这篇博客总结自 Wouter van Heeswijk 在 Medium 的文章:Proximal Policy Optimization (PPO) Explained
策略梯度算法(VPG)
从确定性策略开始
强化学习的目标是学习一个好的决策策略 \(\pi\),随着时间的推移最大化奖励。确定性策略 \(π\) 的做法是基于状态 \(s\),利用策略函数 \(\pi:s\to a\) 得到应选的动作 \(a\)。
确定性策略可以采用值近似的方法,即 Q Learning。在 Q Learning 中,强化学习的目标是逼近价值函数 \(Q\) 而非策略函数 \(\pi\)。我们假设有一个最优价值函数 \(Q_{\star}(a|s)\),DQN 所做的就是利用 \(Q(a|s;\theta)\) 尽量接近 \(Q_{\star}(a|s)\)。决策的时候,选择使 \(Q(a|s;\theta)\) 最高的动作 \(a\) 即可:\(a=\arg\max_{a\in\mathcal{A}} Q(a|s;\theta)\)
值近似方法是确定性的,也就是说其返回的是一个确定的动作 \(a\)。通常我们使用 \(\varepsilon\text{-greedy}\) 算法进行探索:智能体所采取的动作有 \(1-\varepsilon\) 的概率由 \(Q(a|s;\theta)\) 决定,但也有 \(\varepsilon\) 的概率从动作空间中随机选取,这样可以允许智能体对其他的决策行为进行一些探索。此外,在训练智能体的时候,对于动作 \(a_t\) 的回报并不能真的计算出来,所以这里需要采用时间差分(TD)算法(严格来讲是 TD 算法中的一种,即 Q 学习算法),将 \(r_t+\gamma Q_{t+1}\) 与 \(Q_t\) 进行比较来改进价值函数。
策略近似:转向随机性策略
在策略近似中,强化学习的目标从学习价值函数 \(Q\) 变成了学习策略函数 \(\pi\),核心思想是用参数化的概率分布 \(\pi_\theta(a|s)=P(a|s;\theta)\) 代替确定性的策略 \(\pi:s\to a\),通过学习逐渐提高获得高回报动作的概率。
从初始状态出发,在 \(\pi_\theta(a|s)\) 下不断做出决策,最终会得到状态-动作轨迹 \(\tau=\{(s_0,\,a_0),\,(s_1,\,a_1),\,\cdots,\,(s_T,\,a_T)\}\)。因为 \(\pi_\theta(a|s)\) 是随机性策略,产生的轨迹 \(\tau\) 也不是唯一的,而是一个概率分布 \(P(\tau)\)。每种轨迹都有不同的回报(即累计奖励) \(R(\tau)=\sum_{t=1}^T\gamma^t R_t\)。
随机性策略下,强化学习的优化目标是最大化回报的期望:
策略梯度
最大化目标函数,需要求出 \(J(\theta)\) 的梯度 \(\nabla_\theta J(\theta)\),然后更新参数 \(\theta\) 即可:
而 \(\nabla_\theta J(\theta)\) 可以通过一个对数导数的技巧化简:
状态-动作的转移是一个马尔科夫链,每一次转移的概率都是当前策略下采样到动作 \(a_t\) 的概率 \(\pi_\theta(a_t|s_t)\) 与在动作 \(a_t\) 下状态转移的概率 \(P(s_{t+1}|s_t,a_t)\) 的乘积。由于马尔科夫过程中,每一次转移与之前的状态无关,所以整个轨迹 \(\tau\) 的概率分布可以直接通过这些彼此独立的概率的连乘来计算:
得到 \(P(\tau;\theta)\) 的定义后,可以进一步化简 \(\nabla_\theta J(\theta)\):
近似梯度
真正的期望是难以计算的,常常对期望取蒙特卡洛近似,得到近似的梯度:
这里的 \(\frac1m\) 是一个常数,可以吸收到学习率 \(\alpha\) 中,于是我们可以得到策略梯度算法的参数更新过程:

有什么缺点?
策略梯度的想法是好的,但其存在一些问题,导致实际训练时效果不佳。
首先,由于普通的策略梯度算法是on-policy算法,每次采集到的样本只能使用一次。这导致使用普通策略梯度算法的训练对样本的需求量非常大,而在实际问题中,采集这么多样本并不是一件容易的事情,往往既耗费时间,代价也非常昂贵。
其次,对参数的更新没有任何限制,这会导致过度更新(overshooting)或者欠更新(undershooting)的问题。欠更新会导致模型学习的缓慢,而在强化学习中,对模型过度更新,可能会使模型落在策略很差的位置,接下来的采样不具有太多的参考价值,模型很难回到原来较好的状态。
最后,蒙特卡洛近似会带来较大的方差,这对模型的收敛也是不利的。
自然策略梯度
限制参数
为了解决 VPG 算法的问题,一种朴素的想法是限制更新后的参数与原参数之间的变化大小,如 \(\|\Delta\theta\|\leq\epsilon\),现在权重更新的方案可以写成:
我们可以把策略函数看作参数空间内的流形。事实上,限制参数空间不能有效地限制统计流形的变化。如果统计流形是线性的,限制 \(\|\Delta\theta\|\leq\epsilon\) 会有效果,但在这种特殊情况之外,我们必须考虑统计流形对参数变化的敏感程度,这就是二阶导数的范畴了。
限制流形本身
我们需要限制更新前后策略函数的差异,也就是两个概率分布之间的差异。最常见的度量概率分布差异的指标是 KL 散度 \(\mathcal{D}_{KL}(\pi_{\theta}\|\pi_{\theta+\Delta\theta})\),权重更新的新方案可以写成:
Fisher 信息矩阵是描述统计流形曲率的黎曼度量,反映了流形对边际参数变化的敏感性。如果我们只关注 \(\Delta\theta=0\),那么 KL 散度的零阶与一阶泰勒展开项在 \(\Delta\theta=0\) 时计算结果为 \(0\),二阶项由 Hesse 矩阵表示,此时它与 Fisher 信息矩阵是等价的:
对于 Hesse 矩阵,其中每一项都是一个二阶导数,这样的计算是非常困难的。对于 Fisher 矩阵,我们可以通过策略梯度的外积来计算:
拉格朗日松弛
带约束条件的优化并不方便计算,利用拉格朗日松弛方法,可以将约束转化为惩罚项,得到一个更容易求解的表达式:
如上式展示的那样,\(\Delta\theta^*\) 可以近似为损失函数 \(J(\theta)\) 的一阶泰勒展开和 KL 散度的二阶泰勒展开。损失函数没有二阶展开的原因是,与散度相比,二阶泰勒展开项可以忽略不计。
找到 \(\Delta\theta\)
通过对需要最大化的目标求偏导,即可找到最优的权重更新:
于是我们找到了需要的 \(\Delta\theta\):
常数 \(\frac1\lambda\) 可以吸收到学习率 \(\alpha\) 中。而事实上,为了确保 \(\mathcal{D}_{KL}(\pi_{\theta}\|\pi_{\theta+\Delta\theta})\leq\epsilon\),学习率 \(\alpha\) 是有解析解的:
因此权重更新方案就是:
简而言之,自然策略梯度算法从两个方面提出了改进:使用了针对流形曲率校正的自然梯度 \(\tilde{\nabla}_\theta J(\theta)=F^{-1}(\theta)\nabla_\theta J(\theta)\),且更新的学习率是动态的,可以自动限制策略变化的幅度。

还有什么缺点?
自然梯度算法从理论上得到了一个漂亮的结论,但是并没有验证策略在这种更新下是否确实有改进,而且在近似值下约束也未必真的能满足。
此外,Fisher 信息矩阵求逆是一个 \(\Theta(N^3)\) 复杂度的计算,而且需要占用 \(|\theta|^2\) 的空间,时空复杂度都是难以接受的。
最后,诸如 Adam 等梯度优化器都是对一阶梯度的优化,自然梯度算法使用了二阶梯度,无法使用这些优化器。
信任域策略优化
理论
优势函数 \(A^{\pi_\theta}(s,a)=\mathbb{E}\left(Q^{\pi_\theta}(s,a)-V^{\pi_\theta}(s)\right)\) 是一种优化的奖励信号,它为价值函数添加了基线。优势函数为正,即意味着采取的动作“好于预期”。使用优势函数后,可以将更新前后的目标函数建立如下联系:
其中 \(\rho_{\pi_\theta}\) 是在 \(\pi_\theta\) 策略下状态的分布。接下来,我们必须让事情适合模拟,因为我们没有完整的状态和动作集。我们将 \(\rho\) 替换为期望符号,这样我们可以使用蒙特卡洛估计对其进行采样——并使用重要性采样来替换对动作的求和。通过重要性抽样,我们有效地利用了当前策略下对各种动作的期望,并针对新策略下的概率进行了修正:
我们将新策略下的目标函数值相对于旧策略的优势记为代理优势 \(\mathcal{L}_{\pi_\theta}(\pi_{\theta+\Delta\theta})\):
\(J(\pi_{\theta+\Delta\theta})-J(\pi_\theta)\) 与 \(\mathcal{L}_{\pi_\theta}(\pi_{\theta+\Delta\theta})\) 的近似误差可以用两种策略之间最坏情况下的 KL 散度表示:
这个公式意味着,如果 \(\mathcal{L}_{\pi_\theta}(\pi_{\theta+\Delta\theta})\) 超过了 \(C\mathcal{D}_{KL}^{\max}(\pi_\theta\|\pi_{\theta+\Delta\theta})\),我们对策略函数的修改就是朝着好的方向进行的。所以我们只要优化 \(\mathcal{L}_{\pi_\theta}(\pi_{\theta+\Delta\theta})\),就能保证一定是在优化策略函数。
惩罚 \(C\) 是通过分析得出的,会产生了相当严厉的惩罚。如果我们遵循理论上的 TRPO 算法,更新会非常缓慢。
实践
因此实际上,TRPO算法从基于惩罚变成了基于约束,其建立在自然梯度算法上,采用了以下几点优化:
-
共轭梯度法:我们已经讲过,自然策略梯度的一个问题在于,计算逆 Fisher 矩阵是一个相当困难的事情。但是我们在前面的推导中,已经化简过 \(\nabla J(\theta)\) 了,这里再复习一下:\(\nabla J(\theta)=\mathbb{E}_{\tau\sim\pi_\theta}\sum_t\nabla\log\pi_\theta(a_t|s_t) R(\tau)\),而 \(\Delta\theta=\dfrac1\lambda F^{-1}(\theta)\nabla J(\theta)\),不难发现,其实我们只需要乘积 \(F^{-1}∇\log\pi_\theta(x)\),而不需要单独计算逆矩阵 \(F^{-1}\)。如果可以计算\(x=F^{-1}\nabla\log\pi_\theta(x)\) 或 \(F\cdot x=\nabla\log\pi_\theta(x)\),我们实际上并不需要求出逆矩阵。共轭梯度可以比矩阵求逆更快地逼近这个乘积,大大加快更新过程。
-
线性搜索:虽然自然梯度提供了给定 KL 散度约束下的最佳步长,但由于取了近似值,更新实际上可能不满足约束。TRPO 通过线性搜索来解决这个问题——与典型的梯度搜索不同——TRPO 从自然梯度的建议值开始,迭代地减小更新的步长(通过不断衰减的 \(\alpha^j\)),直到更新不再不违反约束。这个过程也可以看作是逐步缩小信任区域,在最终产生更新时,我们可以相信,信任区域内的更新确实可以改进策略函数。

- 改进检查:TRPO 并没有通过理论求出到底怎样更新才能真正改进策略函数,它直接验证了代理损失 \(\mathcal{L}(\theta)\) 在更新后是否有所改善(即上面伪代码的 \(\mathcal{L}(\theta)\geq0\))。回想一下,由于取了近似,自然策略梯度对优化的理论保证不再成立,TRPO 直接实验检查了这一点。
完整的 TRPO 伪代码如下图所示:

还有什么问题?
尽管采用了共轭梯度法,TRPO仍然难以处理大的 Fisher 矩阵——即使不需要对它们求逆——准确逼近 Fisher 矩阵需要大量的样本。
此外 TRPO 用的依旧是二阶梯度,我们还是用不了 Adam 之类的优化器。而且 TRPO 实际上的算法是基于约束的,我们知道基于约束的算法,跑起来比基于惩罚的算法慢多了。
近端策略优化
基于惩罚
在 TRPO 部分,我们已经把目标函数的更新与代理优势函数建立了联系,对参数的更新其实就是:
一个问题是很难确定各种任务下通用 \(\beta\) 值。事实上,即使是同一个任务,随着时间的推移,合适的 \(\beta\) 也可能发生变化。我们没有对 KL 散度设置上限,因此有时我们希望比其他时候更严厉的惩罚,以免更新过大。
PPO 设置了一个“目标分歧” \(\delta\),我们希望我们的更新在 \(\delta\) 附近——更新应该足够大,这样才足以改变策略函数;更新也应当足够小,以免更新不稳定。
每次更新后,PPO 都会检查更新的大小。如果真实的更新太大,对于下一次迭代,我们通过加倍 \(\beta\) 来实施更严厉的惩罚。相反,如果更新太小,我们将 \(\beta\) 减半,从而扩大信任区域,让下一次更新幅度更大。这里与 TRPO 线性搜索有一些相似之处,不过 PPO 对更新步伐的约束在两个方向上都有效。
超过某个目标阈值的 \(1.5\) 倍,我们将 \(\beta\) 加倍,不足阈值的 \(1/1.5\),我们将 \(\beta\) 减半。这并不是精心证明的结果,而是启发式确定的。PPO 的更新会不时违反约束条件,但通过调整 \(\beta\),我们可以很快地纠正它。根据经验,PPO 似乎对超参数设置非常不敏感。总之,PPO 牺牲了一些数学上的严谨性来支持实用主义。
而且值得注意的一点是,由于 PPO 更新相当小,我们可以在某种程度上重复使用采到的样本,并使用重要性采样校正更新的动作概率。
PPO 基于惩罚的算法如下图所示:

基于 Clip
不过 PPO 还有另一种更好的实现。与其费心地随着时间推移改变惩罚,我们不妨直接限制策略函数可以改变的范围。由于在裁剪范围之外的更新所获得的优势函数,不被用于更新目的,这种做法鼓励智能体更新时与原策略尽量保持接近。目标函数仍通过代理优势函数计算,但现在看起来像这样:
其中 \(\rho_t(\theta)=\dfrac{\pi_\theta(a_t|s_t)}{\pi_{\theta_k}(a_t|s_t)}\) 是重要性采样率。在这种目标函数下,超出可信区域外的样本,会被约束到不依赖于 \(\theta\) 的值 \((1-\epsilon)A\) 或 \((1+\epsilon)A\) 上,从而不会被用来更新。对于不同的采样情况,基于 Clip 的 PPO 分别会进行如下操作:
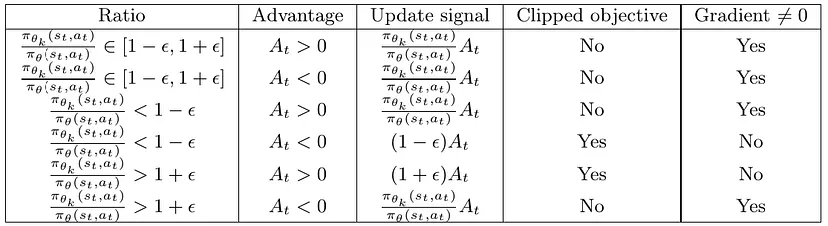
根据经验,\(\epsilon=0.1\) 或 \(\epsilon=0.2\) 是一个比较好的取值。完整的算法如下:

PPO 在速度、谨慎性和可用性之间取得了美妙的平衡。虽然 PPO 没有自然梯度和 TRPO 的理论保证和数学技巧,但在实际应用中,PPO 却能首先做到收敛。自 2017 年推出以来,PPO 迅速成为连续控制问题的首选算法,现在依旧具有相当的竞争力。有意思的是,深度强化学习的简单性似乎得到了回报。