内存映射模块
了解计算机内存
内存映射是一种使用较低级别的操作系统API将文件直接加载到计算机内存中的技术。
它可以显著提高程序中的文件I/O性能。
术语内存是指随机存取内存或RAM.
计算机内存类型:
- 物理的
- 虚拟的
- 共享的
使用内存映射时每种类型的内存都会发挥作用,因此让我们从高层次回顾每种内存。
物理内存
物理内存时最不容易理解的内存类型。
物理内存通常位于连接到计算机主板的卡上。
物理内存是程序运行时可以使用的易失性内存量。物理内存不应与存储(如硬盘驱动器或固态磁盘)混淆。
[易失性内存:](Volatile memory - Wikipedia)是需要电源来维护存储信息的计算机存储器;它在通电时保留其内容,但是当电源中断时,内存的数据很快就会丢失。
虚拟内存
虚拟内存是一种处理内存管理的方法。操作系统使用虚拟内存来是您看起来拥有比实际更多的内存,从而减少您担心在任何给定时间有多少内存可供程序使用,从而减少您担心在任何给定时间有多少内存可供程序使用。在后台,您的操作系统使用部分非易失性存储(如固态磁盘)来模拟额外的RAM.
为此,您的操作系统必须维护物理内存和虚拟内存之间的映射,每个操作系统都使用自己的复杂算法,使用称为页表的数据结构将虚拟内存地址映射到物理内存地址。
[页表](页表 - 维基百科 (wikipedia.org))
页表是计算机操作系统中虚拟内存系统用于存储虚拟地址和物理地址之间的映射的数据结构。
虚拟地址由访问进程执行的程序使用;
而物理地址由硬件使用,或者更具体地说,由随机存取存储器(RAM)子系统使用。
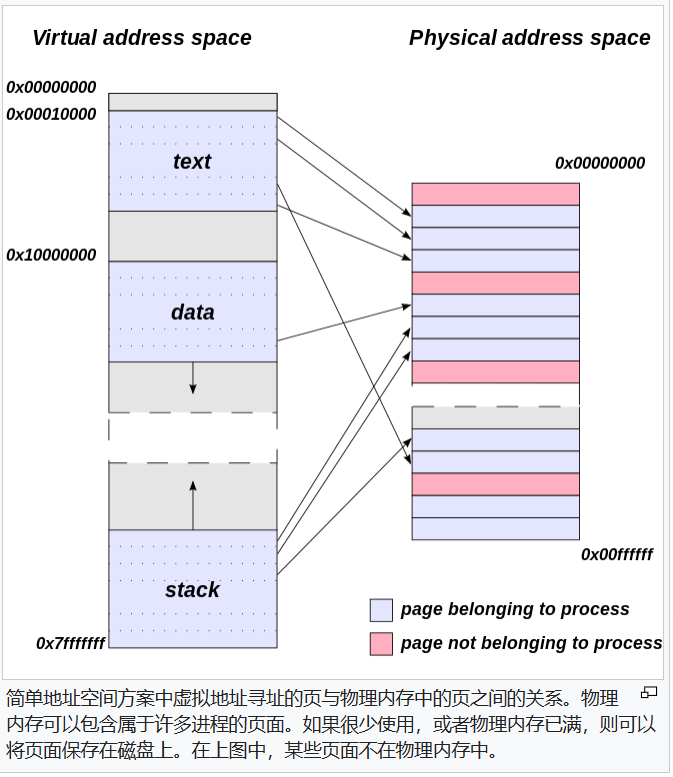
幸运的是,大多数这种复杂性都隐藏在您的程序中。您无需了解页表或逻辑映射即在Python中编写高性能的I/O代码。mmap使用虚拟内存来时您看起来已将非常大的文件加载到内存中,即使文件的内容太大而无法放入物理内存。
共享内存
共享内存是操作系统提供的另一种技术,它允许多个程序同时访问相同的数据。共享内存是在使用并发的程序中处理数据非常有效的方法。
Python使用共享内存在并发发生的多个Python进程,线程和任务之间有效地共享大量数据。
文件I/O
为了充分理解内存映射的作用,从较低级别的角度考虑常规文件 I/O 很有用。读取文件时,幕后会发生很多事情:
- 通过系统调用将控制权转移到内存或核心操作系统代码;
- 与文件所在的物理磁盘交互
- 将数据复制到用户空间和内核空间之间的不同缓存区
示例:
def regular_io(filename):
with open(filename, mode="r", encoding="utf8") as file_obj:
text = file_obj.read()
print(text)
此代码将整个文件读入物理内存(如果运行有足够的可用文件)并将其打印到屏幕上。
这种类型的文件I/O不是很密集或复杂。
但是在函数调用的掩护下发生的事情非常复杂。
系统调用
实际上,对 read() 的调用向操作系统发出信号,要求它们执行大量复杂的工作。幸运的是,操作系统提供了一种通过系统调用将每个硬件设备的特定细节从程序中抽象出来的方法。每个操作系统将以不同的方式实现此功能,但至少 read() 必须执行多次系统调用才能从文件中检索数据。
使用物理硬件进行的所有访问都必须在称为内核空间的受保护环境中进行。系统调用是操作系统提供的 API,用于允许程序从用户空间转到内核空间,其中管理物理硬件的低级详细信息。
在 read() 的情况下,操作系统需要多次系统调用才能与物理存储设备交互并返回数据。
同样,您不需要牢牢掌握系统调用和计算机体系结构的细节来理解内存映射。要记住的最重要的事情是,从计算角度讲,系统调用相对昂贵,因此执行的系统调用越少,代码的执行速度就越快。
除了系统调用之外,read() 的调用还涉及在数据完全返回到程序之前在多个数据缓冲区之间复制大量可能不必要的数据。
通常,这一切都发生得如此之快,以至于不明显。但是所有这些层都会增加延迟,并会减慢程序的速度。这就是内存映射发挥作用的地方。
内存映射优化
避免此开销的一种方法是使用内存映射文件;
可以将内存映射描绘成一个过程,在此过程中,读取和写入操作跳过了上述许多层并将请求的数据直接映射到物理内存中。
内存映射文件I/O方法为了速度而牺牲了内存使用量,这通常称为时空权衡。但是,内存映射不必使用比传统方法更多的内存。操作系统非常聪明,它将在请求时延迟加载数据,类似于生成器的工作方式。
此外,借助虚拟内存,您可以加载大于物理内存的文件。但是,当没有足够的物理内存用于文件时,您不会看到内存映射带来的巨大性能改进,因为操作系统将使用较慢的物理存储介质(如固态硬盘)来模拟它缺少的物理内存。
使用Python读取内存映射文件mmap
示例:
import mmap
def mmap_io(filename):
with open(filename, mode="r", encoding="utf8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
text = mmap_obj.read()
print(text)
此代码将整个文件作为字符串读入内存并将其打印到屏幕上,就像早期使用常规文件 I/O 的方法一样。
简而言之,使用mmap 与传统的文件读取方式非常相似,但有一些小的更改:
- 打开文件
open()是不够的。您还需要使用mmap.mmap()向操作系统发出信号,表示您希望将文件映射到 RAM。 - 您需要确保使用的模式与 兼容。的默认模式用于读取,但默认模式用于读取和写入。因此,打开文件时必须明确。
open()``mmap.mmap()``open()``mmap.mmap() - 您需要使用该对象而不是 返回的标准文件对象执行所有读取和写入。
mmap``open()
性能影响
内存映射方法比典型的文件 I/O 稍微复杂一些,因为它需要创建另一个对象。但是,在读取仅几兆字节的文件时,这种微小的更改可以带来巨大的性能优势。
以下是阅读著名小说《堂吉诃德的历史》的原始文本的比较,大约是 2.4 兆字节:
>>> import timeit
>>> timeit.repeat(
... "regular_io(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io, filename")
[0.02022400000000002, 0.01988580000000001, 0.020257300000000006]
>>> timeit.repeat(
... "mmap_io(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io, filename")
[0.006156499999999981, 0.004843099999999989, 0.004868600000000001]
这测量使用常规文件 I/O 和内存映射文件 I/O 读取整个 2.4 MB 文件的时间量。如您所见,内存映射方法大约需要 .005 秒,而常规方法几乎需要 02.<> 秒。读取较大的文件时,此性能改进可能会更大。
注意:这些结果是使用Windows 10和Python 3.8收集的。由于内存映射非常依赖于操作系统实现,因此结果可能会有所不同。
Python 的文件对象提供的 API 与传统文件对象非常相似,除了一个额外的超能力:Python 的文件对象可以像字符串对象一样切片!mmap``mmap
mmap对象创建
mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ)
mmap需要一个文件描述符,该描述符来自常规文件对象的方法fileno()。
文件描述符是操作系统容用来追踪打开的文件的内部标识,通常是一个整数
第二个参数是length=0这是内存映射的长度(以字节为单位)。0是一个特殊值,指示系统因创建足够大的内存映射以容纳整个文件。
access参数告诉操作系统您将如何与映射的内存进行交互。选项包括ACCESS_READ、ACCESS_WRITE、ACCESS_COPY、ACCESS_DEFAULT。类似于内置open()的mode参数。
- ACCESS_READ创建只读内存映射
- ACCESS_DEFAULT:默认为可选prot参数中指定的模式,该模式用于内存保护;
内存保护是一种控制计算机上内存访问权限的方法,是大多数现代指令集体系结构和操作系统的一部分。内存保护的主要目的是防止进程访问尚未分配给它的内存。这可以防止进程中的错误或恶意软件影响其他进程或操作系统本身。保护可能包括对指定内存区域的所有访问、写入访问或尝试执行该区域的内容。尝试访问未经授权的内存会导致硬件故障,例如分段错误、存储违规异常,通常会导致违规进程异常终止。计算机安全的内存保护包括其他技术,如地址空间布局随机化和可执行空间保护.
- ACCESS_WRITE和ACCESS_COPY:是两种写入模式。
文件描述符、length和access参数表示创建Windows、linux和MacOS等操作系统的内存映射文件所需的最低限度。上面的代码是跨平台的,这意味着踏进通过所有操作系统上的内存映射接口读取文件,而无需知道代码在哪个操作系统上运行。
另一个有用的参数是offset量,它可以是一种节省内存的技术。这将指示mmap从文件中的指定偏移量开始创建内存映射。
mmap对象作为字符串
如前所述,内存映射以字符串的形式透明地将文件内容加载到内存中。因此,打开文件后,您可以执行许多与字符串相同的操作,例如切片:
import mmap
def mmap_io(filename):
with open(filename, mode="r", encoding="utf8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
print(mmap_obj[10:20])
此代码将 mmap_obj 个字符从mmap_obj打印到屏幕上,并将这 10 个字符读入物理内存。同样,数据是延迟读取的。
切片不会推进内部文件位置。因此,如果你在切片之后调用 read()那么你仍然会从文件的开头读取。
搜索内存映射文件
除了切片之外,mmap 模块还允许其他类似字符串的行为,例如使用 find() 和 rfind() 在文件中搜索特定文本。find()例如,这里有两种方法可以查找文件中第一次出现的" the ":
import mmap
def regular_io_find(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
text = file_obj.read()
print(text.find(" the "))
def mmap_io_find(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
print(mmap_obj.find(b" the "))
这两个函数都在文件中搜索第一次出现的" the "之间的主要区别在于,第一个在字符串对象上使用find(),而第二个在内存映射文件对象上使用find()
注意:mmap对字节进行操作,而不是对字符串进行操作
性能差异
>>> import timeit
>>> timeit.repeat(
... "regular_io_find(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_find, filename")
[0.01919180000000001, 0.01940510000000001, 0.019157700000000027]
>>> timeit.repeat(
... "mmap_io_find(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_find, filename")
[0.0009397999999999906, 0.0018005999999999855, 0.000826699999999958]
这相差几个数量级!同样,您的结果可能会因操作系统而异。
内存映射文件也可以直接与正则表达式一起使用。请考虑以下示例,该示例查找并打印出所有五个字母的单词:
\b是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
import re
import mmap
def mmap_io_re(filename):
five_letter_word = re.compile(rb"\b[a-zA-Z]{5}\b")
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
for word in five_letter_word.findall(mmap_obj):
print(word)
此代码读取整个文件并打印出每个包含正好五个字母的单词。请记住,内存映射文件使用字节字符串,因此正则表达式也必须使用字节字符串。
下面是使用常规文件 I/O 的等效代码:
import re
def regular_io_re(filename):
five_letter_word = re.compile(r"\b[a-zA-Z]{5}\b")
with open(filename, mode="r", encoding="utf-8") as file_obj:
for word in five_letter_word.findall(file_obj.read()):
print(word)
此代码还打印出文件中的所有五个字符的单词,但它使用传统的文件 I/O 机制而不是内存映射文件。和以前一样,两种方法的性能不同:
>>> import timeit
>>> timeit.repeat(
... "regular_io_re(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_re, filename")
[0.10474110000000003, 0.10358619999999996, 0.10347820000000002]
>>> timeit.repeat(
... "mmap_io_re(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_re, filename")
[0.0740976000000001, 0.07362639999999998, 0.07380980000000004]
内存映射方法仍然快一个数量级
作为文件的内存映射对象
内存映射文件是部分字符串和部分文件,因此 mmap 还允许您执行常见的文件操作,如 seek()、tell() 和 readline()``seek()这些函数的工作方式与常规文件对象对应函数完全相同。
例如,下面介绍如何查找文件中的特定位置,然后执行单词搜索:
import mmap
def mmap_io_find_and_seek(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
mmap_obj.seek(10000)
mmap_obj.find(b" the ")
此代码将查找文件中的位置 10000,然后找到第一次出现的" the ".
seek() 在内存映射文件上的工作方式与在常规文件上的工作方式完全相同:
def regular_io_find_and_seek(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
file_obj.seek(10000)
text = file_obj.read()
text.find(" the ")
这两种方法的代码非常相似。让我们看看它们的性能如何比较:
>>> import timeit
>>> timeit.repeat(
... "regular_io_find_and_seek(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_find_and_seek, filename")
[0.019396099999999916, 0.01936059999999995, 0.019192100000000045]
>>> timeit.repeat(
... "mmap_io_find_and_seek(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_find_and_seek, filename")
[0.000925100000000012, 0.000788299999999964, 0.0007854999999999945]
同样,只需对代码进行一些小的调整,您的内存映射方法就会快得多。
使用Python的mmap编写内存映射文件
内存映射对于读取文件最有用,但您也可以使用它来写入文件。用于写入文件的 mmap API 与常规文件 I/O 非常相似,只是有一些不同。
下面是将文本写入内存映射文件的示例:
import mmap
def mmap_io_write(filename, text):
with open(filename, mode="w", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj:
mmap_obj.write(text)
此代码将文本写入内存映射文件。但是,如果在创建 mmap 对象时文件为空,它将引发 ValueError 异常。
Python 的 mmap 模块不允许空文件的内存映射。这是合理的,因为从概念上讲,空的内存映射文件只是内存的缓冲区,因此不需要内存映射对象。
通常,内存映射在读取或读/写模式下使用。例如,以下代码演示如何快速读取文件并仅修改其中的一部分:
import mmap
def mmap_io_write(filename):
with open(filename, mode="r+") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj:
mmap_obj[10:16] = b"python"
mmap_obj.flush()
此函数将打开一个已经包含至少 16 个字符的文件,并将字符 10 到 15 更改为"python".
写入
mmap_obj的更改在磁盘上的文件和内存中可见。官方 Python 文档建议始终调用flush()以确保数据写回磁盘。
写入模式
写入操作的语义由access参数控制。写入内存映射文件和常规文件之间的一个区别是access参数的选项。有两个选项可以控制如何将数据写入内存映射文件:
ACCESS_WRITE指定直写语义,这意味着数据将通过内存写入并持久保存在磁盘上。ACCESS_COPY不会将更改写入磁盘,即使调用了flush()
换句话说,ACCESS_WRITE同时写入内存和文件,而ACCESS_COPY只写入内存而不写入基础文件。
搜索和替换
内存映射文件将数据公开为字节字符串,但与常规字符串相比,该字节字符串具有另一个重要优势。内存映射文件数据是可变字节的字符串。这意味着编写搜索和替换文件中数据的代码更加直接和高效:
import mmap
import os
import shutil
def regular_io_find_and_replace(filename):
with open(filename, "r", encoding="utf-8") as orig_file_obj:
with open("tmp.txt", "w", encoding="utf-8") as new_file_obj:
orig_text = orig_file_obj.read()
new_text = orig_text.replace(" the ", " eht ")
new_file_obj.write(new_text)
shutil.copyfile("tmp.txt", filename)
os.remove("tmp.txt")
def mmap_io_find_and_replace(filename):
with open(filename, mode="r+", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj:
orig_text = mmap_obj.read()
new_text = orig_text.replace(b" the ", b" eht ")
mmap_obj[:] = new_text
mmap_obj.flush()
这两个函数都将给定文件中的" the " 更改为 " eht "如您所见,内存映射方法大致相同,但它不需要手动跟踪其他临时文件即可就地进行替换。
在这种情况下,内存映射方法实际上对于此文件长度略慢。因此,对内存映射文件执行完全搜索和替换可能是最有效的方法,也可能不是最有效的方法。这可能取决于许多因素,例如文件长度、机器的 RAM 速度等。可能还有一些操作系统缓存会扭曲时间。如您所见,常规 IO 方法在每次调用时都加快了速度。
>>> import timeit
>>> timeit.repeat(
... "regular_io_find_and_replace(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_find_and_replace, filename")
[0.031016973999996367, 0.019185273000005054, 0.019321329999996806]
>>> timeit.repeat(
... "mmap_io_find_and_replace(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_find_and_replace, filename")
[0.026475408999999672, 0.030173652999998524, 0.029132930999999473]
在此基本的搜索和替换方案中,内存映射会产生稍微简洁的代码,但并不总是显着提高速度。正如他们所说,“您的里程可能会有所不同。
使用Python的mmap在进程间进行共享数据
到目前为止,您仅对磁盘上的数据使用内存映射文件。但是,您也可以创建没有物理存储的匿名内存映射。这可以通过传递 -1 作为文件描述符来完成:
import mmap
with mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE) as mmap_obj:
mmap_obj[0:100] = b"a" * 100
print(mmap_obj[0:100])
这将在 RAM 中创建一个匿名内存映射对象,其中包含字母"a"的 100 个副本.
匿名内存映射对象实质上是内存中特定大小的缓冲区,由 length 参数指定。缓冲区类似于 io.StringIO 或 io.BytesIO标准库中的字节IO。但是,匿名内存映射对象支持跨多个进程共享,而这两个进程都不支持io.StringIO 也不是 io.BytesIO允许。
这意味着您可以使用匿名内存映射对象在进程之间交换数据,即使进程具有完全独立的内存和堆栈。下面是创建匿名内存映射对象以共享可从两个进程写入和读取的数据的示例:
import mmap
def sharing_with_mmap():
BUF = mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE)
pid = os.fork()
if pid == 0:
# Child process
BUF[0:100] = b"a" * 100
else:
time.sleep(2)
print(BUF[0:100])
os.fork()只能在linux中使用,在windows中会报错(https://www.jianshu.com/p/0ba4e7e2647b)
使用此代码,可以创建 100 字节的内存映射缓冲区,并允许从两个进程读取和写入该缓冲区。如果要节省内存并仍然在多个进程之间共享大量数据,则此方法非常有用。
使用内存映射共享内存有几个优点:
- 不必在进程之间复制数据。
- 操作系统以透明方式处理内存。
- 数据不必在进程之间腌制(pickle),从而节省了 CPU 时间。
说到酸洗(pickle),值得指出的是,mmap 与更高层次、功能更全的 API 不兼容,例如内置的multiprocessing模块。multiprocessing模块需要在进程之间传递数据以支持 pickle 协议,而 mmap 没有。
您可能想使用multiprocessing而不是 os.fork()如下所示:
from multiprocessing import Process
def modify(buf):
buf[0:100] = b"xy" * 50
if __name__ == "__main__":
BUF = mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE)
BUF[0:100] = b"a" * 100
p = Process(target=modify, args=(BUF,))
p.start()
p.join()
print(BUF[0:100])
在这里,您尝试创建一个新进程并向其传递内存映射缓冲区。此代码将立即引发 TypeError,因为无法对 mmap 对象进行酸洗,这是将数据传递到第二个进程所必需的。因此,要使用内存映射共享数据,您需要坚持使用较低级别的 os.fork().
如果您使用的是 Python 3.8 或更高版本,则可以使用新的 shared_memory 模块更有效地跨 Python 进程共享数据:
from multiprocessing import Process
from multiprocessing import shared_memory
def modify(buf_name):
shm = shared_memory.SharedMemory(buf_name)
shm.buf[0:50] = b"b" * 50
shm.close()
if __name__ == "__main__":
shm = shared_memory.SharedMemory(create=True, size=100)
try:
shm.buf[0:100] = b"a" * 100
proc = Process(target=modify, args=(shm.name,))
proc.start()
proc.join()
print(bytes(shm.buf[:100]))
finally:
shm.close()
shm.unlink()
这个小程序创建一个包含 100 个字符的列表,并修改另一个进程中的前 50 个字符。
请注意,只有缓冲区的名称传递给第二个进程。然后,第二个进程可以使用唯一名称检索相同的内存块。这是由 mmap 提供支持的 shared_memory 模块的一项特殊功能。在后台,shared_memory模块使用每个操作系统的唯一 API 为您创建命名内存映射。
小结
内存映射是文件 I/O 的另一种方法,Python 程序可以通过 mmap 模块使用它。内存映射使用较低级别的操作系统 API 将文件内容直接存储在物理内存中。此方法通常可以提高 I/O 性能,因为它避免了许多成本高昂的系统调用,并减少了昂贵的数据缓冲区传输。
目的:使用内存映射文件而不是直接读取内容。
内存映射文件使用操作系统虚拟内存直接访问文件上的数据,而不是通过常规的I/O方法。
内存映射通常可以提高I/O性能,因为对于每次访问它不涉及单独的系统调用,也不要会在缓冲池之间复制数据,而是内核和用户程序可以直接访问内存。