进程的虚拟地址空间内存划分和布局
编程语言->产生指令和数据
- 程序生成exe可执行文件,加载到内存后(不是一步直接加载到物理内存中)如何存放。
- x86 32位linux下,linux会给进程分配一块2的32次方大小的一块空间(4G),这块空间是一块虚拟内存空间,虚拟内存空间本质上是系列数据结构。
- 这一块虚拟地址空间分为两块,3G的用户空间,1G的内核空间。
- 地址起始的一段内容是不可访问的,不可读写。
- .text为代码段,.rodata为read only只读数据段(常量区,只读不写)
- .data数据段,.bss也是数据段:前者存储初始化且不为0的数据,后者存储未初始化或初始化为0的。如一个全局变量默认初始化为0,是内核启动阶段操作系统默认对bss中的未初始化变量赋值0。
- .heap堆内存栈自上而下增长,即低地址->高地址。
- 加载的共享库即动态库。
- 函数运行,或产生线程时,都记录在栈stack上,栈自下而上增长,即高地址->低地址。
- 最后一段是命令行参数和环境变量。
- 内核空间。

图中gdata1-gdata6编译后产生数据于符号表,其中gdata1,gdata4存放于.data段;gdata2,gdata3,gdata5,gdata6存放于.bss段;a,b,c属于栈中的局部变量,链接器对此类变量不感兴趣,符号表不会记录,相反,这三行会产生三条指令。e存放于.data段;f,g存放于.bss段。打印c会显示栈上存放的无效值,打印g则输出0,因为g存储在bss段,自动初始化为0。
红色框存放于代码段.text,蓝色与棕色狂产生变量符号,存放于数据段。
a-c汇编后生成指令存放于代码段,代码执行期间,系统为main函数开辟栈,执行指令将abc的值存放到对应存储空间
每一个进程的用户空间是私有的,内核空间是共享的,进程间可以通过向内核空间中读写数据实现共享。
进程的通信方式:匿名管道通信
函数的调用堆栈详细过程

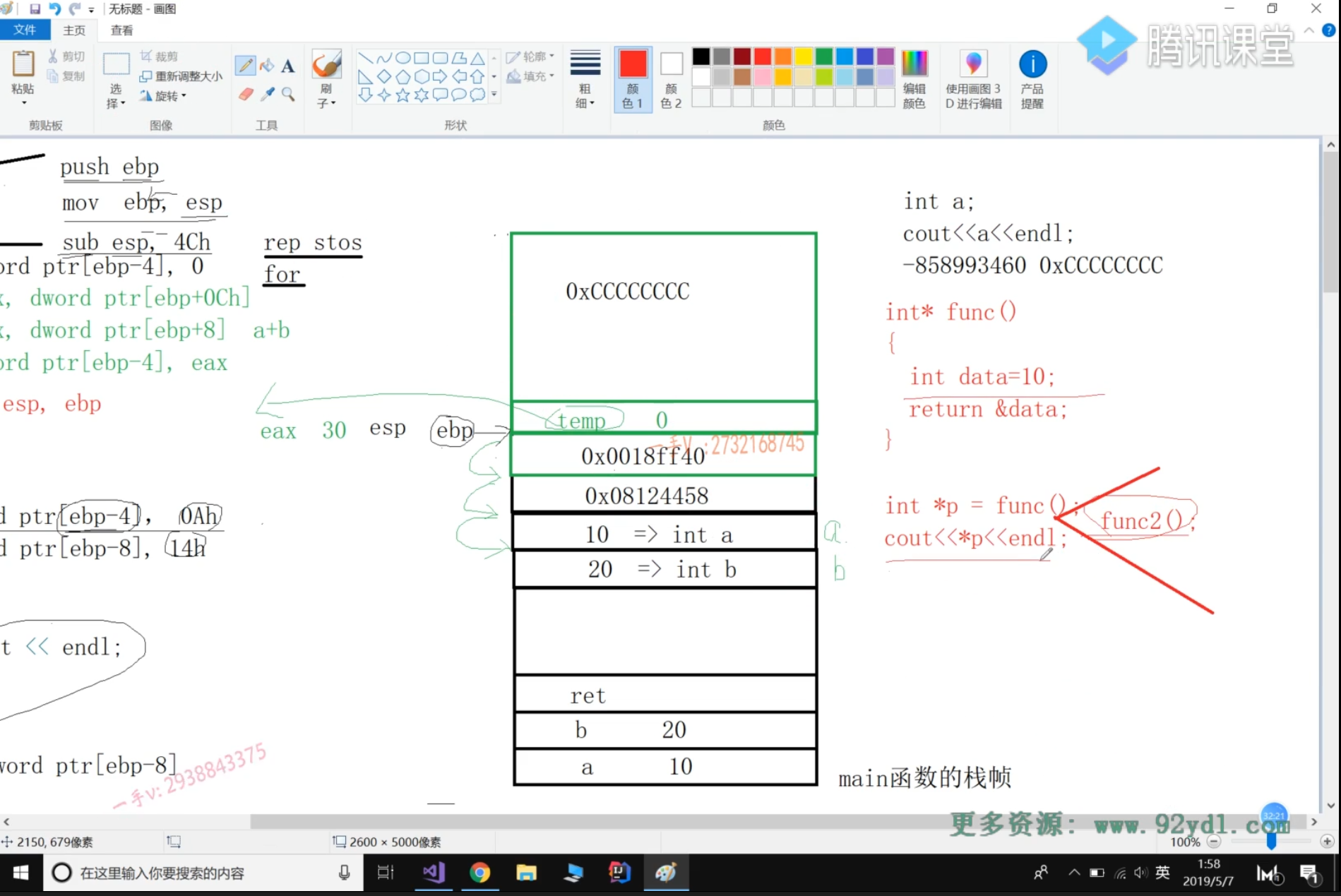
- 第一句:初始化a,符号表中不产生a变量,仅在代码段中保存此句汇编代码,即mov语句,mov语句把10赋值给栈指针
- 第二局:同第一句
- 第三局:将实参的值传给形参,调用sum实现相加函数。
- 首先,sum函数的参数a,b存为寄存器变量并压栈(push,注意压栈是将变量压到栈顶esp),其中形参压栈顺序是从右向左。然后call调用的sum函数,然后立即将call的下一条语句在.text区中的内存地址压栈,该地址标记sum返回后下一步运行的位置。
- 进入sum后,执行代码前,要先压入ebp栈底地址(标记main),然后开新栈帧:mov ebp, esp,然后esp移动。
- 执行sum内部的几条语句
- 将返回结果保存至寄存器变量中
- 栈帧回退:mov esp, ebp,即将栈顶指针指回栈底。这个过程中,栈被释放,但内容没有被清理,如果一个函数func1返回一个指针,在main中访问该指针指向的值,依然可以访问到,但不安全;如果后续有func2调用,从而建立新的栈帧,那么这块内存可能会被修改。
- pop ebp弹栈:即将之前压入的ebp栈底地址赋值回给ebp,这意味着函数执行返回了main
- ret把再次出栈的内容放入CPU的PC寄存器中,继续执行call sum的下一行语句,并继续把两个形参变量所占用的栈空间交还系统,栈顶地址-8
程序编译与链接原理

- 预编译:处理#命令,但保留#pragma,删除注释。
- 编译:词法分析、语法分析、语义分析和优化,生成汇编代码。
- 汇编:将汇编代码翻译成机器码(AT&T,x86语法),打包为可重定位二进制目标文件,此文件不可执行。输出符号表。
- 链接:合并.o文件段,合并符号表,解析并符号重定向。
//以下为main文件
extern int gdata; //gdata *UND*代表需使用但未定义
int sum(int, int); //sum *UND*
int data = 20; //data .data
int main(){ //main .text
int a = gdata;
int b = data;
int ret = sum(a, b);
return 0;
}
//以下为sum文件
int gdata = 10; //gdata .data
int sum(int a, int b){ //sum_int_int .text
return a + b;
}
以上为.o文件中的部分符号注释
具体的.o文件的格式组成包括各种段

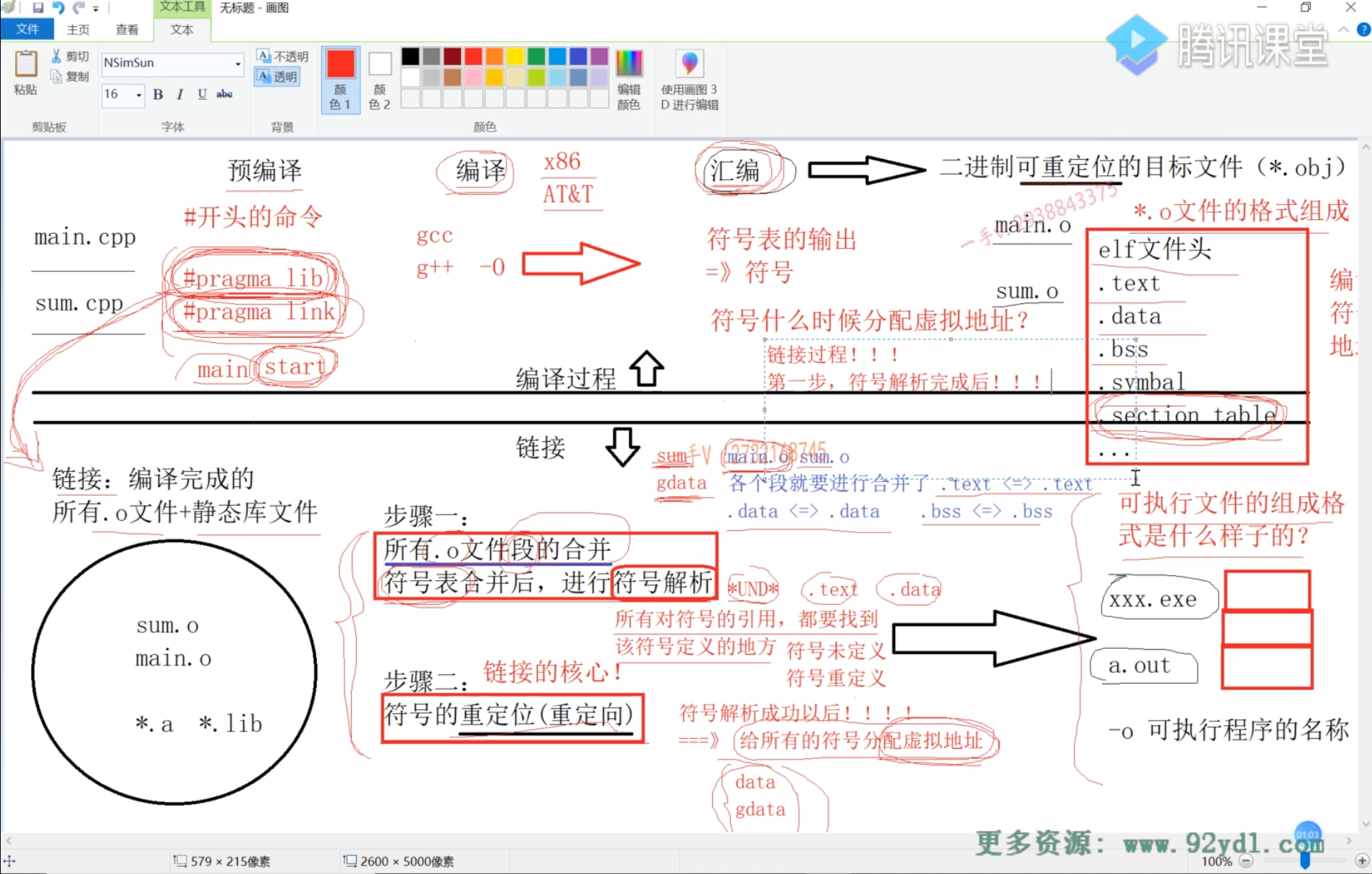
编译过程中不为符号分配地址,通过readelf可以观察到地址皆为0。虽然指令已经在编译阶段翻译好,但变量地址皆为0,需要在链接阶段补充,也因此.o文件无法执行。
链接
链接过程合并若干个.o文件的段合并:text段合并,data段合并...,以及符号表的合并。
-
符号表合并:检查符号表,所有对符号的引用(*UND*),都要找到该符号定义的地方,当然符号定义只能有一个,不可重定义,不可没有。最终符号解析成功。
-
符号解析成功后,在代码段中,为所有符号分配虚拟地址,并把这些地址写回指令中。这个过程叫做符号重定向。
可执行文件
链接产生可执行文件,可执行文件与二进制可重定向文件段格式几乎一致,但可执行文件中多了一个program headers段,这其中包含若干load项,比如.text,.data,这意味着这些load项要在代码执行时,加载如虚拟内存空间
参数为默认值的函数
- 参数从右面开始给默认值。
- 如果不缺省参数,需要在汇编层面mov实参到寄存器,并push压栈此寄存器值;而如果缺省一个参数,在汇编代码层面,相当于少一句mov指令,而可以直接push一个立即数。从而提高效率。
- 定义和声明两阶段都可以给默认值,但二者只能给一次,即使定义和声明两阶段给了相同的默认值也不可以。不过有下述情况。
-
#include<iostream> using namespace std; int sum(int a, int b = 10); int sum(int a = 10, int b); //相当于int sum(int a = 10, int b = 10) int main(){ int a = 20; cout << sum() << endl; cout << sum(10); } int sum(int a, int b){ return a + b; }
内联函数
内联函数与普通函数的区别
inline函数:在编译过程中,就没有函数的调用开销了,在函数的调用点直接把函数的代码进行展开处理,符号表中也不产生内联函数符号。
- 函数的调用开销是什么:参数压栈,栈帧开辟,栈帧回退。
- inline只是建议,不是所有inline被编译器处理为内联函数,比如递归,编译器无法确定递归要执行多少次。大量出现的简单代码时候作为内联。
- debug版本下,inline不起作用,因为会导致无法调试。inline只在release版本下起作用。
函数重载
什么是函数重载:一组函数,函数名相同,但参数类型或个数不同。
C++为什么支持函数重载,但C不支持
- 本质是编译器产生符号的规则不一样:C++代码产生函数符号,由函数名和参数列表类型组成;而C代码产生函数符号,仅由函数名组成。当链接时,会发生符号的重定义。
重载的注意点
-
重载的前提是几个函数在同一作用域下。
//下述情况下可以正确调用对应的函数 #include<cstring> #include<iostream> using namespace std; bool compare(int a, int b){ cout << "int" << endl; return (a>b); } bool compare(double a, double b){ cout << "double" << endl; return(a>b); } bool compare(const char * a, const char * b){ cout << "double" << endl; return strcmp(a, b); } int main(){ compare(1, 2); compare(1.0, 2.0); compare("aa", "vv"); return 0; }//下述情况下无法正确调用对应的函数 #include<cstring> #include<iostream> using namespace std; bool compare(int a, int b){ cout << "int" << endl; return (a>b); } bool compare(double a, double b){ cout << "double" << endl; return(a>b); } bool compare(const char * a, const char * b){ cout << "double" << endl; return strcmp(a, b); } int main(){ bool compare(int, int);//当在局部声明了一个compare函数 compare(1, 2); //后续的所有compare函数在局部作用域即找到了可调用的函数,则不会继续向全局作用域寻找其他conpare函数 compare(1.0, 2.0); //会double强制类型转化int compare("aa", "vv"); //报错,无法强制类型转换 return 0; } -
const和volitale修饰形参,怎么影响形参类型的? 待补坑
-
一组函数的函数名和参数相同,返回类型不同,则不算重载。
-
什么是多态:编译期的静态多态:包含重载;运行期的动态多态。编译时期,指令就确定要重载哪个函数。
C++和C之间如何互相调用
-
下述为C++主程序调用C函数
//C规则下,只依据函数名生成符号表 int sum(int a, int b){ //sum .text return a + b; }//C++规则下,依据函数名与形参生成符号表 int sum(int a, int b); //sum_int_int "UND", 在链接时,无法匹配C中的符号sum int main(){ int ret = sum(10, 20); cout << "ret" << ret << endl; return 0; }extern "C" //这里把C函数的声明加入extern C中 { int sum(int a, int b); //按照C编译生成符号表 sum “UND” } int main(){ int ret = sum(10, 20); cout << "ret" << ret << endl; return 0; } -
同样,如果C主程序调用C++
extern "C" //cpp文件按照C编译 { int sum(int a, int b){ //sum .text return a + b; } }int sum(int a, int b); //sum “UND” int main(){ int ret = sum(10, 20); cout << "ret" << ret << endl; return 0; } -
经常写作
#ifdef __cplusplus //C++编译器内置的宏 extern "C"{ #endif //C++代码 #ifdef __cplusplus } #endif
const
怎么理解const?
- const修饰的变量不能再作为左值。即初始化后不能被修改。
C和C++中的const有什么区别?
-
C中const量可以只定义,但不被初始化(之后无法再赋值),称作常变量。事实上,通过指针仍可修改变量的值。
-
C++中的const必须初始化,称作常量。通过指针不可修改变量的值。
-
C和C++中对const变量的编译方式不同,C中const当作一个变量编译生成;C++中出现const常量名字的地方,都被常量的初始值替换,包括*(&a)这样的形式,也是直接当作a,替换。事实上,a所处的内存上的值已经被替换。
-
如果C++中const初始化为另一个变量,也是常变量。
int main() { const int a = 2; int arr[a]; //a是常变量,报错 int* p = (int *) & a; *p = 20; cout << a << endl << *p << endl << *(&a); //三者都是20。 }int main() { const int a = 2; int arr[a]; //a是常量,没问题 int* p = (int *) & a; *p = 20; cout << a << endl << *p << endl << *(&a); //a依然是2,*p是20,*(&a)依然是2。 }int main() { int c = 5; const int d = c; //即使是在C++中,这种初始化const变量的方式也只生成常变量。 cout << d << endl; int* p = (int*)&d; *p = 4; cout << d << endl; //可以被修改。 }
const修饰的量常出现错误:
- 常量不能直接作为左值(不可直接修改)
- 不能把常量的地址泄露给一个普通指针或普通引用(不可间接修改)
int main() { const int a = 5; int* p = &a; //不能把const int*转换为int*,但可以int*转换为const int* }
const结合一级指针
C++语言规范:const修饰的是离它最近的类型(*不能单独作为类型)
//一般使用前两种保护常量。
const int *p; //const修饰int,即指针所指向的值,p指向内容不变,但p的指向可变。
int const *p; //const修饰int,同上。
int *const p; //const修饰int *,指针p为常量,指向不可变,但可通过指针解引用修改指向内容。
const int *const p; //p指向const int且p的指向不变。
总结:
int * <- const int * //错误
const int * <- int * //正确
int main()
{
//const右面没有指针*的话,const不参与类型。二者类型皆为int *,二者也可相互赋值
int* p1 = nullptr;
int* const p2 = nullptr;
p1 = p2;
cout << typeid(p1).name() << endl;
cout << typeid(p2).name() << endl;
}
const结合二级(多级)指针
int main()
{
int a = 0;
int* p = &a;
//以下情况均错误
//const int** q = &p; //const修饰int,二次指向的值不能变,但q,*q可被赋值。同时也把const int暴露给了*p。
//int* const* q = &p; //const修饰前方int *,*q不能改变,但q,**q可被赋值。
//int** const q = &p; //const修饰前方int **,q不能改变,但*q,**q可被赋值。
const int *const* q = &p; //const修饰int和*q,即**q和*q都不能改变,q指向可改变。
}
总结:
int ** <- const int ** //错误
const int ** <- int ** //错误
int ** <- int* const* //错误
int* const* <- int ** //正确
引用
引用和指针的区别
-
引用是一种更安全的指针。
-
引用必须初始化,指针可以不初始化。引用初始化为另一个同类变量,特殊情况下可初始化为常量。
-
引用只有一级,没有多级引用。
-
从汇编指令层面看。对引用的处理,是采用指针的方法。因为引用是一种const指针。通过引用变量修改所引用内存的值,与通过指针解引用修改指针指向内存的值,二者的底层指令也是一样的。
-
数组如何被引用?
int a; int *b = &a; int &b = a; int array[5]; int (*p)[5] = &array int (&p)[5] = array -
引用虽然本质是指针,但使用时,总是要先进行解引用,因此进行sizeof运算,依然为所引用变量的字节数。
左值引用和右值引用
- 左值:有内存,有名字,值是可以修改的。
- 右值:反之。
- C++11提供了右值引用:右值引用也必须立即进行初始化操作,且只能使用右值进行初始化。右值引用可以修改右值。
- 右值引用专门引用右值,不能引用左值。
- 右值引用变量本身是一个左值,只能用左值引用引用它。
- 指令上,自动产生临时量,然后直接引用临时量。
//一般情况下,C++只允许左值引用,而不允许右值引用 int num = 10; const int &b = num; //正确 const int &c = 10; //错误 //右值引用 int num = 10; //int && a = num; //右值引用不能初始化为左值 int && a = 10; //指令层面,临时量xx=20,然后a引用xx a = 11; //右值引用可以修改右值
const,一级指针,引用的结合使用
为了观察赋值是否可行,可以先将引用换成指针的写法:引用号&修改为*,等式右侧加上取地址符&,然后比较等式两边的类型是否符合赋值规范。video
int main()
{
//int& p = 10 //错误
const int& p = 10; //正确,产生临时量,p是临时量的引用
int* const& q = (int*)0x0018ff44; //q是const修饰的int指针,不能写成const int* &q
}
int main()
{
int a = 1;
int* p = &a;
const int *& q = p;
//相当于const int ** q = &p; const int **和int **不能相互赋值。
return 0;
}
new和delete
new和malloc区别,delete和free区别
- malloc和free,是C的库函数;new和delete,是运算符。
- new不仅内存开辟,还能做内存的初始化,返回指针,如果开辟失败,抛出异常bad_alloc,而不是返回空指针;malloc只能进行内存开辟,返回指针,如果开辟失败,返回nullptr。malloc需要类型强制转换,new不需要。
- new有多少种?
int main()
{
int* p1 = new int(10);
int* p2 = new(nothrow)int;
const int* p3 = new const int(40);
//定位new,固定位置new一个对象
int data = 0;
int* p4 = new(&data) int(20);
cout << data;
}
类和对象,this