前置知识:【EM算法深度解析 - CSDN App】http://t.csdnimg.cn/r6TXM
Motivation
目前的语义分割通常采用判别式分类器,然而这存在三个问题:这种方式仅仅学习了决策边界,而没有对数据分布进行建模;每个类仅学习一个向量,没有考虑到类内差异;OOD数据效果不好。生成式分类器通过对联合分布建模,可以很好地解决这些问题。
为此,本文提出了基于GMM的分割框架GMMSeg,从而建模每个类的数据分布\(p(\textbf{x}|c)\),借助(Sinkhorn) EM算法优化分类器,能够做到对大多数分割方法即插即用。
Method
不同于对后验概率\(p(c|\textbf{x})\)进行建模,生成式分类器通过贝叶斯定理预测标签,通过估计类别条件分布\(p(\textbf{x}|c)\)以及类别先验\(p(c)\)对联合分布\(p(\textbf{x}, c)\)进行建模。后验概率可以表示为:\(p(c|\textbf{x})=\frac{p(c)p(\textbf{x}|c)}{\sum_{c'}p(c')p(\textbf{x}|c')}\)。\(p(c)\)通常设置为均匀分布,因此核心在于估计\(p(\textbf{x}|c)\)。通过逼近数据分布\(\Pi_{x,c}\in\mathcal{D} p(\textbf{x}|c)\)优化生成式分类器的方式也叫做生成式训练。
本文提出的GMMSeg使用了M个多变量高斯分布加权去近似D维编码空间的每个类别:
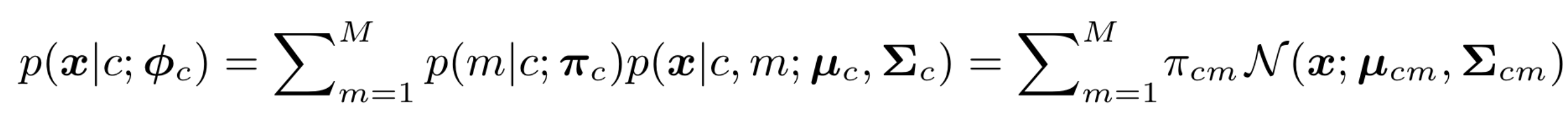
其中\(m|c\sim Multinomial(\textbf{π}_c)\)是先验概率(\(\sum_m π_{cm}=1\)),最右侧就是GMM的形式。\({\phi}_c=\{ \textbf{π}_c,\textbf{μ}_c,\textbf{Σ}_c \}\)为高斯分布的参数。
优化GMM的标准做法是使用EM算法,最大化训练集中特征-标签集合的对数似然:
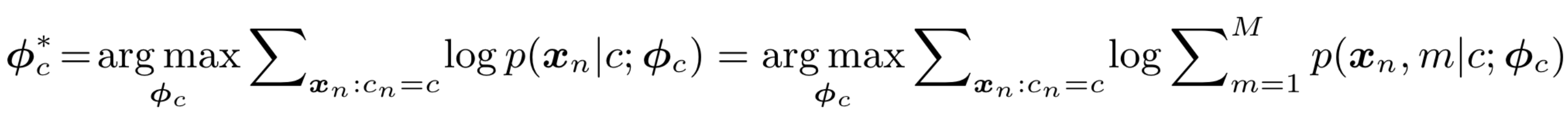
EM算法:
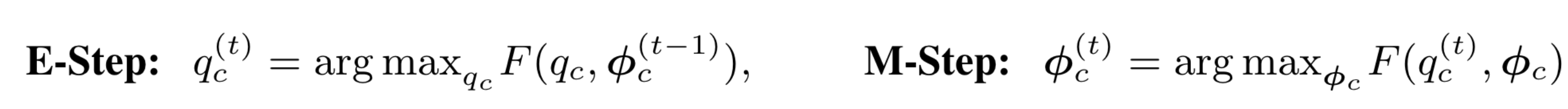
其中\(q_c[m]=p(m|\textbf{x},c;\phi_c)\)表示数据\(\textbf{x}\)分到第m个高斯分量的概率,也就是EM算法中的Q函数。
F:
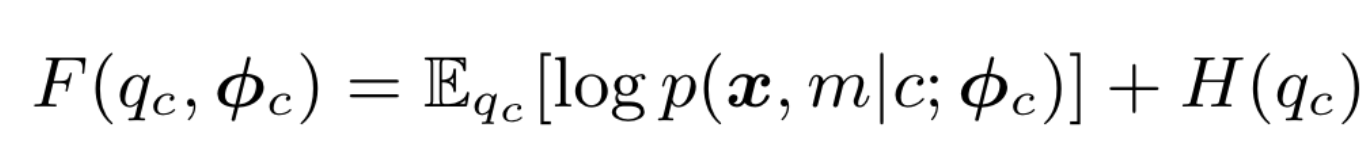
参数更新过程:
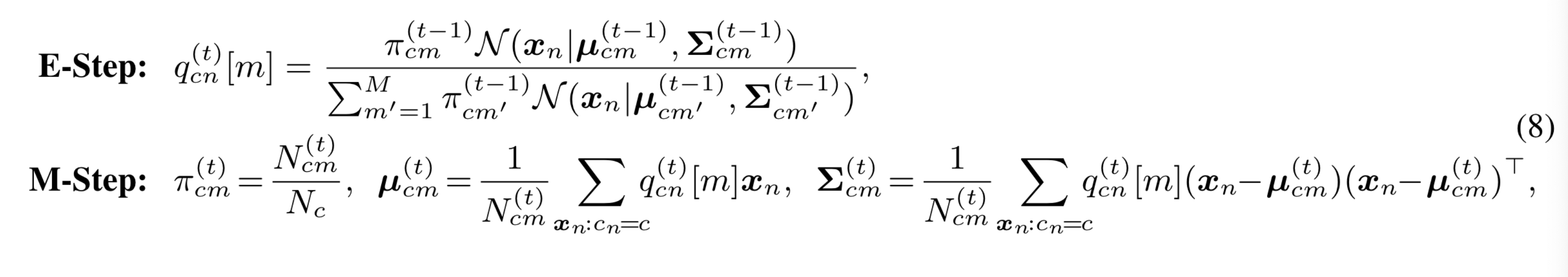
其中\(N_c\)为标签c的训练样本数,\(N_{cm}=\sum_{n:c_n=c}q_{cn}[m]\)。
作者发现标准的EM算法收敛较慢且效果不好,可能的原因为EM算法对于参数的初始值敏感。考虑到基于最优传输的聚类算法,作者将均匀分布先验引入高GMM的权重:\(\forall c,m:\pi_{cm}=\frac{1}{M}\)。这可以直观地看成是一个等分约束引导的聚类过程:在每个类别 c 中,我们希望 \(N_c\) 个像素样本被平均分配到 \(M\) 个高斯分布中。这样E step可以看做熵正则最优传输问题:
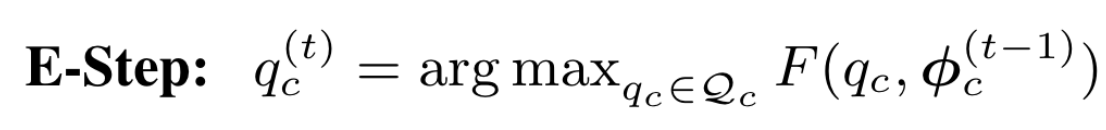
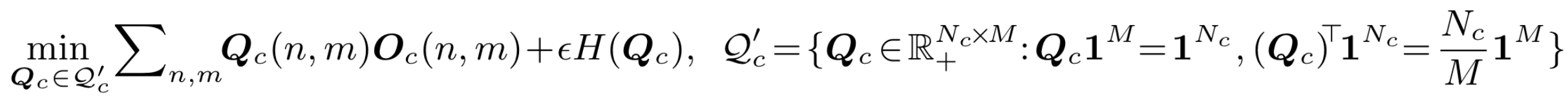
其中传输矩阵\(Q\)可以视作\(N_c\)个样本对于\(M\)个高斯分布的后验分布\(q_c\)(\(\textbf{Q}_c(n,m)=q_{cn}[m]\))。这种优化的方式被称为Sinkhorn EM,能够更好地避开local minima。
训练:分为两部分,分别优化GMM分类器以及特征提取器,

具体的细节见论文。
推理:将提取的特征带入GMM,计算该像素属于当前类别分布的似然,取最大值对应的类别作为结果。
- Segmentation Generative Gaussian Semantic Mixturesegmentation generative gaussian semantic convolutional segmentation networks semantic segmentation criss-cross attention semantic segmentation attentional semantic network segmentation transformers semantic segvit mixture mixture-of-domain-adapters domain mixture-of-domain-adapters pre-trained gaussian nonlinearity estimation gaussian throught