一、选题背景
随着当今社会的发展,电影已经成为人们日常生活中不可或缺的一部分。人们通过观看电影来获得娱乐、放松、获取信息以及探索不同的文化和观点。在数字化时代,大量的电影数据被记录和存储,这为电影数据集的分析提供了丰富的资源。而如今,不同国家和地区的电影制作和发行公司在全球市场上展开竞争与合作。通过分析电影数据集,可以了解各个国家和地区的电影市场表现、制片公司的竞争力以及国际间的合作模式。这对于电影行业从业者来说,有助于了解全球市场趋势,制定跨国合作策略和拓展国际市场。目前的电影市场,各种类型和题材的电影层出不穷,以满足不同受众的多样化需求。通过分析电影数据集中的类型、题材和受众反馈,可以了解观众对不同类型电影的喜好和需求,为电影创作者提供指导和灵感。因此,我本次选题为电影数据集的目的,也正是为了能在电影类型,流行度,受众人群,以及评分和收入等方面进行分析从而更好的了解电影行业的发展。
二、大数据分析方案
本数据集的数据内容与数据特征分析:
数据来源于![]() 数据集网站,数据集地址:Full TMDB Movies Dataset 2023 (930K Movies) (kaggle.com)
数据集网站,数据集地址:Full TMDB Movies Dataset 2023 (930K Movies) (kaggle.com)
数据集介绍:名称:TMDB_movie_dataset_v11
步骤一:导入数据集和包
步骤二:对数据进行清洗
步骤三:将数据进行可视化展示
三、数据集介绍
id: 电影的唯一标识符。 imdb_id: 电影在IMDb上的唯一标识符。
title: 电影的标题。 original_title: 电影的原标题。
vote_average: 电影的平均评分。 original_language: 电影的原语言。
vote_count: 投票给该电影的次数。 overview: 电影的概述或剧情简介。
status: 电影的状态,例如“完成”、“制作中”等。 popularity: 电影的流行度或受欢迎程度。
release_date: 电影的发布日期。 poster_path: 海报图片的路径。
revenue: 电影的总收入。 tagline: 电影的标语或宣传语。
runtime: 电影的时长。 genres: 电影的类型或流派,例如“动作”、“喜剧”等。
adult: 表示电影是否包含成人内容。 production_companies: 制作电影的公司或组织。
backdrop_path: 背景图片的路径。 production_countries: 制作电影的国家或地区。
budget: 电影的预算。 spoken_languages: 电影中使用的语言。
homepage: 电影的主页链接。
四、代码以及功能介绍:
第一步:清洗数据:将数据中的异常数据,错误数据给修正,保证后续数据的准确性
1 import pandas as pd 2 3 # 读取电影数据集 4 data = pd.read_csv("TMDB_movie_dataset_v11.csv") 5 # 清洗数据 6 data['title'] = data['title'].str.strip() # 去除标题两侧的空格 7 data['release_date'] = pd.to_datetime(data['release_date'], errors='coerce') # 将发布日期转换为日期类型 8 data['genres'] = data['genres'].str.split('|') # 将类型或流派分割为列表 9 10 # 打印清洗后的数据集 11 print(data.head())
运行截图:

第二步:数据分析
1.
1 from matplotlib import pyplot as plt 2 plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"] 3 plt.rcParams['axes.unicode_minus'] = False 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import seaborn as sns 8 from scipy import stats 9 10 # 读取数据 11 df = pd.read_csv('TMDB_movie_dataset_v11.csv',nrows=500) 12 13 # 数据清洗 14 # 假设revenue和budget列没有缺失值 15 df['revenue'] = df['revenue'].replace([np.inf, -np.inf], np.nan) 16 df['budget'] = df['budget'].replace([np.inf, -np.inf], np.nan) 17 df = df.dropna(subset=['revenue', 'budget']) # 删除含有缺失值的行 18 19 # 描述性统计 20 print("票房收入的描述性统计:") 21 print(df['revenue'].describe()) 22 23 print("\n预算的描述性统计:") 24 print(df['budget'].describe()) 25 26 # 图表: 散点图和线性拟合线 27 x = df['budget'] 28 y = df['revenue'] 29 slope, intercept, _, _, _ = stats.linregress(x, y) # 计算斜率和截距 30 line = slope * x + intercept # 计算线性拟合线 31 plt.scatter(x, y) # 散点图 32 plt.plot(x, line, color='red') # 线性拟合线 33 plt.xlabel('电影预算') 34 plt.ylabel('电影票房收入') 35 plt.title('电影票房收入与预算的散点图和线性拟合线') 36 plt.show() 37 38 # 图表: 箱线图 (显示异常值) 39 plt.boxplot([df['revenue'], df['budget']], vert=False) # 箱线图,vert=False表示水平放置箱线图 40 plt.title('电影票房收入与预算的箱线图') 41 plt.show()
运行截图:
:


数据分析:
首先进行描述性统计分析,分别输出了'revenue'(票房收入)和'budget'(预算)列的描述性统计结果,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。从中我们得知了较大的标准差说明票房收入或预算的差异较大,大值远大于最小值,说明存在一些高票房或高预算的电影。而25%分位数和75%分位数两者之间的距离较大,说明数据分布较为分散。从散点图中也能反映出数据的分布较为广泛。
然后是散点图和线性拟合线,将'budget'列作为x轴数据,'revenue'列作为y轴数据。使用stats.linregress()函数计算斜率和截距,然后根据线性方程计算线性拟合线的y值,使用plt.plot()函数绘制线性拟合线,设置横轴和纵轴的标签,以及图表标题,并使用plt.show()函数显示图表。从拟合线的形成方式来看,该数据的电影票房收入和电影的预算呈一元一次方程正比趋势增长
第三张是箱线图,设置vert=False以水平放置箱线图。这样可以观察到数据的中位数、上下四分位数、异常值等信息
2.
1 vote_average = data['vote_average'] 2 mean = vote_average.mean() 3 median = vote_average.median() 4 std = vote_average.std() 5 6 # 打印统计结果 7 print("平均值:", mean) 8 print("中位数:", median) 9 print("标准差:", std) 10 11 # 绘制直方图 12 plt.hist(vote_average, bins=10, edgecolor='k', color='skyblue') 13 14 # 添加标题和标签 15 plt.xlabel('评分') 16 plt.ylabel('电影数量') 17 plt.title('电影评分分布直方图') 18 19 # 添加数据标签 20 plt.text(x=mean, y=130, s=f'平均值: {mean:.2f}', color='black', ha='center') 21 plt.text(x=median, y=120, s=f'中位数: {median:.2f}', color='red', ha='center') 22 plt.text(x=mean - std, y=110, s=f'标准差: {std:.2f}', color='green', ha='center') 23 24 # 显示图像 25 plt.show() 26 27 # 绘制箱线图 28 sns.boxplot(x=vote_average, color='skyblue') 29 30 # 添加标题和标签 31 plt.xlabel('评分') 32 plt.title('电影评分分布箱线图') 33 34 # 显示图像 35 plt.show()
运行截图:


数据分析:平均值提供了电影评分的平均水平。作为评估整体电影质量的指标,7.1的平均分也可以用来作为一个评判标准
中位数,也是评分的中间值,反映了评分的中心趋势。与平均值相比,中位数对于受到极端评分影响较小,比如评分表中的前两列电影数量过于低,但中位数收到的影响相对于平均数来说更小
该直方图展示了不同评分区间的电影数量分布情况,总体来看与计算出的平均数相吻合,通过箱线图,我们可以观察到评分的集中趋势、离散程度,中间的那根线也代表着中位线,与之前的计算值正好对应。
3.
1 # 获取status列中的唯一值数量 2 num_statuses = len(df['status'].unique()) 3 # 创建一个标签列表,确保其长度与status列中的唯一值数量相匹配 4 labels = df['status'].unique().tolist() 5 6 # 散点图:平均评分与流行度之间的关系 7 plt.scatter(df['vote_average'], df['popularity']) 8 plt.xlabel('平均评分') 9 plt.ylabel('流行度') 10 plt.title('平均评分与流行度之间的关系') 11 plt.show() 12 13 # 显示图例在饼图的右侧,并使用正确的标签名和位置参数 14 plt.legend(labels + percentages, loc='center left', bbox_to_anchor=(1, 0.5)) # 在饼图的右侧显示图例,并使用正确的标签名和位置参数 15 plt.show()
运行截图:

数据分析:从散点图来看,电影的流行度随着平均评分的增长而增长,峰值在平均数7-8之间,这些数据可以帮助研究人员和相关从业者了解电影评分与流行度之间的关系,以及电影数据集中不同状态的分布情况。这有助于指导电影制作、评价和推广策略的制定。
4.
1 # 将电影类型拆分为单独的类别 2 genres = df['genres'].str.split(',', expand=True).stack().str.strip().value_counts() 3 4 # 创建饼图 5 fig, ax = plt.subplots(figsize=(8, 8)) 6 _, texts, autotexts = ax.pie(genres, labels=genres.index, autopct='%1.1f%%', startangle=90) 7 ax.axis('equal') 8 ax.set_title('电影类型的分布情况') 9 10 # 自定义图例标签 11 labels = [f'{text.get_text()} ({genre:.1f}%)' for text, genre in zip(texts, genres)] 12 13 # 设置图例 14 plt.legend(labels, loc='center right', bbox_to_anchor=(1.5, 0.5)) 15 16 # 设置自动标签的颜色和字体样式 17 for autotext in autotexts: 18 autotext.set_color('white') 19 autotext.set_fontsize(12) 20 autotext.set_fontweight('bold') 21 22 plt.show()
运行截图:

数据分析:该饼图展示出了电影类型的分布情况,作为主体的类型还是以Drama(戏剧),Documentary(纪录片),Comedy(喜剧)作为主要类型,三者占据整个电影类型的一半以上
5.
genres = data['genres'].str.split(',', expand=True).stack().value_counts().head(10) plt.figure(figsize=(10, 6)) ax = sns.barplot(x=genres.index, y=genres.values, palette="Blues_r") plt.title('Top 10 Most Popular Genres') plt.xlabel('Genres') plt.ylabel('Number of Movies') plt.xticks(rotation=45) # 添加数据标签 for p in ax.patches: ax.annotate(f"{p.get_height()}", (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points') plt.tight_layout() plt.show()
运行截图:

数据分析:
在该电影数据集中,最受欢迎的前10个电影类型是根据数量统计而来的。剧情(Drama)是最受欢迎的电影类型,其次是Documentary(纪录片)和动作(Action)。这些最受欢迎的电影类型在数据集中的数量相对较多,可能反映了观众的偏好和市场需求。其他受欢迎的电影类型包括动作(Action)、爱情(Romance)和动画(Animation)等。这些结论可以为电影制片商、编剧和市场营销人员提供有关当前最受欢迎的电影类型和潜在商业机会的见解。
6.
1 zh_movies = data[data['original_language'] == 'zh'] 2 genres = zh_movies['genres'].str.split(',', expand=True).stack().value_counts().head(10) 3 4 plt.figure(figsize=(10, 6)) 5 genres.plot(kind='bar') 6 plt.title('Top 10 Most Popular Genres in Chinese Movies') 7 plt.xlabel('Genres') 8 plt.ylabel('Number of Movies') 9 plt.xticks(rotation=45) 10 plt.show()
运行截图:

数据说明:
在中文电影数据集中,最受欢迎的前10个电影类型是根据数量统计而来的。剧情(Drama)是中文电影中最受欢迎的类型,其次是动作(Action)和Documentary(纪录片)。相对于英文电影,中文电影的市场以剧情为主,动作片相对于英文电影来说占比会更大,因此,动作片的影视在中国市场的观众喜好程度高于外国,这些结论可以为中文电影制片商、以及国内编剧和市场营销人员提供有关当前最受欢迎的剧情类电影和动作类电影潜在商业机会的见解。
7.
1 zh_movies = data[data['original_language'] == 'zh'] 2 en_movies = data[data['original_language'] == 'en'] 3 zh_popularity_stats = zh_movies['popularity'].describe() 4 en_popularity_stats = en_movies['popularity'].describe() 5 zh_vote_average_stats = zh_movies['vote_average'].describe() 6 en_vote_average_stats = en_movies['vote_average'].describe() 7 8 zh_revenue_stats = zh_movies['revenue'].describe() 9 en_revenue_stats = en_movies['revenue'].describe() 10 11 zh_runtime_stats = zh_movies['runtime'].describe() 12 en_runtime_stats = en_movies['runtime'].describe() 13 plt.figure(figsize=(10, 6)) 14 15 # 比较流行度 16 plt.subplot(2, 3, 1) 17 plt.bar(['Chinese', 'English'], [zh_popularity_stats['mean'], en_popularity_stats['mean']]) 18 plt.title('Mean Popularity') 19 plt.ylabel('Popularity') 20 21 # 比较平均评分 22 plt.subplot(2, 3, 2) 23 plt.bar(['Chinese', 'English'], [zh_vote_average_stats['mean'], en_vote_average_stats['mean']]) 24 plt.title('Mean Vote Average') 25 plt.ylabel('Vote Average') 26 27 # 比较总收入 28 plt.subplot(2, 3, 3) 29 plt.bar(['Chinese', 'English'], [zh_revenue_stats['mean'], en_revenue_stats['mean']]) 30 plt.title('Mean Revenue') 31 plt.ylabel('Revenue') 32 33 # 比较电影时长 34 plt.subplot(2, 3, 4) 35 plt.bar(['Chinese', 'English'], [zh_runtime_stats['mean'], en_runtime_stats['mean']]) 36 plt.title('Mean Runtime') 37 plt.ylabel('Runtime') 38 39 plt.tight_layout() 40 plt.show()
运行截图:
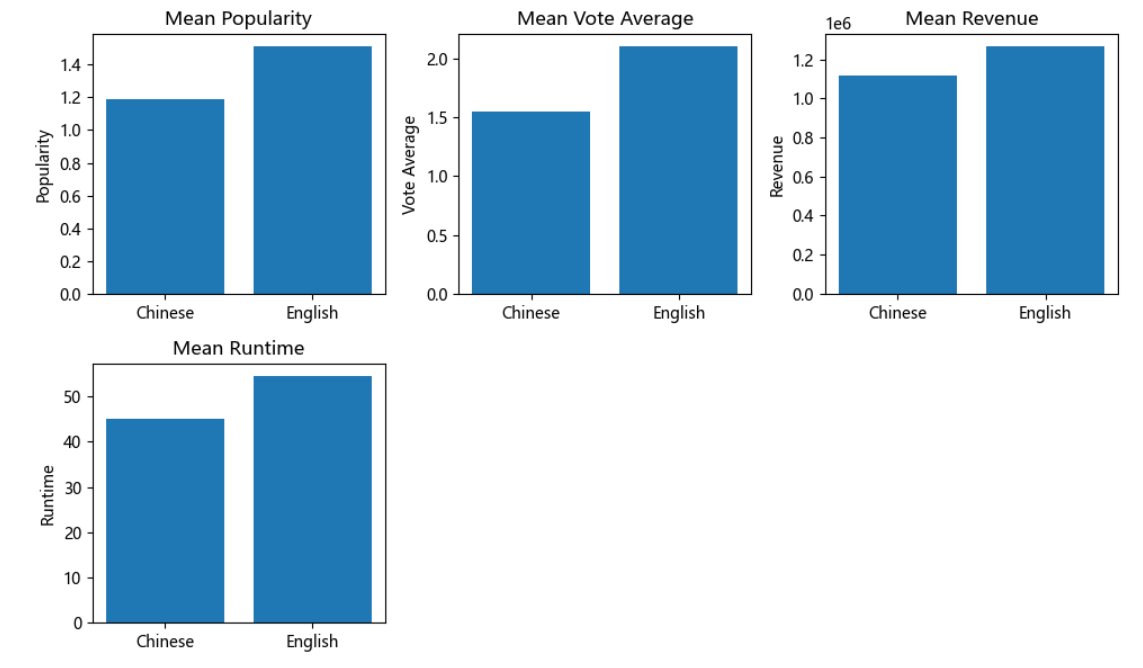
数据说明:这段代码计算了数据集中以中文和英文作为原始语言的电影的流行度(popularity)、平均评分(vote_average)、总收入(revenue)和电影时长(runtime)的统计信息,并通过条形图进行了比较。通过这些比较,可以对中文和英文电影在流行度、评分、总收入和电影时长等方面的差异有一个直观的了解。就如图中我们发现中文和英文电影市场的特点和趋势,英文的电影各项数值都略大于中文,以此分析并,该数据可以提供有关观众偏好和商业机会的见解。
8.
1 # 筛选 original_language 为 "zh" 的电影 2 zh_movies = data[data['original_language'] == 'zh'] 3 4 # 计算每年发布的电影数量 5 movie_counts_by_year = zh_movies['release_year'].value_counts().sort_index() 6 7 plt.figure(figsize=(12, 6)) 8 plt.plot(movie_counts_by_year.index, movie_counts_by_year.values) 9 plt.title('Number of Movies Released by Year (Original Language: Chinese)') 10 plt.xlabel('Year') 11 plt.ylabel('Number of Movies') 12 plt.xticks(rotation=45) 13 plt.show()
运行截图:

数据说明:中文电影的发布数量随着时间的推移呈现出一定的变化。通过观察折线图可以得知,随着年份的增长,并且从2000年开始,我国的电影发布数量以指数形式上涨。从以上数据中可以通过折线图来观察中文电影产量的趋势和变化,了解中文电影产业的发展变化情况。
9.
1 # 对adult列进行分组统计 2 adult_counts = data['adult'].value_counts() 3 4 # 绘制成人内容电影与非成人内容电影的数量柱状图 5 plt.bar(adult_counts.index, adult_counts.values) 6 plt.xlabel('是否包含成人内容') 7 plt.ylabel('电影数量') 8 plt.title('成人内容电影与非成人内容电影的数量') 9 plt.show() 10 11 # 根据成人内容对数据进行分组 12 grouped_data = data.groupby('adult') 13 14 # 计算各组的平均评分和平均流行度 15 mean_vote_average = grouped_data['vote_average'].mean() 16 mean_popularity = grouped_data['popularity'].mean() 17 18 # 绘制成人内容电影与非成人内容电影的平均评分和平均流行度比较图 19 plt.bar(mean_vote_average.index, mean_vote_average.values, label='平均评分') 20 plt.bar(mean_popularity.index, mean_popularity.values, label='平均流行度') 21 plt.xlabel('是否包含成人内容') 22 plt.ylabel('平均值') 23 plt.title('成人内容电影与非成人内容电影的评分和流行度比较') 24 plt.legend() 25 plt.show()
运行截图:


数据说明:从图中我们能看出,成人内容电影和非成人内容电影在评分和流行度上存在一定的差异。成人内容电影的占比相对于非成人内容电影来说差距很大,通过比较图表的柱状图,了解成人内容电影和非成人内容电影在评分和流行度上的平均值情况。但先后对于平均流行度和平均评分来比较,他们之间都有着相对稳定的比例。这有助于了解成人内容电影和非成人内容电影在数量、评分和流行度方面的差异,为电影产业从业者和决策者提供相关信息和洞察。
10.
1 # 统计各个语言的电影数量 2 language_counts = data['original_language'].value_counts() 3 4 # 绘制各个语言的电影数量柱状图 5 plt.bar(language_counts.index, language_counts.values) 6 plt.xlabel('原语言') 7 plt.ylabel('电影数量') 8 plt.title('各个语言的电影数量') 9 plt.show() 10 11 # 计算各语言电影的平均评分和平均流行度 12 mean_vote_average = data.groupby('original_language')['vote_average'].mean() 13 mean_popularity = data.groupby('original_language')['popularity'].mean() 14 15 # 绘制各语言电影的平均评分和平均流行度比较图 16 plt.bar(mean_vote_average.index, mean_vote_average.values, label='平均评分') 17 plt.bar(mean_popularity.index, mean_popularity.values, label='平均流行度') 18 plt.xlabel('原语言') 19 plt.ylabel('平均值') 20 plt.title('各语言电影的评分和流行度比较') 21 plt.legend() 22 plt.show()


数据说明:电影数量统计和柱状图:
- 统计了各个语言的电影数量。通过柱状图展示了各个语言的电影数量。可以观察各个语言之间电影数量的相对分布情况。从图中我们发现影视市场中绝大部分的语言占比都是英语
- 平均评分和平均流行度比较:
- 计算了各个语言电影的平均评分和平均流行度。通过柱状图比较了各个语言电影的平均评分和平均流行度。可以观察各个语言之间电影评分和流行度的差异情况。
这些结论可以帮助了解电影数据集中不同语言电影的分布情况,以及各语言电影的平均评分和平均流行度。通过对电影数量和评分流行度的比较,可以对不同语言电影的受欢迎程度和质量进行初步分析。
11.
1 # 填充缺失值为空字符串 2 df.fillna('', inplace=True) 3 4 # 创建制作公司与电影类型的关系图 5 company_genre_graph = nx.Graph() 6 7 # 遍历每一行数据,建立关系图的节点和边 8 for _, row in df.iterrows(): 9 companies = row['production_companies'].split(',') 10 genres = row['genres'].split(',') 11 for company in companies: 12 for genre in genres: 13 company_genre_graph.add_edge(company.strip(), genre.strip()) 14 15 # 创建并绘制制作公司与电影类型的树状图 16 plt.figure(figsize=(12, 8)) 17 pos = nx.spring_layout(company_genre_graph) 18 nx.draw(company_genre_graph, pos, with_labels=True, node_size=1500, node_color='lightblue', edge_color='gray', arrows=False) 19 plt.title('Production Companies and Movie Genres') 20 plt.show() 21 22 # 创建制作国家与语言的关系图 23 country_language_graph = nx.Graph() 24 25 # 遍历每一行数据,建立关系图的节点和边 26 for _, row in df.iterrows(): 27 countries = row['production_countries'].split(',') 28 languages = row['spoken_languages'].split(',') 29 for country in countries: 30 for language in languages: 31 country_language_graph.add_edge(country.strip(), language.strip()) 32 33 # 创建并绘制制作国家与语言的树状图 34 plt.figure(figsize=(12, 8)) 35 pos = nx.spring_layout(country_language_graph) 36 nx.draw(country_language_graph, pos, with_labels=True, node_size=1500, node_color='lightgreen', edge_color='gray', arrows=False) 37 plt.title('Production Countries and Spoken Languages') 38 plt.show()
运行截图:
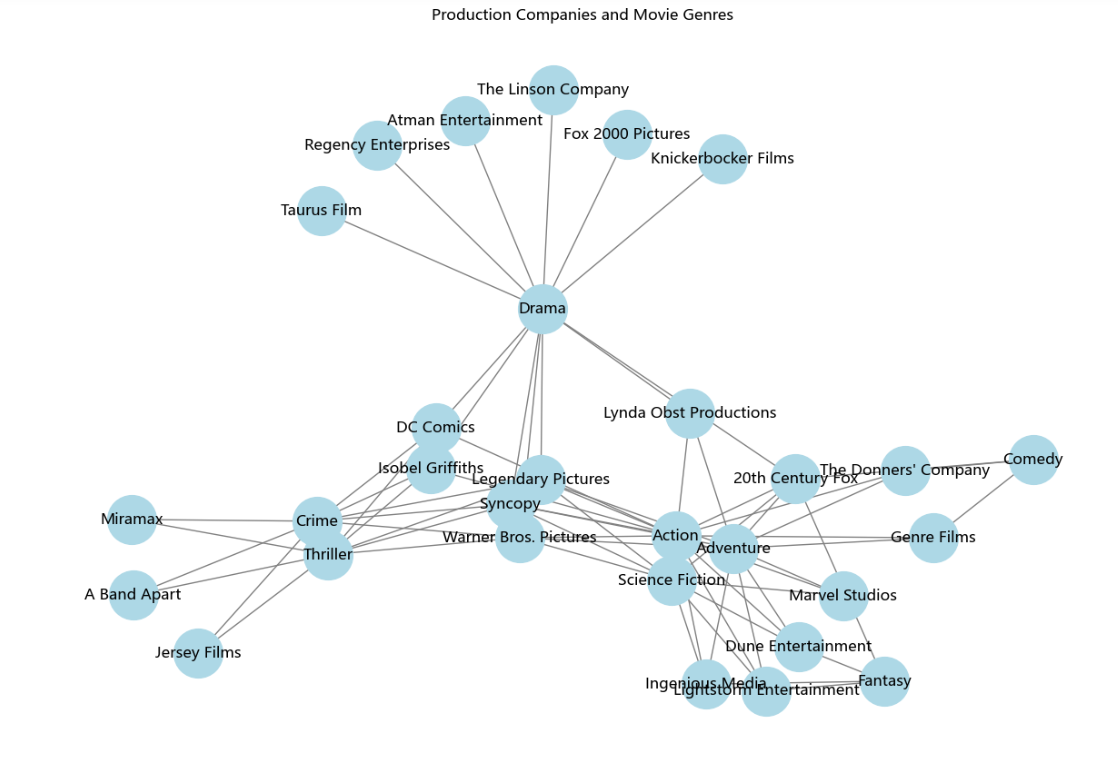

数据说明:从上图两个树状图中,我们发现,制作公司与电影类型之间存在一定的关联关系。通过树状图可以观察到制作公司和电影类型之间的连接情况,了解不同制作公司参与的电影类型分布情况。比如作为当今影视剧最多的Drama(戏剧),与其中的Taurus Film,Atman,Fox2000等制作公司之间都有密切的联系,联系最多的相应也是影视剧数量最多的Drama(戏剧),因此制作国家与语言之间存在一定的关联关系。通过树状图可以观察到制作国家和语言之间的连接情况,了解不同制作国家使用的语言分布情况。这些数据可以帮助研究人员和从业者了解制作公司和电影类型、制作国家和语言之间的关系。
而下图的树状图则显现出的是国家与电影中的语言的联系,以United Kingdom(英国)为例,英国与japanses,English,Spanish等语言的电影都有联系,而对于Russian和Hindi没有联系,说明该语言的电影在英国可能没有出现关联,以至于在电影制作和发布时要对该国家相互联系的语言进行核对,这样有助于在该国家电影的语言能被大部分人适应和认同。
12.
1 # 将发布日期转换为日期类型 2 df['release_date'] = pd.to_datetime(df['release_date']) 3 4 # 按发布日期排序 5 df = df.sort_values('release_date') 6 7 # 提取需要比较的数据列 8 data = df[['release_date', 'vote_average', 'revenue']] 9 10 # 绘制折线图 11 plt.plot(data['release_date'], data['vote_average'], label='Average Vote') 12 plt.plot(data['release_date'], data['revenue'], label='Revenue') 13 14 plt.xlabel('Release Date') 15 plt.ylabel('Value') 16 plt.title('Comparison of Average Vote and Revenue over Time') 17 plt.legend() 18 plt.show()
运行截图:

数据说明:得出的结论是:从以上数据中,我们发现影视剧的收入随着时间的推移产生了很大的波动,也带部分上涨趋势,而影视的平均评分不受影响。
13.
1 # 筛选 original_language 为 "zh" 和 "fr" 的电影 2 zh_movies = data[data['original_language'] == 'zh'] 3 en_movies = data[data['original_language'] == 'en'] 4 5 # 计算每年发布的电影数量 6 zh_movie_counts_by_year = zh_movies['release_year'].value_counts().sort_index() 7 en_movie_counts_by_year = en_movies['release_year'].value_counts().sort_index() 8 9 plt.figure(figsize=(12, 6)) 10 plt.plot(zh_movie_counts_by_year.index, zh_movie_counts_by_year.values, label='Chinese Movies') 11 plt.plot(en_movie_counts_by_year.index, en_movie_counts_by_year.values, label='English Movies') 12 plt.title('Number of Movies Released by Year') 13 plt.xlabel('Year') 14 plt.ylabel('Number of Movies') 15 plt.xticks(rotation=45) 16 plt.legend() 17 plt.show()
运行截图:

数据说明:通过以上折线图可以观察到中文电影和英语电影在不同年份的发布情况。中文电影相对于英文电影来说还是相对落后一段距离,通过比较中文电影和英语电影的发布趋势,了解不同语言电影产量的变化情况。
14,
1 # 选择特征和目标变量 2 features = ['revenue', 'popularity', 'runtime'] 3 target = 'vote_average' 4 # 筛选有效数据 5 valid_data = data.dropna(subset=features + [target]) 6 # 划分训练集和测试集 7 X_train, X_test, y_train, y_test = train_test_split(valid_data[features], 8 valid_data[target], 9 test_size=0.2, 10 random_state=42) 11 # 建立线性回归模型 12 model = LinearRegression() 13 # 拟合模型 14 model.fit(X_train, y_train) 15 # 在测试集上进行预测 16 y_pred = model.predict(X_test) 17 # 计算均方误差 18 mse = mean_squared_error(y_test, y_pred) 19 print("均方误差(MSE):", mse)
运行截图:

数据说明:可以帮助评估选择的特征对于预测电影评分的有效性,从模型性能的评估指标(均方误差)中来衡量预测结果的准确性。值越小表示模型的预测效果越好。数据中运行的均方误差相对来说较小,有助于预测电影的评分有效性。
15.
1 # 筛选有效数据 2 valid_data = data.dropna(subset=['release_date', 'revenue']) 3 4 # 转换release_date列为日期类型 5 valid_data['release_date'] = pd.to_datetime(valid_data['release_date']) 6 7 # 提取年份和月份作为新的列 8 valid_data['year'] = valid_data['release_date'].dt.year 9 valid_data['month'] = valid_data['release_date'].dt.month 10 11 # 按年份和月份分组计算平均收入 12 revenue_by_month = valid_data.groupby(['year', 'month'])['revenue'].mean().reset_index() 13 14 15 # 分析电影上映日期对收入的影响 16 sns.boxplot(data=valid_data, x='month', y='revenue') 17 plt.xlabel('Month') 18 plt.ylabel('Revenue') 19 plt.title('Revenue Distribution by Release Month') 20 plt.show()
运行截图:

数据说明:从图中可以看出,上映月份可能对电影收入产生影响。通过箱线图可以观察到不同月份电影收入的分布情况。可能存在某些月份电影收入较高,而其他月份较低。从图中可以看出月份对电影收入产生一个类似三角函数的周期性影响,不难看出,五月份和十一月份的收入相对较高,而一月份和八月份的电影收入相对较低,从数据中,我们可以了解到这份表格的数据有助于电影行业从业者和决策者了解电影上映日期与收入之间的关系,优化上映时间和制定营销策略,以最大化电影的收益。
五、全部代码
1 from matplotlib import pyplot as plt 2 plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"] 3 plt.rcParams['axes.unicode_minus'] = False 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import seaborn as sns 8 from scipy import stats 9 10 # 读取数据 11 df = pd.read_csv('TMDB_movie_dataset_v11.csv',nrows=500) 12 13 # 数据清洗 14 # 假设revenue和budget列没有缺失值 15 df['revenue'] = df['revenue'].replace([np.inf, -np.inf], np.nan) 16 df['budget'] = df['budget'].replace([np.inf, -np.inf], np.nan) 17 df = df.dropna(subset=['revenue', 'budget']) # 删除含有缺失值的行 18 19 # 描述性统计 20 print("票房收入的描述性统计:") 21 print(df['revenue'].describe()) 22 23 print("\n预算的描述性统计:") 24 print(df['budget'].describe()) 25 26 # 图表: 散点图和线性拟合线 27 x = df['budget'] 28 y = df['revenue'] 29 slope, intercept, _, _, _ = stats.linregress(x, y) # 计算斜率和截距 30 line = slope * x + intercept # 计算线性拟合线 31 plt.scatter(x, y) # 散点图 32 plt.plot(x, line, color='red') # 线性拟合线 33 plt.xlabel('电影预算') 34 plt.ylabel('电影票房收入') 35 plt.title('电影票房收入与预算的散点图和线性拟合线') 36 plt.show() 37 38 # 图表: 箱线图 (显示异常值) 39 plt.boxplot([df['revenue'], df['budget']], vert=False) # 箱线图,vert=False表示水平放置箱线图 40 plt.title('电影票房收入与预算的箱线图') 41 plt.show() 42 # 读取数据 43 data = pd.read_csv("TMDB_movie_dataset_v11.csv", nrows=1000) 44 vote_average = data['vote_average'] 45 mean = vote_average.mean() 46 median = vote_average.median() 47 std = vote_average.std() 48 49 # 打印统计结果 50 print("平均值:", mean) 51 print("中位数:", median) 52 print("标准差:", std) 53 54 # 绘制直方图 55 plt.hist(vote_average, bins=10, edgecolor='k', color='skyblue') 56 57 # 添加标题和标签 58 plt.xlabel('评分') 59 plt.ylabel('电影数量') 60 plt.title('电影评分分布直方图') 61 62 # 添加数据标签 63 plt.text(x=mean, y=130, s=f'平均值: {mean:.2f}', color='black', ha='center') 64 plt.text(x=median, y=120, s=f'中位数: {median:.2f}', color='red', ha='center') 65 plt.text(x=mean - std, y=110, s=f'标准差: {std:.2f}', color='green', ha='center') 66 67 # 显示图像 68 plt.show() 69 70 # 绘制箱线图 71 sns.boxplot(x=vote_average, color='skyblue') 72 73 # 添加标题和标签 74 plt.xlabel('评分') 75 plt.title('电影评分分布箱线图') 76 77 # 显示图像 78 plt.show() 79 # 获取status列中的唯一值数量 80 num_statuses = len(df['status'].unique()) 81 # 创建一个标签列表,确保其长度与status列中的唯一值数量相匹配 82 labels = df['status'].unique().tolist() 83 84 # 散点图:平均评分与流行度之间的关系 85 plt.scatter(df['vote_average'], df['popularity']) 86 plt.xlabel('平均评分') 87 plt.ylabel('流行度') 88 plt.title('平均评分与流行度之间的关系') 89 plt.show() 90 91 # 将电影类型拆分为单独的类别 92 genres = df['genres'].str.split(',', expand=True).stack().str.strip().value_counts() 93 94 # 创建饼图 95 fig, ax = plt.subplots(figsize=(8, 8)) 96 _, texts, autotexts = ax.pie(genres, labels=genres.index, autopct='%1.1f%%', startangle=90) 97 ax.axis('equal') 98 ax.set_title('电影类型的分布情况') 99 100 # 自定义图例标签 101 labels = [f'{text.get_text()} ({genre:.1f}%)' for text, genre in zip(texts, genres)] 102 103 # 设置图例 104 plt.legend(labels, loc='center right', bbox_to_anchor=(1.5, 0.5)) 105 106 # 设置自动标签的颜色和字体样式 107 for autotext in autotexts: 108 autotext.set_color('white') 109 autotext.set_fontsize(12) 110 autotext.set_fontweight('bold') 111 112 plt.show() 113 genres = data['genres'].str.split(',', expand=True).stack().value_counts().head(10) 114 plt.figure(figsize=(10, 6)) 115 ax = sns.barplot(x=genres.index, y=genres.values, palette="Blues_r") 116 plt.title('Top 10 Most Popular Genres') 117 plt.xlabel('Genres') 118 plt.ylabel('Number of Movies') 119 plt.xticks(rotation=45) 120 121 # 添加数据标签 122 for p in ax.patches: 123 ax.annotate(f"{p.get_height()}", 124 (p.get_x() + p.get_width() / 2., 125 p.get_height()), ha='center', 126 va='center', xytext=(0, 5), 127 textcoords='offset points') 128 129 plt.tight_layout() 130 plt.show() 131 132 zh_movies = data[data['original_language'] == 'zh'] 133 genres = zh_movies['genres'].str.split(',', expand=True).stack().value_counts().head(10) 134 135 plt.figure(figsize=(10, 6)) 136 genres.plot(kind='bar') 137 plt.title('Top 10 Most Popular Genres in Chinese Movies') 138 plt.xlabel('Genres') 139 plt.ylabel('Number of Movies') 140 plt.xticks(rotation=45) 141 plt.show() 142 143 data = pd.read_csv("TMDB_movie_dataset_v11.csv") 144 zh_movies = data[data['original_language'] == 'zh'] 145 en_movies = data[data['original_language'] == 'en'] 146 zh_popularity_stats = zh_movies['popularity'].describe() 147 en_popularity_stats = en_movies['popularity'].describe() 148 zh_vote_average_stats = zh_movies['vote_average'].describe() 149 en_vote_average_stats = en_movies['vote_average'].describe() 150 151 zh_revenue_stats = zh_movies['revenue'].describe() 152 en_revenue_stats = en_movies['revenue'].describe() 153 154 zh_runtime_stats = zh_movies['runtime'].describe() 155 en_runtime_stats = en_movies['runtime'].describe() 156 plt.figure(figsize=(10, 6)) 157 158 # 比较流行度 159 plt.subplot(2, 3, 1) 160 plt.bar(['Chinese', 'English'], [zh_popularity_stats['mean'], en_popularity_stats['mean']]) 161 plt.title('Mean Popularity') 162 plt.ylabel('Popularity') 163 164 # 比较平均评分 165 plt.subplot(2, 3, 2) 166 plt.bar(['Chinese', 'English'], [zh_vote_average_stats['mean'], en_vote_average_stats['mean']]) 167 plt.title('Mean Vote Average') 168 plt.ylabel('Vote Average') 169 170 # 比较总收入 171 plt.subplot(2, 3, 3) 172 plt.bar(['Chinese', 'English'], [zh_revenue_stats['mean'], en_revenue_stats['mean']]) 173 plt.title('Mean Revenue') 174 plt.ylabel('Revenue') 175 176 # 比较电影时长 177 plt.subplot(2, 3, 4) 178 plt.bar(['Chinese', 'English'], [zh_runtime_stats['mean'], en_runtime_stats['mean']]) 179 plt.title('Mean Runtime') 180 plt.ylabel('Runtime') 181 182 plt.tight_layout() 183 plt.show() 184 data['release_year'] = pd.to_datetime(data['release_date']).dt.year 185 186 # 筛选 original_language 为 "zh" 的电影 187 zh_movies = data[data['original_language'] == 'zh'] 188 189 # 计算每年发布的电影数量 190 movie_counts_by_year = zh_movies['release_year'].value_counts().sort_index() 191 192 plt.figure(figsize=(12, 6)) 193 plt.plot(movie_counts_by_year.index, movie_counts_by_year.values) 194 plt.title('Number of Movies Released by Year (Original Language: Chinese)') 195 plt.xlabel('Year') 196 plt.ylabel('Number of Movies') 197 plt.xticks(rotation=45) 198 plt.show() 199 200 # 对adult列进行分组统计 201 adult_counts = data['adult'].value_counts() 202 203 # 绘制成人内容电影与非成人内容电影的数量柱状图 204 plt.bar(adult_counts.index, adult_counts.values) 205 plt.xlabel('是否包含成人内容') 206 plt.ylabel('电影数量') 207 plt.title('成人内容电影与非成人内容电影的数量') 208 plt.show() 209 210 # 根据成人内容对数据进行分组 211 grouped_data = data.groupby('adult') 212 213 # 计算各组的平均评分和平均流行度 214 mean_vote_average = grouped_data['vote_average'].mean() 215 mean_popularity = grouped_data['popularity'].mean() 216 217 # 绘制成人内容电影与非成人内容电影的平均评分和平均流行度比较图 218 plt.bar(mean_vote_average.index, mean_vote_average.values, label='平均评分') 219 plt.bar(mean_popularity.index, mean_popularity.values, label='平均流行度') 220 plt.xlabel('是否包含成人内容') 221 plt.ylabel('平均值') 222 plt.title('成人内容电影与非成人内容电影的评分和流行度比较') 223 plt.legend() 224 plt.show() 225 226 # 统计各个语言的电影数量 227 language_counts = data['original_language'].value_counts() 228 229 # 绘制各个语言的电影数量柱状图 230 plt.bar(language_counts.index, language_counts.values) 231 plt.xlabel('原语言') 232 plt.ylabel('电影数量') 233 plt.title('各个语言的电影数量') 234 plt.show() 235 236 # 计算各语言电影的平均评分和平均流行度 237 mean_vote_average = data.groupby('original_language')['vote_average'].mean() 238 mean_popularity = data.groupby('original_language')['popularity'].mean() 239 240 # 绘制各语言电影的平均评分和平均流行度比较图 241 plt.bar(mean_vote_average.index, mean_vote_average.values, label='平均评分') 242 plt.bar(mean_popularity.index, mean_popularity.values, label='平均流行度') 243 plt.xlabel('原语言') 244 plt.ylabel('平均值') 245 plt.title('各语言电影的评分和流行度比较') 246 plt.legend() 247 plt.show() 248 249 # 填充缺失值为空字符串 250 df.fillna('', inplace=True) 251 252 # 创建制作公司与电影类型的关系图 253 company_genre_graph = nx.Graph() 254 255 # 遍历每一行数据,建立关系图的节点和边 256 for _, row in df.iterrows(): 257 companies = row['production_companies'].split(',') 258 genres = row['genres'].split(',') 259 for company in companies: 260 for genre in genres: 261 company_genre_graph.add_edge(company.strip(), genre.strip()) 262 263 # 创建并绘制制作公司与电影类型的树状图 264 plt.figure(figsize=(12, 8)) 265 pos = nx.spring_layout(company_genre_graph) 266 nx.draw(company_genre_graph, pos, with_labels=True, node_size=1500, node_color='lightblue', edge_color='gray', arrows=False) 267 plt.title('Production Companies and Movie Genres') 268 plt.show() 269 270 # 创建制作国家与语言的关系图 271 country_language_graph = nx.Graph() 272 273 # 遍历每一行数据,建立关系图的节点和边 274 for _, row in df.iterrows(): 275 countries = row['production_countries'].split(',') 276 languages = row['spoken_languages'].split(',') 277 for country in countries: 278 for language in languages: 279 country_language_graph.add_edge(country.strip(), language.strip()) 280 281 # 创建并绘制制作国家与语言的树状图 282 plt.figure(figsize=(12, 8)) 283 pos = nx.spring_layout(country_language_graph) 284 nx.draw(country_language_graph, pos, with_labels=True, node_size=1500, node_color='lightgreen', edge_color='gray', arrows=False) 285 plt.title('Production Countries and Spoken Languages') 286 plt.show() 287 288 # 将发布日期转换为日期类型 289 df['release_date'] = pd.to_datetime(df['release_date']) 290 291 # 按发布日期排序 292 df = df.sort_values('release_date') 293 294 # 提取需要比较的数据列 295 data = df[['release_date', 'vote_average', 'revenue']] 296 297 # 绘制折线图 298 plt.plot(data['release_date'], data['vote_average'], label='Average Vote') 299 plt.plot(data['release_date'], data['revenue'], label='Revenue') 300 301 plt.xlabel('Release Date') 302 plt.ylabel('Value') 303 plt.title('Comparison of Average Vote and Revenue over Time') 304 plt.legend() 305 plt.show() 306 data['release_year'] = pd.to_datetime(data['release_date']).dt.year 307 308 # 筛选 original_language 为 "zh" 和 "fr" 的电影 309 zh_movies = data[data['original_language'] == 'zh'] 310 en_movies = data[data['original_language'] == 'fr'] 311 312 # 计算每年发布的电影数量 313 zh_movie_counts_by_year = zh_movies['release_year'].value_counts().sort_index() 314 en_movie_counts_by_year = en_movies['release_year'].value_counts().sort_index() 315 316 plt.figure(figsize=(12, 6)) 317 plt.plot(zh_movie_counts_by_year.index, zh_movie_counts_by_year.values, label='Chinese Movies') 318 plt.plot(en_movie_counts_by_year.index, en_movie_counts_by_year.values, label='English Movies') 319 plt.title('Number of Movies Released by Year') 320 plt.xlabel('Year') 321 plt.ylabel('Number of Movies') 322 plt.xticks(rotation=45) 323 plt.legend() 324 plt.show() 325 # 选择特征和目标变量 326 features = ['revenue', 'popularity', 'runtime'] 327 target = 'vote_average' 328 # 筛选有效数据 329 valid_data = data.dropna(subset=features + [target]) 330 # 划分训练集和测试集 331 X_train, X_test, y_train, y_test = train_test_split(valid_data[features], 332 valid_data[target], 333 test_size=0.2, 334 random_state=42) 335 # 建立线性回归模型 336 model = LinearRegression() 337 # 拟合模型 338 model.fit(X_train, y_train) 339 # 在测试集上进行预测 340 y_pred = model.predict(X_test) 341 # 计算均方误差 342 mse = mean_squared_error(y_test, y_pred) 343 print("均方误差(MSE):", mse) 344 345 # 筛选有效数据 346 valid_data = data.dropna(subset=['release_date', 'revenue']) 347 348 # 转换release_date列为日期类型 349 valid_data['release_date'] = pd.to_datetime(valid_data['release_date']) 350 351 # 提取年份和月份作为新的列 352 valid_data['year'] = valid_data['release_date'].dt.year 353 valid_data['month'] = valid_data['release_date'].dt.month 354 355 # 按年份和月份分组计算平均收入 356 revenue_by_month = valid_data.groupby(['year', 'month'])['revenue'].mean().reset_index() 357 358 # 分析电影上映日期对收入的影响 359 sns.boxplot(data=valid_data, x='month', y='revenue') 360 plt.xlabel('Month') 361 plt.ylabel('Revenue') 362 plt.title('Revenue Distribution by Release Month') 363 plt.show() 364 # 筛选有效数据 365 valid_data = data.dropna(subset=['runtime', 'vote_count']) 366 367 # 生成散点图 368 plt.figure(figsize=(8, 6)) 369 sns.scatterplot(data=valid_data, x='runtime', y='vote_count') 370 plt.xlabel('Runtime') 371 plt.ylabel('Vote Count') 372 plt.title('Runtime vs. Vote Count') 373 plt.show() 374 375 # 生成箱线图 376 plt.figure(figsize=(8, 6)) 377 sns.boxplot(data=valid_data, x='runtime', y='vote_count') 378 plt.xlabel('Runtime') 379 plt.ylabel('Vote Count') 380 plt.title('Runtime vs. Vote Count') 381 plt.show()
六、总结:
通过本次大数据分析的主题对电影数据进行分析,我总结出了以下结论:
通过统计各个语言的电影数量,并使用柱状图展示,可以观察不同语言电影的数量分布情况。可以确定哪些语言的电影数量较多,哪些较少,从而了解电影市场的语言特征。
可以使用散点图来比较电影评分和流行度之间的关系。观察散点图可以了解电影评分和流行度之间是否存在相关性或趋势。
可以使用折线图来分析电影数据随时间的变化趋势。可以比较不同时间点的电影数量、平均评分、收入等指标的变化情况。通过观察折线图,可以发现电影市场的发展趋势、受欢迎程度的变化等。
某些语言的电影数量较多,说明该语言的电影市场较为发达。电影评分和流行度之间呈现正相关关系,高评分电影更容易受欢迎。随着时间推移,电影数量呈现增长趋势,平均评分和收入也可能发生变化,反映了电影市场的演变和趋势。希望,通过本次的大数据分析我能更好的利用数据分析来了解各个行业的相关情况,利用大数据分析来让工作更加的快捷方便和明了。