?前言
- ?博客主页:?睡晚不猿序程?
- ⌚首发时间:2023.6.11
- ⏰最近更新时间:2023.6.11
- ?本文由 睡晚不猿序程 原创
- ?作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
1. 内容简介
论文标题:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
发布于:ICCV 2021
自己认为的关键词:ViT、Pyramid structure
是否开源?:https://github.com/whai362/PVT
2. 论文速览
论文动机:
- 现在的 ViT 主要用于图像分类任务,没有做密集预测任务的纯 ViT 模型
- ViT 的柱状结构(分辨率不变)以及粗糙的 patch 划分天生不适合密集预测任务
本文工作:
- PVT(Pyramid Vision Transformer),金字塔结构的 ViT,更适合于密集预测任务
- 使用更细粒度的 patch 划分以及下采样操作,使得 PVT 可以利用多尺度信息
完成效果:
COCO:
- PVT-S:40.4 AP
- PVT-L:42.6 AP
3. 图片、表格浏览
图一
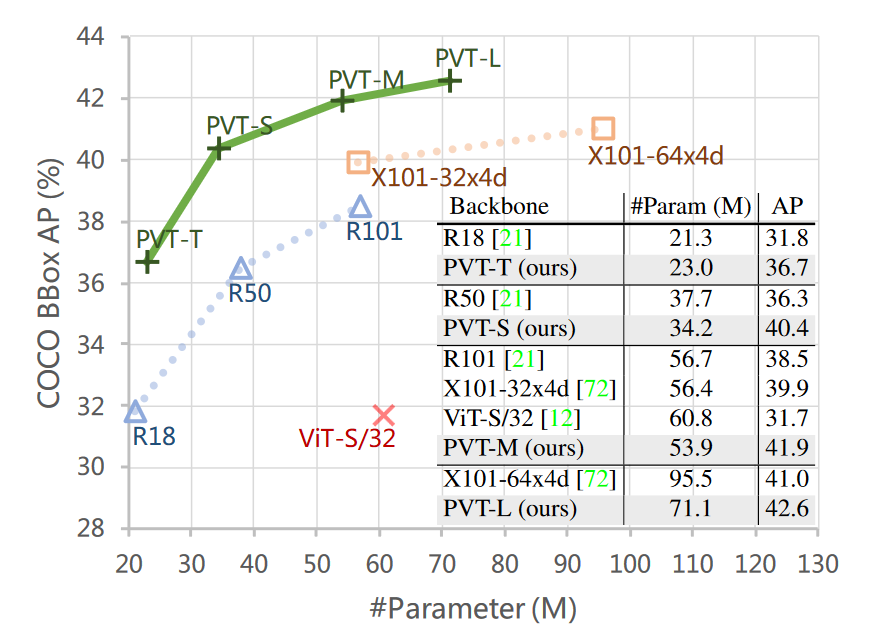
在 COCO 数据集上的性能对比,但是咋不和 Swin Transformer 碰碰?
图三
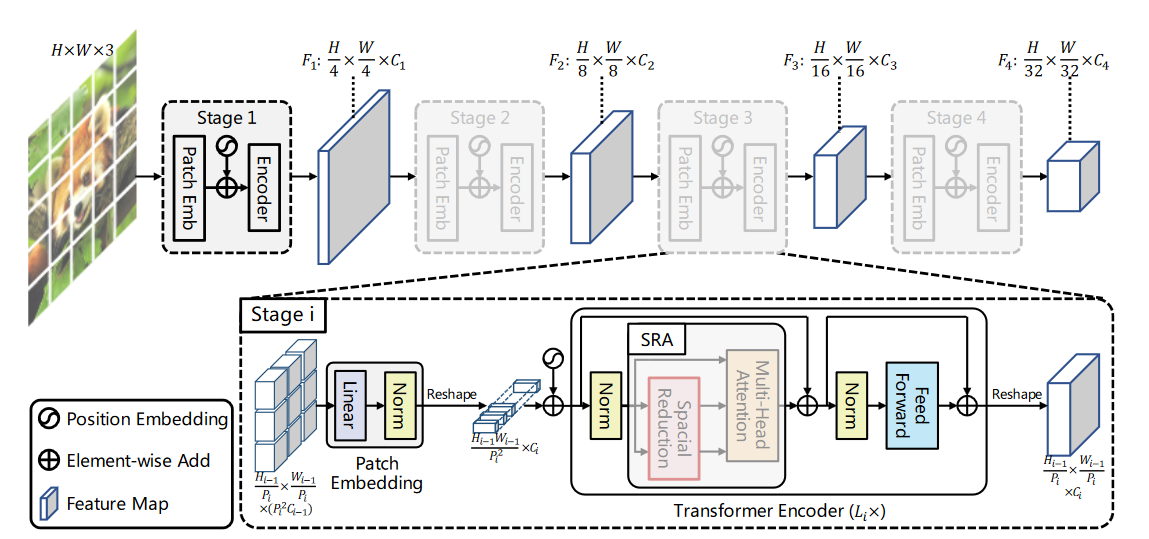
模型架构图,通过 patch embedding 来进行下采样,并且看起来也通过减少 KV 的数量来降低计算量
图四
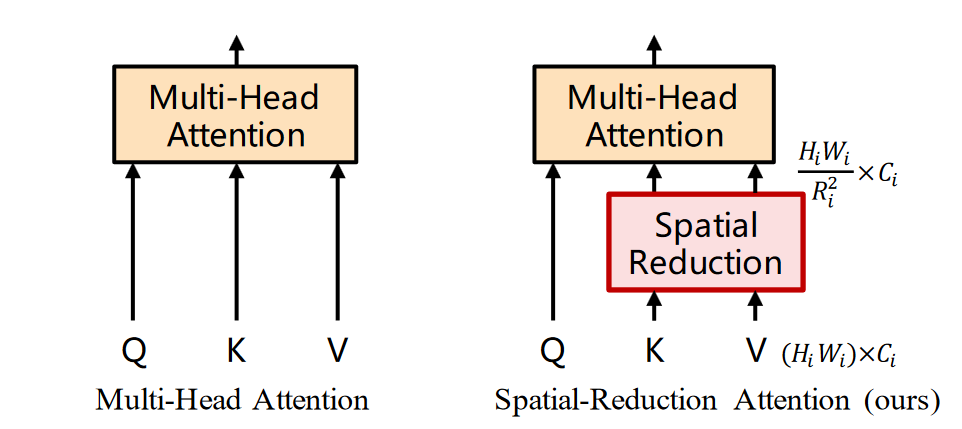
看样子是一个缩放的操作,减少了 KV 的个数来减少自注意力的计算开销
4. 引言浏览
本文目标:探索一种可以替代 CNN,并且用于密集预测以及实例分任务,而不仅是用于图像分类
但是一般的话,应该分类检测分割都做一遍
动机:
- 完全使用 Transformer backbone 作密集预测任务的研究工作较少
- ViT 结构不适合密集预测
- patch 大小 16x16,过于粗糙,并且是单一分辨率
- 计算开销大:全局自注意力计算消耗大量算力以及显存
- 对于像素级别的预测不适用
PVT 克服了原先模型的缺陷:
- patch 大小 4x4,可以获得高分辨率的表征
- 引入了逐级缩减的金字塔结构,减少 Token 的长度以减少 Transformer 的计算开销
- 修改自注意力,减少其开销
PVT 相比 CNN 以及 ViT 的优势:
- 全局感受野
- 金字塔结构,能够更容易的嵌入到密集预测 pipline 中
个人觉得,因为小的 patch 划分导致计算开销疯狂增大,还是引入窗口把,不然就算是减少了 KV 数量计算量的降低也有限
自由阅读
5. 方法
目标:构建金字塔形状的 Transformer 架构,让其拥有多尺度特性以适用于密集预测任务、
整个模型包含四个 stage,每一个 stage 都先进行 patch embedding(线性)然后再经过多个 Transformer block 进行处理,但是似乎没有看到下采样的方式,唯一的些许不同在于自注意力的计算引入了不同的东西
Transformer encoder
因为在较高分辨率下进行自注意力运算,需要的计算时间较大,选择了改进的自注意力
输入的时候 QKV 本应该是相同的,但是他这里对 KV 做了一点小操作:
- 进行 merge,分辨率降低,特征维度增加
- 将特征维度映射到原先的特征维度
- 进行自注意力运算
因为减少了 KV 的数量,所以计算复杂度至少减少了 \(R^2\) 倍,但是输出的大小是和 Q 有关的,所以最后的自注意力输出的 Token 长度不变,只不过是 Q 所查询的 K 变少了,以此来降低自注意力的运算量
6. 实验
6.1 实验结果
ImageNet 分类
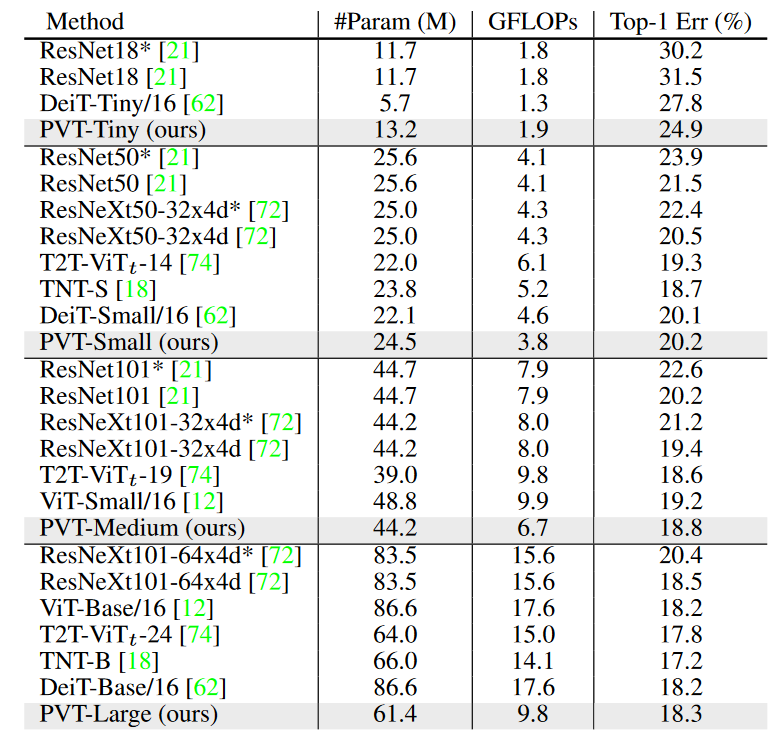
这不和 Swin Transformer 碰碰?
感觉又是在于参数量小(也不小了把)感觉应该是主要用于分割检测什么的,分类倒是次要
检测
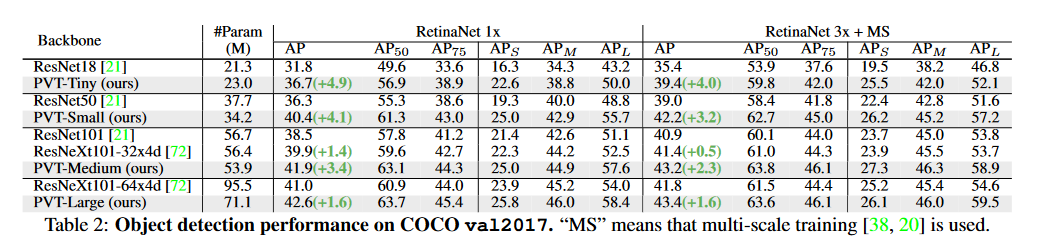
看起来效果就好了,但是怎么对比的是 ResNet?
分割
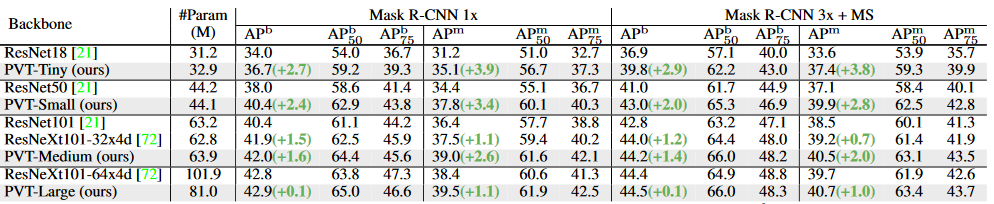
6.2 消融实验
金字塔结构

ViT 没有使用金字塔结构,单一尺度条件下性能看起来是非常的差的
计算开销
PVT 的计算开销介于 ViT 和 ResNet 之间,由于输入分辨率决定了计算量,作者提出了两种方式:
- 缩小输入大小
- 计算量更小的注意力机制
这里作者说会提出 PVT v2 版本,后来我去看了一下 V2 版本,感觉有点水
7. 总结、预告
7.1 总结
提出了较为简单的多尺度 Transformer,保持了 Transformer 的输入输出维度不变,每一个 stage 的 patch 大小不同——刚开始 为 4x4,之后变为 8,16,32,以此让模型可以把握多尺度的信息
感觉应该算是一个比较初级的多尺度,为了保证计算效率也舍弃了一些其他东西,比如提出了 SHA
这个自注意力计算方式会保持 Q 不变,降低 KV 的分辨率,并映射到同样的大小,我认为虽然这样可以保证输出维度不变,但是其参考的 KV 变少了,可能在检测分割这些比较简单的任务上有作用,在超分辨率这种全局性越多越好的任务上效果可能不会很好
- Convolutions Transformer Prediction Versatile Backboneconvolutions transformer prediction versatile versatile versatile格式 简介binary convolutions convolutions-googlenet backbone convolutions improving computer accuracy convolutions exercise convolutions-googlenet convolutions googlenet convolutions transformers introducing vision