写在前面
《Hive性能优化实战》是比较不错的一本hive技术书籍,介绍了hive相关的一些技术,一些基本的理论,看完能对hive优化方面略有了解; 但有俩地方每种不足,一是没有那么多的实际的综合情况分析优化案例,这个有点可惜,要是多几个案例就很不错了;而是执行计划部分大多数
整本书最吸引人的地方在第一章和第二章,实际测了下不同场景下的优化性能,并以新人和老人的角度分析了优化,刚读的时候很震撼。后续则是开始介绍hive相关组件、存储格式,计算引擎,yarn等等。
各章节总结回顾
第一章
各种因素对于sql性能的影响,直观展示了 MultiInsert语法改写,orc/parquet格式,源表文件大小,分区分桶这个方面对性能的影响
MultiInsert
-- union类型sql,改写为 MultiInsert
insert into table student_stat partition(tp)
select s_age,max(s_birth) stat,'max' tp
from student_tb_txt
group by s_age
union all
select s_age,min(s_birth) stat, 'min' tp
from student_tb_txt
group by s_age;
-- 改写后,这种写法只会读一次 student_tb_txt表,节省一个map阶段
from student_tb_txt
INSERT into table student_stat partition(tp)
select s_age,min(s_birth) stat,'min' tp
group by s_age
insert into table student_stat partition(tp)
select s_age,max(s_birth) stat,'max’ tp
group by s_age;
源表文件大小
源表的数据文件大小会显著影响性能,比如相同数据内容(行数字段存储文件类型都一样)的两个表 T-BIG 和 T-SMALL,T-BIG的数据分布在3个文件中每个文件7G,T-SMALL分布在500个文件每个40M
那么运行时最终的 Mapper 任务数量由于 HiveCombineInputFormat 的存在差异不大,但是 T-SMALL表每个服务器的 Mapper 任务大概率可以在本机节点读取文件,而 T-BIG表的不同服务器的 Mapper只能去那3个文件及副本所在的服务器读取文件,中间多了很多网络IO消耗,因此性能较差
需要注意的是,如果源表文件太小,也可能产生 Mapper从不同服务器获取文件进行合并的场景,也会产生网络IO,因此建议源表文件控制在和 HDFS一个BLOCK的大小,通常是128M。
数据格式
纯HIVE场景无脑选ORC就完事了,有大数据场景可以考虑Parquet。都是行列式的存储格式,即把10000行数据分一个组,这个组内按列来存储数据,并且 header和footer存了schema以及统计信息,还会压缩,性能和存储比 text不知道高到哪里去了
分区分桶
分区用的多一些,相当于把数据存到不同的目录,查询时指定分区键就会去指定目录查数,提升性能,通常不会用业务键来做分区,一般都是日分区、月分区、年分区等。
分桶是在单个分区目录下(也可不分区)将数据按照某个字段hash取模然后存入不同的文件内,及把数据按照某个键分组存到不同文件,这样查数时,过滤分桶键的时候就可以立马确定要查哪几个文件,又是一个性能提升。 不过生产上用的比较少,某些地方就不让用,因为分桶数量在建表时确定且后续不能更改,所以业务发生变化后,原先的设计反而可能影响性能。
第二章
第二章主要是介绍了下调优的思路,以及一些开发规范。 很有意思的是从小白的视角和老兵的视角来看待调优。感觉自己还是个小白视角hah
老兵视角的过度优化的案例很有意思,看的时候把我给震惊住了。如下sql是经典的优化count(distinct )数据倾斜的案例。
-
小白认为当数据量特别大的时候,通过group by可以将数据分布到多个reducer处理,避免倾斜; 这确实没错,大部分情况都是OK的
-
老兵认为, 需要计算的字段是 age年龄,这个字段的特殊性决定了最多就 120个枚举值,通过 map端聚合,就算有1000个map,每个map100个年龄,int类型字段4个字节最终也就是400KB的大小,最终输出的数据量汇总到单个reducer的时候也是可以吃的消的; 并且就算真的数据量大还可以开 hive3.0提供的 hive.optimize.countdistinct 参数,将hashtable改成 bitmap来提速; 且count(distinct age) 可读性好
-- 小白sql
select count(1) from(
select s_age
from student_tb_orc
group by s_age
) b
-- 老兵sql
select count(distinct s_age)
from student_tb_orc
总结下调优的过程:
- 确定好性能目标,评估整个链路耗时,有性能瓶颈时才做优化,否则是浪费时间。
- 分析性能瓶颈,通常是出现在IO较多的地方
- 进行性能监控和告警
第三章
hive的安装相关
第四章
介绍了hive的基本组件和架构, 对执行原理有个概览

Hive自身组件
- Hive Client: bin/目录下的 hive客户端,以及jdbc/thrift/beeline等
- HiveServer2: 提供Web服务,接受各种类型客户端的访问,并处理sql解析,mr任务编译的工作
- Metastore: 这位更是重量级,hive的灵魂,将 HDFS 文件系统转化为一个数据库的核心部分
Hive相关组件
- hdfs: hive本身不存数据,数据都存在hdfs上面
- mr: hive本身也没有计算框架,是将sql改写为mr任务,使用hadoop提供的mr计算框架来算数
- yarn: 资源管理框架
- tez: 计算框架
- spark: 计算框架
第五章
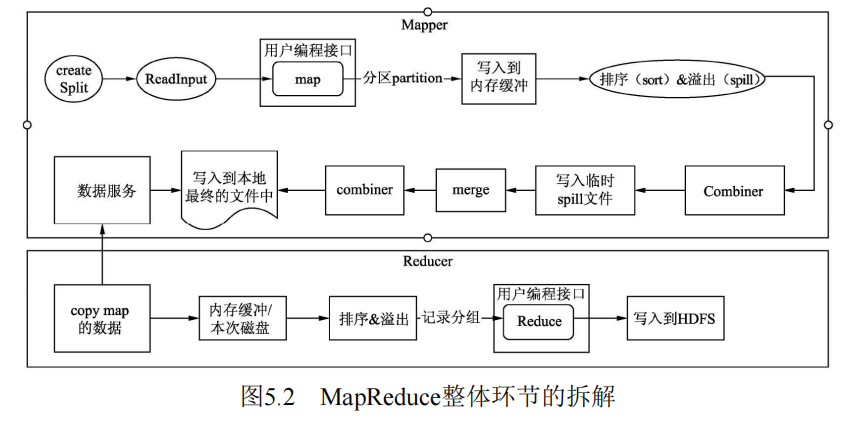
介绍 mr以及mr过程中,hive可以控制的一些参数,参数最后面一起总结吧。下面这个基础的 wordcount 任务有个印象就行,主要的核心在shuffle上面,其实 shuffle的具体内容,知道个大概就行了,卷到啥 环形缓冲区,内存里的kv存的是啥就没意思了
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
public class WordCount {
public static class MyMap extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// System.out.println(key);
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
while (values.iterator().hasNext()) {
sum += values.iterator().next().get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.input.fileinputformat.split.minsize", "4194304");
conf.set("mapreduce.input.fileinputformat.split.maxsize", "4194304");
conf.set("mapreduce.input.fileinputformat.split.minsize.per.node", "4194304");
conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack", "4194304");
Job job = Job.getInstance(conf, "wordcount");
job.setMapperClass(MyMap.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(CombineTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
CombineTextInputFormat.addInputPath(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
第六章
执行计划解读,mr的执行计划,没有tez的可惜,不过差不多
第七章
一些基本的sql处理模式,如where的过滤,group by的聚合,join的关联
第八、九、十、十一章
介绍了下 yarn怎么看, orc的结构特点,metastore的监控脚本,hive体系总结