SED,AWK使用
1.sed命令
sed使用方法
一种叫命令模式,一种叫脚本模式
命令行模式:
格式
sed [option] 'sed的命令|地址定位' filename
说明:引用shell script中的变量应使用双引号,而非平常使用的单引号
option:
-e:进行多项编辑,即对输入行应用多条sed命令时使用
-n:取消默认的输出
-f:指定sed脚本的文件名
-r:使用扩展正则表达式
-i inplace,原地编辑
ps:-i和-n不能一起使用,否则会清空原有文件
-i和'p'不能一起使用
[root@jumpserver ~]# sed 'p' 1.txt
#version=DEVEL
#version=DEVEL
10.40.166.3
10.40.166.3
# System authorization information
# System authorization information
auth --enableshadow --passalgo=sha512
auth --enableshadow --passalgo=sha512
# Use CDROM installation media
# Use CDROM installation media
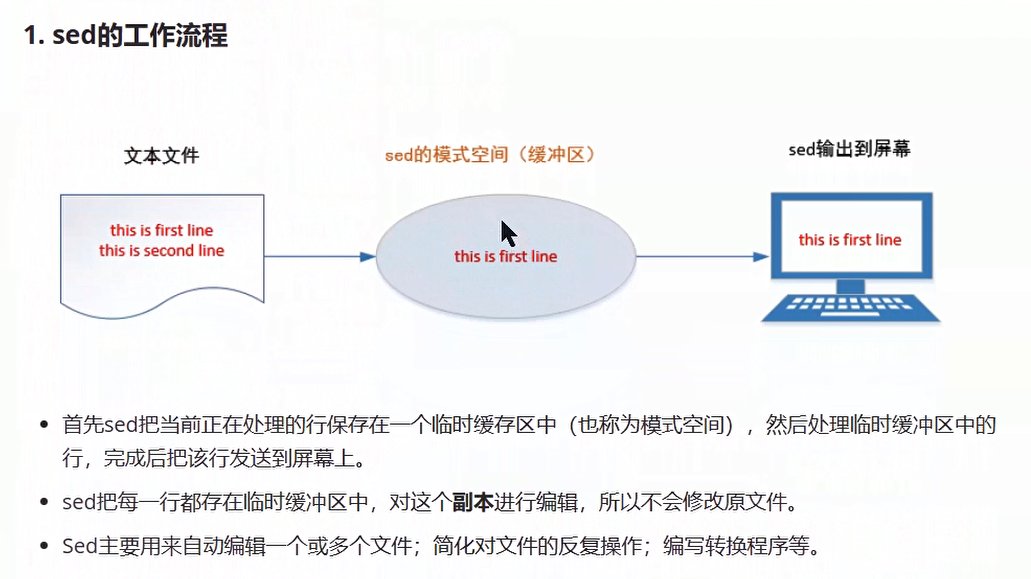
当我们去打印的时候会发现,我们的每一行都打印了两次,因为第一行是将其放在缓冲区中所显示的,
面对这种情况我们可以选择-n取消默认的输出
常用命令和选项
p :打印行
d :删除行
i:在当前行之前插入文本
a:在当前行后添加一行或者多行
c:替换匹配到的这一行
ps:在vim编辑器中,在上一行插入文本为大写O,在下一行插入文本是小写o
#打印第一行
[root@jumpserver ~]# sed -n '1p' 1.txt
#version=DEVEL
#删除第一行
[root@jumpserver ~]# sed -n '1d' 1.txt
打印1-3行
[root@jumpserver ~]# sed -n '1,3p' 1.txt
#version=DEVEL
10.40.166.3
# System authorization information
#在每一行的上一行插入hello
[root@jumpserver ~]# sed 'ihello' 1.txt
hello
#version=DEVEL
hello
10.40.166.3
hello
# System authorization information
hello
auth --enableshadow --passalgo=sha512
hello
# Use CDROM installation media
#在第一行之前插入hello
[root@jumpserver ~]# sed '1ihello' 1.txt
hello
version=DEVEL
10.40.166.3
System authorization information
auth --enableshadow --passalgo=sha512
Use CDROM installation media
#在第一行之前插入两行hello
[root@jumpserver ~]# sed '1ihello\nhello' 1.txt
hello
hello
version=DEVEL
10.40.166.3
System authorization information
auth --enableshadow --passalgo=sha512
Use CDROM installation media
#在最后一行之后添加
[root@jumpserver ~]# sed '$ahello' 1.txt
#用100.100.100.1替换第二行
[root@jumpserver ~]# sed '2c100.100.100.1' 1.txt
version=DEVEL
100.100.100.1
System authorization information
auth --enableshadow --passalgo=sha512
Use CDROM installation media
#把包含有version关键字的那一行替换成helloworld
[root@jumpserver ~]# sed '/version/chello world' 1.txt
[root@jumpserver ~]# sed '/[a-z]/chelloworld' 1.txt
helloworld
10.40.166.3
helloworld
helloworld
helloworld
r 从文件中读取输入行
w 将所选的行写入文件
# 将文件/etc/hosts文件放在当前1.txt文件下读取
[root@jumpserver ~]# sed '3r /etc/hosts' 1.txt
version=DEVEL
10.40.166.3
System authorization information
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
auth --enableshadow --passalgo=sha512
Use CDROM installation media
[root@jumpserver ~]# sed '1,3w ./a.txt' 1.txt
ps:sed -r 就可以实现扩展正则了
#将1.txt文件里面有四个连续数字的那一行写入a.txt文件
[root@jumpserver ~]# sed '/[0-9]\{4\}/w a.txt' 1.txt
! 对所选行以外的所有行应用命令,放到行数之后
过滤有ip地址的那一行
[root@jumpserver ~]# sed -rn '/([0-9]{1,3}\.){3}[0-9]{1,3}/p' 1.txt
s 用一个字符串替换另一个
g 在行内进行全局替换
类似与vi编辑器中s和g的用法
#使用VERSION替换version
[root@jumpserver ~]# sed -n 's/version/VERSION/p' 1.txt
VERSION=DEVEL
ps:分隔符不一定要使用/。可以选择#或者其他符号
#在1-5行行首+#号
[root@jumpserver ~]# sed -n '1,5s/^/#/gp' 1.txt
#删除文件里面的/:.
sed -n 's/[/:n]//gp' 1.txt
&:保存查找串以便在替换串中引用 \(\) 它能保存你前面所查找的串,在替换时候,若你需要使用,直接使用&就可以代替它。
例如:
[root@jumpserver ~]# sed -n 's/version/& 1.1/gp' 1.txt
[root@ecs-shell ~]# cat shadow
root:$6$MisAYPlR$txZjLIpoiTq6.B5x.JrIdkxdPwyiuLfeqU77RKwSl5jtkEUfN/oYvvGhIZ9pbas1YLlpLp1m4B0aWkYNZ.8nc0:19702:0:99999:7:::
#这两者相似:两者不同之处在于,\(\)可以用作选择性保留。
[root@ecs-shell ~]# sed -n 's/root/&adm/gp' shadow
rootadm:$6$MisAYPlR$txZjLIpoiTq6.B5x.JrIdkxdPwyiuLfeqU77RKwSl5jtkEUfN/oYvvGhIZ9pbas1YLlpLp1m4B0aWkYNZ.8nc0:19702:0:99999:7:::
[root@ecs-shell ~]# sed -n 's/\(root\)/\1adm/gp' shadow
rootadm:$6$MisAYPlR$txZjLIpoiTq6.B5x.JrIdkxdPwyiuLfeqU77RKwSl5jtkEUfN/oYvvGhIZ9pbas1YLlpLp1m4B0aWkYNZ.8nc0:19702:0:99999:7:::
#将含有root的那一行的^root前加上#
[root@ecs-shell ~]# sed -nr '/root/s/^root/#&/pg' /etc/passwd
#root:x:0:0:root:/root:/bin/bash
=:打印行号
#获取文件以bash结尾的行号
[root@jumpserver ~]# sed -n '/bash$/=' /etc/passwd
1
22
23
[root@ecs-shell ~]# sed -n '/:$/=' shadow
1
-e:多次编辑的含义
[root@ecs-shell ~]# sed -ne '/bash$/=' -ne '/bash$/p' /etc/passwd
1
root:x:0:0:root:/root:/bin/bash
22
stu1:x:1000:1000::/home/stu1:/bin/bash
23
jerry:x:1001:1001::/home/jerry:/bin/bash
-i:直接对原文件进行修改 慎用!
-i一般不能和-n一起用,不能使用p
[root@ecs-shell ~]# sed -i 's/root/ROOT/g' passwd
[root@ecs-shell ~]# cat passwd
ROOT:x:0:0:ROOT:/ROOT:/bin/bash
过滤掉文件当中的空行和注释行
# grep -v '^#' /etc/vsftpd/vsftpd.conf | grep -v '^$' or
# grep -E -v '^#|^$' /etc/vsftpd/vsftpd.conf or
# sed -ner '/^#|^$/' /etc/vsftpd/vsftpd.conf
# sed -e '/^#/d' -e'/^$/d' /etc/vsftpd/vsftpd.conf
# sed '/^#/d;/^$/d' /etc/vsftpd/vsftpd.confF
过滤掉smb.conf中的空行,注释等
[root@jumpserver ~]# sed -r '/(^#|^$|^:|\t)/d' smb.conf
过滤出/etc/sysconfig/network-script/ifcfg-ens33里面的ip地址,子网掩码和dns服务器地址。
[root@jumpserver ~]# sed -n -r '/^(GATEWAY|DNS1|NETMASK)/p' /etc/sysconfig/network-scripts/ifcfg-ens33 |sed -n -r 's/([A-Z]|=)//pg'
192.168.208.2
1192.168.208.2
255.255.255.0
从以下结果中过滤出ip地址,dns服务器地址,和子网掩码地址
[root@jumpserver ~]# ifconfig ens33
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.208.17 netmask 255.255.255.0 broadcast 192.168.208.255
inet6 fe80::651d:b792:addb:5e53 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:51:c9:5c txqueuelen 1000 (Ethernet)
RX packets 35126 bytes 17623506 (16.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 17956 bytes 1607125 (1.5 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@jumpserver ~]# ifconfig ens33 |sed -n '2p' |sed -n -r 's/[a-z]//pg'|sed -n 's/ /\n/pg'|sed '/^$/d'
192.168.208.17
255.255.255.0
192.168.208.255
sed脚本
sed脚本的执行方式
#使用脚本处理文件
sed -f scripts.sed file
,/sed.sh file
脚本第一行写
#!/bin/sed -f
1,5d
s/root/ROOT
3i777
5i888
/root/p
1)脚本文件是一个sed的清单
2)在每行的末尾不能有任何空格,制表符或其他文本
3)如果在一行中有多个命令,应该用分号隔开
4)不需要不可用引号保护命令
5)#号开头的为注释

#!/bin/bash
ip=$(sed -n '/IPADDR/p' /etc/sysconfig/network-scripts/ifcfg-ens33|sed -n -r 's/([A-Z]|=)//pg')
ip1=$(cut -d. -f4 $ip)
name=server$ip1.itcast.cc
echo $name > /etc/hostname
#自动配置可用的yum源
[ -f /etc/yum.repos.d/CentOS-Base.repo.bak1 ]&&rm -rf /etc/yum.repos.d/CentOS-Base.repo.bak1 || mv CentOS-Base.repo CentOS-Base.repo.bak1
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
if [ $? -eq 0 ];then
yum clean all
yum makecache
fi
#自动关闭防火墙和selinux
systemctl stop firewalld
setenforce 0
2.awk

awk命令模式语法
[root@server ~]# awk 选项 'command' 文件名
常用选项:
F:定义字段分隔符,默认的分隔符为空格
v:定义变量并赋值
command部分
正则表达式,地址定位
#打印含root那一行的
cat passwd | awk '/root/{awk语句}'
#打印1-5行
cat passwd | awk -F":" 'NR==1,NR==5{print $0}'
'/^root/,/^ftp/{awk语句}':/(^root|^ftp)/p
{awk语句1;awk语句2;...}
'{print $0,print $1}' sed中:'p'
'NR==5{Print $0}' sed中:'5p'
ps:awk语句之间用;隔开
BEGIN END
'BEGIN{awk语句};{处理中};END{awk语句}'
'BEGIN{awk语句};{处理中}'
'{处理中};END{awk语句}'
脚本模式
脚本执行
方法一:
awk 选项 -f awk脚本文件 要处理的文本文件
awk -f awk.sh a.txt
sed -f sed.sh -i a.txt sed修改源文件
方法二:
./awk的脚本文件(或脚本文件) 要处理的文本文件
./awk.sh filename
./sed.sh filename
脚本的编写
#!/bin/awk -f 定义魔法字符
以下awk的命令清单,不要用引号保护命令,多个命令用分号分隔
BEGIN{FS=":"}
NR==1,NR==3{print $1"\t"$NF}
...
打印文件的第一列,和最后两列
[root@server ~]# awk -F: '{ print $1,$(NF-1),$NF }' 1.txt
#打印匹配root关键字的那一行
[root@server ~]# awk '/^root/{print $0}' 1.txt
root:x:0:0:root:/root:/bin/bash
#打印前五行
[root@server ~]# awk 'NR==1,NR==5{print $0 }' 1.txt
[root@server ~]# awk 'NR==1,NR==5' 1.txt
#打印前五行中以root关键字开头或者以adm开头的
[root@server ~]# awk 'NR==1,NR==5' 1.txt | awk '/(^adm|^root)/{print $0}' 1.txt
[root@server ~]# awk 'NR==1,NR==5' 1.txt | awk '/(^adm|^root)/{print $0}' 1.txt
#打印从root开头的和adm的行
[root@server ~]# awk '/^root/,/^lp/{print $0}' 1.txt
[root@server ~]# awk -F: '/^root/,/^lp/{print $1,$NF}' 1.txt
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
我们会发现每一列都默认为空格隔开,所以我们可以选择"我们选择的分隔符"
[root@server ~]# awk -F: '/^root/,/^lp/{print $1"的bash为"$NF}' 1.txt
root的bash为/bin/bash
bin的bash为/sbin/nologin
daemon的bash为/sbin/nologin
adm的bash为/sbin/nologin
lp的bash为/sbin/nologin
除了以上-F定义间隔符的方法我们也可以选择使用BEGIN去定义
[root@server ~]# awk 'BEGIN{FS=":"}; /^root/,/^adm/{print $1,$NF}' 1.txt
#在begin中定义输出字段分隔符
[root@server ~]# awk -F: 'BEGIN{OFS="\t\t"};/root/{print $1,$NF}' 1.txt
RS: 判断awk在读取配置文件时,如何判断是否为一行,例如我们在BEGIN中指定RS="\t"
则每当我们遇到"\t"就认为它换行了.我们就可以对新的文件进行操作
ORS:当给此参数值时,我们在输出我们的文本时,会以我们所设置的换行符对每一行文字进行分割。
例如:
[root@server ~]# awk -F: '{ORS="\t\t"};{print $1,$NF}' 1.txt
root /bin/bash bin /sbin/nologin daemon /sbin/nologin adm /sbin/nologin lp /sbin/nologin sync /bin/sync shutdown /sbin/shutdown halt /sbin/halt mail /sbin/nologin operator /sbin/nologin
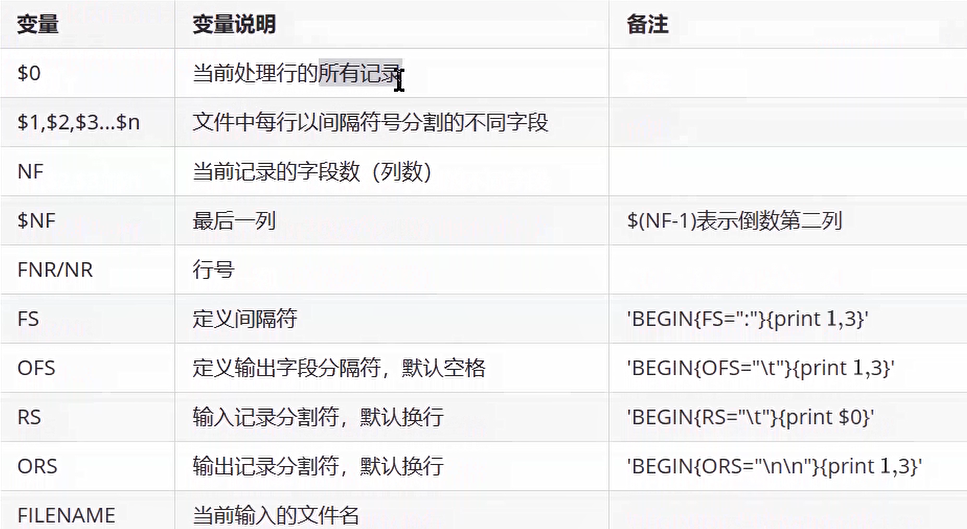
NF

awk定义变量
awk中定义的变量不需要$
在大括号里{print $num}和{print num}前一个是打印第num行,后一个是打印num
#打印第一列
[root@server ~]# awk -v num=1 -F: '{print $num}' 1.txt
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
#文件处理之前打印num这个变量
[root@server100 awk]# awk -v num=1 'BEGIN{print num}'
1
#打印num变量
[root@server ~]# awk -v num=1 -F: '{print num}' 1.txt
1
1
1
1
1
1
1
1
1
1
awk中BEGIN..END使用
1.BEGIN:表示在程序开始前执行
2.END:表示所有文件处理后执行
3用法:‘BEGIN{};{执行中};END{}’
练习:
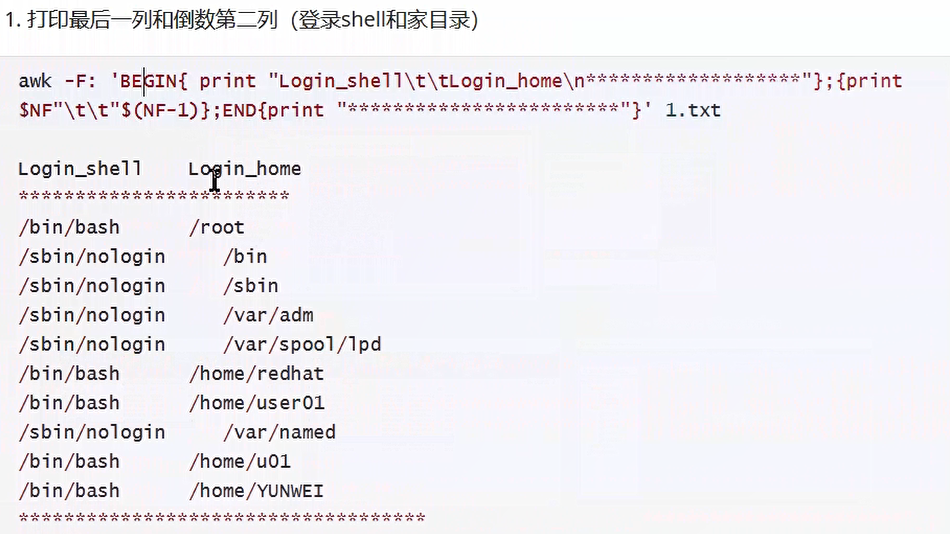
[root@server ~]# awk -F: 'BEGIN{print "login_shell\t\tlogin_home\n******************"};{print $NF"\t\t"$(NF-1)};END{print "*****************"}' 1.txt
login_shell login_home
******************
/bin/bash /root
/sbin/nologin /bin
/sbin/nologin /sbin
/sbin/nologin /var/adm
/sbin/nologin /var/spool/lpd
/bin/sync /sbin
/sbin/shutdown /sbin
/sbin/halt /sbin
/sbin/nologin /var/spool/mail
/sbin/nologin /root
*****************
[root@server100 awk]# cat passwd | awk -F: 'BEGIN{OFS="\t\t";print "login_shell\t\tlogin_home\n***************************************"};{print $NF,$(NF-1)};END{print "*****************************************"} '
login_shell login_home
***************************************
/bin/bash /root
/sbin/nologin /bin
/sbin/nologin /sbin
/sbin/nologin /var/adm
/sbin/nologin /var/spool/lpd
/bin/sync /sbin
/sbin/shutdown /sbin
/sbin/halt /sbin
/sbin/nologin /var/spool/mail
/sbin/nologin /ROOT
/sbin/nologin /usr/games
/sbin/nologin /var/ftp
/sbin/nologin /
/sbin/nologin /
/sbin/nologin /
/sbin/nologin /
/sbin/nologin /var/spool/postfix
/sbin/nologin /var/empty/sshd
/sbin/nologin /var/lib/chrony
/sbin/nologin /
/sbin/nologin /dev/null
/bin/bash /home/tune
*****************************************
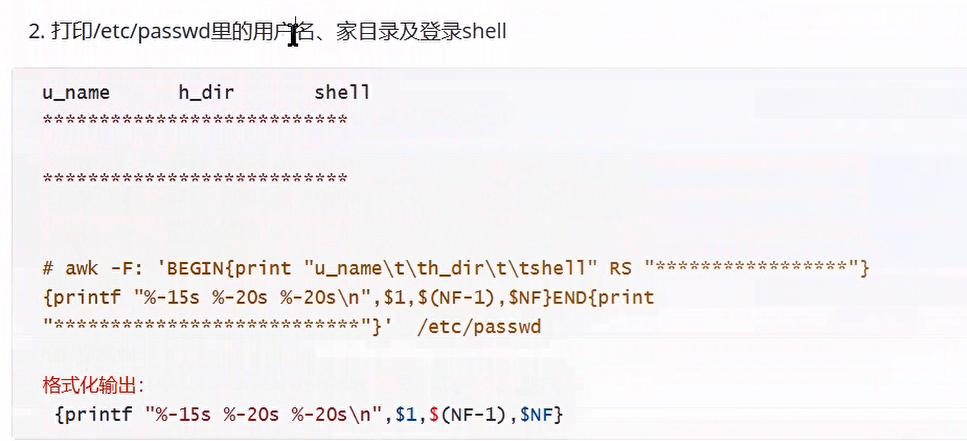
[root@server ~]# awk -F: 'BEGIN{print "u_name\t\th_dir\t\tshell\n******************************************************************"};{print$1"\t\t"$6"\t\t"$NF};END{print "******************************************************************"}' /etc/passwd
我们会发现这样并不美观
我们需要对其进行改动
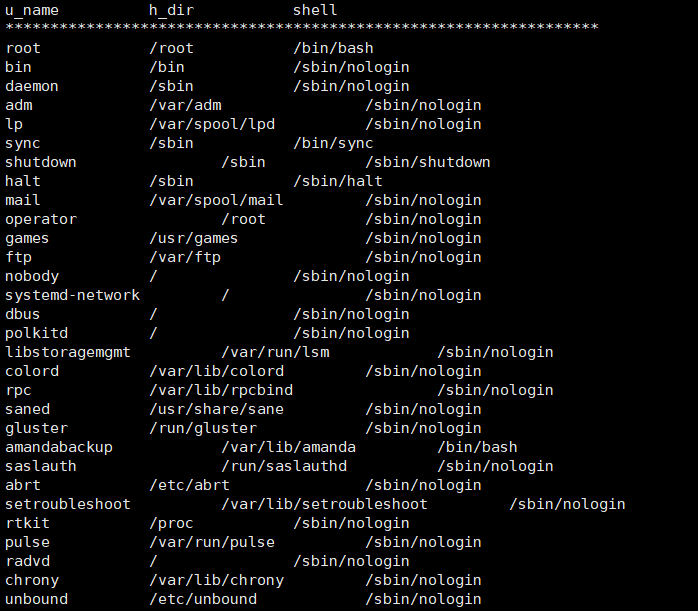
awk的格式化输出
printf函数 类似于echo -n
#awk -F: '{printf "%-15s %-10s %-15s\n",$1,$2,$3}' /etc/passwd
%-15s:
%s:为字符输出
-:左对齐
15:字符长度
[root@server ~]# awk -F: 'BEGIN{print "u_name\t\th_dir\t\tshell\n******************************************************************"};{printf "%-15s %-20s %-15s\n", $1,$6,$NF};END{print "******************************************************************"}' /etc/passwd
#使用print(原来的样子)
[root@server100 awk]# cat passwd | awk -F: 'BEGIN{OFS="\t\t";print "u_name\t\t_dir\t\tshell\n********************************************************"};{print $1,$(NF-1),$(NF)};END{print "********************************************************"}'
u_name _dir shell
********************************************************
root /root /bin/bash
bin /bin /sbin/nologin
daemon /sbin /sbin/nologin
adm /var/adm /sbin/nologin
lp /var/spool/lpd /sbin/nologin
sync /sbin /bin/sync
shutdown /sbin /sbin/shutdown
halt /sbin /sbin/halt
mail /var/spool/mail /sbin/nologin
operator /ROOT /sbin/nologin
games /usr/games /sbin/nologin
ftp /var/ftp /sbin/nologin
nobody / /sbin/nologin
systemd-network / /sbin/nologin
dbus / /sbin/nologin
polkitd / /sbin/nologin
postfix /var/spool/postfix /sbin/nologin
sshd /var/empty/sshd /sbin/nologin
chrony /var/lib/chrony /sbin/nologin
tcpdump / /sbin/nologin
tss /dev/null /sbin/nologin
tune /home/tune /bin/bash
********************************************************
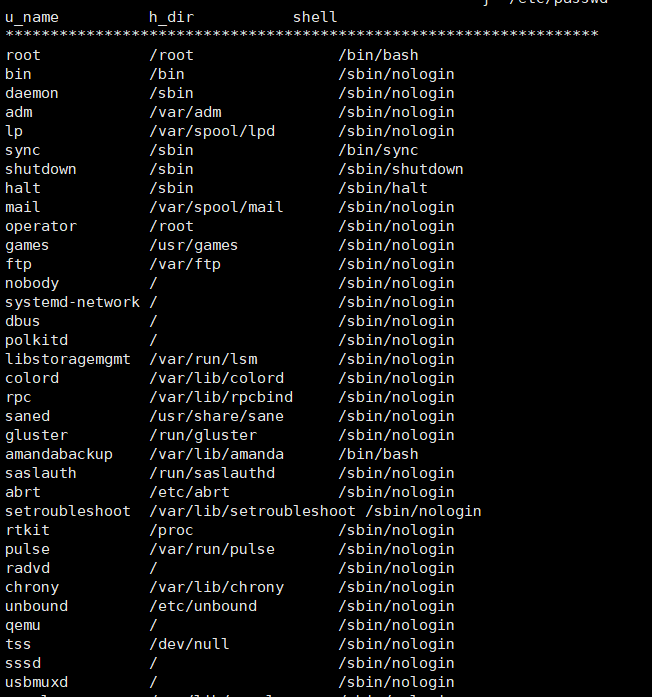
#使用printf
[root@server100 awk]# cat passwd | awk -F: 'BEGIN{OFS="\t\t";print "u_name\t\t_dir\t\tshell\n********************************************************"};{printf "%-15s %-15s %-15s\n",$1,$(NF-1),$(NF)};END{print "********************************************************"}'
u_name _dir shell
********************************************************
root /root /bin/bash
bin /bin /sbin/nologin
daemon /sbin /sbin/nologin
adm /var/adm /sbin/nologin
lp /var/spool/lpd /sbin/nologin
sync /sbin /bin/sync
shutdown /sbin /sbin/shutdown
halt /sbin /sbin/halt
mail /var/spool/mail /sbin/nologin
operator /ROOT /sbin/nologin
games /usr/games /sbin/nologin
ftp /var/ftp /sbin/nologin
nobody / /sbin/nologin
systemd-network / /sbin/nologin
dbus / /sbin/nologin
polkitd / /sbin/nologin
postfix /var/spool/postfix /sbin/nologin
sshd /var/empty/sshd /sbin/nologin
chrony /var/lib/chrony /sbin/nologin
tcpdump / /sbin/nologin
tss /dev/null /sbin/nologin
tune /home/tune /bin/bash
********************************************************
经过格式化输出,我们会发现此时显示较之前美观
awk与正则表达式的混合使用
#从第一行开始匹配到lp开头的行
[root@server ~]# awk 'NR==1,/lp/{print $0}' 1.txt
#打印从第五行到第六行
[root@server ~]# awk 'NR==5,NR==6' 1.txt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
[root@server ~]# awk 'NR>=5&&NR<=6' 1.txt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
#打印第五行或第六行
[root@server ~]# awk 'NR==5||NR==6' 1.txt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
打印以root开头或者以lp开头的行
[root@server ~]# grep -E '(^root|^lp)' 1.txt
[root@server ~]# sed -n -r '/(^root|^lp)/p' 1.txt
root:x:0:0:root:/root:/bin/bash
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@server ~]# awk '/^root/ || /^lp/ {print $0}' 1.txt
或者
[root@server ~]# awk '/^root|^lp/ {print $0}' 1.txt
即在正则表达式中一个|为或逻辑表达式中两个||为或
练习:从ifconfig里面提取ip地址
[root@server ~]# ifconfig ens33
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.208.17 netmask 255.255.255.0 broadcast 192.168.208.255
inet6 fe80::651d:b792:addb:5e53 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:51:c9:5c txqueuelen 1000 (Ethernet)
RX packets 21279 bytes 1642627 (1.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10928 bytes 1149666 (1.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@ecs-shell ~]# ifconfig | awk 'NR==2'
inet 192.168.1.173 netmask 255.255.255.0 broadcast 192.168.1.255
[root@ecs-shell ~]# ifconfig | awk 'NR==2'| awk -F"[ :]+" 'BEGIN{OFS="\n"};{print $3,$5,$7}'
192.168.1.173
255.255.255.0
192.168.1.255
awk流程控制
if语句
类似与linux的shell:
if语句:
if [xxx];then
xxx
fi
格式
awk [选项] '正则,地址定位{awk语句}' 文件名
{if(表达式){语句1;语句2;...}
练习:
[root@server ~]# awk -F: '{if($3>=1000&&$3<=65535){print $1, $3}}' /etc/passwd
[root@server ~]# awk -F: '{if( $7=="/bin/bash" ){print $1"是用户自己创建的"} else {print $1"是系统创建的"}}' /etc/passwd
if语句
if[xxx];then
xxx
else if[xxx];then;
xxx
else
xxx
在awk当中 :{if(){}else if(){}else if(){} else{}}
例如:判断用户为自己创建的还是系统用户
[root@server ~]# awk -F: '{if ($3==0) {print $1"是管理员"}else if($3>=1&&$3<=1000){print $1"为系统用户"} else {print $1"为用户自己创建的"}}' /etc/passwd
计算各种用户的数量
[root@server ~]# awk -F: 'BEGIN{};{if ($3==0) {i++}else if($3>=1&&$3<=1000){j++} else {k++}};END{print"管理员用户的数量为"i; print "系统用户数量为"j;print"普通用户数量为"k}' /etc/passwd
awk循环
while:
awk 'BEGIN{i=1;while(i<=5){print i i++ }}'
for:
[root@server ~]# awk 'BEGIN{for(i=1;i<=5;i++){print i}}'
1
2
3
4
5
[root@server ~]# awk 'BEGIN{i=1;while(i<=5){print i;i=i+2}}'
1
3
5
[root@server ~]# awk 'BEGIN{i=1;while(i<=10){print i;i=i+2}}'
#计算1-5的和
[root@server ~]# awk 'BEGIN{i=1;sum=0;while(i<=5){sum=sum+i;i++;}{print sum}}'
#计算1-10奇数的和
[root@server ~]# awk 'BEGIN{sum=0;for(i=1;i<=10;i+=2){sum=sum+i}{print sum}}'
#打印一个图形
[root@server ~]# awk 'BEGIN{for(i=1;i<=5;i++){for(j=1;j<=i;j++){printf j}print}}'
awk的算术运算
[root@server ~]# awk 'BEGIN{print 1*1}'
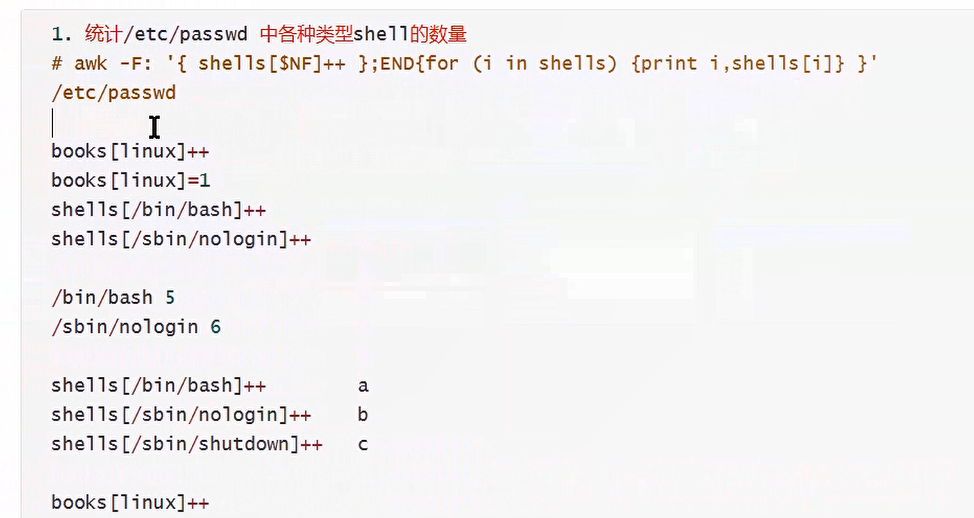
#代码
[root@server ~]# awk -F: '{shells[$NF]++};END{for (i in shells){print i,shells[i]}}' /etc/passwd
从关联数组中获取下标:for(i in shells)