1.官网
https://paimon.apache.org/docs/master/engines/hive/
2.安装flink
3.下载依赖包到flink lib目录下

4.运行yarnsession 创建Application-Name,并修改配置文件
./bin/yarn-session.sh -nm flink-sql -d
拿到对应的applicationID信息配置到conf文件里
yarn app -list
application_1695101257942_0001
配置文件增加配置 flink-conf.yaml
execution.target: yarn-session
yarn.application.id: application_1695101257942_0001
5.进入flink-sql客户端创建表并在hive 进行查询
[root@hadoops108 bin]# ./sql-client.sh
#创建CATALOG,warehouse相当于在hdfs创建的目录即hive数据库名称
CREATE CATALOG paimon_hive WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://hadoopm111:9083',
'warehouse' = 'hdfs:///apps/hive/paimon'
);
#使用CATALOG
USE CATALOG paimon_hive;
#创建paimon目录下的表结构
CREATE TABLE paimon.test_paimon_table (
a int,
b string
);
插入数据
INSERT INTO paimon.test_paimon_table VALUES (3, 'Paimon');
INSERT INTO paimon.test_paimon_table VALUES (4, 'Paimon');
INSERT INTO paimon.test_paimon_table VALUES (4, 'Paimon');
HDFS文件变化

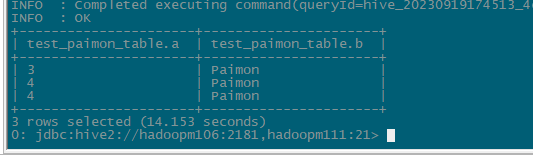
2.hive客户端数据查询
#查数据需要加order by 否则会报错
SELECT * FROM paimon.test_paimon_table ORDER BY a;
6.实验遇到的报错
#报错1
cannot assign instance of java.util.LinkedHashMap to field org.apache.flink.runtime.jobgraph.JobVertex.results of type java.util.ArrayList in instance of org.apache.flink.runtime.jobgraph.InputOutputFormatVertex
#解决办法
mv $FLINK_HOME/opt/flink-table-planner_2.12-1.17.1.jar $FLINK_HOME/lib/flink-table-planner_2.12-1.17.1.jar
mv $FLINK_HOME/lib/flink-table-planner-loader-1.17.1.jar $FLINK_HOME/opt/flink-table-planner-loader-1.17.1.jar
#报错2
ERROR org.apache.flink.yarn.YarnClusterDescriptor[] - The application application_1685677819554_0092 doesn't run anymore. It has previously completed with final status: KILLED
#解决办法
启动yarn-session并进行配置文件配置applicationID
#报错3
Error: Error while compiling statement: FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.paimon.hive.mapred.PaimonInputFormat (state=42000,code=40000)
#解决办法
add jar hdfs:///jars/paimon-hive-connector-3.1-0.6-20230910.002112-5.jar