前言 商汤大模型团队提出的文生图大模型RAPHAEL,可以生成具有高度艺术风格或者摄影风格的图片,速度极快。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
自从 2022 年开始,以 Stable Diffusion、ChatGPT 为代表的生成式 AI 席卷了整个 AI 社区,AI 大模型也走进了公众的视野。
但是,现有的绝大部分模型仍然做不到生成高质量且符合文本描述的图。
本文将介绍商汤大模型团队提出的文生图大模型 RAPHAEL,可以生成具有高度艺术风格或者摄影风格的图片,而且生成速度极快,并且在各项测试上击败了 Stable Diffusion XL,DALL-E 2,DeepFloyd 等模型。

论文地址:https://arxiv.org/pdf/2305.18295.pdf
该研究还提供了将 RAPHAEL 作为基座的 artist v0.3.0 beta 模型的在线试玩链接,可以在 https://miaohua.sensetime.com/zh-CN/ 中免费试玩(注意不要选错模型了)。同时,研究者也设置了反馈按钮(在生成图的旁边)来帮他们不断优化,希望大家可以积极体验并进行反馈。
效果展示





更多效果展示:

方法介绍
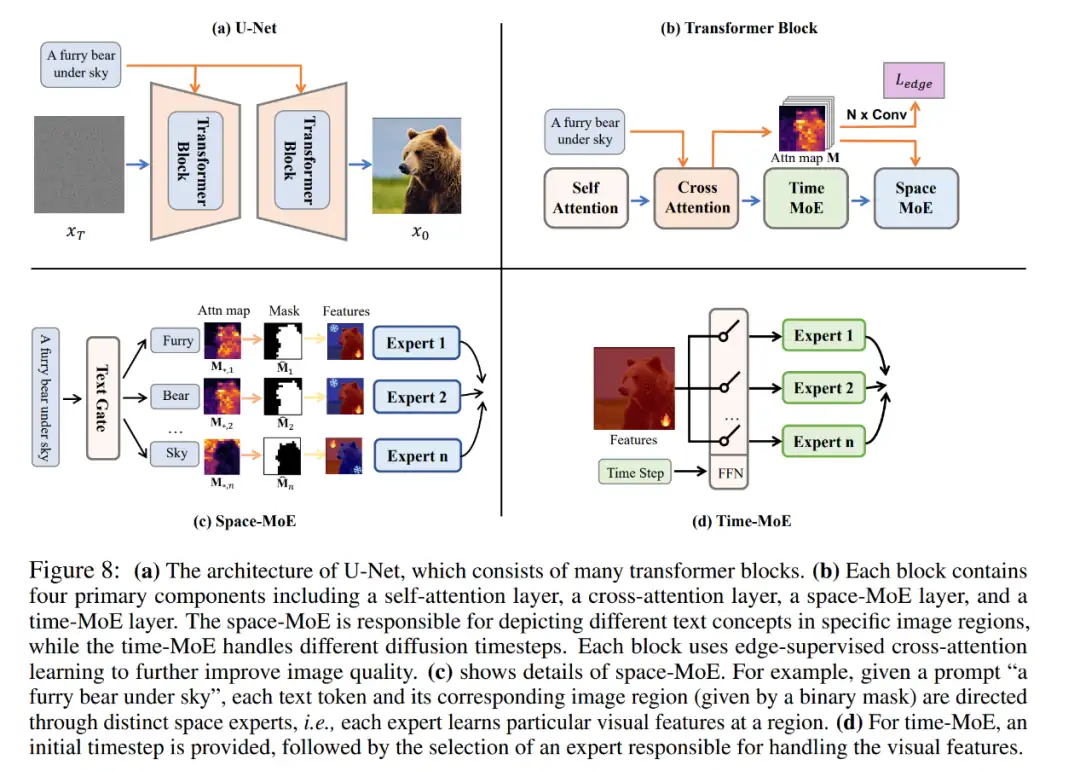
本文共提出了三个组件: Space-MoE, Time-MoE, 以及 Edge-supervised learning 模块。
Space-MoE 找出了文本中每一个 token 在图片中对应的区域,用不同的 expert 来处理不同的区域,最后再融合。
Time-MoE 模块使得模型能够在不同的 timestep 上选择不同的 expert;这些 MoE 事实上组成了一系列的 diffusion path,用来画某一类名词,动词,或者形容词。这些词的 diffusion path 都可以被 XGBoost 算法分开,证明了每一个 path 负责一个词。如下图所示:
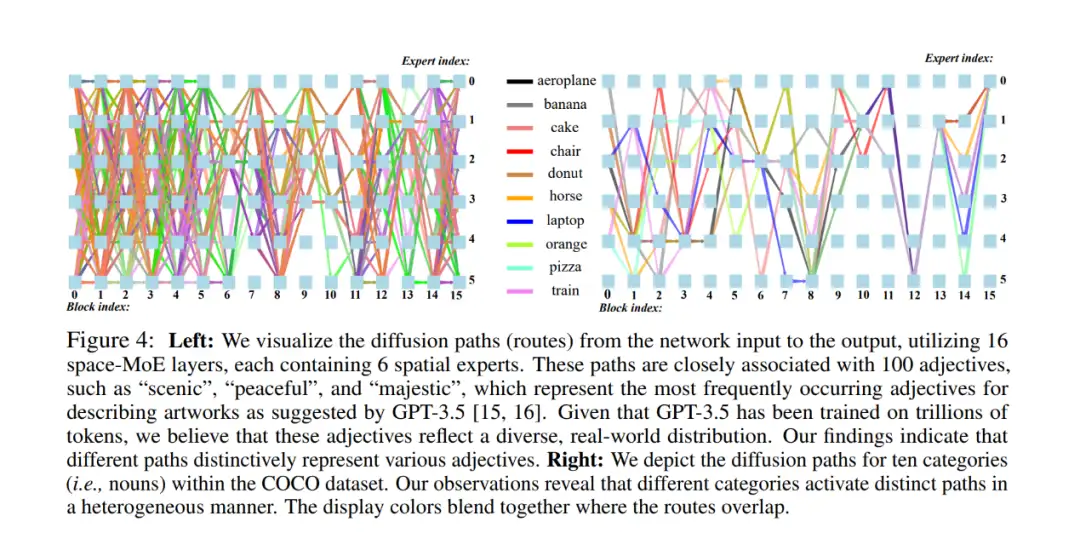
Edge-supervised learning 使用物体的轮廓纹理来监督 attention 模块的学习,帮助模型更好的学习到图片的结构信息。
该研究也做了充分的消融实验来验证这三个模块的效果,具体可见论文的正文部分。研究者使用了清洗后的 LAION-5B 以及一些内部数据集来训练 RAPHAEL,LAION-5B 的清洗方案参考了 Stable Diffusion,超参数文中都有提供。同时,为了使得网络能够生成任意长宽比的图片,受到目标检测领域的启发,研究者提出了多尺度训练:即把不同尺度的图,根据这一尺度的图的数量,输入不同的 GPU 训练。具体的网络结构见下图:
实验结果
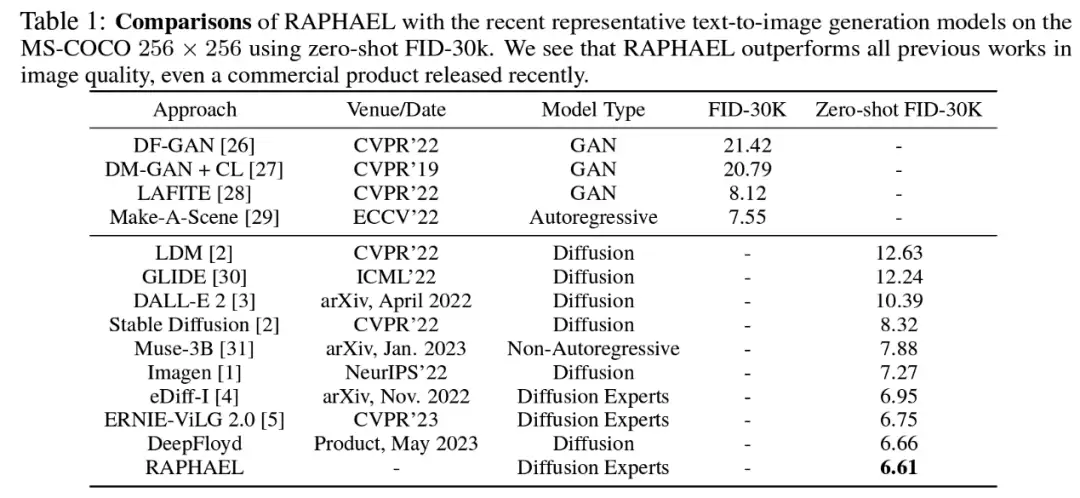
该研究首先在 FID 上进行了测试,FID 是一个衡量图片生成质量和多样性的指标,常常被用于评测生成模型的能力,实验在这一指标上击败了如 Stable Diffusion,DALL-E 2 等模型,达到 6.61。
此外,研究者同时也基于人类评估给出了一些指标,结论发现 RAPHAEL 在图文匹配度以及生成质量上均超过了 Stable Diffusion XL,DeepFloyd,文心一格以及 DALL-E 2,如下图所示:

一些小技巧
可能很多读者没有练习过怎么写文生图的 prompt,因而本文也提供了描述词优化的功能,可以将简单的 prompt 扩展成能得到优秀效果的 prompt。当然,一些国外的网站也提供了一些优秀的 prompt 库:
同时建议大家把步数拉到 100,图片质量会更佳。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
中科院自动化所发布FastSAM | 精度相当,速度提升50倍!!!
大核卷积网络是比 Transformer 更好的教师吗?ConvNets 对 ConvNets 蒸馏奇效
MaskFormer:将语义分割和实例分割作为同一任务进行训练
CVPR 2023 VAND Workshop Challenge零样本异常检测冠军方案
沈春华团队最新 | SegViTv2对SegViT进行全面升级,让基于ViT的分割模型更轻更强
刷新20项代码任务SOTA,Salesforce提出新型基础LLM系列编码器-解码器Code T5+
CVPR最佳论文颁给自动驾驶大模型!中国团队第一单位,近10年三大视觉顶会首例
最新轻量化Backbone | FalconNet汇聚所有轻量化模块的优点,成就最强最轻Backbone
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary