本文参考《Reinforcement Learning:An Introduction(2nd Edition)》Sutton.
强化学习是什么
传统机器学习方法可分为有监督与无监督两类;
有监督学习 -----> 任务驱动
无监督学习 -----> 数据驱动
强化学习则可看作机器学习的“第三范式” -----> 模拟驱动,具体而言:通过agent与environment之间的交互进行学习。
为了更好利用交互所得信息来完成学习任务,我们通过一些计算性的方法(数值化)来实现强化学习。
强化学习的特征
总体而言我们希望通过强化学习得到一个映射:由情况空间(state)-----> 动作空间(action)的映射(或者更通俗点,当我面对情况A的时候,我选择动作B来达成我的目标)。
不妨联想一下人是如何学习的:我们在最开始的时候总是会去尝试一些动作,这些动作可能正确可能错误,但当时我们并不知道其正确与否,我们一般通过一段时间后事情发展的结果来对当时的动作好坏进行判断:比如小时候我们可能试过在期末考试前玩电脑,也试过在期末考试前认真复习(假设你没有考试前应该复习一下的概念: )),那在期末考试之前你应该不知道这两种行为会对你的考试结果有什么样的影响,但是当你考试结果出来之后,你可能会按着你的考试成绩推测一下:你的考前动作对你的考试结果有啥影响;之后你反复进行这个过程多次(考前选择玩or复习--->考试拿高分or低分),你逐渐形成一个判断:复习通常能带来高分,玩通常带来低分;那么根据这个判断你就可以为你的目标选择一种策略来完成目标:比如你想要拿今年的三好学生,要考试分数高一点,那你就会倾向于在考试前复习一下。
同样的我们在强化学习中也遵循着类似的流程,我们总会先试错,试错后根据总体收益(reward)(可以分为即时收益与延迟收益两部分),形成价值(value function)判断,根据价值判断与目标形成策略(policy)。
那么应当注意的一点是,我们的目标一般是抽象的,间接的,比如我要赢下一盘象棋,我要学会走路……这些目标很难得到显式的收益表达(你很难说明开局帅五进一是让你的获胜概率从50%变成了1%)所以在强化学习中收益函数(reward)的设置是相当关键的;
通过上述描述或许读者已经对RL有了初步了解(当然这种了解是基于作者的认知:)),下面作者将尝试更严谨的为强化学习中的要素下定义:
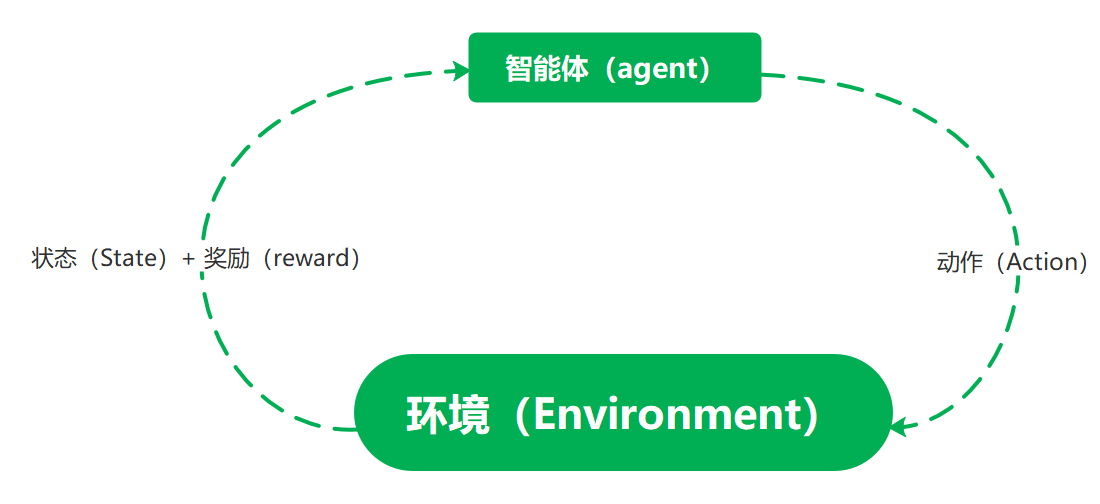
智能体:具备学习能力;在某种程度上感知环境状态(全体/局部);可采取动作影响环境状态;有学习目标(与环境状态相关);
环境:对智能体的动作产生反馈,一般而言环境不确定(不可以根据当前状态预测最终结果(ground-truth),但可以根据动作更新状态并反馈即时奖励)
状态:环境当前状态的抽象表示,简记为 s
动作:智能体对环境施加影响的抽象表示,简记为 a
奖励:强化学习问题的目标,是环境向智能体反馈的一个标量数值,智能体的唯一目标是最大化长期总收益,一般而言奖励依赖于人工设计,与任务目标强相关。可被看作以二元组(state,action)为变量的函数 R(s,a)
价值:以state为变量的函数 V(s),表达对当前状态s未来累积总收益的期望,一般而言未知,但在学习过程中通过智能体与环境的不断交互而逐渐得到V(s),即所谓的价值估计方法;应当注意的是价值是来源于奖励的,但在生成策略时我们更重视价值(不难想到如果我们在交互过程中每次都选择转移到价值更优的状态(如果确实可以转移到新状态的话),那么我们的末状态一定累积了最多的奖励???或许这需要更严谨的证明)
策略:智能体在特定时间(状态)的行为方式,是state到action的映射,具体来说就是在状态s下采取动作a的概率分布(与价值相似,policy是可学习的),一般而言初始策略是随机策略(严格来说作者也不是很明白策略是什么,但可以确定的一点是我们希望通过RL给我们提供一个最优策略,是我们的长期总收益最大,那么据此倒推的话policy应当是state到state的映射,但是有价值、动作等约束条件,并且满足性质:尽可能保证长期总收益最大。这个部分欢迎纠正,作者也上网找了些资料但真没太看明白:( )
如果读者已经读过sutton的书的话,应该已经看到了书上井字棋的例子,里面提及了差分更新、有/无模型学习等概念,这里作者就不再抄书给大家炒冷饭了,这些概念留着到对应章节再给大家分享作者的理解。
另:第一次写blog,加上自身也刚开始学习,难免有误,欢迎大佬指正,也欢迎大家讨论交流。
2023/11/13 刘国林
- Reinforcement Learning Chapterreinforcement learning chapter reinforcement learning noise reinforcement exploration learning reinforcement distillation teachable learning reinforcement transformer decision learning reinforcement transformer learning trainer reinforcement exploration off-policy learning reinforcement modelling learning feedback learning reinforcement q-learning python reinforcement introduction learning deep