基于图神经网络的电商购买预测
如何制作自己的图数据
创建一个图,信息如下:
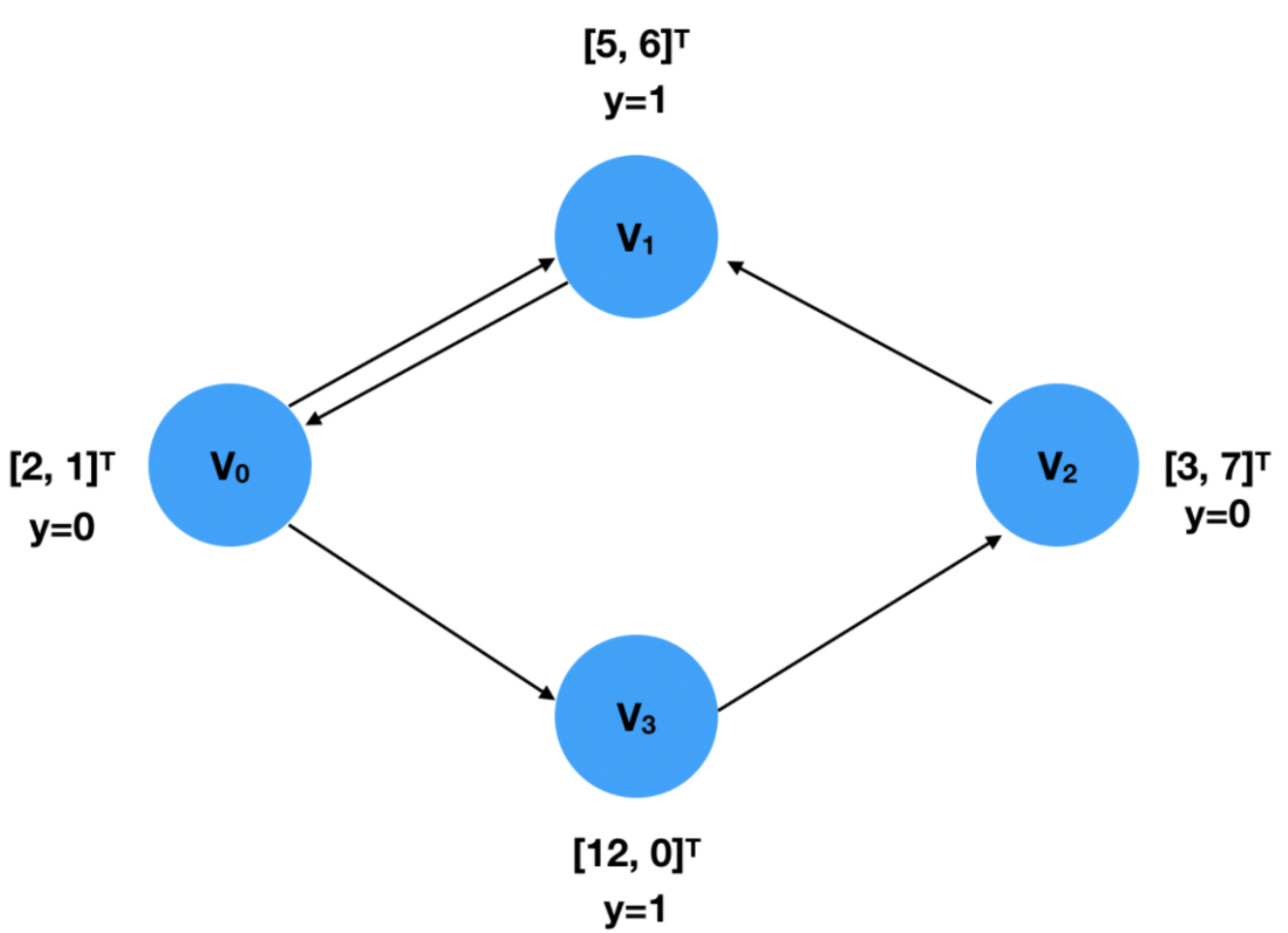
from torch_geometric.data import Data
x = torch.tensor([[2,1], [5,6], [3,7], [12,0]], dtype=torch.float)
y = torch.tensor([0, 1, 0, 1], dtype=torch.float)
edge_index = torch.tensor([[0, 2, 1, 0, 3],
[3, 1, 0, 1, 2]], dtype=torch.long)
data = Data(x=x, y=y, edge_index=edge_index)
yoochoose-clicks:表示用户的浏览行为,其中一个session_id就表示一次登录都浏览了啥东西
item_id就是他所浏览的商品,其中yoochoose-buys描述了他最终是否购会买点啥呢,也就是咱们的标签
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv('yoochoose-clicks.dat', header=None)
df.columns=['session_id','timestamp','item_id','category']
buy_df = pd.read_csv('yoochoose-buys.dat', header=None)
buy_df.columns=['session_id','timestamp','item_id','price','quantity']
item_encoder = LabelEncoder()
df['item_id'] = item_encoder.fit_transform(df.item_id)
df.head()
制作数据集
- 咱们把每一个session_id都当做一个图,每一个图具有多个点和一个标签
- 其中每个图中的点就是其item_id,特征咱们暂且用其id来表示,之后会做embedding
数据集制作流程
- 首先遍历数据中的每一组session_id,目的是将其制作成(from torch_geometric.data import Data)的格式
- 对每一组session_id中的所有item_id进行编码(例如15453, 3651, 15452)就按照数值大小编码成(2, 0, 1)
- 这样编码的目的是制作edge_index,因为在edge_index中需要从0, 1, 2..开始
- 点的特征就由其ID组成,edge_index是这样,因为咱们浏览的过程中是由顺序的比如(0, 0, 2, 1)
- 所以边就是0->0,0->2,2->1这样的,对应的索引就为target_nodes:[0 2 1], source_nodes:[0 0 2]
- 最后转换格式data = Data(x=x, edge_index = edge_index, y = y)
- 最后将数据集保存下来(以后就不用重复处理了)
from torch_geometric.data import InMemoryDataset
from tqdm import tqdm
# 自定义数据集类YooChooseBinaryDataset,用于处理购买预测任务的数据集
# InMemoryDataset类,这是 PyTorch Geometric 中用于处理图数据的基类。
class YooChooseBinaryDataset(InMemoryDataset):
"""
参数说明:
- root:数据集的根目录,通常是数据文件存放的文件夹。
- transform:数据转换函数,用于对数据进行预处理和增强。
在这个代码段中,没有使用自定义的转换函数,所以传入了默认值 None。
- pre_transform:预处理转换函数,通常用于在数据加载之前进行一些预处理操作。同样,这里传入了默认值 None。
"""
def __init__(self, root, transform=None, pre_transform=None):
super(YooChooseBinaryDataset, self).__init__(root, transform, pre_transform) # transform就是数据增强,对每一个数据都执行
# 加载已经处理好的数据集。self.processed_paths 存储了已处理数据的文件路径列表,通常情况下只有一个文件。
# 其中self.data包含了数据对象,self.slices包含了数据对象的切片信息。
self.data, self.slices = torch.load(self.processed_paths[0])
@property # 这是Python中的装饰器,用于定义属性的getter方法。
def raw_file_names(self): # 检查self.raw_dir目录下是否存在raw_file_names()属性方法返回的每个文件
# 如有文件不存在,则调用download()方法执行原始文件下载
return []
# 该方法返回已处理数据文件的文件名列表。
@property
def processed_file_names(self): # 检查self.processed_dir目录下是否存在self.processed_file_names属性方法返回的所有文件,没有就会走process
return ['yoochoose_click_binary_1M_sess.dataset']
def download(self):
pass
# 用于处理原始数据并将其转化为图数据。
def process(self):
# 存储图数据对象
data_list = []
# 根据session_id列将原始数据df分成多个会话组。每个会话代表一个用户的一系列行为。
grouped = df.groupby('session_id')
# session_id存储了当前会话的唯一标识,而group是包含了该会话的所有行的DataFrame。
for session_id, group in tqdm(grouped):
# 这一行代码使用LabelEncoder()对会话中的商品ID(item_id)进行标签编码。
# 标签编码的目的是将原始的商品ID转换为整数形式,以便在图数据中使用。
sess_item_id = LabelEncoder().fit_transform(group.item_id)
# 这里将group DataFrame重新索引并删除之前的索引,以确保行索引从零开始并连续。
group = group.reset_index(drop=True)
# 在DataFrame group中添加了一个新的列'sess_item_id',该列包含了标签编码后的商品ID。
group['sess_item_id'] = sess_item_id
# 这一行代码用于创建节点特征node_features。具体操作包括:
# - 从group DataFrame中选择session_id与当前迭代的绘画相同的行。
# - 选择sess_item_id和item_id这两列数据,并按sess_item_id进行排序
# - 使用drop_duplicates()方法去除重复的item_id值,并将结果转换为一个Numpy数组。
node_features = group.loc[group.session_id == session_id, ['sess_item_id', 'item_id']].sort_values(
'sess_item_id').item_id.drop_duplicates().values
# 将node_features 转换为PyTorch的LongTensor类型,并添加一个额外的维度,以满足图神经网络的输入要求。
node_features = torch.LongTensor(node_features).unsqueeze(1)
# 这两行代码用于创建目标节点和源节点。目标节点是会话中的商品ID('sess_item_id')的后续节点,
# 而源节点是其前一个节点。这是为了构建图数据中的边缘索引。
target_nodes = group.sess_item_id.values[1:]
source_nodes = group.sess_item_id.values[:-1]
# 创建了边缘索引edge_index,其中source_nodes是源节点的列表,target_nodes是目标节点的列表。
# 这一行代码将它们合并为一个包含两行的 PyTorch LongTensor。
edge_index = torch.tensor([source_nodes, target_nodes], dtype=torch.long)
# 将节点特征node_features赋给x,表示图数据中的节点特征。
x = node_features
# 创建了一个包含购买标签的张量y,这里假设每个会话的购买标签是相同的(取第一个商品的标签作为会话的标签)。
y = torch.FloatTensor([group.label.values[0]])
data = Data(x=x, edge_index=edge_index, y=y)
# 将当前会话的图数据对象添加到data_list列表中,以便后续将它们合并成一个大的数据对象。
data_list.append(data)
# 使用pytorch提供的collate方法将图数据对象列表data_list合并成一个数据对象data和一个切片对象slices。
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
dataset = YooChooseBinaryDataset(root='data/')
构建网络模型
embed_dim = 128
from torch_geometric.nn import TopKPooling,SAGEConv
from torch_geometric.nn import global_mean_pool as gap, global_max_pool as gmp
import torch.nn.functional as F
class Net(torch.nn.Module): #针对图进行分类任务
def __init__(self):
super(Net, self).__init__()
# 定义卷积层
self.conv1 = SAGEConv(embed_dim, 128)
# 定义池化层
self.pool1 = TopKPooling(128, ratio=0.8)
self.conv2 = SAGEConv(128, 128)
self.pool2 = TopKPooling(128, ratio=0.8)
self.conv3 = SAGEConv(128, 128)
self.pool3 = TopKPooling(128, ratio=0.8)
# 定义嵌入层
self.item_embedding = torch.nn.Embedding(num_embeddings=df.item_id.max() +10, embedding_dim=embed_dim)
# 定义线性层
self.lin1 = torch.nn.Linear(128, 128)
self.lin2 = torch.nn.Linear(128, 64)
self.lin3 = torch.nn.Linear(64, 1)
# 定义标准化层和激活函数
self.bn1 = torch.nn.BatchNorm1d(128)
self.bn2 = torch.nn.BatchNorm1d(64)
self.act1 = torch.nn.ReLU()
self.act2 = torch.nn.ReLU()
def forward(self, data):
x, edge_index, batch = data.x, data.edge_index, data.batch # x:n*1,其中每个图里点的个数是不同的
#print(x)
# 使用嵌入层将节点特征进行编码。这里的item_embedding是一个嵌入层,用于将节点的特征映射到一个低维空间。
x = self.item_embedding(x)# n*1*128 特征编码后的结果
#print('item_embedding',x.shape)
# 去掉特征的维度为1的维度,使特征具有形状n * 128。
x = x.squeeze(1) # n*128
#print('squeeze',x.shape)
x = F.relu(self.conv1(x, edge_index))# n*128
#print('conv1',x.shape)
x, edge_index, _, batch, _, _ = self.pool1(x, edge_index, None, batch)# pool之后得到 n*0.8个点
#print('self.pool1',x.shape)
#print('self.pool1',edge_index)
#print('self.pool1',batch)
#x1 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
# 全局平均池化
x1 = gap(x, batch)
#print('gmp',gmp(x, batch).shape) # batch*128
#print('cat',x1.shape) # batch*256
x = F.relu(self.conv2(x, edge_index))
#print('conv2',x.shape)
x, edge_index, _, batch, _, _ = self.pool2(x, edge_index, None, batch)
#print('pool2',x.shape)
#print('pool2',edge_index)
#print('pool2',batch)
#x2 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
# 全局特征
x2 = gap(x, batch)
#print('x2',x2.shape)
x = F.relu(self.conv3(x, edge_index))
#print('conv3',x.shape)
x, edge_index, _, batch, _, _ = self.pool3(x, edge_index, None, batch)
#print('pool3',x.shape)
#x3 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
x3 = gap(x, batch)
#print('x3',x3.shape)# batch * 256
# 将三个尺度的全局特征相加,以获取不同尺度的全局信息。
x = x1 + x2 + x3 # 获取不同尺度的全局特征
x = self.lin1(x)
#print('lin1',x.shape)
x = self.act1(x)
x = self.lin2(x)
#print('lin2',x.shape)
x = self.act2(x)
x = F.dropout(x, p=0.5, training=self.training)
# 最后一层使用了Sigmoid激活函数,将模型的输出压缩到0到1之间,用于进行二元分类。
# .squeeze(1)操作将结果的维度从(batch_size, 1)变为(batch_size,)。
x = torch.sigmoid(self.lin3(x)).squeeze(1)#batch个结果
#print('sigmoid',x.shape)
return x
from torch_geometric.loader import DataLoader
def train():
model.train()
loss_all = 0
for data in train_loader:
data = data
#print('data',data)
optimizer.zero_grad()
output = model(data)
label = data.y
loss = crit(output, label)
loss.backward()
loss_all += data.num_graphs * loss.item()
optimizer.step()
return loss_all / len(dataset)
model = Net()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
crit = torch.nn.BCELoss()
train_loader = DataLoader(dataset, batch_size=64)
for epoch in range(10):
print('epoch:',epoch)
loss = train()
print(loss)
from sklearn.metrics import roc_auc_score
def evalute(loader,model):
model.eval()
prediction = []
labels = []
with torch.no_grad():
for data in loader:
data = data#.to(device)
pred = model(data)#.detach().cpu().numpy()
label = data.y#.detach().cpu().numpy()
prediction.append(pred)
labels.append(label)
prediction = np.hstack(prediction)
labels = np.hstack(labels)
return roc_auc_score(labels,prediction)
for epoch in range(1):
roc_auc_score = evalute(dataset,model)
print('roc_auc_score',roc_auc_score)
TopKPooling流程
- 其实就是对图进行剪枝操作,选择分低的节点剔除掉,然后再重新组合成一个新的图


Top-K Pooling 是一种图神经网络中的池化操作,具体解释如下:
假设我们有一个图,图中的每个节点都有一个分数,分数代表节点的重要性或者说贡献度。Top-K Pooling 的目标是从图中选择最重要的 K 个节点,保留它们,丢弃其他节点。
具体计算方法如下:
- 计算节点分数: 首先,对图中的每个节点计算一个分数。这个分数通常是通过某种方式从节点的特征或权重中得出的。分数越高,表示节点越重要。
- 排序: 将所有节点按照分数从高到低进行排序,分数最高的排在前面,最低的排在后面。
- 选择Top-K: 从排序后的节点列表中选择前 K 个节点,这些节点是分数最高的节点。
- 保留节点: 将选中的这 K 个节点保留下来,丢弃其他节点。这样,我们就得到了一个新的图,其中只包含 K 个最重要的节点。
Top-K Pooling 的核心思想就是通过分数来衡量节点的重要性,并根据这些分数选择保留的节点。这个操作通常用于图神经网络中,以减少图的规模,提取关键信息,或者将图转化为固定大小的输出。不同的应用场景可以选择不同的 K 值,以满足任务需求。
计算节点分数的方法
计算节点分数通常是根据具体的任务和需求来确定的,有多种方法可以计算节点的分数。以下是一些常见的计算节点分数的方法:
- 节点特征加权: 在许多情况下,节点的分数可以直接从其特征中得出。每个节点的特征向量通常包含有关该节点的信息,例如节点的属性、邻居节点的信息等。可以通过将节点特征进行加权和组合来计算节点的分数。例如,可以使用线性加权或非线性函数(如神经网络层)来计算节点的分数。
- 邻居节点的聚合: 节点的分数可以通过聚合其邻居节点的信息来计算。一种常见的方法是使用图卷积神经网络(GCN)或图注意力网络(GAT)等技术来聚合邻居节点的特征,并将聚合后的结果作为节点的分数。
- 图结构特征: 节点的分数还可以依赖于图的拓扑结构。例如,节点的度(即与其相邻的节点数量)可以用作节点分数的一部分,度较高的节点可能被认为更重要。
- 自定义规则: 根据特定任务和领域知识,可以定义自己的节点分数计算规则。这些规则可以基于问题的特点来确定,例如社交网络中的节点的活跃度,或者推荐系统中的用户历史行为等。
总的来说,计算节点分数的方法取决于具体的任务和数据特点。在设计图神经网络模型时,研究人员需要根据问题需求选择适当的节点分数计算策略,以确保模型能够提取和利用有用的信息来完成任务。
【补充】
Embedding
在机器学习中,Embedding(嵌入) 是一种将高维离散数据映射到低维连续向量空间的技术。它通常用于处理具有大量类别或标签的离散数据,例如自然语言中的单词、商品的类别、用户的ID等。Embedding 的目标是将离散的符号信息转化为连续的向量表示,以便计算机能够更好地理解和处理这些数据。
1. 离散数据表示问题: 许多机器学习任务中,需要处理离散的数据,例如文本分类任务中的单词、推荐系统中的物品ID等。这些数据通常以离散的整数或类别形式存在,不方便直接输入到机器学习模型中。
2.Embedding的作用:Embedding技术允许我们将离散数据映射到低维的连续向量空间中,其中每个离散数据对应一个唯一的向量表示。这些向量在连续空间中的位置和相对距离包含了数据之间的语义信息,使得模型能够更好的理解数据的关系和特征。
3. 词嵌入的示例: 最典型的应用是自然语言处理中的词嵌入(Word Embedding)。在词嵌入中,每个单词被映射到一个连续向量空间,使得具有相似语义的单词在向量空间中彼此接近。例如,"king" 和 "queen" 的词嵌入向量在向量空间中会非常接近,因为它们有相似的语义。
4. 学习过程: Embedding 向量通常是通过训练数据来学习的。在训练过程中,模型会尝试调整嵌入向量的参数,使得模型在特定任务上的性能最优。这意味着模型会自动学习如何表示数据,而无需手动设计特征。
5. 应用领域: Embedding 不仅用于自然语言处理,还用于推荐系统、图数据分析、社交网络分析等领域。它们有助于改进模型性能,提高模型对数据的理解能力,以及降低模型的维度和计算复杂性。
总的来说,Embedding 技术是机器学习中非常重要的工具,它允许模型更好地处理离散数据,提取数据的语义信息,从而改进各种任务的性能。
SAGEConv
"SAGEConv" 是一种图神经网络(Graph Neural Network,简称GNN)中的卷积层,用于处理图数据。SAGE 代表 "GraphSAGE",这是一种常用的图神经网络模型。
图数据是一种不规则的数据,通常表示为节点和它们之间的连接关系。图神经网络的目标是对这种图数据进行学习和预测,例如节点分类或链接预测。
"SAGEConv" 的全名是 "GraphSAGE Convolution",它是 GraphSAGE 模型中的卷积层,用于学习节点的表示。在图数据中,每个节点都有一些邻居节点,它们与当前节点有连接。SAGEConv 通过聚合邻居节点的信息来更新当前节点的表示。
具体来说,SAGEConv 会计算当前节点的邻居节点的表示,然后将这些表示进行聚合。这个聚合过程可以是平均池化、最大池化或其他方法,取决于具体的设置。最后,更新后的节点表示将用于后续任务,如节点分类。
SAGEConv 是图神经网络中的一种卷积层,类似于传统卷积神经网络中的卷积层,但是它是专门为处理图数据而设计的。通过不断堆叠多个 SAGEConv 层,可以构建更复杂的图神经网络模型,用于各种图数据相关的任务。
总之,SAGEConv 是图神经网络中的一个关键组件,用于在图数据上进行信息传播和学习节点表示。它有助于理解和处理复杂的图结构数据。
节点特征
在图论和图神经网络中,节点特征(Node Features)指的是图中每个节点所携带的信息或属性。这些信息可以是各种类型的数据,比如文本、数值、图像等,用来描述节点的特点或特征。节点特征对于图神经网络中的节点分类、链接预测、图分类等任务非常重要。
节点特征的示例:
- 在社交网络中,节点特征可以是用户的个人信息,如性别、年龄、兴趣爱好等。
- 在推荐系统中,节点特征可以表示商品的属性,如价格、类别、销售量等。
- 在生物信息学中,节点特征可以包括蛋白质的结构信息、基因的表达水平等。
节点特征在图神经网络中用来进行信息传递和节点状态更新。这些特征通常表示为向量或矩阵的形式,以便计算机能够处理和学习它们。在图卷积神经网络(GCN)等模型中,节点特征的传播和聚合是整个图神经网络的核心操作,用于学习节点之间的关系和图的全局结构。