1 常用显存管理
1.1 CUDA Runtime API
在CUDA编程中,编程人员通常会使用以下CUDART同步API进行显存申请和释放,比如调用cudaMalloc并传入所需的显存size即可返回显存的虚拟地址,使用完成后可调用cudaFree进行释放。
__host__ __device__ cudaError_t cudaMalloc(void **devPtr, size_t size); __host__ cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flags = cudaMemAttachGlobal); __host__ cudaError_t cudaMallocPitch(void **devPtr, size_t *pitch, size_t width, size_t height); __host__ __device__ cudaError_t cudaFree(void *devPtr);
此外,CUDART也提供了显存申请和释放的异步API供编程人员使用,只需传入CUDA Stream即可调用,返回给编程人员的也是显存的虚拟地址。
__host__ cudaError_t cudaMallocAsync(void **devPtr, size_t size, cudaStream_t hStream); __host__ cudaError_t cudaFreeAsync(void *devPtr, cudaStream_t hStream);
1.2 CUDA Driver API
CUresult cuMemAlloc(CUdeviceptr* dptr, size_t bytesize);
CUresult cuMemAllocManaged(CUdeviceptr* dptr, size_t bytesize, unsigned int flags);
CUresult cuMemAllocPitch(CUdeviceptr* dptr, size_t* pPitch, size_t WidthInBytes, size_t Height,
unsigned int ElementSizeBytes);
CUresult cuMemFree(CUdeviceptr dptr);
2
2.1 特性
就常用显存管理API来说,由于编程人员只能获取到显存的虚拟地址,如果有动态调整显存大小的需求(比如GPU上vector扩容),用户必须显示地申请更大的一块显存,并从原始显存中复制数据到新显存,再释放原始显存,然后继续跟踪新分配的显存地址,这样的操作通常会导致应用程序的性能降低和较高的显存带宽峰值利用率。
在CUDA 10.2中引入VMM API为应用程序提供了一种直接管理统一虚拟地址空间的方法,可以将显存的虚拟地址和物理地址解耦,允许编程人员分别处理它们。VMM API允许编程人员在合适的时候将显存的虚拟地址与物理地址进行映射和解映射。借助VMM API可以更好地解决动态调整显存大小的需求,只需要申请额外的物理地址,再与原始虚拟地址扩展的空间进行映射,既不需要更换追踪的显存地址,也不需要将数据从原始显存拷贝到新显存。因此,VMM API能够帮助编程人员构建更高效的动态数据结构,并更好地控制应用程序中的显存使用。参考
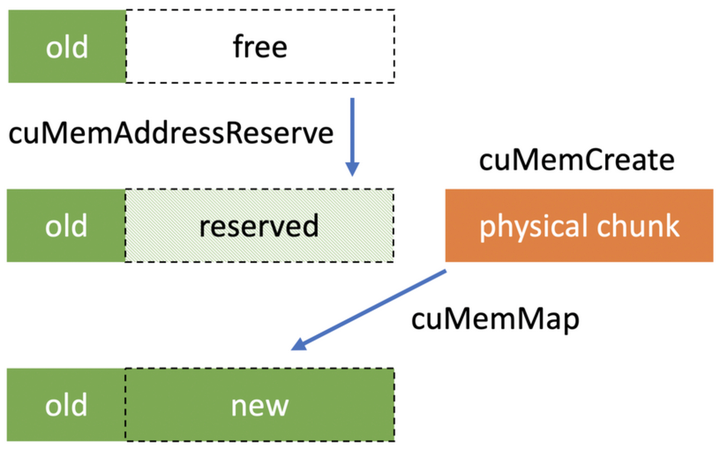
2.2 API
// Calculates either the minimal or recommended granularity.
CUresult cuMemGetAllocationGranularity(size_t* granularity, const CUmemAllocationProp* prop,
CUmemAllocationGranularity_flags option);
// Allocate an address range reservation.
CUresult cuMemAddressReserve(CUdeviceptr* ptr, size_t size, size_t alignment, CUdeviceptr addr,
unsigned long long flags);
// Free an address range reservation.
CUresult cuMemAddressFree(CUdeviceptr ptr, size_t size);
// Create a CUDA memory handle representing a memory allocation of a given size described by the given properties.
CUresult cuMemCreate(CUmemGenericAllocationHandle* handle, size_t size, const CUmemAllocationProp* prop,
unsigned long long flags);
// Release a memory handle representing a memory allocation which was previously allocated through cuMemCreate.
CUresult cuMemRelease(CUmemGenericAllocationHandle handle);
// Retrieve the contents of the property structure defining properties for this handle.
CUresult cuMemGetAllocationPropertiesFromHandle(CUmemAllocationProp* prop, CUmemGenericAllocationHandle handle);
// Maps an allocation handle to a reserved virtual address range.
CUresult cuMemMap(CUdeviceptr ptr, size_t size, size_t offset, CUmemGenericAllocationHandle handle,
unsigned long long flags);
// Unmap the backing memory of a given address range.
CUresult cuMemUnmap(CUdeviceptr ptr, size_t size);
// Get the access flags set for the given location and ptr.
CUresult cuMemGetAccess(unsigned long long* flags, const CUmemLocation* location, CUdeviceptr ptr);
// Set the access flags for each location specified in desc for the given virtual address range.
CUresult cuMemSetAccess(CUdeviceptr ptr, size_t size, const CUmemAccessDesc* desc, size_t count);
3 使用
参考
3.1 显存申请
显存申请主要包括获取显存粒度、申请虚拟地址、申请物理地址、虚拟地址与物理地址映射、释放物理地址handle(注意此处并不会真正释放物理地址)和设置访问权限几个步骤。
cudaError_t vmm_alloc(void **ptr, size_t size) {
CUmemAllocationProp prop = {};
memset(prop, 0, sizeof(CUmemAllocationProp));
prop->type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop->location.type = CU_MEM_LOCATION_TYPE_DEVICE;
prop->location.id = currentDevice;
size_t granularity = 0;
if (cuMemGetAllocationGranularity(&granularity, &prop, CU_MEM_ALLOC_GRANULARITY_MINIMUM) != CUDA_SUCCESS) {
return cudaErrorMemoryAllocation;
}
size = ((size - 1) / granularity + 1) * granularity;
CUdeviceptr dptr;
if (cuMemAddressReserve(&dptr, size, 0, 0, 0) != CUDA_SUCCESS) {
return cudaErrorMemoryAllocation;
}
CUmemGenericAllocationHandle allocationHandle;
if (cuMemCreate(&allocationHandle, size, &prop, 0) != CUDA_SUCCESS) {
return cudaErrorMemoryAllocation;
}
if (cuMemMap(dptr, size, 0, allocationHandle, 0) != CUDA_SUCCESS) {
return cudaErrorMemoryAllocation;
}
if (cuMemRelease(allocationHandle) != CUDA_SUCCESS) {
return cudaErrorMemoryAllocation;
}
CUmemAccessDesc accessDescriptor;
accessDescriptor.location.id = prop.location.id;
accessDescriptor.location.type = prop.location.type;
accessDescriptor.flags = CU_MEM_ACCESS_FLAGS_PROT_READWRITE;
if (cuMemSetAccess(dptr, size, &accessDescriptor, 1) != CUDA_SUCCESS) {
return cudaErrorMemoryAllocation;
}
*ptr = (void *)dptr;
return cudaSuccess;
}
3.2 显存释放
显存释放主要包括获取显存粒度、虚拟地址与物理地址解映射(注意此处解映射之后物理地址随即释放)和释放虚拟地址几个步骤。
cudaError_t vmm_free(void *ptr, size_t size) {
if (!ptr) {
return cudaSuccess;
}
CUmemAllocationProp prop = {};
memset(prop, 0, sizeof(CUmemAllocationProp));
prop->type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop->location.type = CU_MEM_LOCATION_TYPE_DEVICE;
prop->location.id = currentDevice;
size_t granularity = 0;
if (cuMemGetAllocationGranularity(&granularity, &prop, CU_MEM_ALLOC_GRANULARITY_MINIMUM) != CUDA_SUCCESS) {
return cudaErrorMemoryAllocation;
}
size = ((size - 1) / granularity + 1) * granularity;
if (cuMemUnmap((CUdeviceptr)ptr, size) != CUDA_SUCCESS ||
cuMemAddressFree((CUdeviceptr)ptr, size) != CUDA_SUCCESS) {
return cudaErrorInvalidValue;
}
return cudaSuccess;
}
4 问题
4.1 P2P访问
使用CUDART实现设备的对等访问可以直接调用cudaDeviceEnablePeerAccess API设置,而使用VMM实现设备的对等访问需要调用cuMemSetAccess API设置显存的访问权限。
4.2 带宽
笔者曾经做过一个项目,期间对比测试过VMM和cuMemAlloc申请的显存在H2D、D2H和D2D带宽上的差异(Tesla V100,CUDA 10.2,CUDA Driver 470.80,主机内存为普通内存或pinned memory),发现VMM的带宽略低于cuMemAlloc,尝试过并行优化、异步优化和小包优化,效果都不明显。百思不得其解后向Nvidia反馈,其美研工程师排查后表示是CUDA Driver内部的一个bug,发过来修复版本后测试两者带宽无明显差异。
