Poisoning Attacks and Counterattacks in Federated Learning
中毒攻击发生在模型训练阶段,而推理攻击则在第一章中讨论,通常发生在模型的测试或预测阶段。
什么是投毒攻击
中毒攻击的目的是破坏模型的训练或降低预期训练模型的有效性,包括延长模型收敛或者拒绝模型收敛。一般来说,中毒攻击可以分为两类:无目标攻击和目标攻击。在无目标攻击类别中,我们可以进一步有两个分支:拒绝服务(DoS)攻击和失真攻击。有针对性的攻击也被称为后门攻击。
在失真攻击类中,攻击者的目标是引导训练过程来实现一个被腐化的模型,从而尽可能地偏离真实的模型。例如,攻击者可以随机打乱数据集图像的标签,然后将它们提供给监督学习算法。
后门攻击是一种复杂的隐形攻击,在模型训练过程中,通过有毒数据在训练后的模型中嵌入一个后门,攻击者可以在实践中使用后门来实现其恶意目标。
中毒攻击是机器学习训练阶段最直接的威胁。联邦学习中的中毒攻击是传统的机器学习系统中毒攻击的自然扩展。
投毒攻击的基础
中毒攻击的基本目标是降低目标模型的整体性能或预测精度。此外,还有其他的高级目标,例如,尽可能多地隐藏攻击的轨迹或精细地控制异常的范围(降低或增加某些指标而使其他指标不受影响,指标包括比如真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN))。
与攻击训练好的模型不同,攻击模型的训练过程可以从根本上降低或破坏合法的功能。因此,投毒攻击成功将带来巨大的影响。例如,如果一个模型是通过后门发布的,那么敌手可以随时实施恶意行为。此外,由于训练集非常庞大(收集自大量的公开实体),不可能仔细检查训练数据集中的所有样本,这为敌手实施攻击提供了机会。
中毒攻击主要有两种目的,即无目标投毒攻击和有目标投毒攻击。
- 没有针对性的投毒攻击会使训练的模型无法使用或导致拒绝服务。
- 在有针对性的投毒攻击中,敌手的目标是训练一个模型,使得其对特定的样本产生敌手期望的预测。
而显然有目标投毒攻击比无目标投毒攻击更难实施。
投毒攻击的分类
无目标投毒攻击
第一类无目标投毒攻击的目的是降低目标模型的整体性能。这类攻击的成功取决于模型的过拟合特征。
第二类无目标投毒攻击的目的是降低某些样品的准确性,同时其他部分保持正常。例如在人脸识别模型中的无目标攻击,敌手只需要降低他自己输入的分类精度;换句话说,只要他自己的输入被错误地分类,攻击就会成功。
有目标投毒攻击
与无目标投毒攻击不同,有目标投毒攻击关注的是目标模型错误预测的类别。敌手强制目标模型在指定的样本上产生异常输出,同时确保其在其他良性样本上的合法功能。例如,在一个数字分类任务中,对手试图迫使模型对数字“7”进行错误分类,同时对其他数字进行正常分类。
无目标投毒攻击中的第二类与有目标投毒攻击的主要区别是:无目标投毒攻击判断攻击成功的标志是敌手需要的输入样本被错误分类(不一定是同一类),其他样本保持正常;而有目标投毒攻击需要使某一类别发生错误,其他类别正常。
后门攻击
在前面描述的两种攻击中,敌手攻击的结果是目标模型的性能下降,这使得模型所有者很容易检测到这些攻击。因此如何隐藏敌手的攻击痕迹,成为敌手所追求的另一个目标。
在二分类任务中,精度、查全率、准确性和f-测量值可以清晰地评价模型的性能。但在多分类任务中,分类结果需要分为几个二分类任务进行评估,如宏精度、查全率、f1测量值和微精度、查全率、f1指标。虽然这些指标仍然可以客观地评价模型的性能,但在评价过程中丢失了很多信息。例如,在一个多分类任务中,无论错误的预测类别是什么,错误都被分类为FN和FP。这就给敌手留下了足够的空间来隐藏他们的攻击路径。
隐藏攻击踪迹的一种直观方法是缩小异常性能的范围,降低目标模型的异常性能。我们将后门投毒攻击归类为有目标投毒攻击的一个子类。如上所述,目标中毒攻击需要保持目标模型的整体性能,并导致对目标输入/输出的不当行为。后门投毒攻击符合这一分类法,而它对激活隐藏后门的样本有更高的要求。在投毒样本中,对手会引入一些模式(称为触发器),以便在模型训练中植入一个后门。只有包含相同触发器的样本才能激活隐藏的后门。
无目标投毒攻击中的第二类与有目标投毒攻击的主要区别是:无目标投毒攻击判断攻击成功的标志是敌手需要的输入样本被错误分类(不一定是同一类),其他样本和往常一样,这种攻击不太管其他样本是否分类正确,也就是说使整体收敛性能下降或使某些输入下的输出错误而其他输入下的输出不管;而有目标投毒攻击需要使某一类别发生错误,其他类别正常。
而后门投毒攻击是有目标投毒攻击的一个子类,其特殊性在于其针对的不光是同一个类别,还需要有相同的模式(触发器),更有针对性和更精确。
投毒攻击的技术
在投毒攻击中,如何构造噪声是最基本的研究问题之一。
-
标签操作
投毒攻击技术中最常用的就是标签操作。通过机器学习学习到的知识主要是基于样本-标签对,因此只要样本-标签对中的固定模式被破坏,机器学习模型的性能就会下降。最直观的实现标签操作的方式是翻转一些样本的标签。最经典的标签操作方法是标签翻转。
标签操作的缺点:标签翻转通常会显著降低模型的性能,因此很容易被检测出来。 -
数据操作
为了实现更复杂的攻击目标,仅仅修改标签是不够的。直观上看,样本空间比翻转标签更有可能实现复杂的攻击。例如,当攻击一个人脸识别模型时,所有使用红框眼镜的图像都被标记为同一个人,这样模型就会认为红框眼镜是这个人的标准。在上述示例中,对手不是简单地修改样本以实现在目标模型中植入后门的目标,而是将图像的某些特征与标签关联起来。这些特征不是某些类的标准,而是一些故意引入了错误的特征标签对。
与标签操作类似,数据操作也需要优化中毒样本的生成以达到最大的攻击效果。中毒样本的生成可以转化为一个优化问题,优化的目标是生成对目标模型的训练阶段影响最大的样本,利用现有的优化方法可以对目标函数进行优化,如基于梯度的优化方法。
基于优化的投毒攻击(数据操作)优点:很好地控制投毒样本,易于实现任何对抗目标;缺点:1.大多方法每次只能产生一个毒样本,效率过低 2.基于梯度的本地优化易陷入局部最优,难找到有效的投毒点
另一种敌手通过辅助模型帮助产生毒样本,两种辅助模型:同构辅助模型和生成模型
(自编码器和生成对抗网络)
3.其他技术
除了使用投毒数据集训练模型外,也可以对开源的训练代码进行投毒攻击。
联邦学习中的投毒攻击
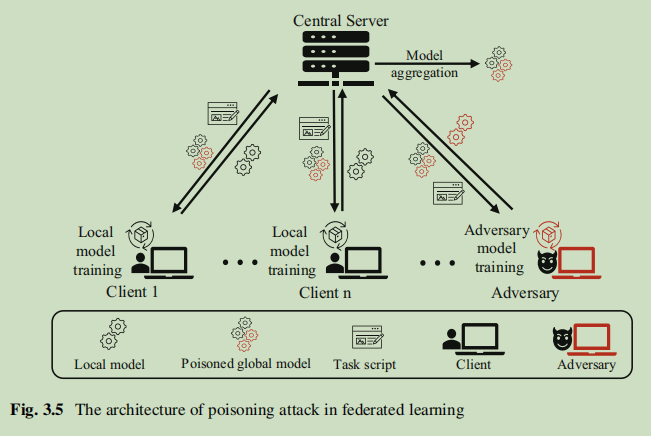
联邦学习本身自带隐私保护属性,但也由于联邦学习的各方数据通常是独立同分布的,因此其也容易收到投毒攻击,投毒攻击的目标通常是使得可信服务器控制的全局模型不能收敛或者在其中植入后门。在联邦学习中,对手经常进行拜占庭式攻击,比如这样的威胁模型:恶意客户端可以向服务器发送任意梯度更新,而良性客户端发送正常的梯度更新。
联邦学习中的投毒攻击可以分为数据投毒攻击和模型投毒攻击。联邦学习中的数据投毒攻击和传统的数据投毒攻击在技术上相同实现这些技术的对象是不同的;在联邦学习中,敌手只能将恶意数据注入或修改到被攻击的客户端的数据集中。而联邦学习中的模型中毒攻击的情况则有所不同:因为客户端是服务器的一个黑盒,所以敌手可以直接操作客户端的本地模型训练过程来实现投毒攻击。Fang等人假设敌手的目标是尽可能地使一个全局模型偏离真正模型,攻击者可以通过在每次迭代中解决一个优化问题来实现这个目标,此外,在联邦学习训练过程中,服务器会将全局模型作为基础信息分配给客户端,敌手则可以在攻击过程中根据全局模型的变化动态修改投毒内容。
联邦学习投毒攻击敌手的挑战来自两个方面:影响限制(小部分妥协的客户端影响有限)以及防御对策设置(例如FedAvg中每轮随机选择不同客户端参与训练,很容易添加防御策略)
联邦学习投毒攻击的效率和隐蔽性非常重要。当有大量用户参与联邦学习时,单个客户端的作用非常有限,因此有些攻击者会放大更新来提高攻击的成功率,但这样很容易被检测到。此外,越多比例的客户端是恶意的(被腐化),则成功的概率越高。一般来说,敌手会遵循训练协议来保持攻击的隐形,而除了被腐化的客户端(敌手)自己没有人会知道他的数据是什么样子的。在Sybil攻击场景中,敌手还可以通过控制多个恶意客户端的行为来执行更复杂的攻击方法,例如分布式后门攻击将全局触发器模式分解到不同的敌手参与方,嵌入其训练数据集中,分解的触发器使得恶意的客户端和良性客户端表现相似(难以检测)。
在联邦学习中防御投毒攻击
由于联邦学习系统是动态的和开放的,在模型训练期间,新的客户端随时可能加入,而现有参与训练的客户端随时可能离开。因此,在训练过程中,服务器必须始终警惕投毒攻击的发生,因为某些新加入的客户端可能会受到损害,也可能新加入的客户端就是恶意的(被敌手所控制的)。
联邦学习中投毒攻击的防御集中在两方面:
- 客户端上传给服务器的数据(数据层面)
- 客户端的表现(表现层面)