The Deep Learning Compiler: A Comprehensive Survey
AI编译器综述
对ai编译器进行综述,分析整体设计,并具体比较TVM、XLA等框架
摘要
在不同的硬件上部署不同的深度学习模型十分困难,所以社区中深度学习编译器研究开始迅速发展。一些深度学习编译器例如TVM、TensorFlow XLA促进了工业和学业界的发展。这些深度学习编译器大多将不同深度学习框架的深度学习模型表示作为输入,然后输出为不同的硬件后端构建优化的代码。
介绍
深度学习发展广泛影响了多个科学领域,例如NLP、CV、智慧城市、药物研发等,多种不同的模型也开始出现,卷积神经网络CNN,递归神经网络RNN,长短期记忆LSTM等。
于此同时,一些专门的计算例如矩阵乘法,促使芯片体系开始设计定制化的深度学习加速器,以获得更高的效率。
为了应对硬件的多样性,将计算高效地映射到深度学习硬件上是十分重要的。在一些硬件上,经过高度优化的线性代数库作为深度学习模型计算的基础,例如BLAS库(MKL、cuBLAS),以卷积算子为例,深度学习框架将卷积转换成矩阵乘法,然后调用BLAS的GEMM函数。除此之外,硬件供应商还发布了专门的深度学习计算库,例如MKL-DNN和cuDNN,包括前向和后向的卷积、池化、正则化和激活函数。为了进一步提高性能,更多先进的工具被应用,例如TensorRT支持图优化(layer fusion),以及低比特量化,使用高度优化的GPU kernels的集合。
为了减轻在不同深度学习硬件上手动优化深度学习模型的负担,一些深度学习编译器被提出。例如TVM,Tensor Comprehension,Glow,nGraph和XLA,来自工业界或学术界。这些深度学习编译器将深度学习框架定义的模型作为输入,输出针对硬件优化的代码。从模型定义到构建代码的过程经过高度优化。包含深度学习方面的层融合和算子融合,深度学习编译器也利用了一些通用编译器的成熟工具链,例如LLVM,提供了更好的可移植性。类似于传统编译器,深度学习编译器也采用了前端、IR、后端的设计。不同深度学习的编译器主要在多级别IR和DL特定的优化上有区别。
将来可能的发展
- 动态shape,预处理和后处理,进一步的自动调优,多面体模型,子图划分,量化,统一优化(unified optimizations),可微编程(differentiable programming),隐私保护。
背景
深度学习框架

TensorFlow
- TensorFlow在支持多种语言接口方便具有很大优势,包括C++,Python,Java,Go,R和Haskell。TensorFlow使用数据流图来表示,扩展了严格使用边控制的微分程序。TensorFlow Lite被用作移动和嵌入式的深度学习提供了Android神经网络API,为了减少使用TensorFlow的复杂程度,Google开发了Keras作为TensorFlow core的前端,进一步,eager-mode在TensorFlow中被使用,提供了类似于PyTorch一样支持动态计算图的方式。
Keras
- Keras是高层次神经网络库,可以快速构建DL模型,使用纯Python编写。尽管它本身没有DL框架,但提供了高层次的接口,整合了TensorFLow,MXNet,Theano和CNTK。使用Keras,DL开发者可以使用几行代码来构建神经网络。除此之外,还整合了其他通用的DL包,例如scikit-learn。但是,Kears的过度封装导致可扩展性下降,添加算子和获取底层数据信息比较困难。
PyTorch
- Facebook重写了基于Lua编写的DL框架Torch,并使用Tensor重构了所有模块,PyTorch成为最流行的动态图框架。
Caffe
- Caffe被设计用作图像分类,提供了命令行,Python和MATLAB API。Caffe十分简洁,便于扩展。
MXNet
- MXNet支持C++,R,Scala,Julia,Matlab和JavaScript的API,目的是增强可扩展性,减少数据的加载和IO的复杂性,体哦那个了声明式的编程和类似于PyTorch的方式。
CNTK
- CNTK可以通过Python,C++和C# API调用,还有本身的脚本语言BrainScript,但CNTK不支持ARM体系,限制了在移动设备上的使用。
PaddlePaddle
- 最初的设计类似与Caffe,每个模型使用一系列层来表示,v2版本采用了类似于TensorFlow的算子表示,将层拆分成更细粒度的算子,能够支持更加复杂的模型结构。PaddlePaddle Fluid类似于PyTorch,因为它提供了自己的解释器来避免Python解释器的性能限制。
ONNX
- Open Neural Network Exchange(ONNX)定义了可扩展的计算图模型,因为不同框架的计算图能够简单地转换为ONNX格式,使用这种格式可在不同DL框架中转换模型。
深度学习硬件
深度学习硬件可以被分为三个种类
- 通用硬件,对DL工作负载进行硬件和软件的优化
- 专用硬件,专门为DL定制电路设计
- 神经形态硬件,通过模仿人类大脑发挥作用
通用硬件
- 最具代表性的就是GPU,使用多核体系并行。例如Nvidia GPUs从Volta体系开始引入了tensor cores,能够加速混合精度矩阵乘法,加速并行计算,在DL的训练和推理过程中都广泛使用。并为了协同硬件进行优化发布了专门优化的DL库和工具,例如cuDNN和TensorRT,进一步加速计算。
专用硬件
- 专用硬件完全为了DL定制,最有名的是Google TPU系列,一个TPU包括了矩阵乘法单元(MXU),统一缓冲区(UB),激活单元(AU),通过host处理器的CISC指令驱动。相比于CPU和GPU,TPU虽然可以编程,但是最基础的原语不是向量或标量,而是矩阵乘。Amacon Inferentia芯片包含4个NeuroCores用作tensor级别的计算,拥有更大的片上(on-chip)cache减少主存访问。
神经形态硬件
- 神经形态硬件使用电子技术来模仿生物大脑,代表是IBM的TrueNorth和Intel的Loihi,在神经元中有很强的连通性,结构也与大脑类似,神经元可以同时存储和处理数据。传统的芯片处理器和内存在不同的位置,但是神经形态硬件通常含有很多的微处理器,每个包含一个小的局部存储,相比于TrueNorth,Loihi有更类似于大脑的学习能力。
DL编译器设计体系
通常的DL编译器主要设计包含两个部分,编译器前端和编译器后端。中间表示IR分布在前端和后端,通常来说,IR是程序的抽象,被用于程序的优化。特别地,DL模型在编译器中用多层IR来表示,high-level IR在前端,low-level IR在后端。根据high-level IR,编译器前端负责进行硬件无关的变换和优化。根据low-level IR,编译器后端负责进行硬件相关的优化,代码生成和编译。

high-level IR
- 也被称为图IR,表示了计算和控制流,硬件无关。high-level IR的设计挑战在于对计算和控制流的抽象能力,需要能表达多种DL模型。high-level IR的目的是为了建立控制流和算子、数据之间的依赖关系,提供图级别的优化接口,包含丰富的编译语义信息,为自定义算子提供了扩展性。
low-level IR
- 被设计用作硬件相关的优化和针对不同目标硬件的代码生成,因此,low-level IR应该足够细粒度来表示硬件的特性和硬件相关的优化。并且应当允许在编译器后端使用成熟的第三方工具链,例如Halide,多面图模型和LLVM等。
frontend
- 将深度学习框架的模型作为输入,然后将模型转换为计算图表示(graph IR)。前端需要实现多种格式转换来支持不同的框架。计算图优化包括通用编译方案和深度学习专门的优化,减少冗余,提升图IR的性能。这些优化可以被分为node级别(nop消除和zero-dim-tensor消除),block级别(代数化简,算子融合,算子下沉),数据流级别(CSE,DCE,static memory planning和layout transformation)。经过前端处理之后,优化的计算图将被构建并传给后端。
backend
- 将high-level IR转换成low-level IR,并执行硬件相关的优化。
- 既可以直接将high-level IR转换成第三方工具链,例如LLVM IR,来使用已有的一些工作。
- 也可以利用模型和硬件的先验知识,使用自定义的编译passes,做更进一步的代码生成。
- 通常使用到的硬件相关优化包括,硬件指令映射,内存分配和访问,隐藏内存访问延迟,并行化和循环方面的优化。为了在可能的空间中选择最优的参数,auto-scheduling(polyhedral model)和auto-tuning(AutoTVM)这两种方式被广泛使用。优化后的low-level IR将使用JIT或者AOT编译,为不同的硬件生成代码。
DL编译器的关键组成
High-level IR
传统编译器的IR限制了DL模型中复杂计算的表示,为了克服这一点,现有的DL编译器利用high-level IR(也被称为graph IR)进行表示。
graph IR表示
graph IR的表示方法会影响其表现力,也会影响DL编译器分析它的方法。
基于DAG图的IR
- 这是最经典的方式,使用节点和边构建有向无环图(DAG)。在深度学习编译器中,节点表示原子的DL算子(卷积、池化等),边表示张量。DAG中没有环,与通用编译器的数据依赖图(DDG)不同。在DAG计算图的帮助下,DL编译器可以分析算子之间的依赖关系,并使用这些信息指导优化。DDG中已经有许多优化方案,例如常见的子表达式消除,死代码消除。通过将DL的一些知识组合进这些方法中,可以对DAG图进行优化。DAG IR便于编程和编译,因为它较为简洁,但是也存在缺陷,例如语义歧义,因为缺少计算范围的定义。
基于Let-binding的IR
- Let-binding是解决语义歧义的一种方法,通过let表达式来限定范围,在一些高级编程语言如Javascript、F#、Scheme中使用。当使用let关键字定义一个表达式时,一个let节点被创建,并且指向表达式中的算子和数据,在基于DAG的编译器中,当一个过程需要获取表达式的数据时首先需要访问对应相关节点,例如递归下降。而let-binding编译器将let表达式中结果和变量的值存储在map中。当需要某个结果时,编译器通过查找map获得。在DL编译器中,TVM的Relay IR采取了DAG和let-binding结合的IR,利用两者的优势。
张量计算表示
- 不同的graph IRs有不同的方式来描述张量的计算,不同DL框架的算子将会转换成IR,有时会用到一些自定义算子,张量计算的表示方法可以分为三类。
- 基于函数。这种表示只提供了封装好的算子,在Glow,nGraph和XLA中被使用,以高层次的优化器(HLO,XLA的IR)作为例子,它包含了一系列函数,并且大多数没有副作用,这些指令被组织成三个级别,包括HloModule(整个程序),HloComputation(一个函数),HloInstruction(算子)。XLA使用HLO IR来表示graph IR和算子IR,所以HLO在数据流和算子级别均被使用
- lambda表达式。lambda表达式,通过变量绑定描述了计算方式。使用lambda表达式,开发者可以快速定义计算。TVM使用tensor expression来表示张量的计算,就是基于lambda表达式。在TVM中,tensor expression中的张量计算通过输出张量的形状和lambda表达式定义的计算规则描述。
- Einstein notation。是一种求和约定的计算符号。编程比lambda表达式更简洁,以TC为例,不需要定义临时变量的索引,IR可以通过爱因斯坦注解找到表达式的值。算子需要可交换,这种限制保证了规约算子可以任意顺序执行,使得进一步并行化成为可能。
Graph IR的实现,包括数据和算子的管理
数据表示
DL编译器的数据(例如输入、权重和中间数据)通常以张量形式表示,即多维数组。DL编译器可以直接通过内存指针表示张量数据,或者通过占位符的方式更加灵活地处理。占位符信息包括张量每个维度的尺寸,有时一些维度是未知的。为了进行优化,DL编译器需要数据布局的信息,迭代器的界限应当能从占位符中推理。
-
Placeholder。占位符广泛应用于符号编程(Lisp、Tensorflow)。一个占位符是有确定形状信息的变量,在之后的计算中会填充数据。它允许开发者描述算子和构建计算图,而不需要考虑具体的数据。分离了计算和执行的过程。并且在不改动计算定义的情况下,可以方便地修改输入输出的形状。
-
Unknown(Dynamic) shape representation。TVM使用Any来表示未知的维度(Tensor<(Any,3),fp32>)。XLA使用None(tf.placeholder("float",[None,3]))。nGraph使用PartialShape类。为了支持动态模型,边界推断和张量维度检查需要被放松。需要采取一些其他机制来保证内存的有效性。
-
Data layout。数据布局描述了张量在内存中是如何组织的,以及逻辑索引和内存索引的关系。数据布局通常包括一系列维度(NCHW和NHWC),分块,填充,步长等。TVM和Glow使用算子的参数进行表示,并且利用这个信息进行计算和优化。将数据信息和算子组合而不是和张量组合,能够便于实现某些算子,并减少编译开销。XLA将数据布局与后端硬件关联。Relay和MLIR将把这些信息加入type systems中
-
Bound inference。边界推断用于确定迭代器的边界。虽然DL编译器可以方便地描述输入和输出,但也给边界推断带来了挑战。边界推断根据计算图和已知的占位符,通常会递归和迭代地去执行。例如在TVM中,迭代器构成一个无环超图,图中每个节点表示了一个迭代器,每个超边表示了两个或多个迭代器的关系(split、fuse或rebase)。一旦根迭代器由占位符的形状确定之后,其他的迭代器可以通过这些关系递归地确定。
算子支持
- 算子通常包括代数算子(例如+,exp和topK),神经网络算子(conv、pooling),张量算子(reshape,resize和copy),广播和规约算子(min和armin),以及控制流算子(条件和循环)。
- Broadcast。广播算子可以复制数据并产生一个有新形状的数据。如果没有广播算子,输入张量的形状将更加严格。例如加法算子,输入的张量应当是相同的形状,一些编译器例如XLA和Relay放松了这种约束,通过广播算子复制达到相同的形状。
- Control flow。控制流在复杂模型中是必需的。例如RNN和强化学习模型需要递归的关系,以及数据条件执行。如果DL编译器不支持,则需要host语言进行控制(Python的if和while),或者静态展开,降低了计算的效率。Relay注意到任意的控制流都可以被递归和模式进行实现,类似于函数式编程。因此,它提供了if算子和递归函数来实现控制流。XLA通过特定的XLO算子例如while和conditional来表示控制流
- Customized operators。允许开发者自定义算子。提供自定义算子的支持能提高DL编译器的可扩展性。例如在Glow中,开发者需要实现逻辑和节点的封装,并且转为低级代码的步骤,算子IR的构建,指令的构建有时也需要实现。而TVM和TC只需要更少地工作,TVM只需要描述计算和调度,然后生命输入输出张量的形状。自定义的算子将通过hooks自动与Python函数整合,减少了开发者的负担。
小结
几乎所有的DL编译器有独特的高级IR设计,但有着相似的设计哲学,例如使用DAG图和let-binding来构建计算图。并且提供了简洁的方式定义张量的计算。数据和算子在高级IR中的设计是可扩展的,以支持不同的DL模型。更重要的是高级IR是硬件无关的,所以可以适用于不同的硬件后端。
Low-level IR
Low-level IR的实现
Low-level IR更细粒度地描述了DL模型,通过提供调优计算和内存访问的接口,可以进行硬件相关的优化。Low-level IR可以分为三类:Halide-Based IR,ployhedral-based IR和其他unique IR
Halide-based IR
- Halide最初是在并行图像处理中提出的,后来在DL编译器中有很好地扩展性。Halide的设计哲学是将计算和调度分离。编译器采用Halide尝试多种可能的schedule,并选择其中最好的一种。内存访问边界和循环在Halide中有轴对齐的严格边界限制。因此,Halide不能表示一些复杂的计算(non-rectangular),幸运的是,深度学习的计算通常都是矩形的,可以用Halide完美地表示。并且Halide能够将这些边界参数化并暴露给tuning机制。当应用在DL编译器中时,Halide原始的IR需要修改,例如Halide输入的形状是不固定的,而DL编译器需要知道数据的形状,从而将算子映射到硬件后端。一些编译器,例如TC,需要固定的数据,来保证张量数据更好的局部性。
- TVM在Halide IR上进行了改进。去除了对于LLVM的依赖,并重构了项目的结构和Halide IR的设计,选择Python作为前端语言。可重用性提升,通过实时分配机制来便捷地添加自定义算子。简化了变量的定义,由原来的字符串匹配改为指针匹配,保证了每个变量由独自的定义位置(static single-assignment,SSA)
Polyhedral-based IR
- 多面图模型是DL编译器中的重要技术。它使用线性编程,仿射变换和其他的一些数学方法,使用静态的控制流和分支来优化循环代码。与Halide不同,内存的边界和嵌套循环可以像多面体一样有任意形状。这种灵活性让多面体模型在通用编译器中广泛使用。但是这种灵活性也阻碍了调优。TC和PlaidML(nGraph的后端),采用多面体模型作为它们的低级IR,能够应用多面体变换(fusion,tiling,sinking,mapping),包括设备无关和设备相关的优化。有许多工具链可以使用,例如isl,Omega,PIP,Polylib,PPL。
- TC有着独特的低级IR设计,组合了Halide和多面体模型。它使用基于Halide的IR表示计算,使用多面体模型表示循环结构。TC通过抽象的实例和节点类型避免了具体的计算。使用domain节点指定索引变量的范围,使用context节点描述与硬件关联的新的迭代变量。使用band节点指定迭代的顺序。filter节点表示迭代器和一个实例声明相关。Set和sequence关键字表示特定的执行类型(filter的并行和串行)。使用extension节点描述了其他代码生成需要的指令,例如内存搬运。
- PlaidML使用多面体IR(Stripe)来表示张量计算。创建了层次化的并行代码,扩展了多级嵌套并行的多面体块。并且允许多面体作为嵌套循环的内存单元被分配,提供了一种计算和内存层次匹配的方法。在Stripe中,硬件的配置和kernel代码是无关的,Stripe中的tags(其他编译器中的passes)不改变kernel的结构,但提供了额外的硬件信息,有利于优化passes。Stripe切分DL算子到tiles,从而符合硬件资源
Other unique IR
- 一些IR既没有使用Halide,也没有使用多面体模型。在这些低级IR中,他们应用硬件相关的优化,然后转换成更低级的LLVM IR。
- Glow的低级IR是基于指令的表达式。通过地址寻找张量进行计算,Glow的基于指令的函数有两种,declare和program。第一个声明了固定的内存区域,在程序运行期间使用(input、weight、bias)。第二个是本地分配的区域、函数(conv、pool)的集合,还包括临时变量。指令在全局内存区域或本地内存区域中运行,每个操作数使用注解来量化。@in表示操作数从缓冲区读取,@out表示写入缓冲区,@inout表示缓冲区读写。这些指令和操作数量化帮助Glow确定何时能够进行内存的优化。
- MLIR受到LLVM影响很大。与LLVM它是更纯粹的编译基础设施,重用了LLVM中许多思路和接口,在模型表示和代码生成之间。MLIR有灵活的类型系统,能够进行多级别的抽象,引入dialects来表示这种多级别的抽象。每个dialect由一系列不可变的操作组成。当前MILR的dialects包括TensorFlow IR,XLA HLO IR,试验阶段的polyhedral IR,LLVM IR和TensorFlow Lite。在dialects之间可以进行转换。MLIR还可以创建新的dialects来连接新的low-level编译器,为硬件开发者和编译器研究员搭建了桥梁。
- XLA的HLO IR既可以认为是high-level IR,也可以认为是low-level IR,因为HLO足够细粒度来表示硬件相关的信息,并且HLO支持硬件相关的优化,可以用于启动LLVM IR。
Low-level IR的代码生成
大多数DL编译器使用的low-level IR将最终被转换成更低级的LLVM IR,使用LLVM成熟的优化器和代码生成器。LLVM还可以根据专门的加速器设计定制的指令集合。但是传统的编译器可能会生成较差的代码,如果直接传给LLVM IR。为了避免这种现象,DL编译器采用两种方式来进行硬件相关的优化。
- 执行目标硬件的循环优化,在LLVM IR之上进行(Halide-based IR和polyhedral-based IR)
- 为优化passes提供额外的目标硬件信息。多数DL编译器可以同时使用这两种方式,但是重点不同。通常来说DL编译器更喜欢前端用户(TC,TVM,XLA,nGraph)将重点放在第1点,其余偏向后端开发者(Glow,PlaidML,MLIR)注重第2点
编译的方案可以分为两个类型,just-in-time(JIT)和ahead-of-time(AOT)
- JIT编译器,能够利用运行时的信息优化代码。
- AOT编译出所有的可执行二进制文件,然后执行,因此需要进行更大的静态分析范围,可以用于嵌入式的交叉编译(C-GOOD),并可以在远程机器上执行(TVM RPC)
小结
DL编译器中,low-level IR足够细粒度来表示DL模型,并且能反映不同的硬件,low-level IR包括Halide-based IR,polyhedral-based IR和其他unique IR。虽然它们设计上不同,但都利用了成熟的编译器工具链和基础设施,提供了专门的硬件优化和代码生成接口。low-level IRs的设计也会受到新的DL加速器的影响。(TVM Halide IR和Inferentia,XLA HLO和TPU)
前端优化
创建了计算图之后,前端进行图级别的优化,许多优化更容易在图级别进行,因为图级别提供了计算的全局信息,这些优化只能在计算图中使用,而不能在后端实现,所以是硬件无关的,可以在不同硬件后端使用。
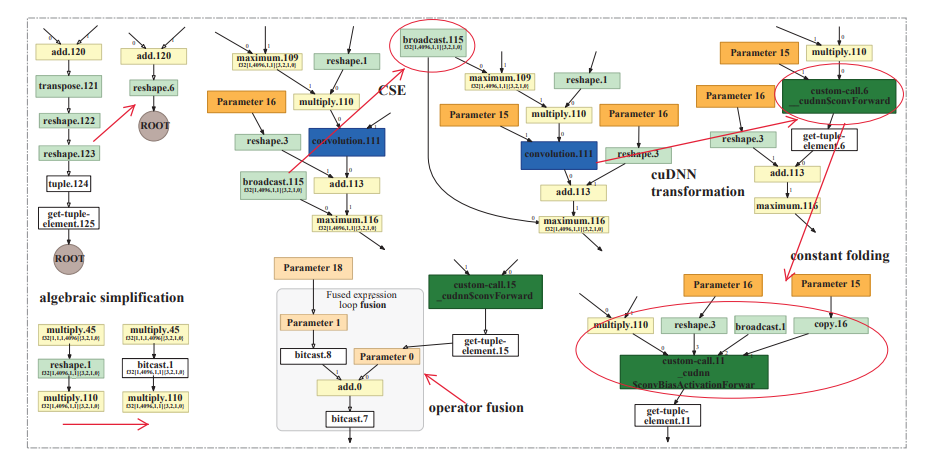
前端优化通常用passes定义,然后通过遍历计算图中节点来执行图变换。前端提供方法。
- 捕捉特定的计算图中的特征
- 重写计算图进行优化
通过预定义passes,开发者可以在前端定制pass,DL模型被转换为计算图后,大多数DL编译器可以决定每个算子的输入和输出张量形状。这个特性是的DL能够根据这些信息进行优化。图中展示了Tensorflow XLA的计算图优化。
可以将前端优化分为三类,节点级别、块级别(peephole,local)、数据流级别(global)。
Node-level
计算图的节点粒度足够粗,所以可以在单个节点上进行优化。包括节点消除,删除无用的节点。节点替换,使用开销更小的节点进行替换。
在通用编译器中,Nop消除,去除了no-op指令。在DL编译器中,Nop消除对应着消除那些缺少对应输入的操作。例如sum节点只有一个输入tensor,可以被消除。padding节点只有zero padding width,可以被消除。
zero-dim-tensor消除对应着去除那些张量维度是0的tensor。假设A是0维张量,B是常数张量,则A和B的sum操作可以被替换成已有的常量节点B,不产生其他错误。假设C是3维张量,但是其中一维的形状是0,例如[0,2,3],则C中没有数据,argmin、argmax操作可以消除。
Block-level
代数化简
- 代数化简包括代数识别、长度规约,将开销高的算子替换为开销低的算子、常量折叠,用值替换常量表达式。这些优化考虑一系列节点,使用交换律、结合律和分配律等方式简化计算。
- 典型的算子中(add,mul),代数化简也可以用作DL特定的算子(reshape,transpose,pooling)。算子可以被重排序之后消除,减少了冗余,提升效率。有一些方法可以使用
- 优化计算顺序。例如通用矩阵乘法GEMM,两个矩阵,都进行转置之后再相乘,但一种更简洁的方式是交换A和B变量的位置,然后相乘,将结果进行转置。将两次转置减少为一次。
- 优化节点组合。一些计算包括连续的转置节点,如果没有移动数据,将这些节点用reshape代替。
- 优化ReduceMean节点。将ReduceMean用AvgPool节点替换(Glow),如果输入规约算子是4D张量,并且最后两个维度需要被规约。
算子融合
- 算子融合是DL编译器必不可少的优化。消除中间变量的内存分配,维进一步优化提供可能(loop nests),减少了kernel launch和overhead的同步。在TVM中,算子被分为4类,injective、reduction、complex-out-fusible,和opaque。当算子确定时,他们对应的类型也确定了。针对这些类型,TVM设计了算子间的融合规则。在TC中,融合基于自动化多面体转换进行。但如何识别和融合更加复杂的计算图模式,例如多个广播和规约算子,仍然是个问题。一些研究提出了更加激进地优化策略,不仅支持element-wise和reduction节点,同时能处理计算、方寸密集的算子。
operator sinking
- 这个优化将算子计算下沉,例如计算后的转置,batch normalization,ReLU,sigmoid,channel shuffle。一些类似的计算靠的更近,为代数化简提供可能。
dataflow-level
公共子表达式消除(CSE)
- 表达式E是公共子表达式,当E之前被计算过,并且E的值在之前的计算中没有改变。在这种情况下,E的值计算一次,可以在其他地方直接使用。DL编译器通过全局计算图搜索公共子表达式,用之前计算的结果替换公共子表达式。
死代码消除(DCE)
- 如果计算结果或者副作用没有被使用到,则这些代码是死代码。通常死代码不是由开发者造成的,而是由于其他图优化产生的。因此,DCE和CSE通常在其他图优化后使用。一些其他的优化,例如dead store elimination(DSE),消除张量中的存储,也属于DCE。
static memory planning
- 静态内存规划优化尽可能重用内存缓冲区。通常由两种方式,in-place内存共享和标准内存共享。in-place内存共享对算子的输入和输出使用相同的内存,仅在计算前分配一份内存的拷贝。标准内存共享在不和上一个算子产生重叠(overlapping)的情况下重用内存。静态内存管理是离线进行的,所以可以使用一些更复杂的算法。最近的研究首先设计了memory-aware的调度,减少了memory footprint和边缘设备活跃的峰值。提出了一种在内存有限的设备的内存规划的新的研究方向。
layout transformation
- 布局转换尝试找到最好的布局来存储张量,然后在计算图中插入布局转换节点。注意到实际的转换并不会执行,只是在编译器后端evaluating计算图的时候执行。
- 相同算子使用不同的数据布局执行性能不同,每种硬件的最好的布局也不同。例如算子使用NCHW在GPU上通常运行更快(TensorFlow),一些DL编译器依赖硬件专用的库来获得更高的性能,这些库需要特定的布局。一些DL加速器使用复杂的布局更加有利(tile)。边缘设备通常有异质计算单元,不同的单元可能需要不同的数据布局,所以数据布局转换需要仔细考虑。编译器需要能够针对多种硬件执行数据布局转换。
- 不仅数据布局会对最终的性能产生影响,转换操作的开销也很大,因为同样消耗内存和计算资源。
- 最近的研究基于TVM,在CPU上将所有的卷积改变成NCHW[x]c的布局,c表示channelC划分的子维度,x表示划分子维度的大小。然后所有的x在硬件相关的优化步骤中,通过提供的硬件信息(cache line大小,向量化单元大小,访存模式)自动调优得到。
小结
前端是DL编译器最重要的组件,需要把DL模型转换成high-level IR(例如计算图),根据high-level IR进行硬件无关的优化。虽然在前端的实现上,不同的DL编译器的数据表示、算子定义可能有所不同,但硬件无关的优化都能分为三个级别:node-level,block-level,dataflow-level。在每个级别上的优化需要通用编译优化和深度学习编译的技术,在计算图级别减少计算的冗余,提高模型的性能。
后端优化
DL编译器后端通常包括多种硬件相关的优化,自动调优技术,优化的算子库。硬件相关的优化能对不同的硬件后端生成高效的代码。自动调优技术是必不可少的,能够减少手工劳动,导出最佳的参数配置。高度优化的算子库在通用处理器和定制的深度学习加速器上广泛使用。
Hardware-specific Optimization
硬件相关优化,也叫作目标相关优化,针对特定的硬件获得高性能代码。一种后端优化的实现方式是讲low-level IR转换成LLVM IR,利用LLVM基础设施生成优化的CPU、GPU代码。另一种方式是使用DL的知识,设计定制的优化,更充分地利用硬件性能。由于硬件相关的优化针对特定的硬件有所不同,不能在本文中详尽阐述,只列举现有DL编译器中广泛使用的5种方法。

Hardware intrinsic mapping
- 张量指令映射能够将low-level IR的一部分指令映射到硬件已经高度优化的kernel上。在TVM中,硬件指令映射通过可扩展的张量化实现,声明硬件指令的行为和指令映射的转换规则。这种方法使得编译器后端能够使用多种硬件的实现,包括高度优化的micro-kernels,获得极大的性能提升。Glow也支持硬件指令映射,例如量化,能够估计每个阶段神经网络的数值范围,并且通过信息来指导自动量化。Halide/TVM将特定的IR模式在不同体系结构上映射到SIMD算子代码上,避免特定向量组合时LLVM IR映射低效的问题。
Memory allocation and fetching
- 内存分配是代码生成中的另一个挑战,是GPU和定制加速器必不可少的步骤。例如,GPU包括共享内存空间(更低的访存延迟,内存大小有限)。这种内存层次需要高效的内存分配和访存技术来提高数据的局部性。为了实现这种优化,TVM引入了memory范围的schedule概念,memory scope schedule primitive能够给计算阶段打上标签,例如shared或者thread-local,对于shared标签的计算阶段,TVM使用共享内存分配和cooperative data fetching,在代码的特定位置加入memory barrier保证正确性。除此之外,TC也提供了类似的特性(memory promotion),扩展了PPCG编译器。但是TC编译器只支持有限的预定义规则。TVM还支持通过内存范围调度指令在加速器指定位置缓存。
Memory latency hiding
- 内存延迟隐藏通过重排序执行流水线,是后端的一个重要技术。多数DL编译器支持CPU和GPU上的并行化,内存延迟隐藏能由硬件自然地实现(GPUwarp上下文切换),但是对于TPU之类的加速器使用decoupled access-excute(DAE)体系结构,后端需要执行schedule,进行细粒度的同步来获得正确高效的代码。为了达到更好的性能并减少编程的负担,TVM引入了virtual threading调度原语,使得用户呢能够在虚拟多线程体系中指定数据并行方式。然后TVM通过加入必要的memory barriers,将这些线程的指令交错在一个指令流中,将虚拟线程转换成更low的步骤。每个线程实现了延迟隐藏,得到了更优的执行流水线。
Loop oriented optimizations
- 循环优化。由于Halide和LLVM(整合了polyhedral方法)已经合并了这些优化技术,一些DL编译器在它们的后端使用Halide和LLVM。循环优化的关键技术包括循环融合,滑动窗口,分块,循环重排序,循环展开。
- Loop fusion:循环融合将相同边界的循环融合,获得更好的数据重用,对于PlaidML,TVM,TC和XLA,这种优化是通过Halide schedule或polyhedral方法执行的,Glow通过自己的operator stacking进行实现。
- Sliding windows:滑动窗口是Halide采用的一种优化技术。核心思想是在运行时计算并存储需要的值,直到这些值不再需要。滑动窗口可能涉及到两个循环的计算,使得它们串行化,所以是并行和数据重用之间的tradeoff。
- Tiling:分块将循环分为数个块,循环可以分为外层遍历每个tile,内层遍历tile的内部。这种转换通过将一个tile适配硬件的cache获得更好的性能。由于tile的大小和硬件是相关的,很多DL编译器通过auto-tuning来决定tile的模式。
- Loop reordering:循环重排序改变嵌套循环中迭代的顺序,能够优化访存,提高局部性。与数据布局和硬件特性相关,但是当迭代顺序有依赖时,执行循环重排序是不安全的。
- Loop unrolling:循环展开,使用数个循环体的复制来代替特定的循环,帮助编译器进行更激进的指令级别的并行。通常与循环分割组合使用,首先将循环分为两个嵌套的循环,然后将内层循环展开。
Parallelization
- 现代处理器支持多线程和SIMD并行,编译器后端需要利用并行最大限度使用硬件,获得高性能。Halide使用schedule primitive,称为parallel来指定线程级循环并行的维度,支持GPU的并行,通过使用block和thread的注解和标记parallel。使用n-wide向量语句代替循环次数n,利用硬件指令映射能够映射到硬件的SIMD代码上。Stripe开发了nested polyhedral model,是多面体模型的变体。引入了parallel polyhedral block作为它在循环中的基本执行元素。通过这种扩展,嵌套多面体模型能够检测到tiling和strding中分层的并行级别。一些DL编译器依赖手工库,例如Glow或者其他硬件供应商提供的优化的数学库。Glow将向量化的过程利用LLVM实现,因为LLVM auto-vectorizer在张量的维度和loop trip count提供的情况下能够很好地工作。但是,完全由编译器后端实现并行需要使用更多的深度学习知识,需要更多工程上的努力。
Auto-tuning
由于硬件相关的参数调优组成了巨大的搜索空间,有必要使用自动调优来决定最优的参数配置。TVM,TC和XLA支持自动调优,通常自动调优的实现包含4个关键组件,parameterization,cost model,searching technique and acceleration
- Parameterization
- Data and target:数据参数描述了指定的数据,例如输入形状。目标参数描述了硬件相关的特性和限制,在优化的schedule和代码生成中被使用。例如,对于GPU目标,硬件的参数例如共享内存和寄存器大小需要被指定。
- Optimization options:优化选项包括优化scheduling和对应的参数,例如循环优化和分块大小。在TVM中有预定义和用户定义的scheduling,以及参数,将被考虑。而TC和XLA进行参数化优化,与性能有更强的相关性,并且之后能以更小的代价进行修改。例如minibatch维度通常是参数中用来映射CUDA的gird维度,可以通过自动调优优化。
- Cost model:
- 黑盒模型:这个模型只考虑最终的执行时间,不考虑其他编译任务的特性,构造黑盒模型比较简单,但没有任务的特性信息执行时间很长,优化效果也不好。
- 基于机器学习的代价模型:基于机器学习的代价模型是一种统计方法,使用机器学习方法预测性能。在搜索过程中更新配置,帮助模型达到更高的准确度。TVM和XLA使用这种模型。例如,gradient tree boosting model(GBDT)和feedforward neural network(FNN)。
- 预定义代价模型:一个预定义代价模型理论上效果最好,因为能够利用编译任务的特性,评估所有任务的性能,相比于机器学习模型,与定义模型产生更少的配置,但对新的DL模型和硬件,需要较多的工程上的努力。
- Searching technique
- 初始化和搜索空间的确定:初始的操作是随机的或基于已知的配置,例如用户提供的或者历史最优配置。搜索空间应当在自动调优开始前被指定。TVM需要开发者使用领域知识指定搜索空间,并提供针对每种硬件的搜索空间提取。与之不同,TC依赖编译的cache和预定义规则。
- Genetic algorithm(GA):遗传算法将每个调优参数作为基因,每种配置作为候选者,新的候选者通过交叉、排序等方法迭代获得,根据健康值选择,这种方法受到自然选择的启发,最终导出最优的参数配置。交叉、排序的比例和选择方法用来控制搜索与开发的权衡。TC使用GA作为自动调优技术。
- Simulated annealing algorithm(SA):模拟退火算法受到退火过程的启发,允许一种坏情况有可能性减少,可以找到近似的全局最优解,避免精确的局部解。TVM使用SA作为自动调优技术。
- Reinforcement learning(RL):RL学习能够获得最大奖励的方法,Chameleon(在TVM基础上开发的)使用RLRL作为自动调优技术。
- Acceleration
- Parallelization:加速自动调优的一个方向是并行化,TC提出了多线程、多GPU策略,因为遗传算法需要在每一代中评估所有候选者。首先输入候选者的配置,然后将它们编译到多个CPU线程上。生成的代码通过GPU并行评估,每个候选者根据父辈的选择步骤有自己的健康值。完成整个评估之后,一个新的候选者将生成,然后新的编译工作输入,等待CPU上的编译。TVM支持交叉编译和RPC,允许用户在本地机器编译,在多个不同目标机器上使用不同的自动调优策略来运行程序。
- Configuration reuse:另一个方向是重用之前的自动调优配置。TC存储已知最快的生成代码版本,与编译cache中给定的配置对应。cache在每个kernel优化之前查询,如果cache miss,将执行自动调优。TVM创建log文件来存储所有scheduling算子最优的配置,编译过程中查询log文件得到最优配置。值得一提的是TVM为Halide IR(例如conv2d)中的每个算子执行自动调优,所以每个算子的最优配置是独立得到的。
优化算子库
有许多高度优化的算子库被不同硬件广泛使用。Intel的DNNL(之前是MKL-DNN),NVIDIA的cuDNN,AMD的MIOpen,都广泛使用。计算密集指令(convolution,GEMM和RNN)和访存密集指令(batch normalization,pooling,shuffle)都根据硬件特性(AVX-512 ISA,tensor cores)高度优化。支持定制的数据布局,整合DL应用时不需要过多的布局转换。同时还支持低精度训练和推理,包括FP32,FP16,INT8和non-IEEE,floating-point format bfloat16,其他定制DL加速器也有各自的算子库。
现有的DL编译器例如TVM,nGraphTC能够将函数调用在代码生成阶段创建这些库。但是如果DL编译器需要利用已有的优化算子库,首先应当转换数据布局和融合至这些算子库预定义的风格上。这种转换可能破坏最优的控制流。并且DL编译器将算子库当做黑盒对待,所以不能在这些算子中执行优化策略。总体的说,当计算高度满足特定的优化指令时,使用可以获得很好的性能,否则将会限制进一步的优化空间。
小结
后端需要根据low-level IR进行硬件相关的代码优化和代码生成,虽然low-level IR的设计不同,但都可以认为是代码相关的优化:自动调优技术,优化的算子库。这些优化能够独立或组合执行,通过搜索硬件和软件的特性,来获得更好的数据局部性和并行可能。最后,low-level IR将根据不同硬件的实现转换为高效的代码。
DL编译器的分类
主要针对TVM,nGraph,Tensor Comprehension(TC),Glow和XLA,从前端、IR和优化四个方面进行分类。
评估
进行了一系列对比实验
结论和未来展望
分析了DL编译器的设计原则,指出未来DL编译器可能的发展方向
Dynamic shape and pre/post processing
- 动态模型在深度学习领域越来越常见,输入形状甚至模型本身可能在执行过程中改变。特别是在NLP方向,模型能接受多种形状的输入,这是DL编译器面临的挑战,因为数据的形状只能在运行时得到。现有的DL编译器需要更多的研究以支持动态形状和新出现的动态模型。
- 当未来的DL模型越来越复杂,它们的control flow不可避免地会包括复杂的预处理和后处理过程。目前大多数DL编译器使用Python作为编程语言,预处理和后处理过程可能会成为性能的瓶颈,因为Python解释器的执行较慢。
Advanced auto-tuning
- 现有的自动调优技术聚焦于优化独立的算子,但是局部最优的组合不一定能达到全局的最优。例如两个相邻算子使用不同的数据布局被一起调优,但是没有引入额外的内存转换。并且当计算边的数量增长,执行时间不止受到优化目标的影响。新的优化目标应当在自动调优过程中被考虑,例如memory footprint和energy consumption。
- 特别的,对于基于机器学习的自动调优技术,有几个未来研究的方向。
- 机器学习技术可以在自动调优的其他阶段使用,不只是代价模型,例如在选择编译器操作和schedule优化时,机器学习技术能够用于预测可能性,决定最终的配置。
- 基于机器学习的自动调优技术还能进一步优化,例如加入特征工程(特征选择来表示程序),在自动调优技术中可能取得更好的效果。
Polyhedral model
- 将多面体模型和自动调优技术组合起来,取得更好地效果。一方面自动调优能够重用之前的配置,最小化多面体JIT编译的开销。另一方面多面体模型能够用作执行auto-scheduling,减少auto-tuning的搜索空间。
- 另一个挑战是应用多面体模型如何支持稀疏张量。通常稀疏张量例如CSF用索引矩阵表示循环(a[b[i]]),已经不是线性的形式。这种简洁的索引寻址导致非线性的下标表达式和循环边界。导致多面体的循环优化无法使用。幸运的是,多面体社区已经在支持稀疏张量方面做了很多努力,整合了最新的多面体模型能够提升DL编译器的优化性能。
Subgraph partitioning
- DL编译器支持子图划分,将计算图划分为多个子图,子图可以使用不同方式处理。
- 打开了图算子库优化的可能性,以nGraph和DNNL为例,DNNL使用凸优化生成了许多高度优化的kernel,将DNNL与nGraph整合能加速nGraph产生子图的执行性能。
- 打开了异质和并行执行的可能性,一旦计算图被划分为多个子图,执行不同的子图可以安排在异质的硬件上。例如边缘计算设备,它的计算单元可能包括ARM CPU,Mail CPU,DSP和NPU,构建子图能够充分利用所有计算单元。
Quantization
- 传统的量化策略基于固定的策略和数据类型,很少利用不同硬件的信息。支持量化能够在编译过程中更高效的导出量化策略。例如Relay提供了量化重写flow,自动为多种计划生成量化的代码。
- 为了支持量化,有几个挑战需要解决
- 如何用最小的工程量实现新的量化算子,AWS尝试了一种可能的方向,利用dialect从基本算子实现心酸自,能够复用图级别和算子级别的优化。
- 量化和其他优化的交互。例如决定量化的正确阶段,如何与其他优化,例如算子融合共同使用还需要研究
Unified optimizations
- 虽然现有的DL编译器在计算图优化和硬件相关的优化方面采用了类似的设计,但每个编译器有自己的优势。缺少一种方法共享最优的策略,以及这些编译器对新硬件的支持。
- 目前,Google MLIR正在朝着这个方向努力,它提供了多级IR的基础设施,包括了IR的规格和不同级别IR转换的工具箱。还提供了灵活的dialects,每种Dl编译器能够定制high-level和low-level IR。虽然转换是通过dialects,,但一个DL编译器的优化能够被另一个编译器复用。但是这种dialects的转换还需要进一步研究以减少依赖。
Differentiable programming
- 一种编程范式,程序彻底可微。通过可微编程写的算法能够自动微分。许多编译器项目采用了可微编程,例如Myia,Flux和Julia,但是现有的DL编译器对可微编程的支持较少。
- 为了支持可微编程是比较有挑战性的。困难不仅来自于数据结构,还来自于语法。例如为了识别Julia到XLA HLO IR的转换,一个挑战是Julia使用的命令式语言和XLA使用的符号式语言的不同,为了使用HLO IR,编译器需要听Julia操作的抽象,例如MapReduce,broadcast,这种不同需要对编译器设计进行较大的改动。
Privacy protection
- 在边-云计算系统中,DL模型通常被分为两份,在边缘设备和云设备上分别运行,能够获得更小的延迟,消耗更少的贷款。缺点是用户的隐私不安全,原因是空记者能够拦截从边缘设备发送到云的数据,然后使用中间结果来训练其他的模型,窃取隐私信息。
- 为了保护隐私,一些研究提出在中间结果中用统计特征加入噪声,减少攻击者信息的准确性,并且对用户任务影响不大。但是困难在于如何选择哪一层加入噪声,需要大量的工程量来确定最优的位置。
Training support
- 通常来说,DL编译器很少支持模型训练,nGraph只支持在Intel NNP-T加速器上训练,TC只支持单个kernel自动微分,Glow在一些模型上尝试训练支持,TVM对训练支持的特性还在开发中,XLA依赖TensorFlow进行训练。现有DL编译器主要在部署DL模型至多个硬件上做工作,所以推理是主要目标。
参考资料
- Comprehensive Compiler Learning Survey Deepcomprehensive compiler learning survey comprehensive cdeepfuzz compiler learning meta-learning learning survey meta reconstruction learning natural survey detection learning anomaly survey deep-learning deep-learning-based learning deep loss learning smooth deep nature-deep learning nature deep