背景
GPT-1 采用了两阶段训练的方式:
1. 第一阶段 pre-training,在海量文本上训练,无需label,根据前k-1个词预测第k个单词是什么,第一阶段的训练让模型拥有了很多的先验知识,模型具有非常强的泛化性
2. 第二阶段在特定任务上fine-tuning,让模型能适应不同的任务,提高模型在特定任务上的准确性
GPT-1 模型采用了Transformer Decoder 结构
训练过程
Unsupervised pre-training
在一个无监督预料集上训练,更加前k-1个词,预测第k个词是什么

Supervised fine-tuning
第二阶段就是在有label的数据集上微调,具体来说就是替换掉第一阶段的最后一层,在监督数据集上训练
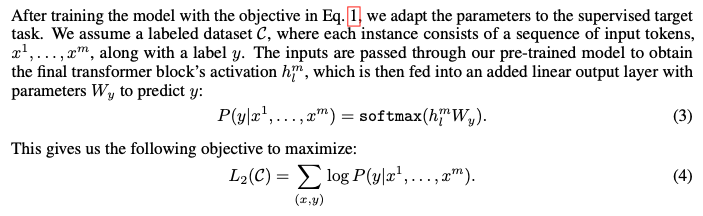
此外作者还发现在第二阶段微调的时候,将语言建模作为微调的辅助目标有助于:
- 提高监督模型的泛化
- 加速收敛
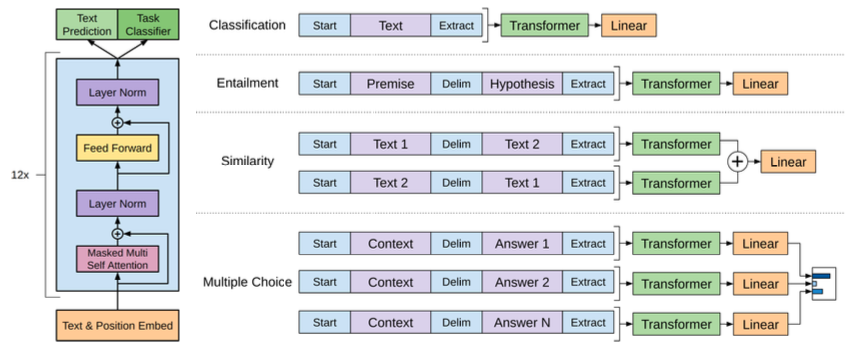
不同训练任务的输入token序列
针对不同的任务,模型的输入token序列是有区别的。简单总结如下:

- Understanding Pre-Training Generative Improving Languageunderstanding pre-training generative improving pre-training generative training模型 pre-training generative networks training vision-language pre-training embodiedgpt embodied language-image pre-training grounded language vision-language understanding enhancing advanced 模态language-image pre-training referring pre-training improving translation augmentation robustness improving