libfacedetection是基于SSD进行魔改,而DBFace是基于MobileNetV3进行改进。
- 一、libfacedetection
- 二、DBFace
- 三、libfacedetection网络结构图
一、libfacedetection
链接:https://github.com/ShiqiYu/libfacedetection
训练代码:https://github.com/ShiqiYu/libfacedetection.train (用到nvidia-dali,不能在win下使用)
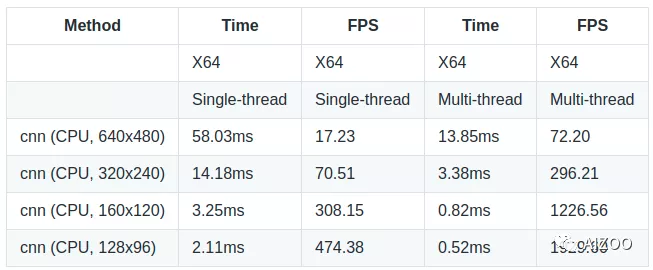
于老师这个项目,牛就牛在,他可以转为纯C++代码,不依赖任何第三方库,检测速度在128x96的输入上,在i7的CPU上可以达到1929帧/秒,在树莓派这种嵌入式设备上,也可以达到116帧/秒;而在常规的VGA分辨率(640x480)输入下,在CPU上也可以达到72帧/秒,可以说是非常优秀了。下表是该项目的评测指标,分别有单线程和多线程的耗时和速度。
模型结构也比较简单,就是一个轻量级的 SSD 架构,共四个定位层,而且借鉴了RetinFace的关键点方法,可以同时回归5个关键点。模型体积只有232万,体积仅有3.34M
面是于老师的文章中叙述的libfacedetection的特点:
-
卷积操作无浮点计算,算法基本全是8位整数操作。
-
采用AVX512/AVX2/NEON指令提速。
-
代码更加简短和简洁,只有一千多行代码。
-
代码不依赖任何其他第三方库,只要平台能编译C++则可使用。
-
项目License采用3-Clause BSD License,可以商业应用!
今晚,于老师开源的是该模型的训练代码,下面我们一起分析一下该训练框架。这个人脸检测模型,于老师一共更新了三版,再加上今天开源的训练代码,一共四篇文章,我们先把这四篇官方微信文章列一下:
通过查看于老师开源的训练代码,我们可以看到该模型是一个SSD类型的目标检测模型,一共有四个检测分之,Backbone网络共16层,模型非常轻量级,
不过该模型使用一个PriorBox层生成anchor,可以做到任意大小的输入。这点我们在后面也会借鉴过去。
网络结构如下图所示,该模型是在下降8、16、32、64倍后的四个尺度的特征图上接入分类定位层,四个层每个点的anchor数目分别为3、2、2、3,所有anchor的长宽比分别为1:1。
| 定位层 | 下降倍数 | anchor大小 |
| 一 | 8 | 10, 16, 24 |
| 二 | 16 | 32, 48 |
| 三 | 32 | 64, 96 |
| 四 | 64 | 128, 192, 256 |
该网络共有参数232万,可以说比较轻量级了。在RetinaFace中,作者也同样对每个人脸同时回归了五个关键点。于老师这里的做法与RetinaNet一样,也是对每个anchor在回归cx、cy、dw、dh四个bounding box偏移量时,额外再增加10个节点的输出,分别对应五个关键点的cx、cy偏移量。
另外,模型在推理的时候,也将Batch Norm层的参数融合进了卷积层,从而实现一定量的网络加速。关于BN层融合,笔者后面会写一篇文章简单介绍一下。
二、DBFace
1.3M 的轻量级高精度的关键点人脸检测模型 DBFace,并手把手教你如何在自己的电脑端进行部署和测试运行,运行时bug解决。前段时间DBFace人脸检测库横空出世,但是当时这个人脸识别模型是7M大小,几乎可以识别出世界最大自拍中的所有人像。DBFace出自国内人工智能公司深兰科技(DeepBlue),这个模型的创建者正是这个公司的两位“高手”-Libia和Wish,而最近,高手就是高手,两位大佬对模型进行了再升级,现在这个模型的大小仅仅只有1.3M。
DBFace的网络结构
DBFace的初衷设计就是为了设计成一款轻量级的人脸检测器,能够在边缘计算上有效的使用,为了让处理更加简洁、高效、对小目标的检测效果也好,选择 CenterNet(基于中心点的方法预测目标,称为:CenterNet,)结构做检测任务,采用MoblienetV3做Backbone。我相信大家在这里已经晕了吧,不知道什么是CenterNet和MoblienetV3,因为这不是几句话能说清楚的,需要大家明白卷积的知识,在知道这之后,还需要去读这个论文,啃代码,可能才能理解个七八分吧。
相对于MoblienetV2,MoblienetV3在其基础上新增了SE、Hard-Swish Activation等模块,在兼顾infence速度的同事提升网络性能。
对于任务头的设计,大佬引入了SSH的DetectModule和ContextMoudle,经试验验证该模块能有效的提升DBFace算法的检出性能,这里涉及到卷积、池化中的最大值池,对模型进行的整合。
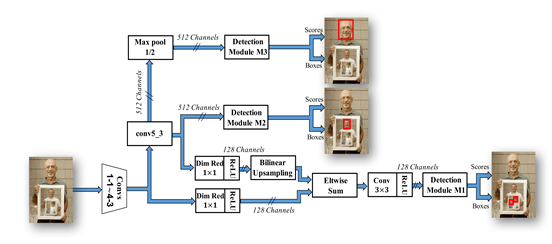
对于上采样设计,作者采用Upsample + Conv + Act的方式,即上采样 + 卷积 + 激活函数Activation,从图中可以看到有激活函数Relu。
损失函数Loss的定义
整个网络由三个部分的Loss组成:
- 热力图HeatMap损失 - (CenterNet网络中热力图误差损失)
- 位置坐标偏移量(Bounding Box)损失 - (检测边界框误差损失)
- 关键点(Landmark)损失 - (人脸关键点误差损失)
对于一个模型来说,网络结构和损失函数、以及数据集是最重要的,这里作者并没有开源自己的数据集,我们可以利用工具来标记属于自己的数据集,这里给大家介绍一个关键点标记的软件CasiaLabeler
三、libfacedetection网络结构图

参考:https://mp.weixin.qq.com/s?__biz=MzIyMDY2MTUyNg==&mid=2247483818&idx=1&sn=12e14dfd5154b35f14575d876785da76&chksm=97c9d3d3a0be5ac5a4e5cb05b23dd90bb73d57c2b3be6a70a139d8c28391a6185ec6297b6da0&scene=21#wechat_redirect
https://zhuanlan.zhihu.com/p/183203043
https://blog.csdn.net/weixin_45192980/article/details/106485602