任务
基于logistic回归和softmax rengression的文本分类
实验
- 分析不同的特征、损失函数、学习率对最终分类性能的影响
- shuffle 、batch、mini-batch
处理流程
读取文本->提取词向量(BOW,N-gram)->softmax回归->输出预测特征
实验设置:
- 不同的特征:set-of-word,bag-of-word,N-gram(2-gram)
- 不同的学习率[0.0001,0.001,0.01,0.1,1,10,100]
- 梯度下降方法:随机梯度下降,batch下降和mini-batch
实验结果如下:
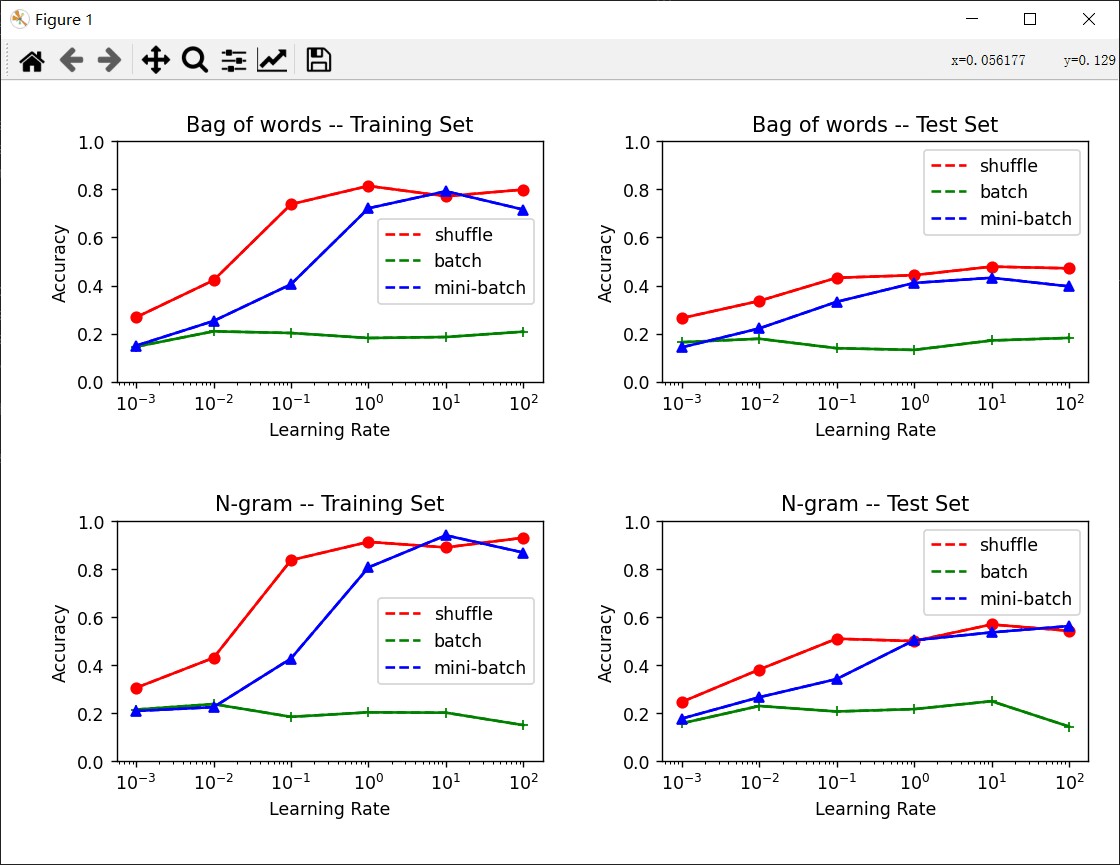
图1:迭代次数:10000,bag-of-word(bag-of-word)
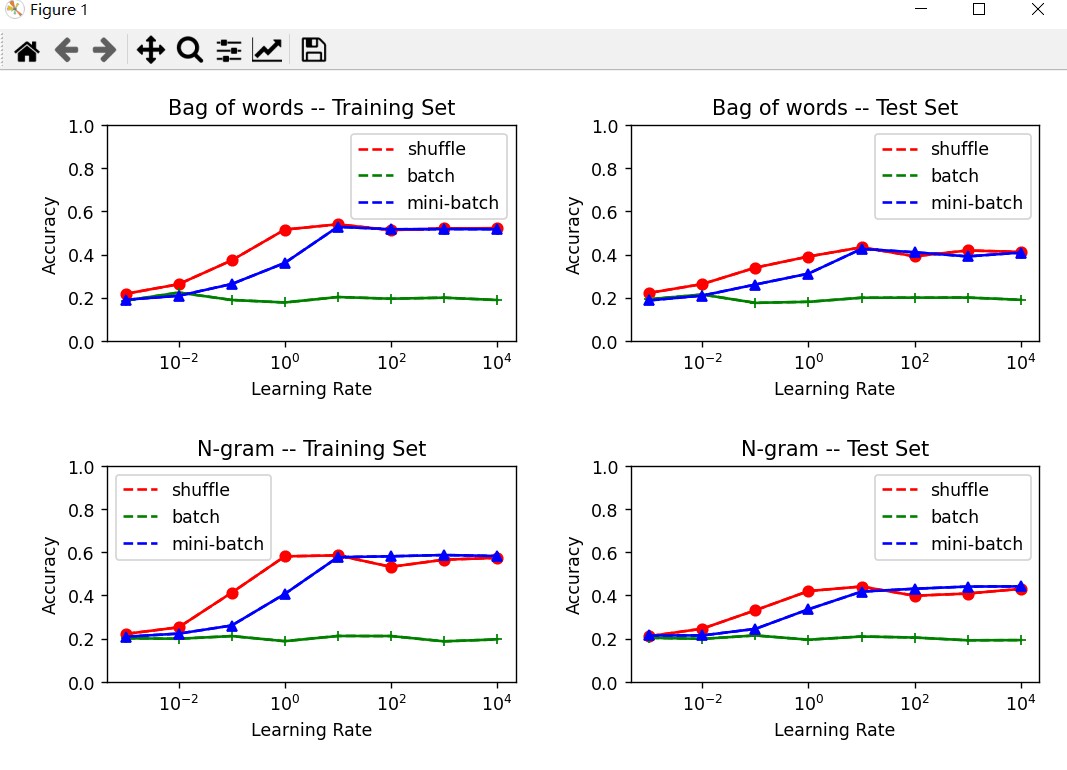
图2:迭代次数:10000,bag-of-words(set-of-words)
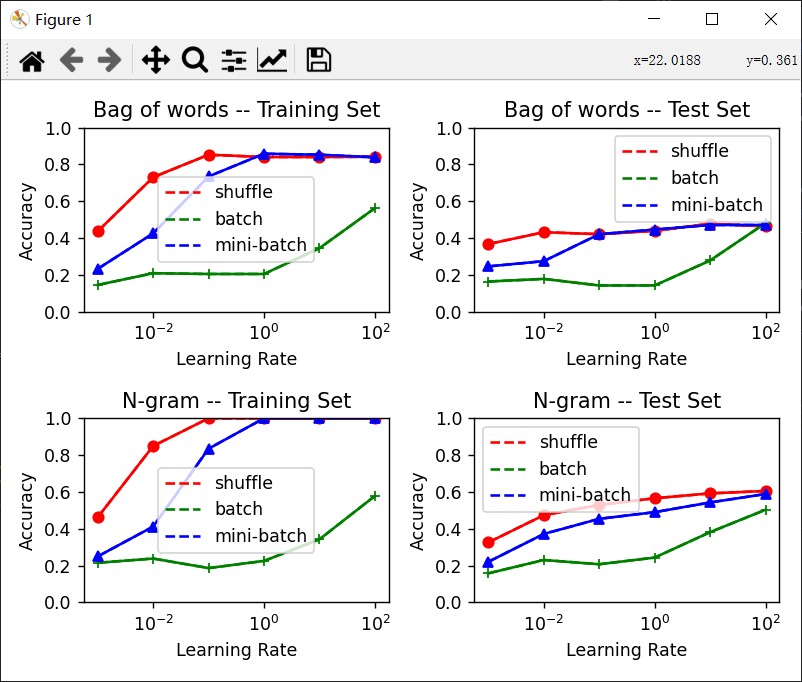
图3:迭代次数:100000,bag-of-words(bag-of-words)
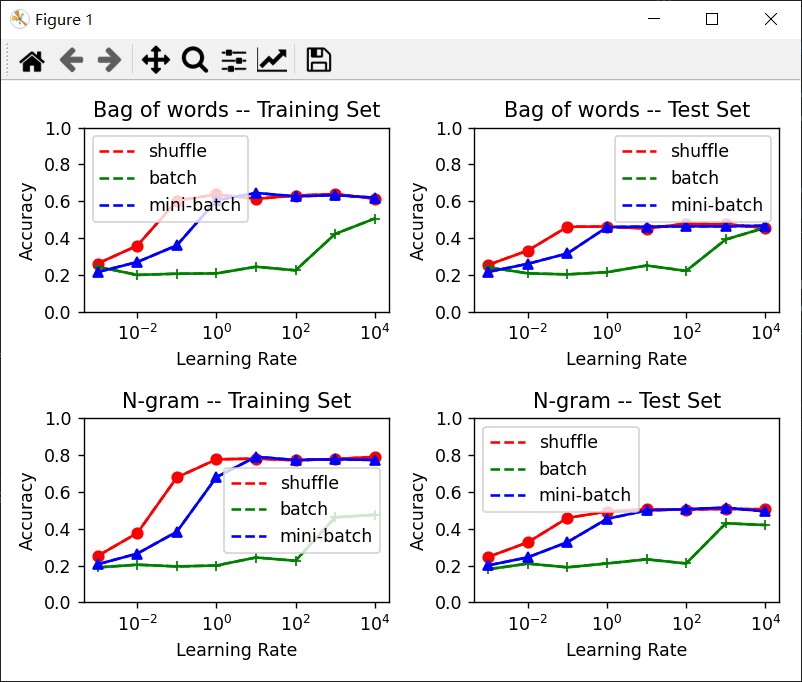
图4:迭代次数:100000,bag-of-words(set-of-words)
由于设备原因,大概训练集只能跑是30000条数据,7:3训练测试集比例,手搓softmax回归。
通过上图的实验,大致可以得到以下结论:
- bag-of-word相对于set-of-word的特征提取效果较好,分类性能提高5%左右,推断可能是因为在文本分类中,带有情感的词汇出现的次数可能会比较多,而在bag-of-word提取的特征可以突出这一点。
- 2-gram提取的特征相对于bag-of-word提取的特征更好,在图1和图 2的比较过程中,可以发现在相同的条件设置下,2-gram的准确率可以达到60%。
- batch的参数优化方法只有在较大的学习率,准确率才稍有提升,原因是因为每次读取整个数据集才更新一次参数,导致模型收敛较慢。而mini-batch和随机梯度下降的方法收敛速度较快。但只要达到足够多的次数,准确率几乎相近。
- 图3中出现了过拟合现象。
针对batch-size做一组实验,也可以选一个迭代曲线出来。
带走的知识点
- 文本的特征表示:bag-of-word,N-gram
- 分类器:logistic/softmax regression,损失函数、(随机)梯度下降、特征选择
- 了解基本的文本分类的过程
- 对文本的数据处理有了基本的了解
代码如下:
main.py: 主程序的入口地址
``python
import numpy
import csv
import random
from myfeature import Bag,Gram
from mycomparison_plot import alpha_gradient_plot
with open(r'Project1\train.tsv') as f:
tsvreader = csv.reader(f,delimiter = '\t')
temp = list(tsvreader)
data = temp[1:]
max_item = int((len(data)-1)*0.2)
random.seed(1)
numpy.random.seed(1)
特征提取
bag = Bag(data,max_item)
bag.get_words()
bag.get_matrix()
gram = Gram(data,dimension=2,max_item=max_item)
gram.get_words()
gram.get_matrix()
alpha_gradient_plot(bag, gram, 10000, 10)
alpha_gradient_plot(bag, gram, 100000, 10)
comparison_plot.pypython
import matplotlib.pyplot
from my_mysoftmax_regression import Softmax
def alpha_gradient_plot(bag, gram, total_times, mini_size):
alphas = [0.001, 0.01, 0.1,1,10,100]
# Bag
shuffle_train = list()
shuffle_test = list()
for alpha in alphas:
soft = Softmax(len(bag.train), typenum=5, feature=bag.len)
soft.regression(bag.train_matrix, bag.train_y,alpha,total_times,"shuffle")
r_train,r_test = soft.correct_rate(bag.train_matrix, bag.train_y, bag.test_matrix, bag.test_y)
shuffle_train.append(r_train)
shuffle_test.append(r_test)
# Batch
batch_train = list()
batch_test = list()
for alpha in alphas:
soft = Softmax(len(bag.train), 5, bag.len)
soft.regression(bag.train_matrix, bag.train_y, alpha, int(total_times/bag.max_item), "batch")
r_train, r_test = soft.correct_rate(bag.train_matrix, bag.train_y, bag.test_matrix, bag.test_y)
batch_train.append(r_train)
batch_test.append(r_test)
# Mini-batch
mini_train = list()
mini_test = list()
for alpha in alphas:
soft = Softmax(len(bag.train), 5, bag.len)
soft.regression(bag.train_matrix, bag.train_y, alpha, int(total_times/mini_size), "mini",mini_size)
r_train, r_test= soft.correct_rate(bag.train_matrix, bag.train_y, bag.test_matrix, bag.test_y)
mini_train.append(r_train)
mini_test.append(r_test)
matplotlib.pyplot.subplot(2,2,1)
matplotlib.pyplot.semilogx(alphas,shuffle_train,'r--',label='shuffle')
matplotlib.pyplot.semilogx(alphas, batch_train, 'g--', label='batch')
matplotlib.pyplot.semilogx(alphas, mini_train, 'b--', label='mini-batch')
matplotlib.pyplot.semilogx(alphas,shuffle_train, 'ro-', alphas, batch_train, 'g+-',alphas, mini_train, 'b^-')
matplotlib.pyplot.legend()
matplotlib.pyplot.title("Bag of words -- Training Set")
matplotlib.pyplot.xlabel("Learning Rate")
matplotlib.pyplot.ylabel("Accuracy")
matplotlib.pyplot.ylim(0,1)
matplotlib.pyplot.subplot(2, 2, 2)
matplotlib.pyplot.semilogx(alphas, shuffle_test, 'r--', label='shuffle')
matplotlib.pyplot.semilogx(alphas, batch_test, 'g--', label='batch')
matplotlib.pyplot.semilogx(alphas, mini_test, 'b--', label='mini-batch')
matplotlib.pyplot.semilogx(alphas, shuffle_test, 'ro-', alphas, batch_test, 'g+-', alphas, mini_test, 'b^-')
matplotlib.pyplot.legend()
matplotlib.pyplot.title("Bag of words -- Test Set")
matplotlib.pyplot.xlabel("Learning Rate")
matplotlib.pyplot.ylabel("Accuracy")
matplotlib.pyplot.ylim(0, 1)
# N-gram
# Shuffle
shuffle_train = list()
shuffle_test = list()
for alpha in alphas:
soft = Softmax(len(gram.train), 5, gram.len)
soft.regression(gram.train_matrix, gram.train_y, alpha, total_times, "shuffle")
r_train, r_test = soft.correct_rate(gram.train_matrix, gram.train_y, gram.test_matrix, gram.test_y)
shuffle_train.append(r_train)
shuffle_test.append(r_test)
# Batch
batch_train = list()
batch_test = list()
for alpha in alphas:
soft = Softmax(len(gram.train), 5, gram.len)
soft.regression(gram.train_matrix, gram.train_y, alpha, int(total_times / gram.max_item), "batch")
r_train, r_test = soft.correct_rate(gram.train_matrix, gram.train_y, gram.test_matrix, gram.test_y)
batch_train.append(r_train)
batch_test.append(r_test)
# Mini-batch
mini_train = list()
mini_test = list()
for alpha in alphas:
soft = Softmax(len(gram.train), 5, gram.len)
soft.regression(gram.train_matrix, gram.train_y, alpha, int(total_times / mini_size), "mini", mini_size)
r_train, r_test = soft.correct_rate(gram.train_matrix, gram.train_y, gram.test_matrix, gram.test_y)
mini_train.append(r_train)
mini_test.append(r_test)
matplotlib.pyplot.subplot(2, 2, 3)
matplotlib.pyplot.semilogx(alphas, shuffle_train, 'r--', label='shuffle')
matplotlib.pyplot.semilogx(alphas, batch_train, 'g--', label='batch')
matplotlib.pyplot.semilogx(alphas, mini_train, 'b--', label='mini-batch')
matplotlib.pyplot.semilogx(alphas, shuffle_train, 'ro-', alphas, batch_train, 'g+-', alphas, mini_train, 'b^-')
matplotlib.pyplot.legend()
matplotlib.pyplot.title("N-gram -- Training Set")
matplotlib.pyplot.xlabel("Learning Rate")
matplotlib.pyplot.ylabel("Accuracy")
matplotlib.pyplot.ylim(0, 1)
matplotlib.pyplot.subplot(2, 2, 4)
matplotlib.pyplot.semilogx(alphas, shuffle_test, 'r--', label='shuffle')
matplotlib.pyplot.semilogx(alphas, batch_test, 'g--', label='batch')
matplotlib.pyplot.semilogx(alphas, mini_test, 'b--', label='mini-batch')
matplotlib.pyplot.semilogx(alphas, shuffle_test, 'ro-', alphas, batch_test, 'g+-', alphas, mini_test, 'b^-')
matplotlib.pyplot.legend()
matplotlib.pyplot.title("N-gram -- Test Set")
matplotlib.pyplot.xlabel("Learning Rate")
matplotlib.pyplot.ylabel("Accuracy")
matplotlib.pyplot.ylim(0, 1)
matplotlib.pyplot.tight_layout()
matplotlib.pyplot.show()
``
划分数据集:
``python
import numpy
import random
划分数据集
def data_split(data, test_rate = 0.3, max_item = 1000):
train = list()
test = list()
i = 0
for indic in data:
i += 1
if random.random() > test_rate:
train.append(indic)
else:
test.append(indic)
if i >max_item:
break
return train,test
class Bag:
'''词袋'''
def init(self, data, max_item = 1000):
self.data = data[:max_item]
self.max_item = max_item
self.dict_words = dict()
self.len = 0
self.train,self.test = data_split(self.data)
self.train_y = [int(term[3]) for term in self.train]
self.test_y = [int(term[3]) for term in self.test]
self.train_matrix = None # Feature vectors of training set
self.test_matrix = None
def get_words(self):
for term in self.data:
s = term[2]
s = s.upper()
words = s.split()
for word in words:
if word not in self.dict_words:
self.dict_words[word] = len(self.dict_words) #给定一个序号
self.len = len(self.dict_words)
self.test_matrix = numpy.zeros((len(self.test), self.len))
self.train_matrix = numpy.zeros((len(self.train), self.len))
def get_matrix(self):
for i in range(len(self.train)):
s = self.train[i][2]
words = s.split()
for word in words:
word = word.upper()
self.train_matrix[i][self.dict_words[word]] = self.train_matrix[i][self.dict_words[word]]+1
for i in range(len(self.test)):
s = self.test[i][2]
words = s.split()
for word in words:
word = word.upper()
self.test_matrix[i][self.dict_words[word]] = self.test_matrix[i][self.dict_words[word]]+1
class Gram:
"N-gram"
def init(self, data, dimension = 2, max_item = 1000):
self.data = data[:max_item]
self.max_item = max_item
self.dict_words = dict()
self.len = 0
self.dimension = dimension
self.train, self.test = data_split(self.data)
self.train_y = [int(term[3]) for term in self.train]
self.test_y = [int(term[3]) for term in self.test]
self.train_matrix = None
self.test_matrix = None
def get_words(self):
for d in range(1,self.dimension+1): # 为什么这里需要 1-gram, 2-gram,..., dimension-gram
for term in self.data:
s = term[2]
s = s.upper()
words = s.split()
for i in range(len(words) - d + 1):
temp = words[i:i+d]
temp = '_'.join(temp) #形成一个gram feature
if temp not in self.dict_words:
self.dict_words[temp] = len(self.dict_words)
self.len = len(self.dict_words)
self.test_matrix = numpy.zeros((len(self.test), self.len))
self.train_matrix = numpy.zeros((len(self.train),self.len))
def get_matrix(self):
for d in range(1, self.dimension + 1):
for i in range(len(self.train)):
s = self.train[i][2]
s = s.upper()
words = s.split()
for j in range(len(words)-d+1):
temp = words[j:j+d]
temp = '_'.join(temp)
self.train_matrix[i][self.dict_words[temp]] = self.train_matrix[i][self.dict_words[temp]]+1
for i in range(len(self.test)):
s = self.test[i][2]
s = s.upper()
words = s.split()
for j in range(len(words)-d+1):
temp = words[j:j+d]
temp = '_'.join(temp)
self.test_matrix[i][self.dict_words[temp]] = self.test_matrix[i][self.dict_words[temp]]+1
``
softmax.py:softmax回归
``python
import numpy
import random
class Softmax:
"""Softmax regression"""
def init(self, sample, typenum, feature):
self.sample = sample # How many sample in training set
self.typenum = typenum # How many categories
self.feature = feature # The size of feature vector
self.W = numpy.random.randn(feature, typenum) # Weight matrix initialization
def softmax_calculation(self, x):
"""Calculate softmax function value. x is a vector."""
exp = numpy.exp(x - numpy.max(x))
return exp / exp.sum()
def softmax_all(self, wtx):
"""Calculate softmax function value. wtx is a matrix."""
wtx -= numpy.max(wtx, axis=1, keepdims=True)
wtx = numpy.exp(wtx)
wtx /= numpy.sum(wtx, axis=1, keepdims=True)
return wtx
def change_y(self, y):
"""Transform an 'int' into a one-hot vector."""
ans = numpy.array([0] * self.typenum)
ans[y] = 1
return ans.reshape(-1, 1)
def prediction(self, X):
"""Given X, predict the category."""
prob = self.softmax_all(X.dot(self.W))
return prob.argmax(axis=1)
def correct_rate(self, train, train_y, test, test_y):
"""Calculate the categorization accuracy."""
# train set
n_train = len(train)
pred_train = self.prediction(train)
train_correct = sum([train_y[i] == pred_train[i] for i in range(n_train)]) / n_train
# test set
n_test = len(test)
pred_test = self.prediction(test)
test_correct = sum([test_y[i] == pred_test[i] for i in range(n_test)]) / n_test
print(train_correct, test_correct)
return train_correct, test_correct
def regression(self, X, y, alpha, times, strategy="mini", mini_size=100):
"""Softmax regression"""
if self.sample != len(X) or self.sample != len(y):
raise Exception("Sample size does not match!")
if strategy == "mini":
for i in range(times):
increment = numpy.zeros((self.feature, self.typenum)) # The gradient
for j in range(mini_size): # Choose a mini-batch of samples
k = random.randint(0, self.sample - 1)
yhat = self.softmax_calculation(self.W.T.dot(X[k].reshape(-1, 1)))
increment += X[k].reshape(-1, 1).dot((self.change_y(y[k]) - yhat).T)
# print(i * mini_size)
self.W += alpha / mini_size * increment
elif strategy == "shuffle":
for i in range(times):
k = random.randint(0, self.sample - 1) # Choose a sample
yhat = self.softmax_calculation(self.W.T.dot(X[k].reshape(-1, 1)))
increment = X[k].reshape(-1, 1).dot((self.change_y(y[k]) - yhat).T) # The gradient
self.W += alpha * increment
# if not (i % 10000):
# print(i)
elif strategy=="batch":
for i in range(times):
increment = numpy.zeros((self.feature, self.typenum)) # The gradient
for j in range(self.sample): # Calculate all samples
yhat = self.softmax_calculation(self.W.T.dot(X[j].reshape(-1, 1)))
increment += X[j].reshape(-1, 1).dot((self.change_y(y[j]) - yhat).T)
# print(i)
self.W += alpha / self.sample * increment
else:
raise Exception("Unknown strategy")
``