Gunicorn
参考博客:
相关概念
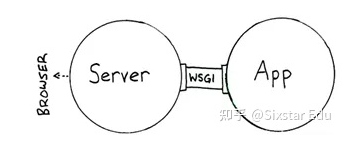
WSGI
WSGI是Web Server Gateway Interface的简称。WSGI标准在PEP333中定义并被许多框架实现,它规定了一种Web服务器与Web应用程序/框架之间推荐的标准接口,以确保Web应用程序在不同的Web服务器之间具有可移植性,可以让Web应用程序的开发者把精力集中到自己的领域。
WSGI协议主要包括server和application两部分:
- -WSGI server负责从客户端接收请求,将request转发给application,将application返回的response返回给客户端;
- -WSGI application接收由server转发的request,处理请求,并将处理结果返回给server。
客户端和服务器端进行沟通遵循了HTTP协议, 可以说HTTP就是它们之间沟通的语言。 从HTTP请求到我们的Web程序之间, 还有另外一个转换过程——从HTTP报文到WSGI规定的数据格式。 WSGI则可以视为WSGI服务器和我们的Web程序进行沟通的语言。
uwsgi
同WSGI一样是一种通信协议
uwsgi协议是一个uWSGI服务器自有的协议,它用于定义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型描述,它与WSGI相比是两样东西。
uWSGI (服务器)
它是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。用于接收前端服务器转发的动态请求并处理后发给 Web 应用程序。
因为apache也好,Nginx也罢,它们自己都没有解析动态语言如php的功能,而是分派给其他模块来做,比如apache就可以说内置了php模块,支持的非常爽,让人感觉好像apache就支持php一样。uwsgi实现了WSGI协议、uwsgi、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。
uWSGI是使用C编写的,显示了自有的uwsgi协议的Web服务器。它自带丰富的组件,其中核心组件包含进程管理、监控、IPC等功能,实现应用服务器接口的请求插件支持多种语言和平台,比如WSGI、Rack、Lua WSAPI,网管组件实现了负载均衡、代理和理由功能
uWSGI也可以当做中间件。
- 如果是Nginx+uWSGI+App,那uWSGI就是一个中间件
- 如果是uWSGI+App,那它就是服务器
ASGI
异步网关协议接口,一个介于网络协议服务和Python应用之间的标准接口,能够处理多种通用的协议类型,包括HTTP,HTTP2和WebSocket。
然而目前的常用的WSGI主要是针对HTTP风格的请求响应模型做的设计,并且越来越多的不遵循这种模式的协议逐渐成为Web变成的标准之一,例如WebSocket。
ASGI尝试保持在一个简单的应用接口的前提下,提供允许数据能够在任意的时候、被任意应用进程发送和接受的抽象。并且同样描述了一个新的,兼容HTTP请求响应以及WebSocket数据帧的序列格式。允许这些协议能通过网络或本地socket进行传输,以及让不同的协议被分配到不同的进程中。
WSGI和ASGI的区别
WSGI是基于HTTP协议模式的,不支持WebSocket,而ASGI的诞生则是为了解决Python常用的WSGI不支持当前Web开发中的一些新的协议标准。同时,ASGI对于WSGI原有的模式的支持和WebSocket的扩展,即ASGI是WSGI的扩展。
Nginx
是一个 HTTP 和反向代理服务器
-
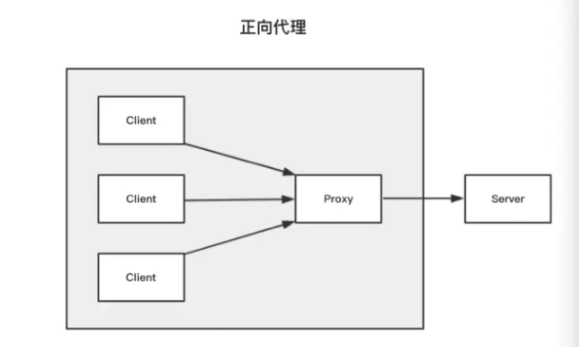
正向代理:正向的就是由浏览器主动的想代理服务器发出请求,经代理服务器做出处理后再转给目标服务器
-
反向代理:反向的就是不管浏览器同不同意,请求都会经过代理服务器处理再发给目标服务器
作用:
- 保障应用服务器的安全(增加一层代理,可以屏蔽危险攻击,更方便的控制权限)
- 实现负载均衡
- 实现跨域
-
负载均衡:根据请求情况和服务器负载情况,将请求分配给不同的Web服务器,保证服务器性能
-
提高Web服务器的IO性能:请求从客户端传到Web服务器是需要时间的,传递多长时间就会让这个进程阻塞多长时间,而通过反向代理,就可以由反向代理完整接受该请求,然后再传给Web服务器,从而保证服务器性能,而且有的一些简单的事情(比如静态文件)可以直接由反向代理处理,不经过Web服务器
简述
gunicorn(绿色独角兽),是一个 Python 的 WSGI HTTP 服务器。它所在的位置通常是在反向代理(如 Nginx)或者 负载均衡(如 AWS ELB)和一个 web 应用(如Flask)之间。它是一个移植自Ruby的Unicorn项目的pre-fork worker模型,即支持eventlet也支持greenlet。 Gunicorn启动项目之后一定会有一个主进程Master和一个或者多个工作进程。工作进程的数量可以指定。工作进程是实际处理请求的进程。主进程维护服务器的运行。
安装
# 安装最新版本的gunicorn
pip install gunicorn
# 安装指定版本的gunicorn
pip install gunicorn==19.9.0
# 异步模式
pip install gevent==1.4.0
# 查看Gunicorn版本
pip show gunicorn
运行
gunicorn [OPTITIONS] $(MIDULE_NAME):$(VAROABLE_NAME)
(MODULENAME):(VARIABLE_NAME) 表示要启动的WSGI_app。其中MODULE_NAME对应的是python文件名,VARIABLE_NAME对应web应用实例。举个 吧!!!这里定义一个名为learn.py 文件,在其内部创建Flask应用。
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
那么,用gunicorn启动该Flask应用的命令就是:
gunicorn --workers=2 learn:app
配置参数
-c CONFIG:CONFIG,配置文件的路径,通过配置文件启动;生产环境使用;
-b ADDRESS:ADDRESS,ip加端口,绑定运行的主机;
-w INT, --workers INT:用于处理工作进程的数量,为正整数,默认为1;
-k STRTING, --worker-class STRTING:要使用的工作模式,默认为sync同步进程,可以修改为eventlet或gevent异步进程
--threads INT:处理请求的工作线程数,使用指定数量的线程运行每个worker。为正整数,默认为1。
--worker-connections INT:最大客户端并发数量,默认情况下这个值为1000。
--backlog int:未决连接的最大数量,即等待服务的客户的数量。默认2048个,一般不修改;
-p FILE, --pid FILE:设置pid文件的文件名,如果不设置将不会创建pid文件
--access-logfile FILE:要写入的访问日志目录
--access-logformat STRING:要写入的访问日志格式
--error-logfile FILE, --log-file FILE:要写入错误日志的文件目录。
--log-level LEVEL:错误日志输出等级。
--limit-request-line INT:HTTP请求头的行数的最大大小,此参数用于限制HTTP请求行的允许大小,默认情况下,这个值为4094。值是0~8190的数字。
--limit-request-fields INT:限制HTTP请求中请求头字段的数量。此字段用于限制请求头字段的数量以防止DDOS攻击,默认情况下,这个值为100,这个值不能超过32768
--limit-request-field-size INT:限制HTTP请求中请求头的大小,默认情况下这个值为8190字节。值是一个整数或者0,当该值为0时,表示将对请求头大小不做限制
-t INT, --timeout INT:超过这么多秒后工作将被杀掉,并重新启动。一般设定为30秒;
--daemon:是否以守护进程启动,默认false;
--chdir:在加载应用程序之前切换目录;
--graceful-timeout INT:默认情况下,这个值为30,在超时(从接收到重启信号开始)之后仍然活着的工作将被强行杀死;一般使用默认;
--keep-alive INT:在keep-alive连接上等待请求的秒数,默认情况下值为2。一般设定在1~5秒之间。
--reload:默认为False。此设置用于开发,每当应用程序发生更改时,都会导致工作重新启动。
--spew:打印服务器执行过的每一条语句,默认False。此选择为原子性的,即要么全部打印,要么全部不打印;
--check-config:显示现在的配置,默认值为False,即显示。
-e ENV, --env ENV:设置环境变量;
-n proc_name, --name=APP_NAME 用于指定gunicorn进程的名称;
--max-requests INT 最大请求数,默认值是0。在重启之前工作进程(worker)能处理的最大请求数,任何一个大于0的值都会限制工作进程(worker)在重启之前处理的请求数量,这是一种帮助限制内存泄漏的简单方法。如果该值设置为0(默认值)那么工作进程的自动重启是被禁用;
工作模式
默认的工作模式是sync,即同步的工作模式。一共有五种工作模式,分别是 sync, eventlet, gevent, tornado, gthread
1、sync 模式(同步工作模式)
这是最基本的工作模式,也是默认的工作模式,线程为native类型。即请求先来后到,排队模式。
2、eventlet 模式(协程异步)
eventlet 工作模式是基于eventlet库,利用python协程实现的。
要使用该工作模式的话必须先安装eventlet库,并且版本要大于等于0.24.1
安装命令是:pip install eventlet
3、gevent模式(协程异步)
gevent是基于Greentlet库,利用python协程实现的。
安装命令是:pip install gevent
Gunicorn允许通过设置对应的worker类来使用这些异步Python库。这里的设置适用于我们想要在单核机器上运行的gevent:
gunicorn --worker-class=gevent -w 2 manage:app
4、tornado模式
tornado利用python Tornado框架来实现。安装命令是:pip install tornado 安装的tornado库的版本要大于等于0.2。
5、 gthread模式
gthread采用的是线程工作模式,利用线程池管理连接,需要安装gthread库。
安装命令是:pip install gthread
Gunicorn允许每个worker拥有多个线程。在这种场景下,Python应用程序每个worker都会加载一次,同一个worker生成的每个线程共享相同的内存空间。为了在 Gunicorn 中使用多线程。我们使用了 gthreads 模式,指定threads参数。
配置文件
当配置比较复杂时,可通过conf文件对gunicorn进行配置,启动命令为:
gunicorn -c gunicorn.conf app:app
例如:
# gunicorn.conf
# coding:utf-8
import multiprocessing
# 并行工作进程数, int,cpu数量*2+1 推荐进程数
workers = multiprocessing.cpu_count() * 2 + 1
# 指定每个进程开启的线程数
threads = 3
# 绑定的ip与端口
bind = '0.0.0.0:5000'
# 设置守护进程,将进程交给supervisor管理
daemon = 'false'
# 工作模式协程,默认的是sync模式
worker_class = 'gevent'
# 设置最大并发量(每个worker处理请求的工作线程数,正整数,默认为1)
worker_connections = 2000
# 最大客户端并发数量,默认情况下这个值为1000。此设置将影响gevent和eventlet工作模式
max_requests = 2000
# 设置进程文件目录
pidfile = '/home/your_path/gunicorn.pid'
# 设置访问日志和错误信息日志路径
accesslog = '/home/your_path/gunicorn_acess.log'
errorlog = '/home/your_path/gunicorn_error.log'
# 日志级别,这个日志级别指的是错误日志的级别,而访问日志的级别无法设置
loglevel = 'info'
# 设置gunicorn访问日志格式,错误日志无法设置
access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"'
# 监听队列
backlog = 512
#进程名
proc_name = 'gunicorn_process'
# 设置超时时间120s,默认为30s。按自己的需求进行设置timeout = 120
timeout = 120
# 超时重启
graceful_timeout = 300
# 在keep-alive连接上等待请求的秒数,默认情况下值为2。一般设定在1~5秒之间。
keepalive = 3
# HTTP请求行的最大大小,此参数用于限制HTTP请求行的允许大小,默认情况下,这个值为4094。
# 值是0~8190的数字。此参数可以防止任何DDOS攻击
limit_request_line = 5120
# 限制HTTP请求中请求头字段的数量。
# 此字段用于限制请求头字段的数量以防止DDOS攻击,与limit-request-field-size一起使用可以提高安全性。
# 默认情况下,这个值为100,这个值不能超过32768
limit_request_fields = 101
# 限制HTTP请求中请求头的大小,默认情况下这个值为8190。
# 值是一个整数或者0,当该值为0时,表示将对请求头大小不做限制
limit_request_field_size = 8190
# 设置gunicorn使用的python虚拟环境
pythonpath='/home/your_path/venv/bin/python3'
# 环境变量
raw_env = 'APE_API_ENV=DEV'
备注
1、如果这个应用是I/O受限,通常可以通过使用“伪线程”(gevent或asyncio)的工作模式来得到最佳性能。正如我们了解到的,Gunicorn通过设置合适的worker类并将workers数量调整到(2*CPU)+1来支持这种编程范式。
2、如果这个应用是CPU受限,那么应用程序处理多少并发请求就并不重要,唯一重要的是并行请求的数量。因为Python’s GIL,线程和’伪线程’并不能以并行模式执行,可以将worker的数量改成CPU的核数,理解到最大的并行请求数量其实就是核心数。这时候适合的工作模式是sync工作模式。
3、如果不确定应用程序的内存占用,使用多线程以及相应的gthread worker类会产生更好的性能,因为应用程序会在每个worker上都加载一次,并且在同一个worker上运行的每个线程都会共享一些内存,但这需要一些额外的CPU消耗。
4、如果你不知道你自己应该选择什么就从最简单的配置开始,就只是 workers 数量设置为 (2*CPU)+1 并且不用考虑 多线程。从这个点开始,就是所有测试和错误的基准环境。如果瓶颈在内存上,就开始引入多线程。如果瓶颈在 I/O 上,就考虑使用不同的 Python 编程范式。如果瓶颈在 CPU 上,就考虑添加更多内核并且调整 workers 数量。