1. 前言
AlexNet是一个深度卷积神经网络模型,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton于2012年设计。这个模型在ImageNet图像识别挑战赛中获得了当时的冠军,并推动了卷积神经网络在计算机视觉中的广泛应用。
AlexNet包括5个卷积层和3个全连接层,使用了大量的ReLU非线性激活函数和Dropout正则化技术。此外,AlexNet还使用了数据增强、随机裁剪和LRN局部响应归一化等技术来提高模型的鲁棒性。
AlexNet的设计还采用了两个GPU并行计算的策略,可以显著减少训练时间。此外,AlexNet还将GPU的显存用于存储中间结果,从而降低了内存瓶颈的影响。
AlexNet在当时的ImageNet图像识别挑战赛上获得了15.3%的top-5错误率,比第二名低了*10个百分点,标志着深度卷积神经网络在计算机视觉中的应用开始进入黄金时期。
虽然这篇文章中用到的很多trick,在后面的研究中被证明是无效的,但是这是第一次在ImageNet这么大的数据集上使用CNN进行模型训练,而且最后的结果吊打其他传统的算法,具有划时代的意义。
本篇论文的重点有,end-to-end训练,relu激活函数,数据增强,LRN,DROPOUT,OVERLAP POOLING。
2. 网络结构

如上图所示,Alexnet有5个卷积层和三个全连接层,因为时代的原因,无法在训练的时候将数据塞入一个GPU进行训练,因此作者花了很多力气将模型放到两个显卡中进行训练(虽然后面大家认为没什么用,并不采用这种方式)。
可以看到,第一个卷积层分为两部分,kernel窗口的尺寸是11*11,两部分各自卷积,后面接relu+LRN+Max pooling形成自己的feature map;第二卷积层也是各自卷积,后面接relu+LRN+Max pooling,直到第三个卷积层每个部分的卷积核才会去看另外一个GPU中的feature map……第五个卷积层之后,分别全连接两个2048*2的全连接,输出4096维的特征向量(后面用来进行特征距离计算就是用这一层的输出),最后与连接到1000个神经元的全连接层,后面接一个softmax,输出每个种类的概率。
现在看来,一个是没必要分多GPU进行训练,二是全连接层神经元太多,导致后面的参数太大。
3. RELU激活函数
相比于传统饱和的激活函数sigmod和tanh,本文采用了非饱和的relu激活函数,使得在输入的值很大的时候,也不会造成梯度消失,而且relu更加简单,速度更快,也更容易收敛,如下图所示,4层CNN在cifar-10上进行训练,收敛到训练误差为0.25,使用relu比使用tanh快6倍。

4. LRN
Local Response Normalization,局部响应归一化,目的是为了抑制临*通道的高激活值,使得泛化性能更好。
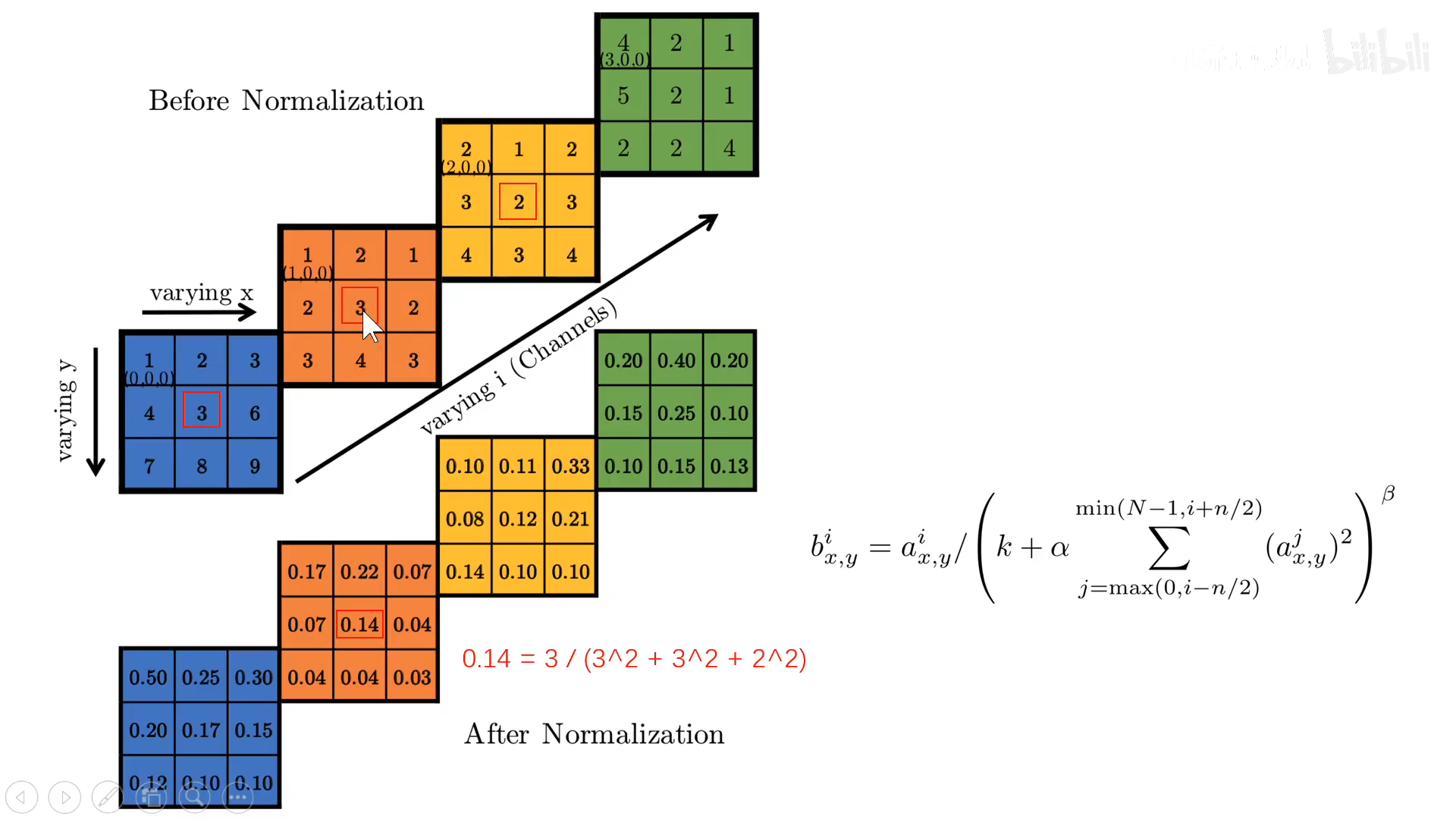 实际上,就是在摞起来的feature map上,沿着通道的方向,对每一个需要归一化的值,除以临*值的*方和,以第二层feature map最中间的值3为例,他的归一化值就是除以临*通道的的*方和,也就是下面红色的式子。当然最终采用的右边的公式会稍微复杂,k是为了防止分母为零,N为feature map通道数,n表示往左右看多少个通道,α为系数项,β为指数项,最后作者们通过交叉验证,得到最好的结果为,k,α,β,n=2,10^-4,0.75,5。
实际上,就是在摞起来的feature map上,沿着通道的方向,对每一个需要归一化的值,除以临*值的*方和,以第二层feature map最中间的值3为例,他的归一化值就是除以临*通道的的*方和,也就是下面红色的式子。当然最终采用的右边的公式会稍微复杂,k是为了防止分母为零,N为feature map通道数,n表示往左右看多少个通道,α为系数项,β为指数项,最后作者们通过交叉验证,得到最好的结果为,k,α,β,n=2,10^-4,0.75,5。
后面LRN在VGG中,被证明为没什么作用,而且后面有了更牛逼的BN,因此后面算法,普遍没采用LRN这种归一化的方法。
5. Overlapping Pooling
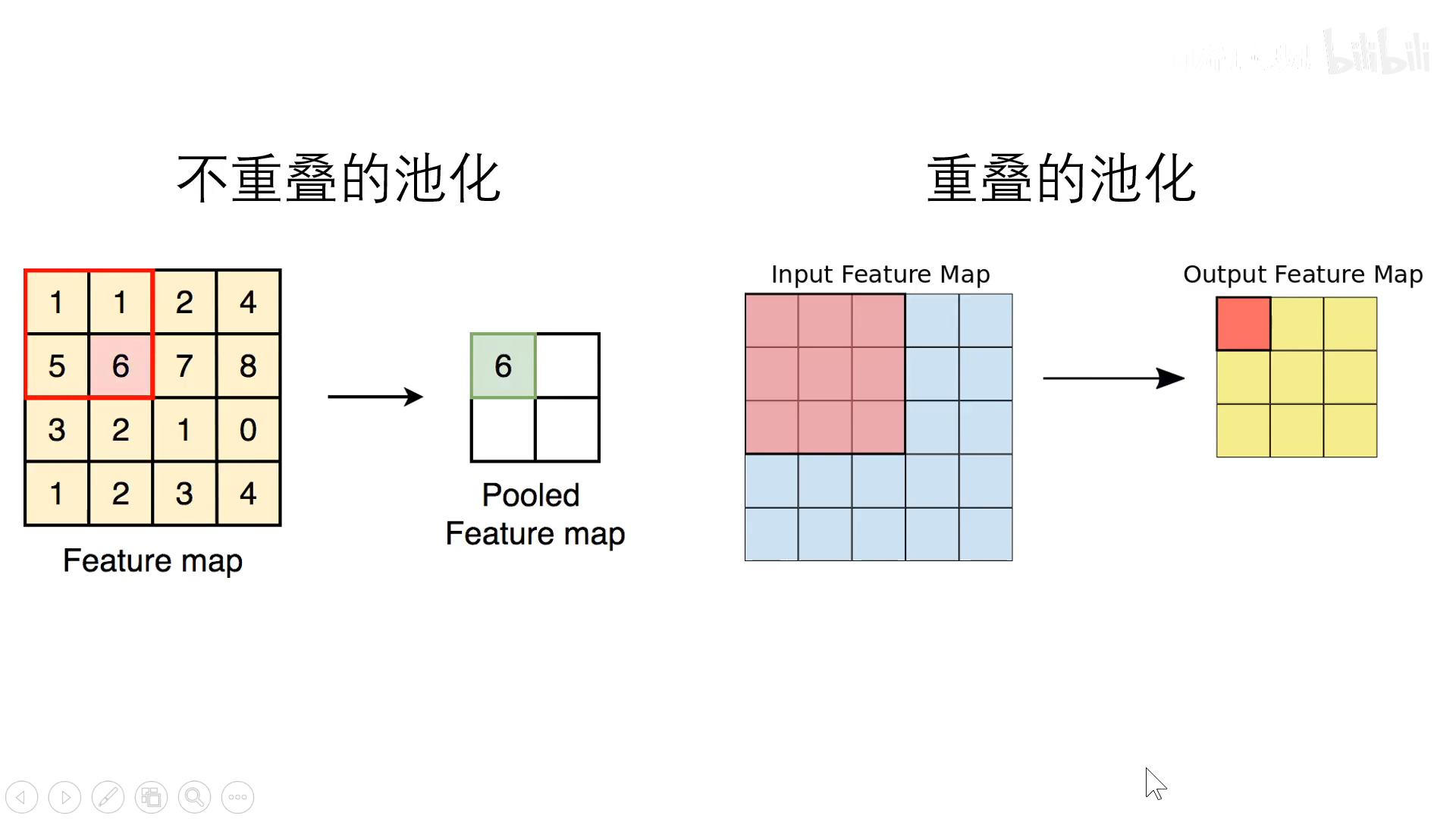
重叠池化,如上图所示,左边的是传统的池化,池化窗口尺寸等于stride步长,因此在池化的时候,是没有重叠的;右边是重叠池化,stride步长小于池化窗口,因此在池化的时候,是有重叠的,作者认为使用重叠池化能够减少过拟合,不过后面也被证明为意义不大,因此后续也没有被其他人采用。
6. 数据增强

数据增强主要目的是扩充数据集,防止过拟合,本文主要使用了两种数据增强的方式:
- 随机裁剪*移+水*翻转:
从256*256*3的图片中,随机裁剪224*224*3,在长度和宽度的方向都有256-224=32种裁发,加上水*翻转,因此本文中说有32*32*2=2048种方式进行增强。其实我们现在知道,这些裁剪出来的图片其实很相似,这种裁剪方式意义不大,一般来说,ten crop效果会比较好。
- 颜色光照变换:
通过在通道上使用PCA主成分分析的方式,算出3*3协方差矩阵的特征值特征向量,最后再加入随机数进行变换。
7. dropout
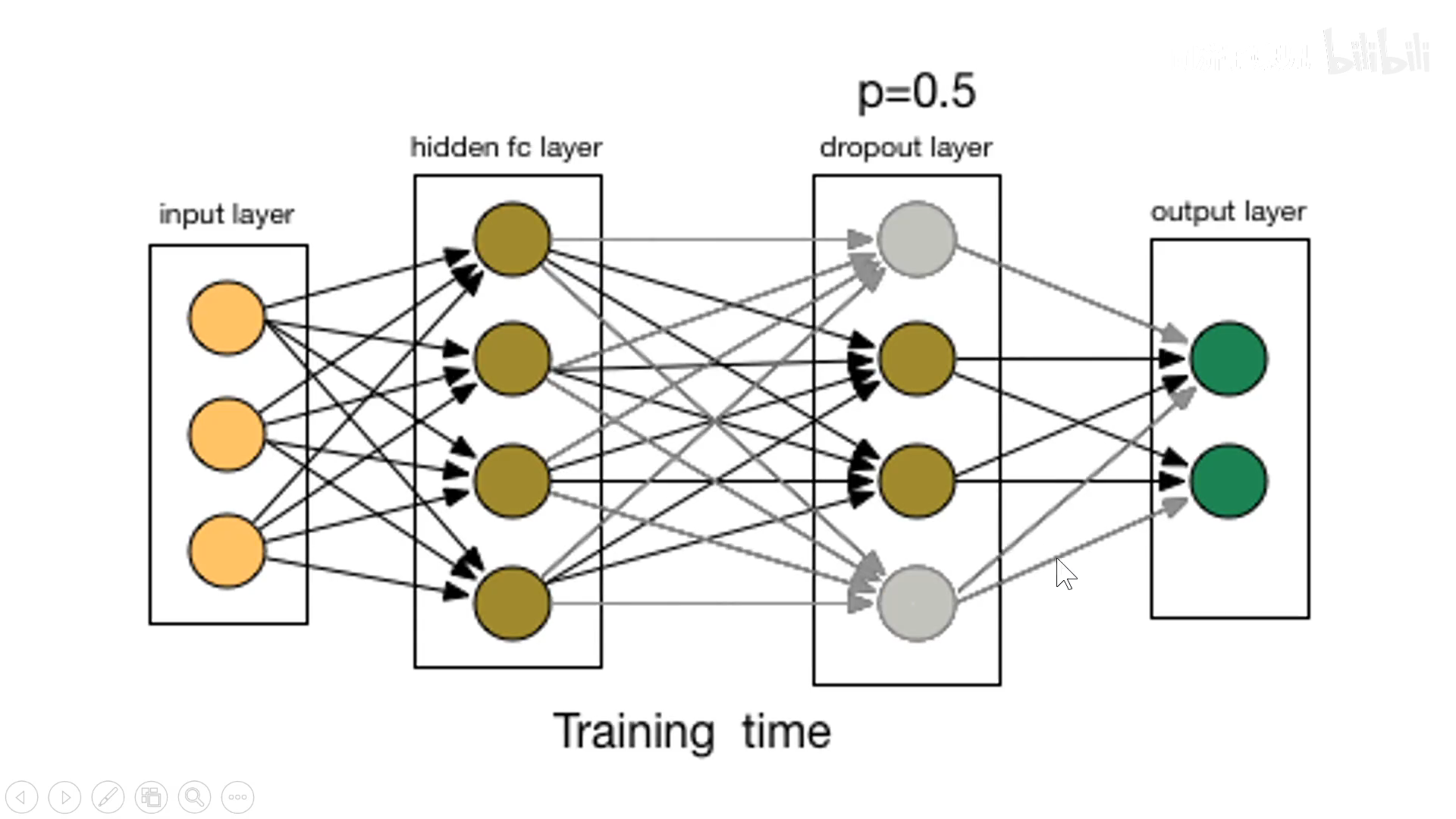
所谓dropout,就是在训练阶段,在全连接层上,随机杀死一部分的神经元,也就是将激活值设置为0,目的是为了让神经元在训练的时候减少路径依赖,与所有与其连接的神经元进行合作,避免过拟合。
8. 模型训练
模型的训练阶段,使用了SGD训练策略,优化算法是momentum,其中momentum是0.9,weight decay是0.0005,后面这个weight decay值也是pytorch中默认的权重。
9. 总结
其实这篇论文更像是一篇技术报告,大部分只是说,用了什么trick,这些trick如何有效,也没有去解释说为什么有效,这也是深度学习被诟病的地方,里面都是黑盒,缺乏可解释性。
另外一方面,这篇论文尝试了很多trick,虽然在后面被证明为无效,但是也相当于为后面的人避坑,而且本文中端到端训练,relu的使用,采用更深的网络,都为后面的深度学习指明了方向,因此从今天看,这篇论文的确是开创性的。
10. 参考
(完)