| 课程 | 软件工程 |
|---|---|
| 要求 | 结对项目 |
| 目标 | 实现一个自动生成小学四则运算题目的命令行程序 |
团队组成
| 姓名 | 学号 | GitHub |
|---|---|---|
| 于杨 | 3221004940 | GitHub |
PS:另一个队员不是计科12班的同学
Part1 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| Estimate | 估计这个任务需要多少时间 | 25 | 25 |
| Development | 开发 | 100 | 120 |
| Analysis | 需求分析(包括学习新技术) | 30 | 40 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 20 | 10 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 40 | 50 |
| Coding | 具体代码 | 40 | 40 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 40 |
| Reporting | 报告 | 40 | 30 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 15 | 15 |
Part2 效能分析
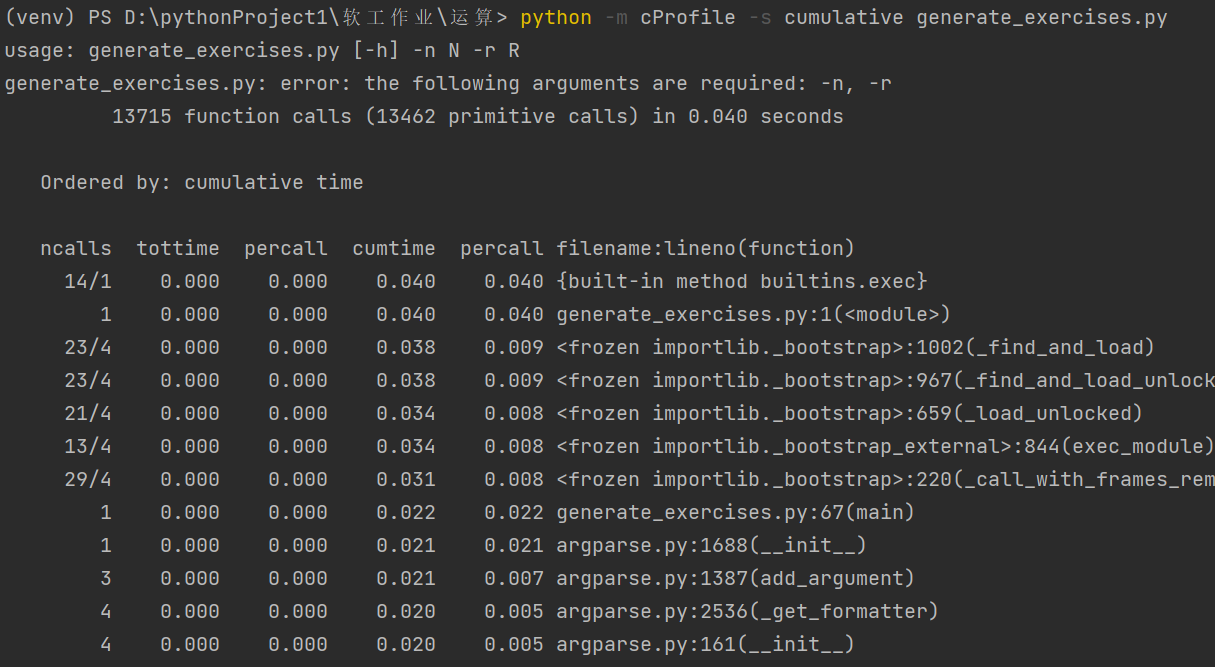
从分析报告结果中我们可以得到:
整个过程一共有13715个函数调用被监控,其中13462个是原生调用(即不涉及递归调用)。总共执行的时间为0.040秒
- ncalls表示函数调用的次数(有两个数值表示有递归调用,总调用次数/原生调用次数)
- tottime是函数内部调用时间(不包括他自己调用的其他函数的时间)
- percall等于 tottime/ncalls
- cumtime累积调用时间,与tottime相反,它包含了自己内部调用函数的时间
- 最后一列,文件名,行号,函数名
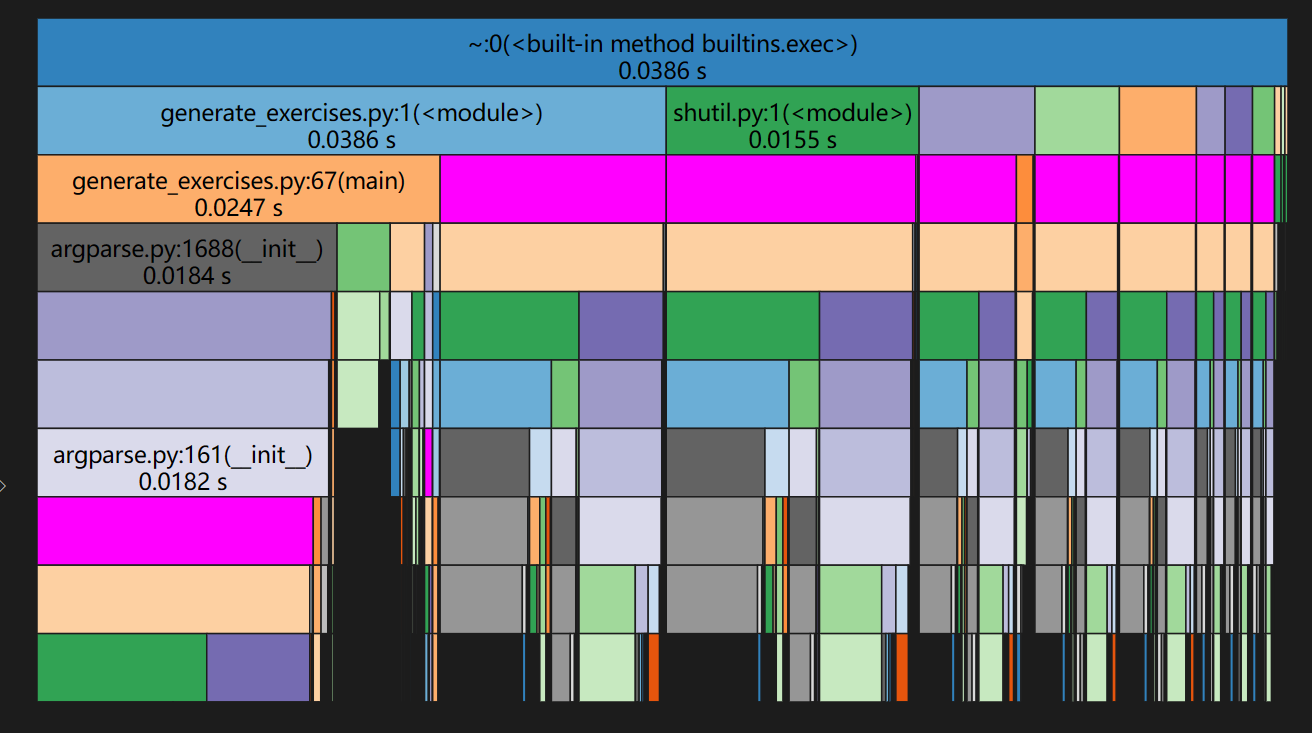
总结:程序生成10道题目的总执行时间仅为0.04s时间较短,效果良好;在其中程序消耗最大的函数是生成关系式的函数,原因是因为只是使用了简单的迭代方式进行,方法的复杂程度太高,没有好的表现效果,占用太多内存
Part3 实现过程
Part4 代码说明
这部分代码实现了表达式的自动生成,使用简单的迭代的方式生成,可以通过修改参数实现对题目难度的调整,也就是调整运算符号的数目。
def generate_expression(min_value, max_value, max_operators):
# 递归生成数学表达式
if max_operators == 0 or (min_value == 1 and max_value == 1):
#如果不需要再添加运算符或者已经达到最小值1直接返回一个随机整数
return str(random.randint(min_value, max_value))
operator = random.choice(operators) #随机选择一个运算符
if operator == '+':
e1 = generate_expression(min_value, max_value, max_operators - 1)
e2 = generate_expression(min_value, max_value, max_operators - 1)
elif operator == '-':
e1 = generate_expression(min_value, max_value, max_operators - 1)
e2 = generate_expression(min_value, max_value, max_operators - 1)
elif operator == '*':
e1 = generate_expression(min_value, max_value, max_operators - 1)
e2 = generate_expression(min_value, max_value, max_operators - 1)
else:
e1 = generate_expression(min_value, max_value, max_operators - 1)
e2 = generate_expression(min_value, max_value, max_operators - 1)
return f"({e1} {operator} {e2})"#返回拼接好的表达式
这部分代码定义一个函数,用于评估表达式,主要是为了避免分母出现0的情况,会是得结果出现逻辑错误。
def evaluate_expression(expression):
try:
# 使用eval函数计算表达式的值,并使用limit_denominator函数将其限制为最简分数
return Fraction(eval(expression)).limit_denominator()
except ZeroDivisionError:
# 避免除以零的错误
return None
这部分代码是使用遍历的方法对答案和正确答案之间进行对比,得到最后结论出现错误的个数和错误的题目。
def check_answers(exercise_file, generated_answer_file, reference_answer_file):
# 读取题目文件和生成的答案文件
with open(exercise_file, 'r') as ex_file, open(generated_answer_file, 'r') as gen_ans_file:
exercises = ex_file.readlines()
generated_answers = gen_ans_file.readlines()
# 读取参考答案文件
with open(reference_answer_file, 'r') as ref_ans_file:
reference_answers = ref_ans_file.readlines()
correct_indices = [] # 存储正确答案的索引
wrong_indices = [] # 存储错误答案的索引
# 遍历题目文件和生成的答案文件,检查是否正确
for i, (exercise, generated_answer) in enumerate(zip(exercises, generated_answers), start=1):
exercise = exercise.strip()
generated_answer = generated_answer.strip()
# 如果参考答案文件的长度小于题目文件,则将参考答案设置为N/A
if i <= len(reference_answers):
reference_answer = reference_answers[i - 1].strip()
else:
reference_answer = "N/A"
# 如果生成的答案和参考答案相同,则将该题的索引添加到正确索引中
if generated_answer == reference_answer:
correct_indices.append(i)
else:
# 如果生成的答案和参考答案不同,则将该题的索引添加到错误索引中
wrong_indices.append(i)
# 返回正确索引和错误索引
return correct_indices, wrong_indices
Part5 测试运行
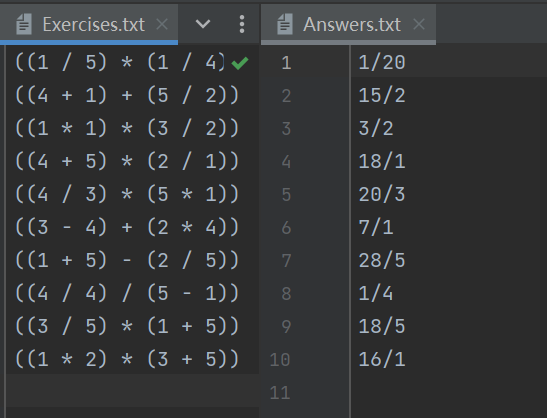
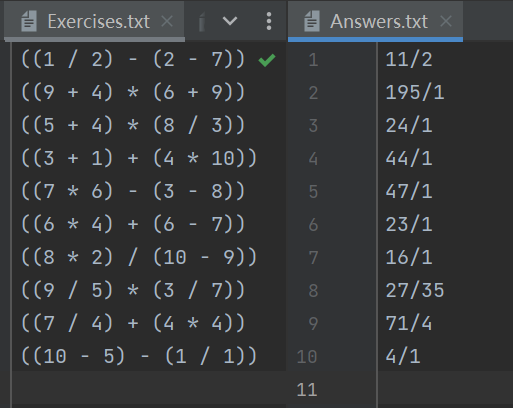
通过上述测试案例可以看出来计算结果正确,但是还含有问题是不能做到将分母上的1去除掉,最后的结果保留了分数形式,还需有再进行优化和调整
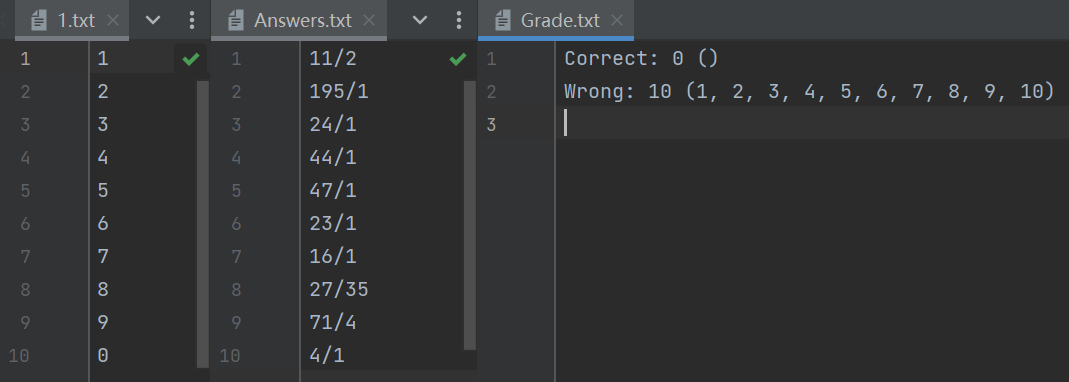
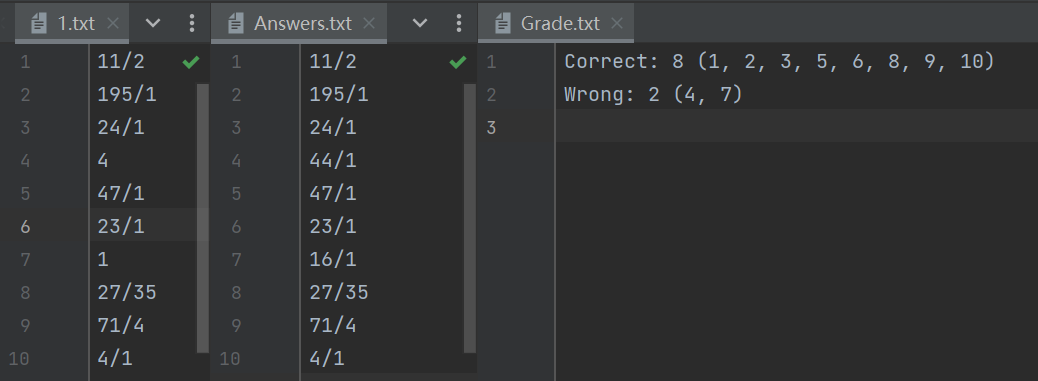
答案检查功能也正常,可以输出错误题目的个数和具体题目,经过检验和比对是正确的。
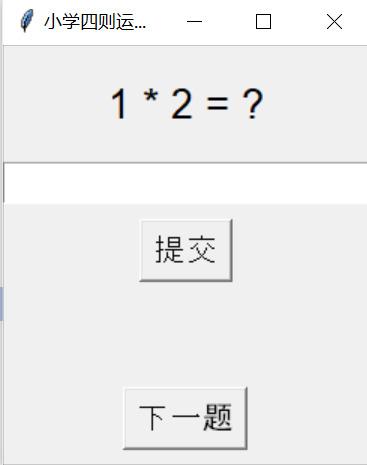
part6 尝试
我们尝试开发可视化界面,是得程序的可用性更强。经过实验后可以实现简洁清晰的界面,但是该尝试还有缺点,该程序在文件的读取和记录方面没有呈现好的表现,后期还可以进行优化。例如:
- 可以选择不同难度类型的题库
- 可以选定本次测试的题目数量和最后输出该次测试的得分
- 建立错题本等等
该程序的优化方向还有很多,可以进一步探索。


Part7 项目小结
合作过程中的优点:
-
明确的分工和责任:我们在项目开始时明确定义了每个人的角色和职责。这有助于避免冲突和混淆,并使我们能够高效地完成任务。
-
良好的沟通:良好的沟通是合作的关键。我们建立了一个开放的沟通渠道,定期讨论进展、问题和解决方案。这有助于保持团队协作的流畅性。
-
相互尊重:我们尊重彼此的观点和意见,充分利用每个人的优势。这鼓励了创新和更好的决策。
取得的成果:
-
项目管理经验:我们学会了规划和管理项目,包括任务分配、时间管理和问题解决。这将有助于我们未来的合作项目。
-
团队协作:我们增强了团队协作和沟通的能力,这对于与他人一起工作至关重要。
-
时间管理:我们发现在合作项目中,合理分配时间非常重要。
结对感受:
结对项目使我们完成项目时更有动力,相互支持和鼓励。当一个人遇到困难时,另一个人总是在身边提供帮助。我们共享了技术经验,相互学习了解决问题的方法。这种知识共享丰富了我们的技能库。通过项目,我们不仅在技术上成长,还在团队协作、沟通和问题解决方面成长。这是一次宝贵的经历。