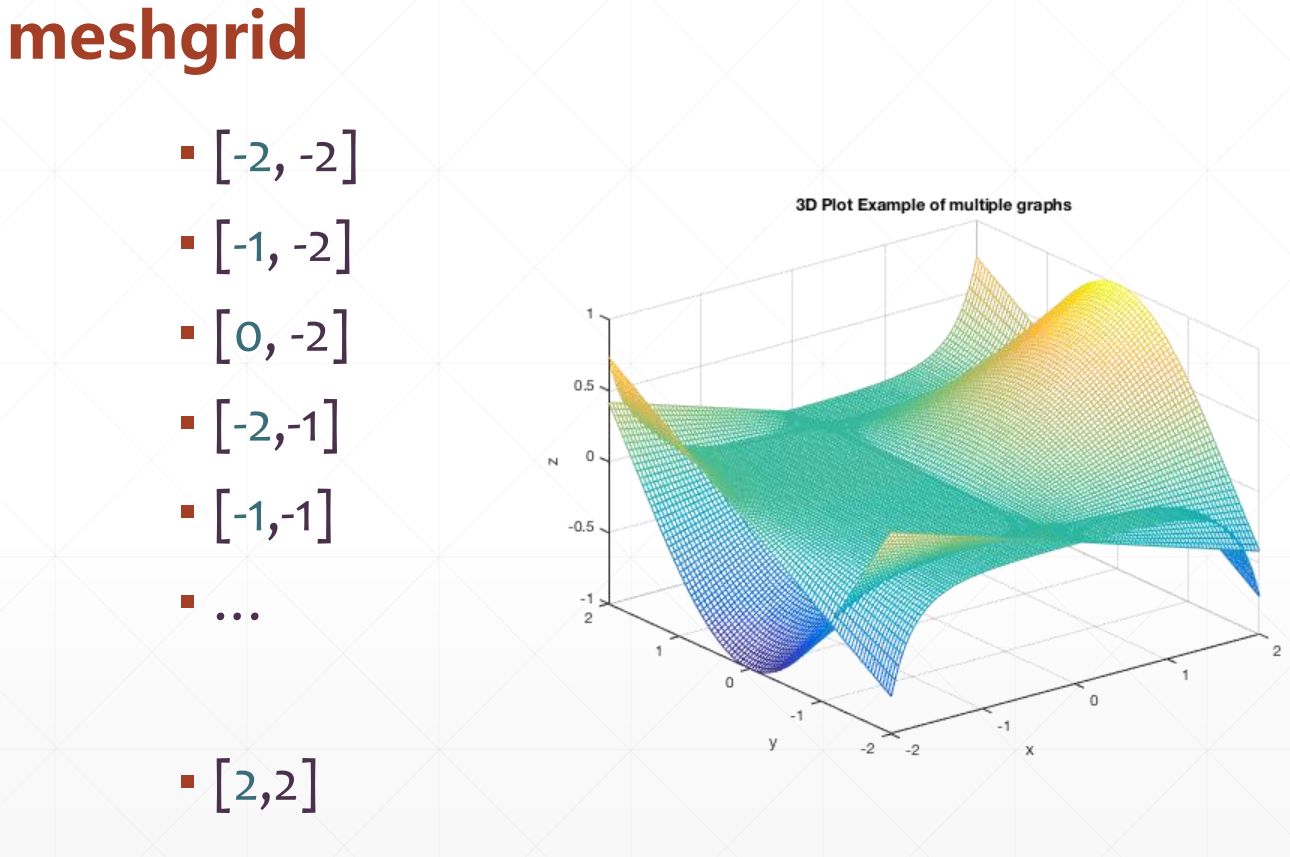
▪ meshgrid(生成坐标系)
6.1 where
where(tensor)
这个tensor里面是一个Ture,False的张量,然后返回Ture所在的位置
例如这个:
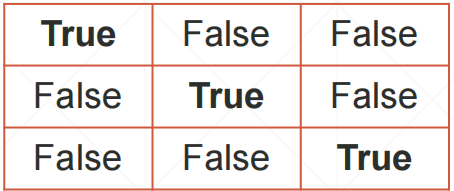
我们就返回一个
indices=
[[0,0]
[1,1]
[2,2]],这是我们会得到这些为Ture的坐标。
然后我们可以通过这个gather_nd(a,indices),来得到这些数。
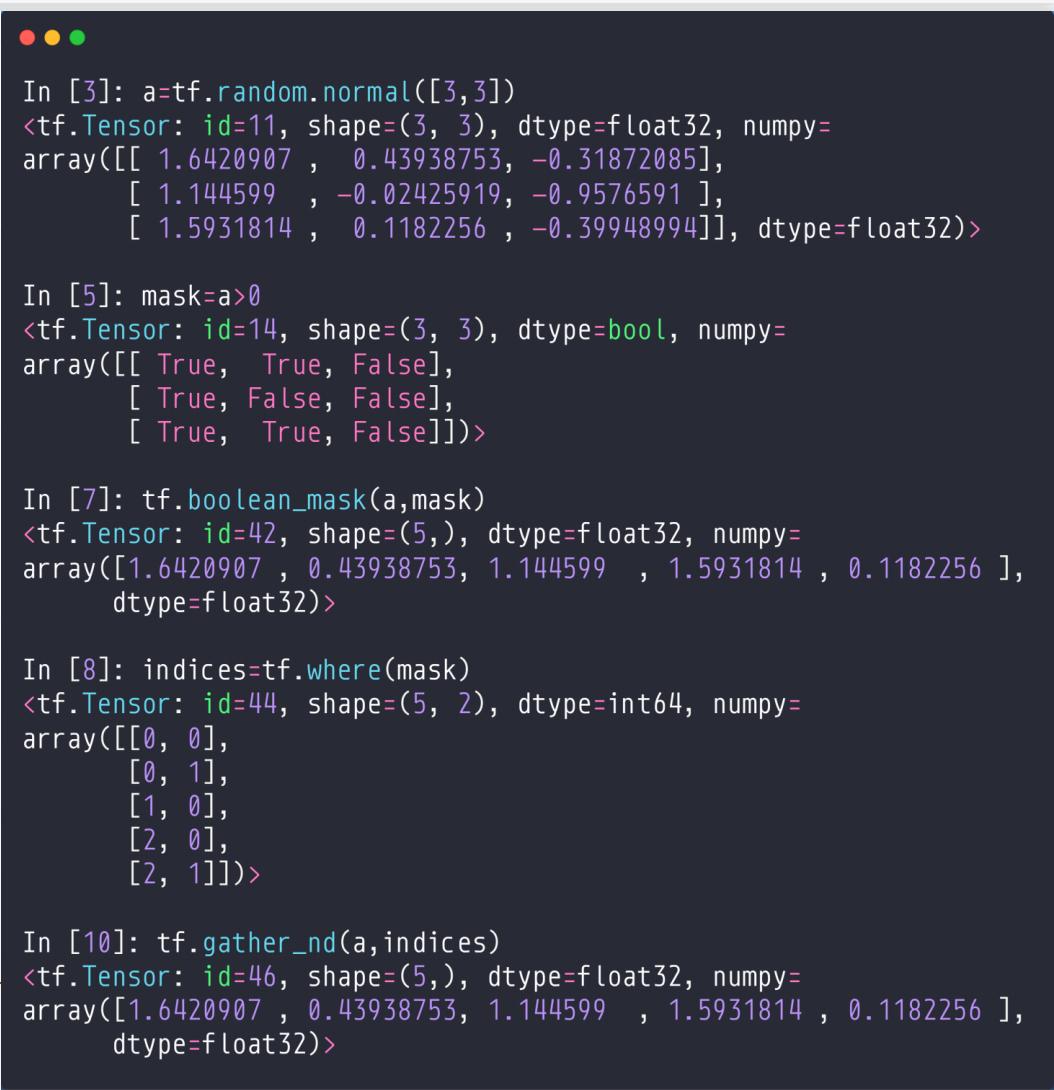
对于上面的代码,我们可以通过tf.boolean_mask(a,mask)来获得,或者我们可以通过先tf.where(mask)和tf.gather_nd(a,indices)
然后我们还有一个API:
where(cond,A,B)
这个首先这个cond是一个True/False的张量,然后如果cond中的某个位置是True的话,我们会从A中选择相应位置,否则从B中选择
例如:
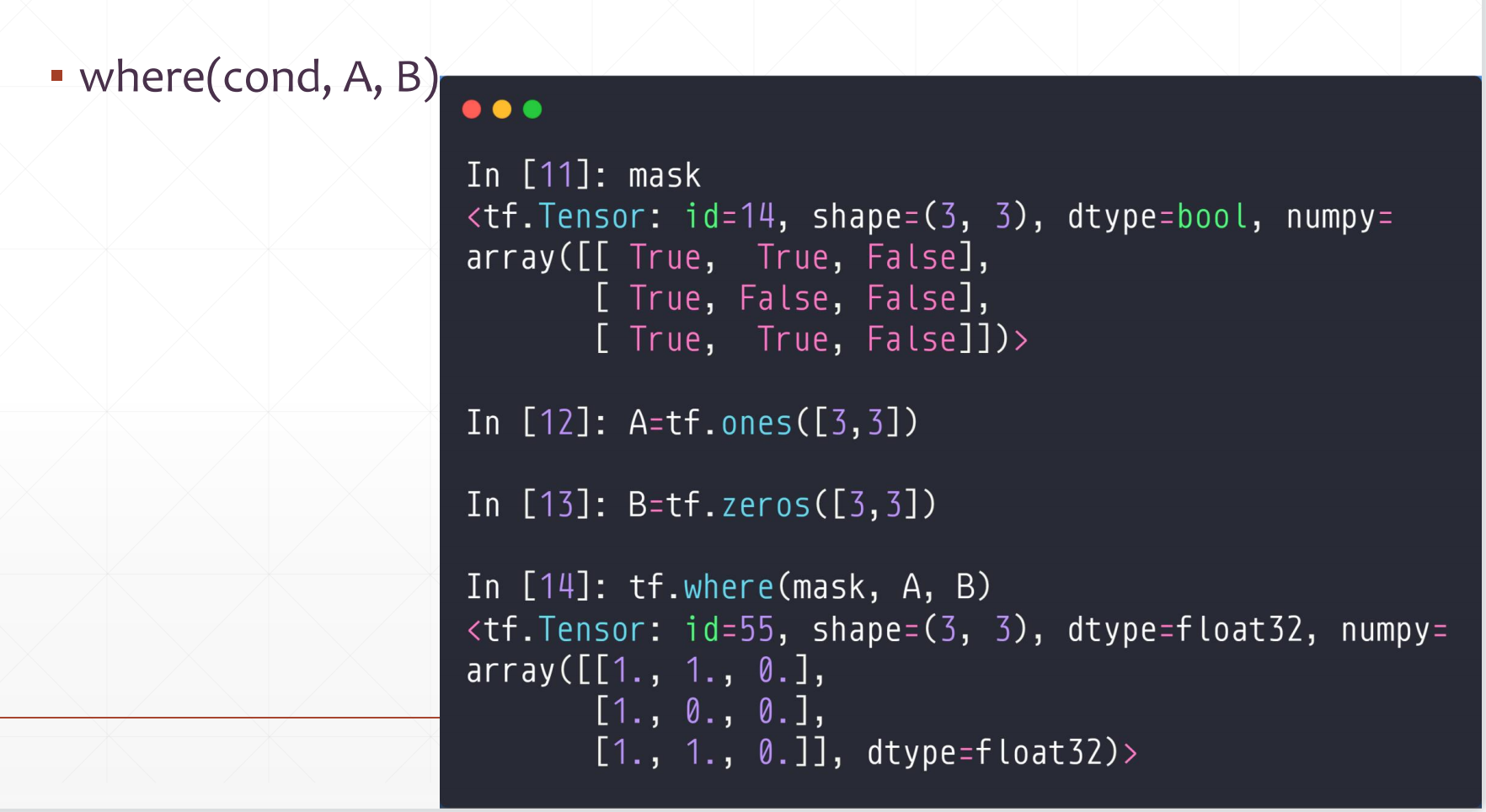
6.2 scatter_nd
tf.scatter_nd(indices,updates,shape)
这个shape相当于一个全为0的底板,然后我们可以根据indices和updates来跟新这个底板
其中indices是坐标,updates是要跟新的值
indices:[[],[],[],[]--[]]坐标
例如:

这个就是第4个位置更新为9,第3个位置更新为10,第1个位置更新为11,第7个位置更新为12
一个2D的例子:
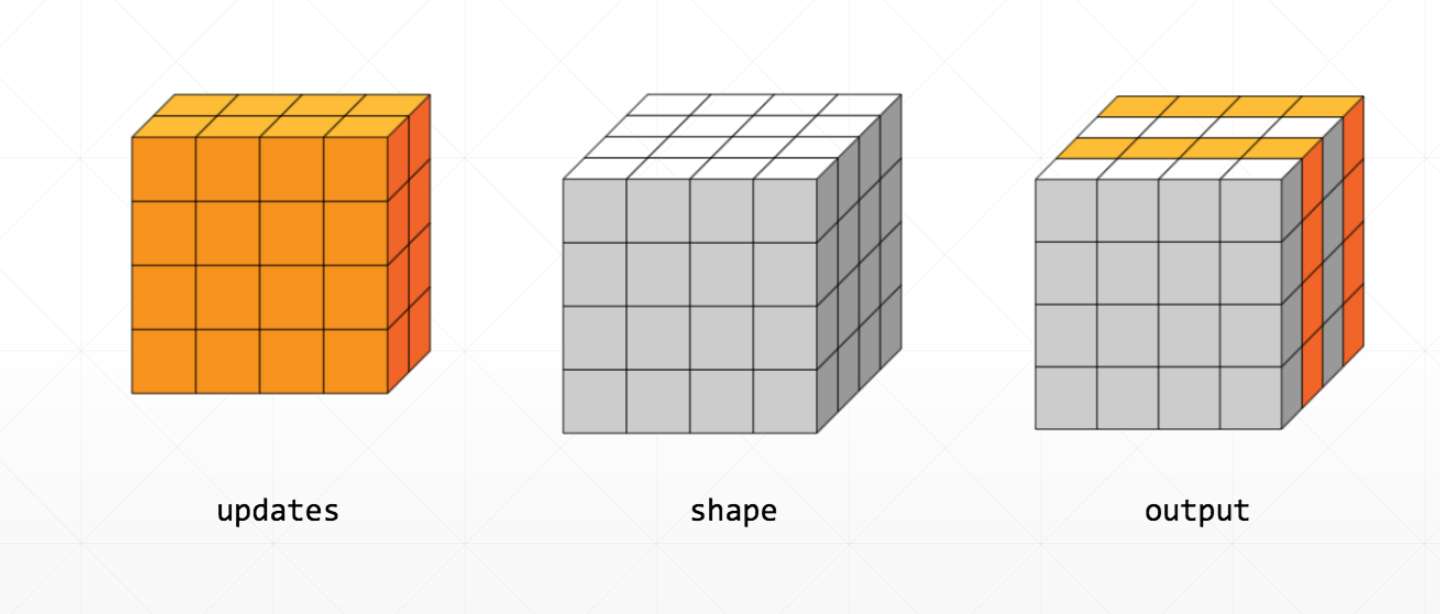
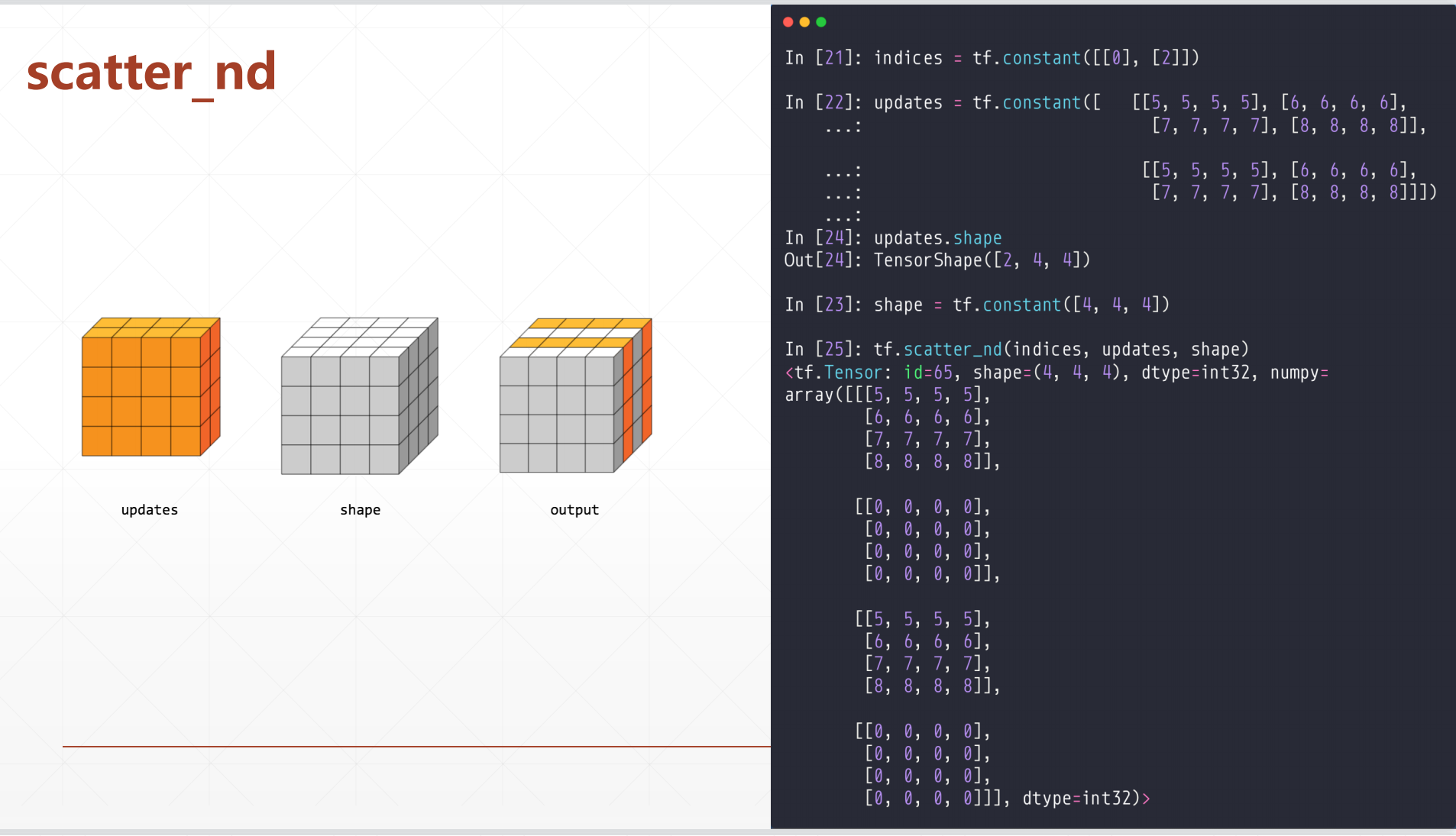
在上面的二维中,我们一开始给了一个indices,这个就是[[0],[2]],这个就相当于a[0]和a[2]。
其中这个a[0]对于了第一个[4,4],a[2]对应了第三个[4,4],总的为[4,4,4]
6.3 meshgrid