强化学习Chapter1——基本认识
一句话概括强化学习(RL,reinforce learning):强化学习实际上是通过对某个主体的行为来进行奖励或者惩罚,从而使其在未来更可能重复或者放弃某个行为。(倒有点“培养小学生养成良好的学习习惯”那味了......)
从基本概念谈起
1、框架表征:State,Reward,Action
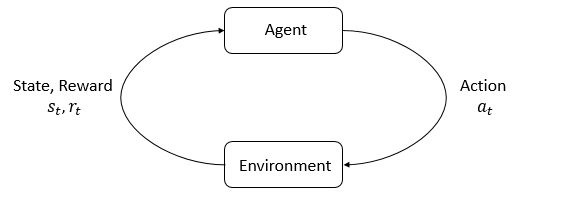
如果对文首所言进行 formalization,就需要提出 agent 和 environment 的概念了。行为主体称之为 agent,而给予奖惩反馈的主体统称为 environment。定义了两大主体,就需要进一步定义二者交互的元素:
- State:environment 的状态,这是一个较为完备的概念,实际中常常以 Observation 代替,譬如训练电脑(agent)控制机器人(environment)的项目中,机器人运动过程中的诸多观测值可以用来表征其所处状态。
- Reward:奖惩可以看作 reward 的正负,是 enviroment 对 agent 行为的反馈。
- Action:agent 的行为,可能会影响 environment 的走向。事实上 Action 是指环境所允许的行为,譬如象棋所规定每个子的走向,所有 action 构成 action space。
在上图中,这三个概念分别用 \(s_t, r_t, a_t\) 表征,因为 agent 和 environment 往往是规律性进行周期交互的,所以可以加一个下标 \(t\) 表示交互的周期或者轮次。如果你了解状态机的话,会发现强化学习的框架与状态机十分相似,即 environment 的状态随着 agent 的 action 不断迁移变化。
强化学习的优化目标与优化的参数对象是多样性的,在后文中会逐步引出,目前只需要知道 Reward 是强化学习更新的一个指标即可。
2、策略 Policy
Policy is the brain of agent
所谓策略,是决定 action 的方法。根据环境所处 State 及上次所得的 Reward,agent 需要做出下一个 action,而 Policy 就是在讲如何做出下一个 action。
更具体来讲,策略大致上可分为两种:确定性策略(deterministic)和随机性策略(stochastic),而这两种策略的表征如下:
| 策略 | 公式 | 说明 |
|---|---|---|
| Deterministic Policy | \(a_t=\mu(s_t)\) | 无 |
| Stochastic Policy | \(a_t\sim \pi(·|s_t)\) | \(a_t\) 是服从这样一个分布的,其中 \(\cdot\) 是涉及的一些随机变量的概括,最终 \(a_t\) 的获取,是通过在 \(\pi\) 分布(一个概率向量logits)中采样得到的 |
需要解释的是,这里的策略都是依据给定参数 \(s_t\) 即当前环境的状态所决定的,但是根据上图其实可以看出,Action 还与 Reward 有关。事实上,Reward 在做出决策前就已经使用了——在做出上一个 Action 后,所得 Reward 会参与调整策略。所谓策略,参数化后不过是一个函数,不管是 \(\mu\) 还是 \(\pi\) 都是系列参数表征的函数而已,Reward 会参与这些参数的调整,从而调整策略。因此,上述的两种策略常常被写作:\(\mu_{\theta}(s_t)\),\(\pi_\theta(\cdot|s_t)\).
3、轨迹Trajectories
轨迹的概念根据其形式很容易理解:
即轨迹为一系列状态和动作的序列,在有一个明确策略的前提下,从一个初始状态(一般是从状态集中随机采样)可以导出系列后续的动作和下一状态。状态转移可以简单表示为:
当然环境状态的迁移,也不一定是确定的,因此在某些情形下也可以写成
Trajectories are also frequently called episodes or rollouts.
可以看出,这里的下一状态仅从当前状态出发,即状态的变化没有显式的记忆,不会受到当前状态之前的状态影响。这一性质也被称为马尔可夫性质,在后面的文章中会提到。
4、奖励和回报 Reward and Return
在前面提到过 Reward 但没有给出详细的数学表征,不过从上图也可以大致看出,Reward 实际上是一个 \(a_t\) 和 \(s_t\) 的函数,即与当前状态以及当前做出的动作有关:
但根据策略的公式可以看出,当前动作 \(a_t\) 实际上是在 Policy 下的 \(s_t\) 的函数,因此这个式子也可以简化为:
PS:实际上,\(r_t\) 还应当与下一状态 \(s_{t+1}\) 有关,因为迁移到不同的状态,显然 Reward 应当不同,但由于 \(s_{t+1}\) 其实是由当前状态和当前动作决定的,因此该变量也可以略去。
如上所述,Reward 只是单步交互所得的奖惩,但强化学习的初衷是长期的,可以解释为:强化学习期望积累的 Reward 尽可能高。这就引出了回报(Return),来表征奖励的积累。顾名思义,奖励的积累可以简单的写成
即有限步内的期望累计值。这里只能是有限步,因为这个级数的收敛性未知,如果 \(T = \infin\) 那么回报就很难作为模型更新的指标了。另一种更为先进的表征方法,是带遗忘因子的回报:
其中,\(\gamma\) (discount factor) 使得该级数具有一定的收敛性(可通过压缩映射理论进行证明),表观上为回报赋予“遗忘”的特性——回报更多关注于当下的 Reward。
While the line between these two formulations of return are quite stark in RL formalism, deep RL practice tends to blur the line a fair bit—for instance, we frequently set up algorithms to optimize the undiscounted return, but use discount factors in estimating value functions.