基于Transformer的遥感影像目标检测研究
1. 研究课题三要素
1.1 研究对象
遥感影像。
1.2 研究问题
目标检测任务指的是为每个感兴趣的对象预测一组边界框和类别标签。与自然场景下的通用目标检测不同,遥感影像存在一些自身的特点,例如遥感图像幅面大、成像视角单一、可提取的特征较少;目标数量庞大、种类繁多、背景复杂,往往是自然图像的数十到上百倍,计算量相当庞大;对遥感影像的标注需要耗费大量的人力资源,尤其是大量的精细化标注几乎是不可能实现的,因此可供模型训练的数据不足也是很大的一个问题。
传统的遥感影像目标检测方法往往难以应对复杂场景和多样化目标特征,其中包括但不限于光照变化、遮挡、不同视角和目标尺度等问题,这些困难和挑战限制了目标检测方法在实际应用中的效率和精度,降低了其在高度动态和多变的现实世界场景中的适用性。
现有的目标检测研究往往倾向于设计或改进已有的模型结构,使其能够适应不同场景,满足不同数据特征的变化。遥感影像目标检测课题中具有挑战性的任务主要包括任意朝向目标的检测、弱小目标的检测、细粒度型号识别、弱监督条件下的检测、实时高效的检测等。
1.3 研究方法
卷积神经网络(CNN)一直是计算机视觉任务中模块,以往的目标检测大多是建立在CNN的基础上的[1-11]。自从Transformer[12]被应用于自然语言处理(NLP)领域以来,他所使用的自注意力(self-attention)机制便受到了学术界的广泛关注,例如最近的GPT[13],BERT[14]等模型都是受到了这一机制的启发而提出的。
近几年来,在计算机视觉领域应用注意力机制的研究发展也十分迅猛,使用注意力机制替换原来流行的CNN结构,能学习到丰富的关联特征信息,获得全局的相关特征,再通过增强检测头或特征融合模块,这一类模型在分类、检测、分割等多个任务上的性能已经超过了传统的基于卷积的神经网络[21]。
本文主要调研基于Transformer的目标检测模型,这些研究在检测模型中引入自注意力机制,针对遥感影像的特点改进了模型结构,因此在应对复杂场景和多样化目标特征时能够表现出更高的检测性能和鲁棒性。
2. 研究背景和意义
为了建立全球天空地一体化立体对地观测网,我国正在全面推进高分辨率对地观测系统重大专项,这将成为保障国家安全的基础性和战略性资源。未来10年,全球每天获取的观测数据将超过10PB,这预示着遥感大数据时代已然来临。随着卫星系统越来越广泛的应用,遥感影像也不断深入地在矿产勘探、精准农业、城市规划、林业测量、军事目标检测和灾害评估等领域中发挥作用。
最近几年内,随着遥感影像空间分辨率的提高和人工智能技术的发展,遥感影像自动地物检测任务上的研究取得了卓越的成果。起初的深度卷积网络采用“端对端”的特征学习,通过多层处理机制揭示隐藏于数据中的深层次特征。与传统的目标检测方法不同,基于神经网络的方法能够通过大量的计算和大规模的训练数据集,自动学习到全局特征,而不是人工设计的浅层次特征,这是其在遥感影像目标检测中取得成功的重要原因。这一成功促使深度学习技术的不断发展,当前以Transformer结构为基础的检测模型迅速崭露头角,在许多应用场景下甚至超过了原有的以CNN为主的检测模型。
3. 课题研究现状
3.1 基于 CNN 的目标检测
在R-CNN提出之前,一般采用基于滑动窗口和人工特征提取的方法完成目标检测任务,由于无法捕获数据更深层次的特征,这些方法难以达到较高的精度。
随着深度学习技术的发展,现在流行的目标检测方法大致可以分为一阶段检测(One-Stage)与二阶段检测(Two-Stage),如图 2所示。Two-Stage方法先进行区域生成,即生成候选区域(Region Proposal),在通过卷积神经网络预测候选框的类别,代表性的算法包括R-CNN[1],Fast R-CNN[2],Faster R-CNN[3],SPP-Net[4];One-Stage方法则直接根据CNN提取出的特征预测目标的分类与定位,例如YOLO系列算法[5-10],SSD[11]等。One-Stage方法中没有显示生成Region Proposal的步骤,因此计算速度更快,能满足移动端的使用需求,但是检测精度不如Two-Stage方法。
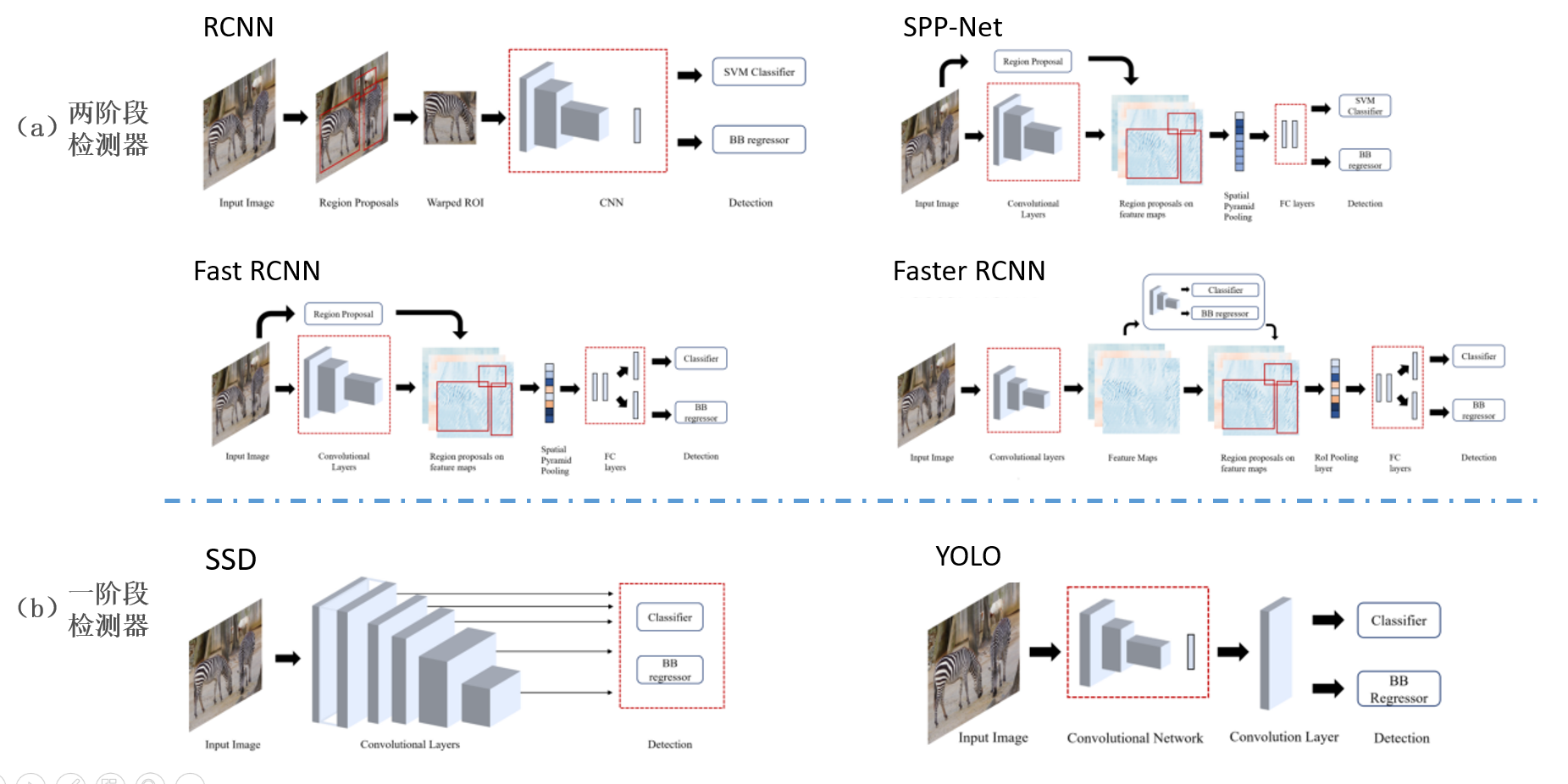
图 2 单阶段和两阶段检测器的模型结构
现有的遥感目标检测方法通常在通用目标检测的范式上加以改进,在数据处理方面,将大幅的遥感图像切分成小幅的图像,再针对特定任务场景调整模型结构,例如基于光学影像的模型[15-17],基于合成孔径雷达(SAR)的模型[18],基于红外影像的模型[19]。目前基于CNN的模型已经能够达到相当高的检测精度,进一步的研究方向主要是设计模型结构提高有挑战性的目标(如小目标、遮挡目标或细粒度检测)的精度,通过减少模型参数实现实时高效的检测,通过弱监督学习减小训练集规模等。
3.2 基于 Transformer 的目标检测
以往的目标检测模型大多是基于CNN的[1-11],但是CNN有一些固有的缺点,如缺乏捕获全局上下文信息的能力,固定的训练后权重等。应用于视觉任务中的注意力机制可以看作是一种加权求和算法,通过赋予空间中的不同通道或者区域以不同的权重,保证模型能够对特定的区域进行高分辨率处理,将注意力集中在图片中特定的部分,不是处理全部图像,从而有针对性地选择相应位置处理,提取图像中的关键信息同时忽略无关信息,这样做还能保证网络层数不会过深,解决了梯度爆炸的问题,使整个模型的性能得到了提高[21]。
在提出第一个基于Transformer的端到端检测模型DEtection TRansformer(DETR)之后[23],人们意识到使用注意力机制的模型可以学习全局特征,于是改进了DETR,使其能应用于多个特定任务,得到超越传统基于CNN的模型的检测精度,包括加速训练[24]、减少冗余计算[25]、小目标检测[26]、旋转目标检测[27]等。
近年来,由于注意力机制的优越性,在遥感领域,基于Transformer的目标检测方法受到了越来越广泛的关注,该领域的研究成果也迅速涌现,包括用于旋转目标检测的Ao2-detr[27]、O2DETR[28] ,用于小目标检测的LPSW[29] 、 SPH-YOLOv5[31],用于细粒度型号识别的SFRNet[30]。
4. 课题研究内容概要
4.1 DEtection TRansformer(DETR)[23]
论文信息:
DETR是Facebook提出的基于Transformer的端到端目标检测网络,发表于ECCV2020[23]。
Transformer:
在计算机视觉方向上,Transformer主要用于捕捉图像上的感受野,如图所示,Transformer成功的关键是使用了注意力机制,在本质上是一个编码器-解码器(Encoder-Decoder)的结构,Encoder和Decoder均是一种Self-Attention模块的多重叠加[12]。
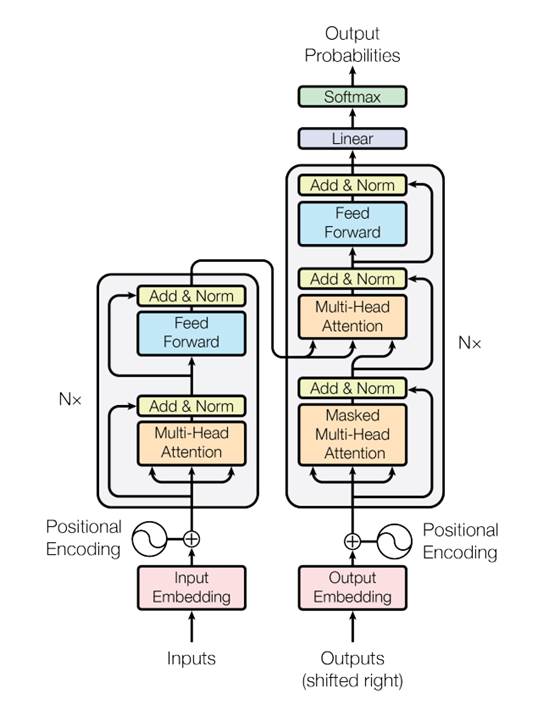
Transformer模型结构
摘要:
通过将目标检测看作是一个直接的集合预测问题,论文将Transform引入到了端到端的目标检测模型中。该方法简化了pipeline,移除了需要手工设计的模块,比如非最大抑制(NMS)或显式生成锚点。DETR的主要组成部分是一个基于集合的全局损失,它通过二部图匹配得到唯一的预测,以及一个Transform的encoder-decoder结构。
方法:
如下图所示,DETR使用传统的CNN来学习输入图像的2D表示。在将其传递到transformer编码器之前,模型改变其维度将它压平,并加入位置编码。然后,transformer解码器将固定数量的学习位置嵌入作为输入(object queries),并额外处理编码器输出。将解码器的每个输出嵌入传递给一个共享的前馈网络(FFN),该网络预测一个检测对象(类别和检测框)或一个“no object”。
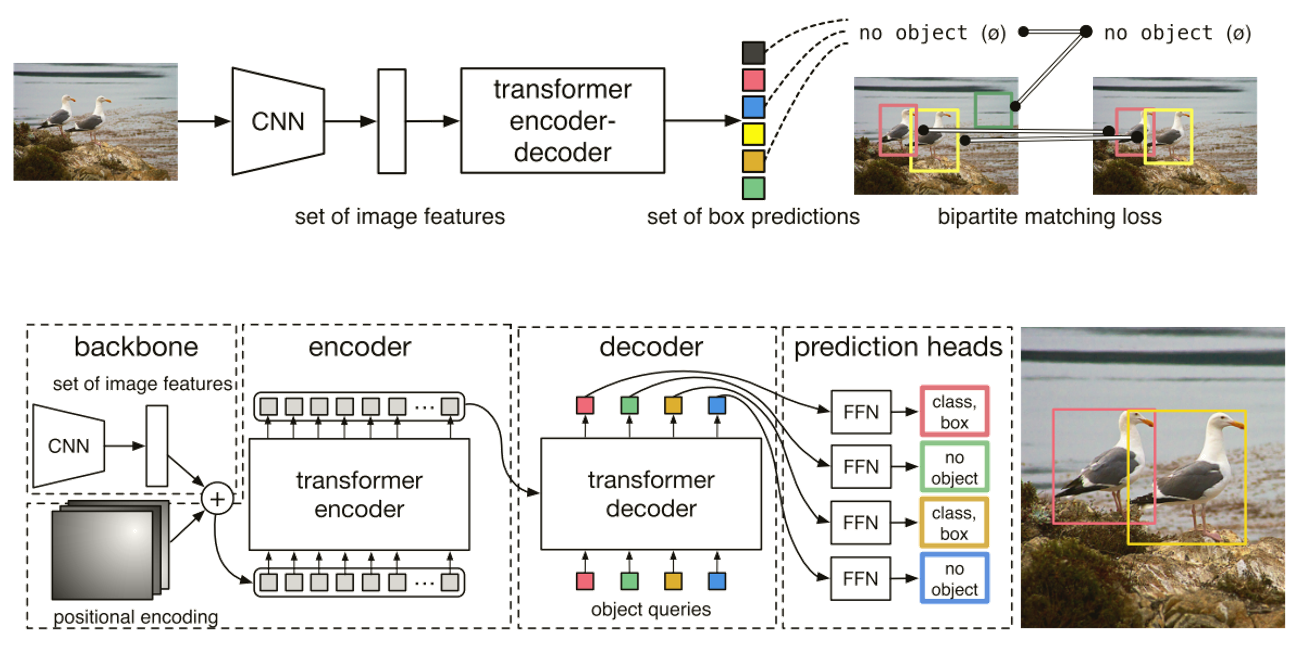
DETR模型框架
实验:
\1. 与Faster R-CNN相比,DETR在COCO数据集上取得了相当的结果。
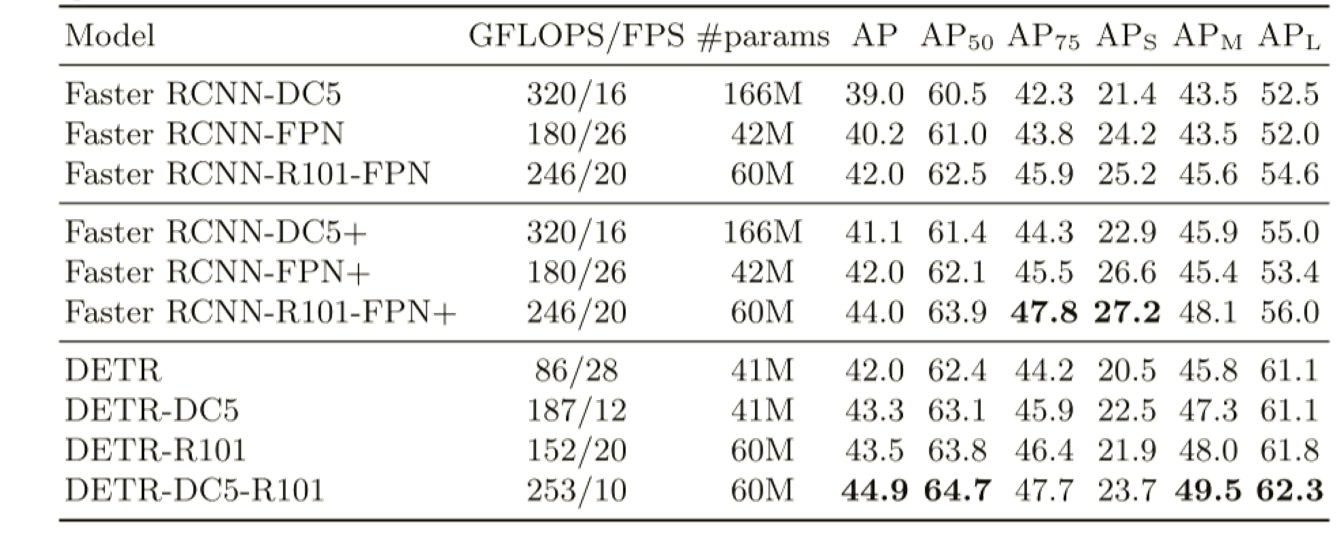
\2. 通过消融实验得出结论:transforme组件: 编码器中的全局自注意、FFN、多解码器层和 位置编码,都对最终的目标检测性能有显著的贡献。
可视化解码器对每一个预测对象的注意力如图所示,对于不同的物体,用不同的颜色表示注意力分数。解码器可以处理对象的四肢和头部。

\3. 与扩展Faster R-CNN到Mask R-CNN类似,通过在解码器输出的顶部添加一个mask head,将DETR扩展到全景分割任务上。与UPSNet 和 Panoptic FPN 对比结果如表。

结论:
本文提出了一种基于Transformer和bipartite matching loss的直接集合预测的目标检测方法,不再需要NMS和anchor。该方法在COCO数据集上取得了与优化的Faster R-CNN相媲美的结果。它在较大对象上的性能明显优于Faster R-CNN,作者认为这可能是由于自注意力能够处理全局信息。此外,DETR流程简单,并且易于扩展到全景分割,得到具有竞争力的结果。
未来的工作可以针对小目标检测、训练优化和性能提升等问题来展开。
4.2 O2DETR[28]
论文信息:
Oriented Object Detection with Transformer(O2DETR),作者单位:布法罗大学, 北航, 百度,发表于2021年。[28]
摘要:
本文是第一个将Transformer应用于旋转目标检测的工作,主要贡献包括:
\1. 为旋转目标检测提供了新的见解,应用Transformer直接地有效地完成定位,而不是像传统检测器那样使用旋转锚;
\2. 设计了一种简单高效的编码器,用深度可分离卷积代替了注意力机制,大大降低了原始Transformer中使用多尺度特征的内存和计算成本;
\3. O2DETR 可以成为旋转目标检测领域的一个新基准,它比 Faster R-CNN 和 RetinaNet 实现了高达 3.85 mAP 的改进。
主要研究问题:
目前在旋转框目标检测任务上,基于不带角度旋转的anchors回归存在很多问题(主要由于在航空DOTA数据集上旋转框尺度小,带有角度倾斜,并且很密集),使用预设旋转anchors的方法在旋转框的回归以及使用NMS的后处理上计算很复杂。
方法:
在Transformer的编码器端,利用深度可分离卷积代替了注意力机制。利用O2DETR较高的召回率来微调,以获得更好的性能。
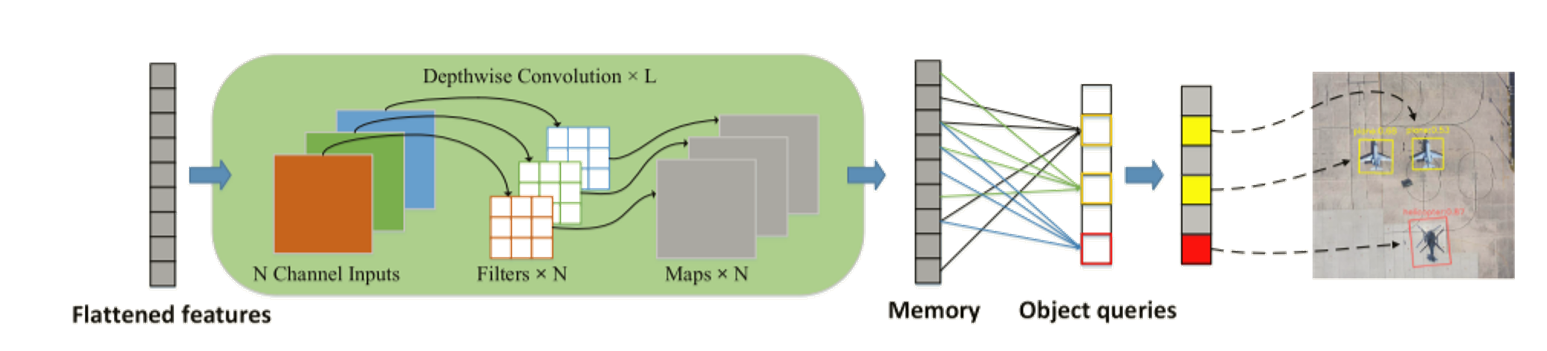
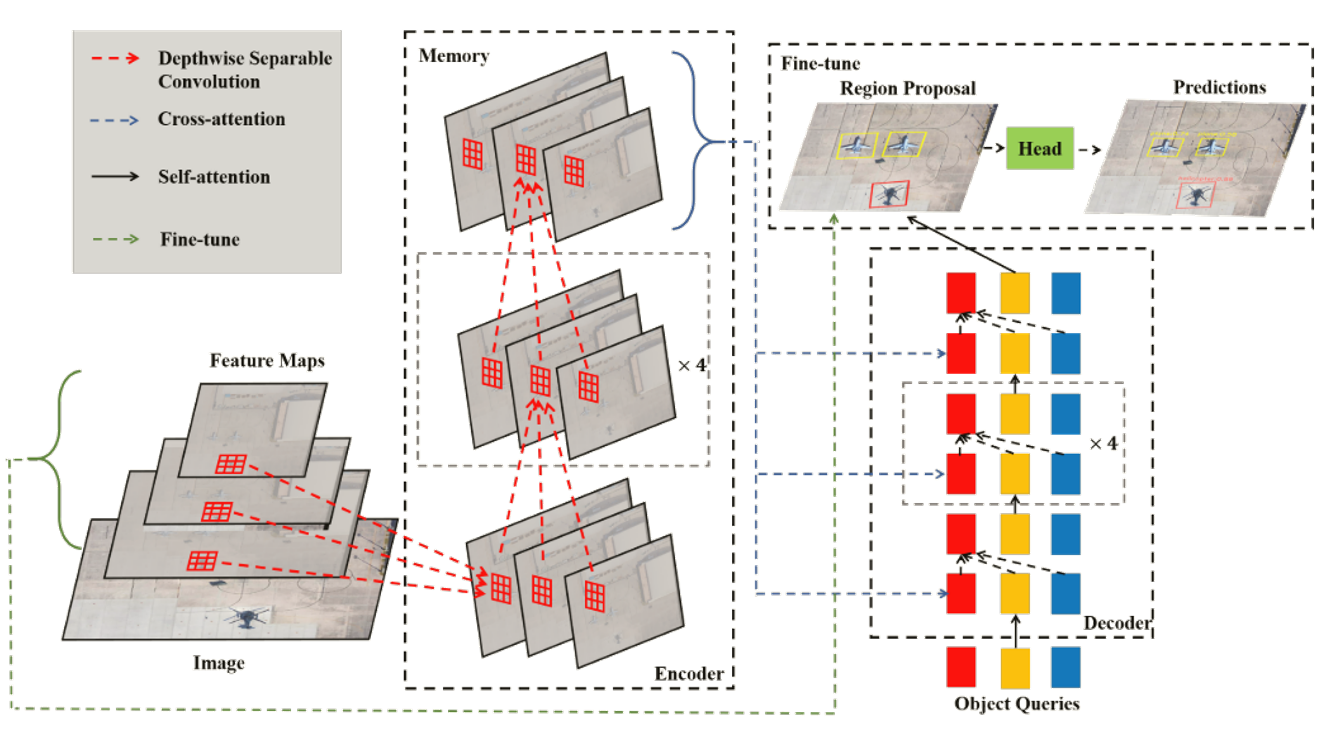
实验:
在DOTA数据集上开展实验。
\1. 同Faster-RCNN以及RetinaNet的比较

\2. 深度可分离卷积和注意力机制的比较。结果证明,尽管注意机制在整个图像中使用了全局场景推理,但在密集、微小的物体中,围绕物体进行局部场景推理就足够了,甚至更好,而深度可分离卷积能更好地处理局部聚集的情况。
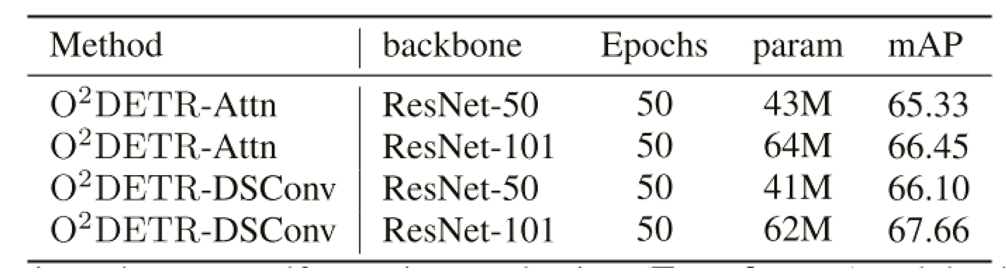
结论:
O2DETR在DOTA数据集上取得了优于原始Faster R-CNN和RetinaNet的检测结果,并且本文通过对O2DETR进行微调,实现与其他模型相比具有竞争力的性能。
4.3 Arbitrary-Oriented Object DEtection TRansformer(AO2-DETR)[27]
论文信息:
AO2-DETR是基于transformer(DETR)的旋转目标检测模型,发表于IEEE TCSVT 2023[27]。
摘要:
任意面向目标检测(AOOD)是一项具有挑战性的任务,它可以检测任意方向的杂乱排列的目标。本文提出了AO2-DETR,它包括三个组件:旋转候选框生成机制(oriented proposal generation mechanism)、自适应的旋转候选框细化模块(adaptive oriented proposal refinement module)、旋转感知集合匹配损失(rotation-aware set matching loss)。该方法作为一个新的AOOD范例,大大简化了整个pipeline,在多个具有挑战性的数据集上的综合实验取得了较好的性能。
主要研究问题:
与自然图像中的一般目标检测不同,旋转对象的目标检测主要的困难包括:任意方向的密集的分布 或 高度复杂的背景。
主要贡献:
\1. 提出了一种基于transformer的旋转目标检测器AO2-DETR,它不需要锚点和复杂的预处理/后处理。
\2. 设计了一种旋转候选框生成(OPG)方法,该方法引导网络生成具有方向信息的旋转候选框,可以有效地解决错位问题,并为融合特征提供更好的位置先验,从而调节交叉注意力。
\3. 引入了一种新的自适应的旋转候选框细化(OPR)模块。OPR模块通过一个特征对齐模块和更大的接受域,根据学习到的上下文信息动态调整旋转候选框,可以显著缩小旋转候选框与ground-truth之间的差距。此外,在一对一匹配过程中增加了一个旋转感知集合匹配损失,以确保预测框和真实结果之间的正确匹配。
\4. 在四个公开数据集DOTA-v1.0、DOTA-v1.5、SKU110K-R和HRSC2016上进行了大量实验,验证了模型的有效性。在这四个数据集上,AO2-DETR在无锚和单阶段方法中实现了最先进的性能。
方法:
OPG负责生成旋转候选框作为object queries,为池化特征提供了更好的位置先验;OPR模块,根据学习到的上下文信息自适应地调整旋转框;旋转感知的几何匹配损耗保证AO2-DETR中一对一的匹配过程。前馈网络(FFN)预测一个检测对象(类别和检测框)或一个“no object”。
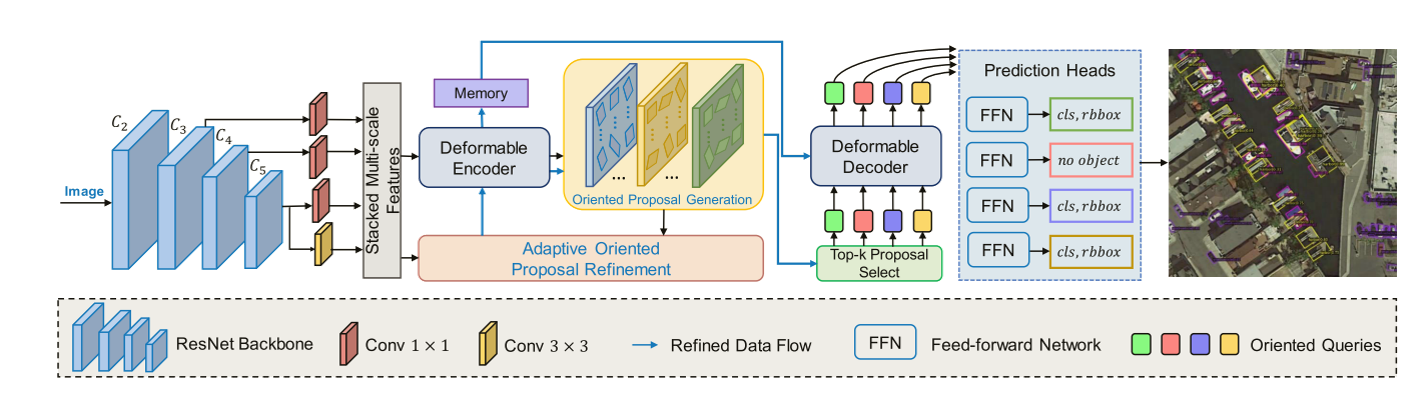
实验:
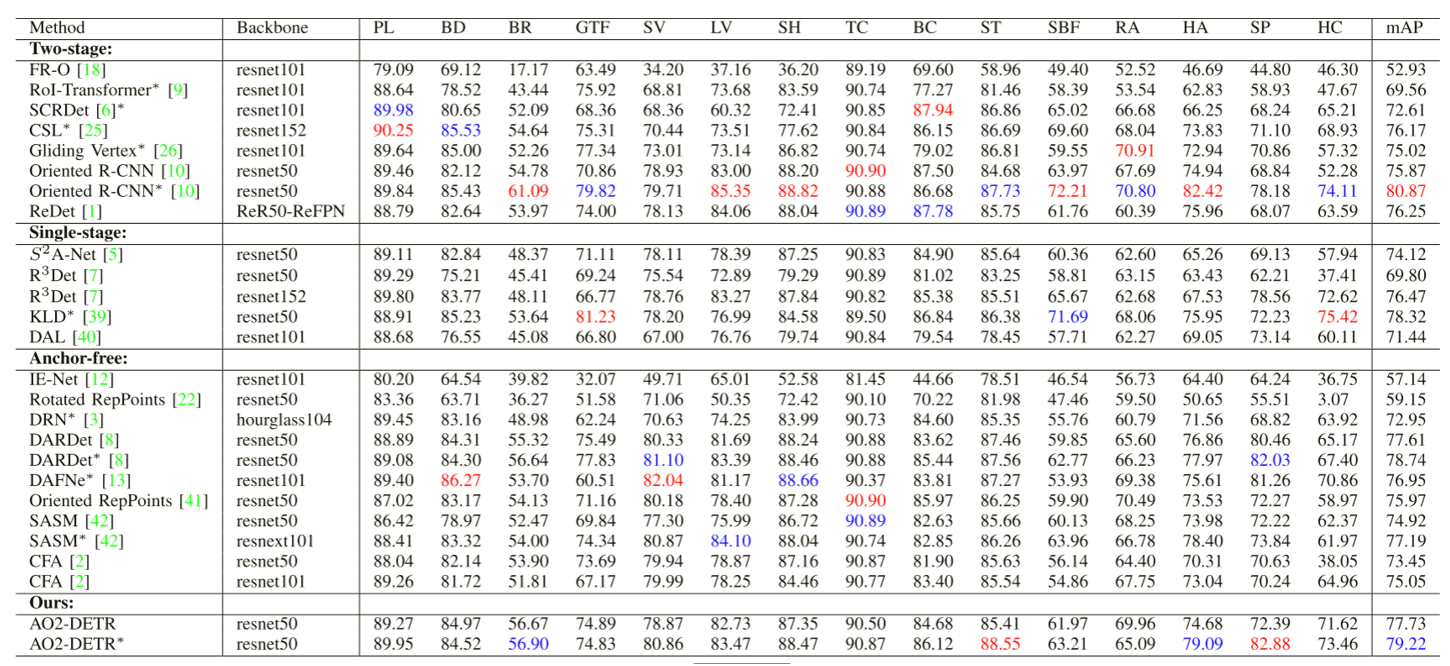
\1. 与最先进方法的比较
DOTA-v1.0(用红色和蓝色表示的结果分别是最好和次最好的结果)
DOTA-v1.5

SKU110K-R
HRSC2016( 表示VOC 2012评价指标,其他的是在VOC 2007评价指标下进行评估。†表示以resnet50为骨干重新实现。)
表示VOC 2012评价指标,其他的是在VOC 2007评价指标下进行评估。†表示以resnet50为骨干重新实现。)

\2. 消融实验:旋转候选框生成(Oriented Proposal Generation Mechanism OPG)、自适应旋转框细化(Adaptive Oriented Proposal Refinement Module)、迭代边界框优化(iterative bounding box refinement IBR)、旋转感知集合匹配损失(rotation-aware set matching loss RAL)。

结论:
本文提出了OPG、OPR、RAL三个组件,用编码器-解码器的结构将旋转候选框(作为对象查询)转换为每个对应的目标,不再需要手工设计组件和复杂的预处理/后处理。但是,模型训练收敛时间较长,基于transformer的方法要求较高的计算量。
4.4 local perception Swin transformer (LPSW)[29]
论文信息:
An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation是西安电子科技大学的成果,发表于remote sensing 2021[29]。
摘要:
应用于遥感目标检测(和实例分割)的Transformer仍然存在小目标检测能力差、边缘细节分割效果差等问题。为了解决这些问题,本文利用Transformer和CNN的优点对Swin transformer进行了改进,设计了局部感知Swin transformer(LPSW)主干网,增强了网络的局部感知能力,提高了小尺度目标的检测精度。另外,还设计了空间注意交错执行级联(SAIEC)网络框架,增强了网络的分割精度,创建了MRS-1800遥感掩码数据集。
主要贡献:
\1. 为了克服CNN全局信息提取能力差的缺点,选择Swin transformer作为骨干网络,建立遥感图像目标检测和实例分割的模型。
\2. 针对遥感图像的特点,提出了一种基于局部感知的transformer (LPSW),LPSW结合了CNN和transformer的优点,增强了局部感知能力,提高了小尺度目标的检测精度。
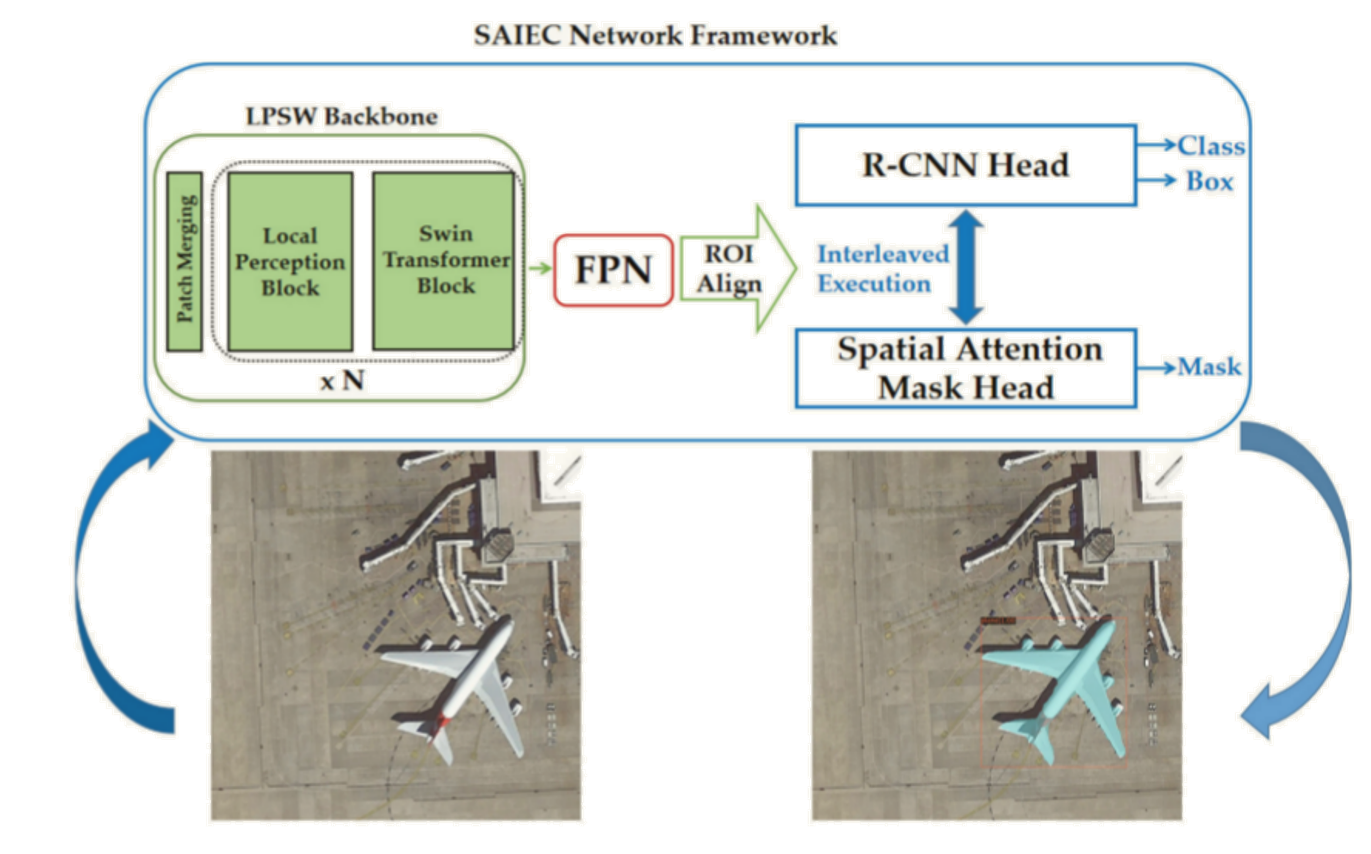
\3. 提出了空间注意交错执行级联(spatial attention interleaved execution cascade SAIEC)网络框架。通过多任务处理方式和改进的空间注意力模块提高了网络的掩膜感知能力。最后,在网络框架中插入LPSW作为骨干,建立新的模型,进一步提高了检测和分割的准确性。
\4. 从现有公共数据集中选取共1800幅多目标类型的图像进行标注,创建MRS-1800遥感掩模数据集作为本文的实验资源。
方法:
模型将输入图像输入到LPSW骨干网络,生成feature map后,发送给FPN结构后的SAIEC网络模型。模型的后端执行feature map分类、边界框回归和实例分割任务。每个边界框被划分为对象区域和非对象区域。
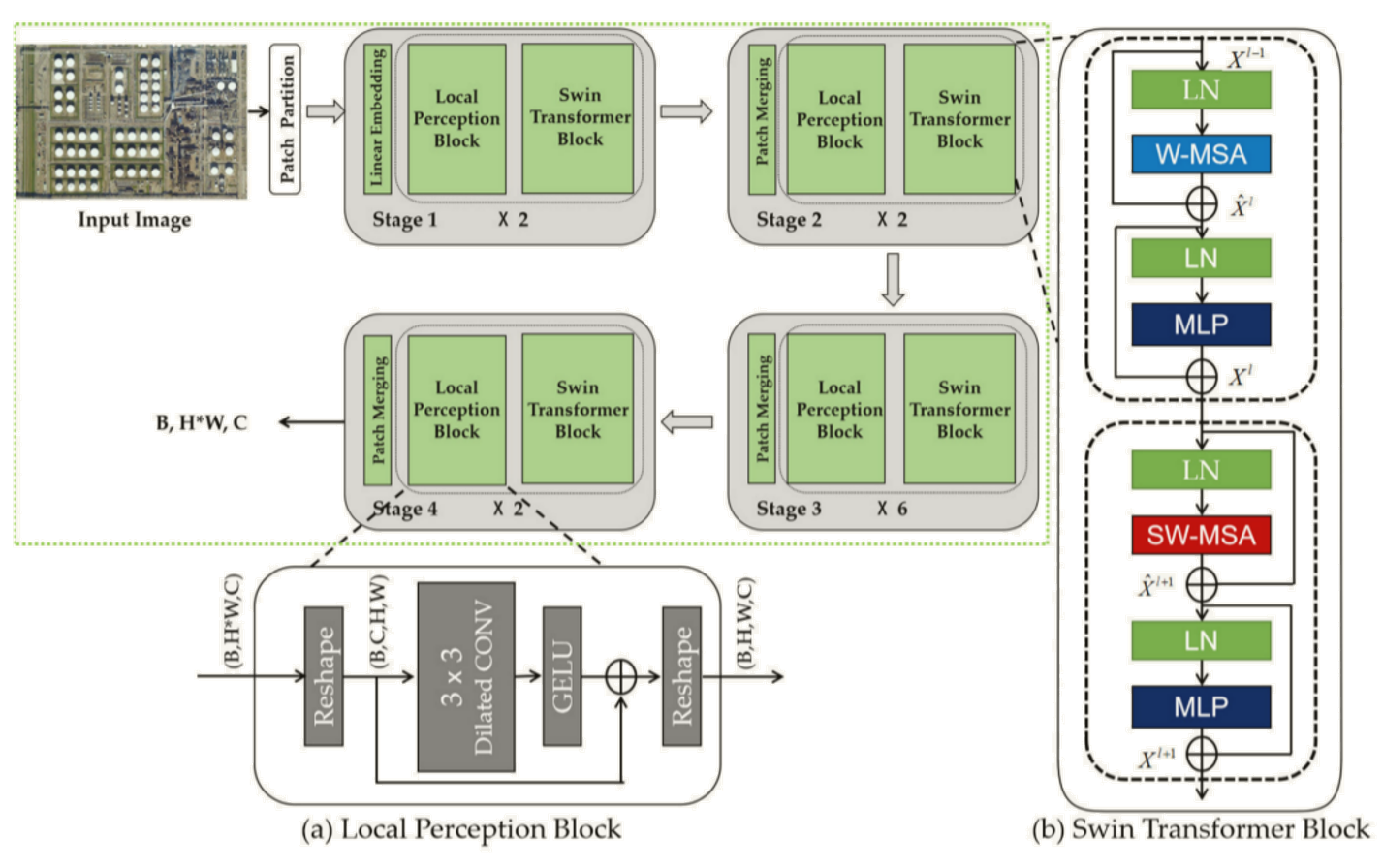
LPSW的结构如下图,(a)局部感知模块;(b) Swin transformer模块。
Swin transformer模块是Swin transformer算法的核心部分,但是不能很好地编码大范围的空间上下文信息,因此局部感知模块被加入到了Swin transformer模块的前面。
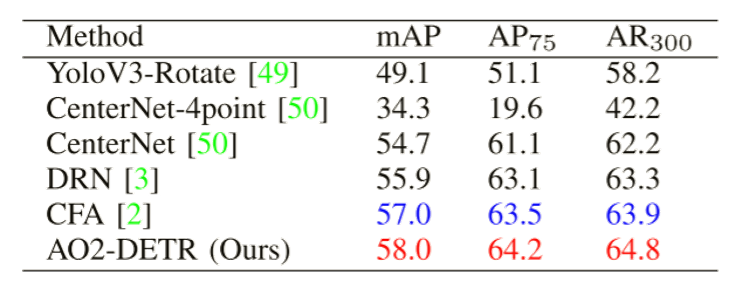
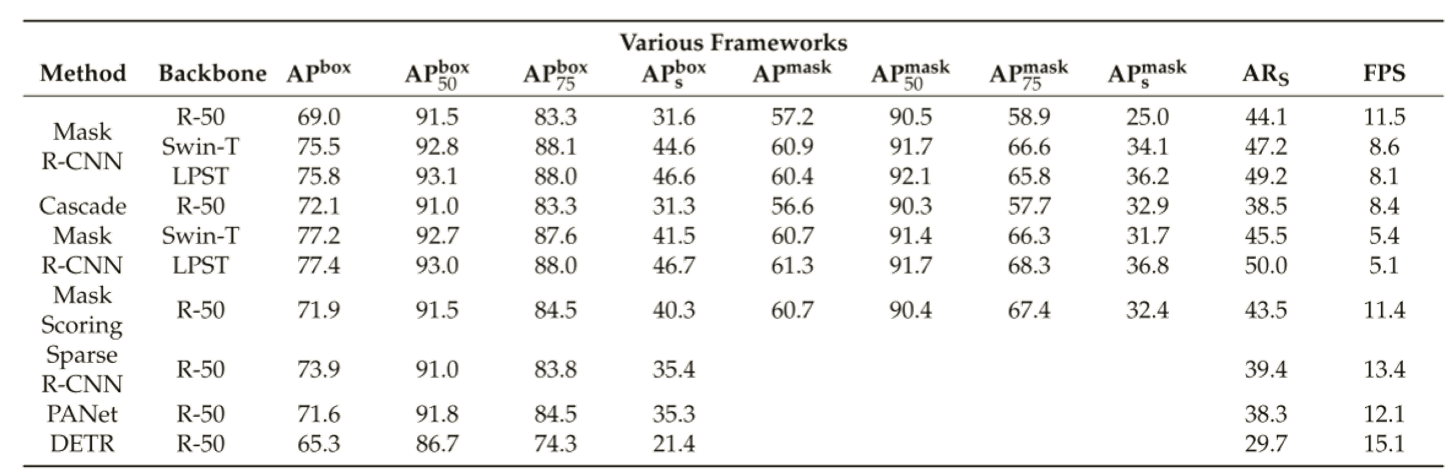
实验:
在创建的MRS-1800数据集上开展实验,不同方法的检测和分割性能比较如表。与传统CNN模型相比,使用Swin transformer和LPSW作为骨干网络,实验结果的各项指标都有较大的改善。
结论:
本文设计的网络模型能够大大提高遥感图像小尺度目标的检测效果,增强多尺度目标的分割精度。将CNN与transformer在局部信息和全局信息获取方面的优势相结合,可以显著提高小尺度目标的检测和分割精度。在掩模头中插入交错执行结构和改进的空间注意力模块有助于抑制噪声,增强网络的掩模预测能力。但值得注意的是,由于缺乏成熟、开放的遥感掩模数据集,实验仅在MRS-1800数据集上进行,可能在数量和类型上受到限制。此外,对模型推理速度的改进和提升的研究还不够。
4.5 SFRNet[30]
论文信息:
SFRNet: Fine-Grained Oriented Object Recognition via Separate Feature Refinement是发表在TGRS 2023 的关于细粒度型号识别的工作[30]。
摘要:
细粒度旋转目标识别是智能解读遥感图像的重要需要,它的目标是实现细粒度的分类,同时利用有方向的边界框实现精确定位。本文提出了一个具有分离特征细化的网络(Separate Feature Refinement, SFRNet),其中有两个基于Transformer的分支分别执行特定功能的特征细化细粒度分类和定位。为了突出明显的信息以便细粒度分类,本文提出了一种空间和通道的transformer(spatial and channel transformer, SC-Former),以捕获远程空间交互和隐藏在特征通道中的关键关联。此外,本文还设计了一个基于深度度量学习协议的多感兴趣区域损失(multi-region of interest loss, MRL),进一步增强了细粒度类的可分离性。对于有向定位,我们将有向响应卷积与transformer结构(OR-Former)进行集成,以帮助在回归过程中对旋转信息进行编码。SFRNet在大规模FAIR1M数据集(FAIR1M-1.0和FAIR1M-2.0)上实现了最先进的性能。
主要贡献:
\1. 提出SC-Former来细化特征以实现细粒度分类。它由两个基于transformer的模块组成,突出了空间维度和通道维度中更具判别性的信息。
\2. 为了进一步增强细粒度类别的可分离性,我们设计了MRL,它根据深度度量学习协议建立实例级约束。
\3. 用OR-Former来细化特征以实现定向定位。它集成了OR-Former算法,有助于在回归过程中对旋转信息进行编码。
\4. 在大规模FAIR1M数据集(FAIR1M-1.0和FAIR1M-2.0)上进行的大量实验表明,SFRNet达到了最先进的技术水平。
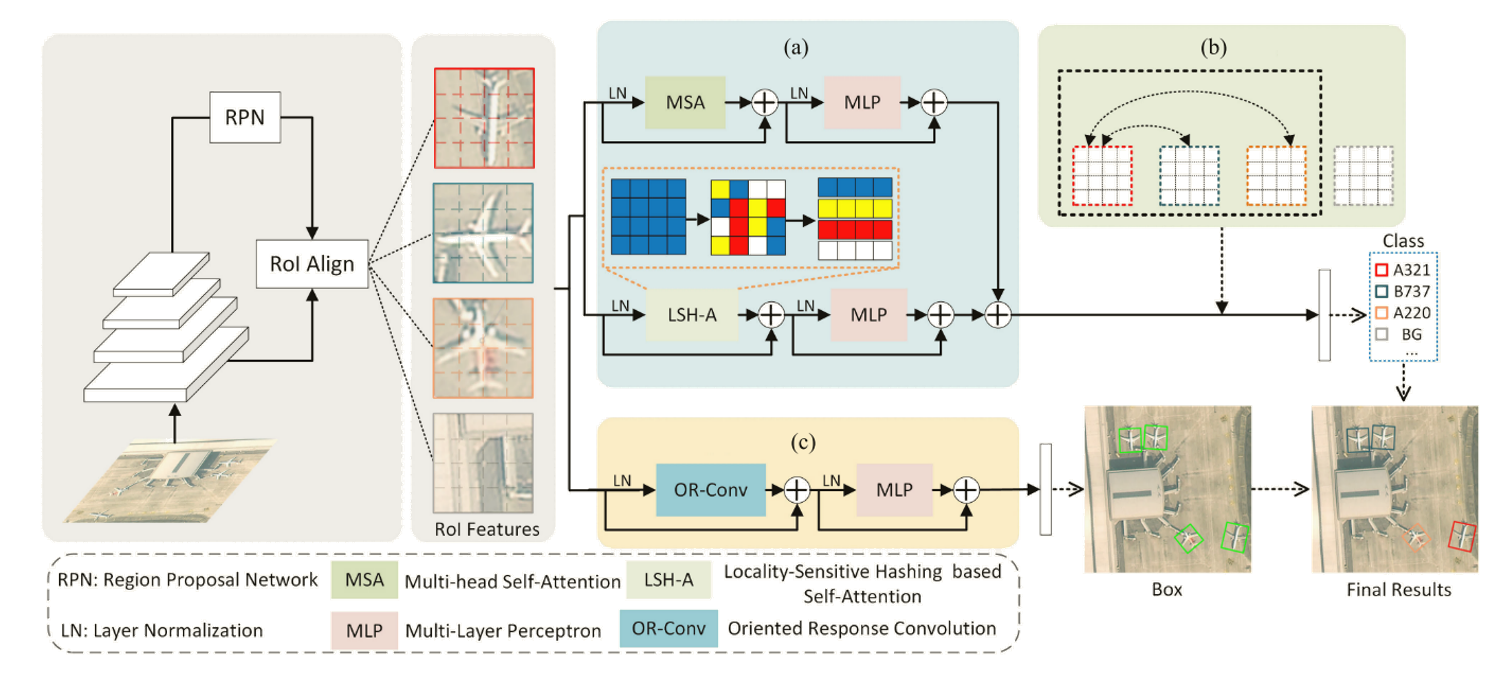
方法:
RoI的特征被发送到两个分支进行单独的细化。(a) SC-Former在分类分支中联合空间注意力和通道注意力,通过(b) MRL对细粒度分类进行规则化。(c) OR-Former为定位分支,用于编码旋转信息。
实验:
旋转目标检测结果如图。

Oriented R-CNN和SFRNet得到的细粒度识别结果的可视化结果。结果表明, SFRNet在细粒度分类方面表现得更好,结果比定向的R-CNN更接近于GT。

结论:
SFRNet能在分类分支中提取细粒度类别之间的细微差异,并在定位分支中获取旋转敏感特征。在大规模数据集FAIR1M上的实验结果表明,我们的SFRNet达到了最先进的性能。
5. 参考文献
[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[2] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
[3] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28.
[4] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
[5] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[6] Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection[J]. arXiv preprint arXiv:2004.10934, 2020.
[7] Ouyang L, Wang H. Aerial target detection based on the improved YOLOv3 algorithm[C]//2019 6th International Conference on Systems and Informatics (ICSAI). IEEE, 2019: 1196-1200.
[8] Baiqi X, Gangwu J, Jianhui L, et al. Aircraft Rotated Boxes Detection Method Based on YOLOv5[C]//2021 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI). IEEE, 2021: 390-394.
[9] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7464-7475.
[10] Aboah A, Wang B, Bagci U, et al. Real-time multi-class helmet violation detection using few-shot data sampling technique and yolov8[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 5349-5357.
[11] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer International Publishing, 2016: 21-37.
[12] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[13] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[14] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[15] Ding J, Xue N, Long Y, et al. Learning RoI transformer for oriented object detection in aerial images[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 2849-2858.
[16] Baiqi X, Gangwu J, Jianhui L, et al. Aircraft Rotated Boxes Detection Method Based on YOLOv5[C]//2021 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI). IEEE, 2021: 390-394.
[17] Ouyang L, Wang H. Aerial target detection based on the improved YOLOv3 algorithm[C]//2019 6th International Conference on Systems and Informatics (ICSAI). IEEE, 2019: 1196-1200.
[18] Lang H, Wu S, Xu Y. Ship classification in SAR images improved by AIS knowledge transfer[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(3): 439-443.
[19] Ying X, Liu L, Wang Y, et al. Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 15528-15538.
[20] Aleissaee A A, Kumar A, Anwer R M, et al. Transformers in remote sensing: A survey[J]. Remote Sensing, 2023, 15(7): 1860.
[21] Han K, Wang Y, Chen H, et al. A survey on vision transformer[J]. IEEE transactions on pattern analysis and machine intelligence, 2022, 45(1): 87-110.
[22] Srinivas A, Lin T Y, Parmar N, et al. Bottleneck transformers for visual recognition[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 16519-16529.
[23] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European conference on computer vision. Cham: Springer International Publishing, 2020: 213-229.
[24] Li F, Zhang H, Liu S, et al. Dn-detr: Accelerate detr training by introducing query denoising[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 13619-13627.
[25] Zheng D, Dong W, Hu H, et al. Less is More: Focus Attention for Efficient DETR[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 6674-6683.
[26] Zhu X, Su W, Lu L, et al. Deformable detr: Deformable transformers for end-to-end object detection[J]. arXiv preprint arXiv:2010.04159, 2020.
[27] Dai L, Liu H, Tang H, et al. Ao2-detr: Arbitrary-oriented object detection transformer[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022.
[28] Ma T, Mao M, Zheng H, et al. Oriented object detection with transformer[J]. arXiv preprint arXiv:2106.03146, 2021.
[29] Xu X, Feng Z, Cao C, et al. An improved swin transformer-based model for remote sensing object detection and instance segmentation[J]. Remote Sensing, 2021, 13(23): 4779.
[30] Cheng G, Li Q, Wang G, et al. SFRNet: Fine-Grained Oriented Object Recognition via Separate Feature Refinement[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023.
[31] Gong H, Mu T, Li Q, et al. Swin-transformer-enabled YOLOv5 with attention mechanism for small object detection on satellite images[J]. Remote Sensing, 2022, 14(12): 2861.