本文总结自:极客时间韩健老师的分布式协议与算法实战课程。
为什么要学习Paxos算法?其实关于这个问题的答案,每个人有不同的看法。其实对我来说,我认为当前很多常用的共识算法都是基于它改进,我学习它的初衷也是为了更好的去理解Raft算法。如果你想深入理解RAFT算法,博主在这里推荐蚂蚁金服的SOFAJRaft,它是基于JAVA语言开发的一个生产级高性能共识算法实现。
博主总结过一些关于SOFAJRaft的源码,有兴趣的读者可以访问:SOFAJRaft源码阅读。
@Author:Akai-yuan
@更新时间:2023/1/29
1.Basic Paxos
假设我们要实现一个分布式集群,这个集群是由节点 A、B、C 组成,提供只读 KV 存储服务。你应该知道,创建只读变量的时候,必须要对它进行赋值,而且这个值后续没办法修改。因此一个节点创建只读变量后就不能再修改它了,所以所有节点必须要先对只读变量的值达成共识,然后所有节点再一起创建这个只读变量。

1.1三种角色
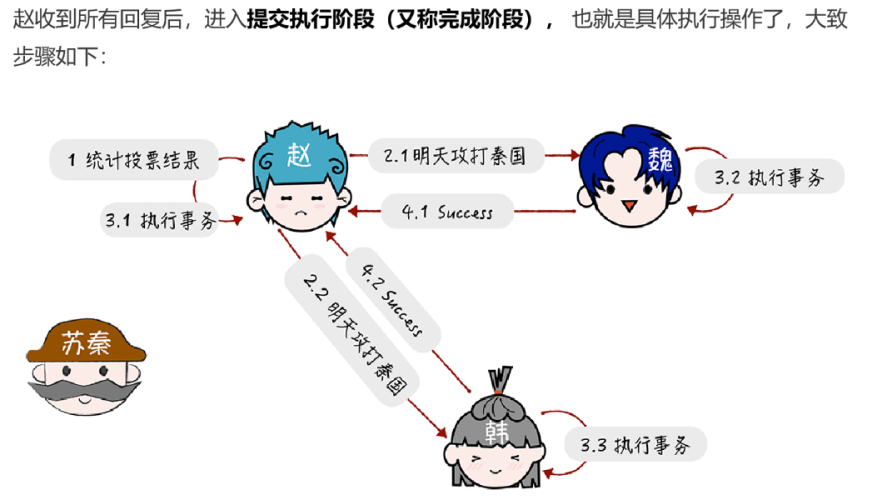
在 Basic Paxos 中,有提议者(Proposer)、接受者(Acceptor)、学习者(Learner)
三种角色,他们之间的关系如下:
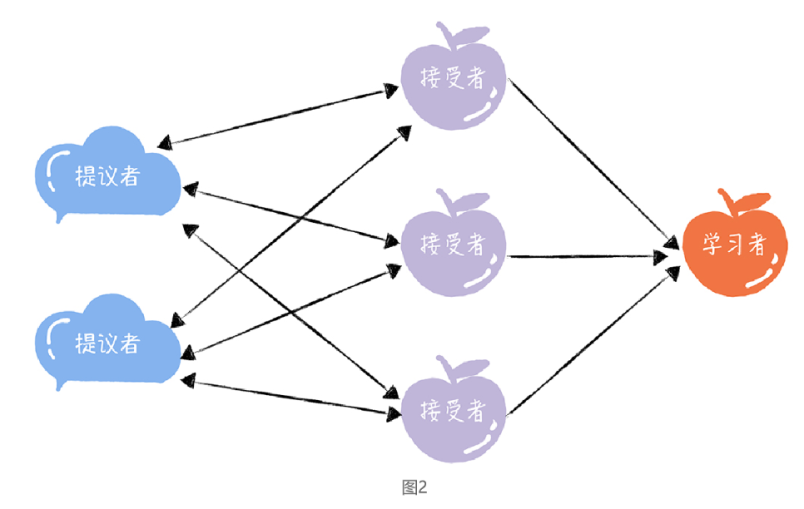
提议者(Proposer):提议一个值,用于投票表决。为了方便演示,你可以把图 1 中的客户端 1 和 2 看作是提议者。但在绝大多数场景中,集群中收到客户端请求的节点,才是提议者(图 1 这个架构,是为了方便演示算法原理)。这样做的好处是,对业务代码没有入侵性,也就是说,我们不需要在业务代码中实现算法逻辑,就可以像使用数据库一样访问后端的数据。
接受者(Acceptor):对每个提议的值进行投票,并存储接受的值,比如 A、B、C 三个节点。 一般来说,集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受和存储数据。
学习者(Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的过程。一般来说,学习者是数据备份节点,比如“Master-Slave”模型中的 Slave,被动地接受数据,容灾备份。
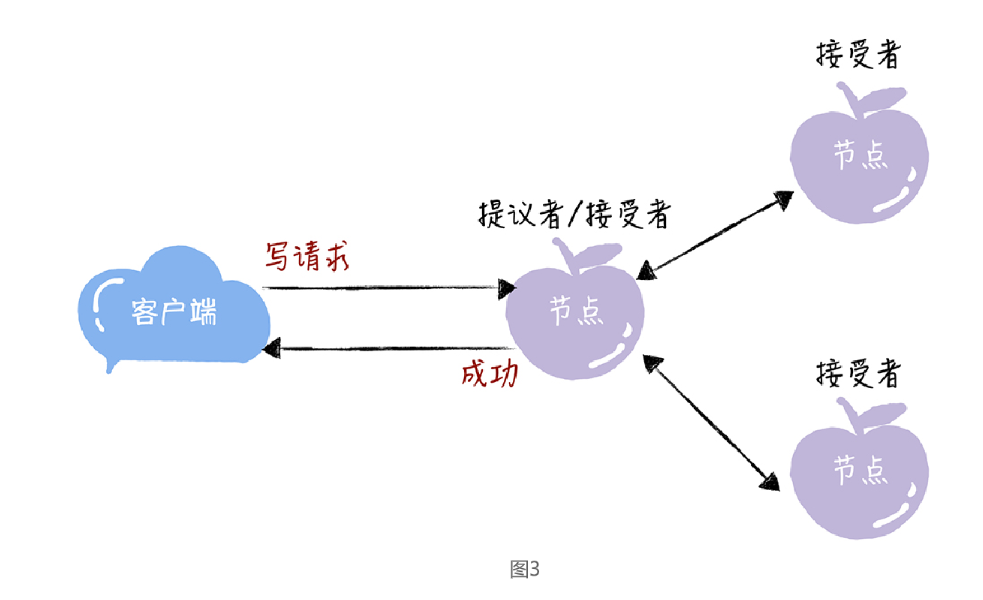
前面不是说接收客户端请求的节点是提议者吗?这里怎么又是接受者呢?
一个节点(或进程)可以身兼多个角色。想象一下,一个 3 节点的集群,1 个节点收到了请求,那么该节点将作为提议者发起二阶段提交,然后这个节点和另外2 个节点一起作为接受者进行共识协商,如下图:
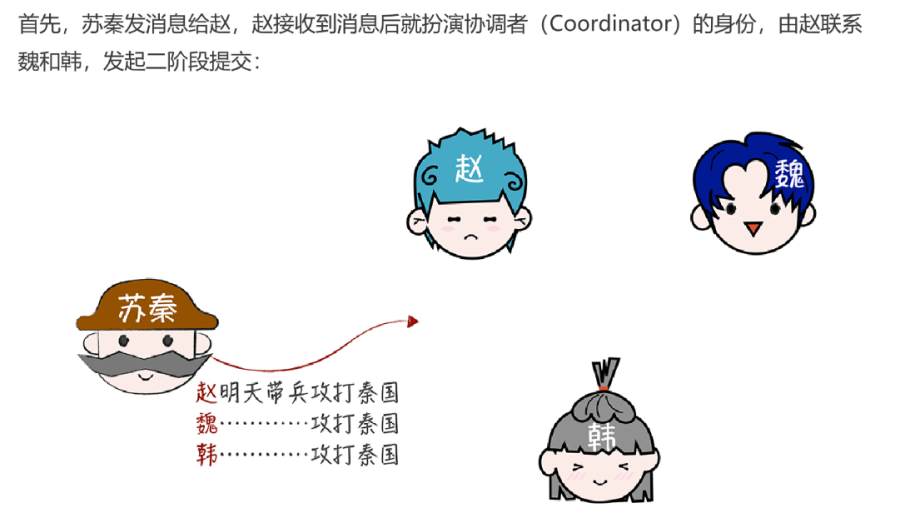
什么是二阶段提交?
在两阶段提交过程中,主要分为了两种角色协调者(coordinator)和参与者(participants),协调者主要就是起到协调参与者是否需要提交事务或者中止事务,参与者主要就是接受协调者的响应并回复协调者是否能够参与事务提交,当接受到协调者提交事务的命令后提交事务等功能。
1.2如何达成共识
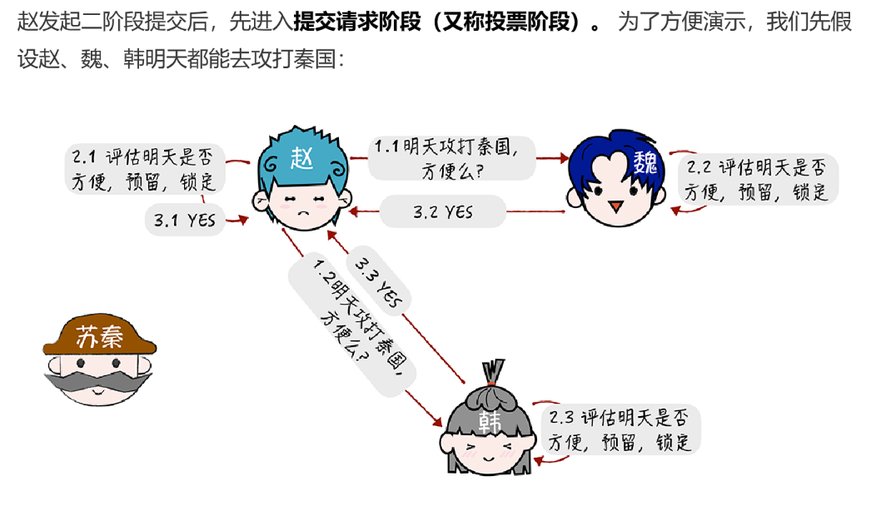
(1)准备阶段
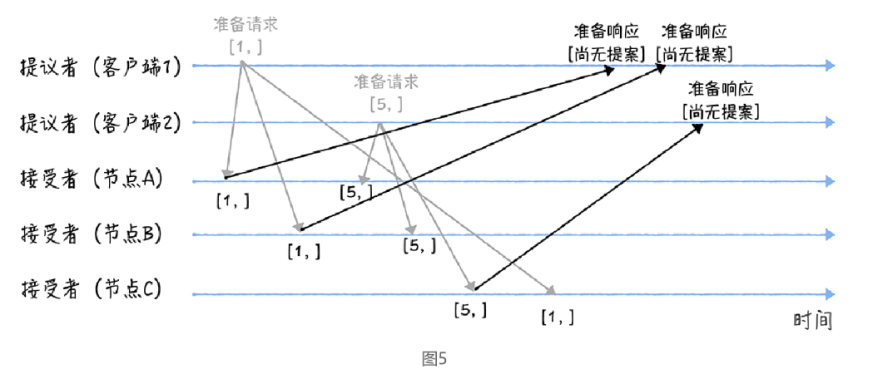
先来看第一个阶段,首先客户端 1、2 作为提议者,分别向所有接受者发送包含提案编号的准备请求:
注意:在准备请求中是不需要指定提议的值的,只需要携带提案编号就可以了

当节点 A、B 收到提案编号为 1 的准备请求,节点 C 收到提案编号为 5 的准备请求后,将进行这样的处理
由于之前没有通过任何提案:
节点 A、B 将返回一个 “尚无提案”的响应。也就是说节点 A 和 B 在告诉提议者,我之前没有通过任何提案呢,并承诺以后不再响应提案编号小于等于 1 的准备请求,不会通过编号小于 1 的提案。
节点 C 也是如此,它将返回一个 “尚无提案”的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案。
继续:
另外,当节点 A、B 收到提案编号为 5 的准备请求,和节点 C 收到提案编号为 1 的准备请求的时候,将进行这样的处理过程:
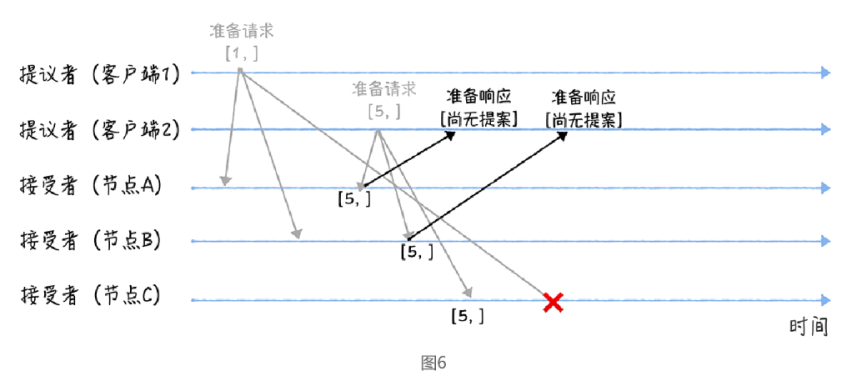
当节点 A、B收到提案编号为 5 的准备请求的时候,因为提案编号 5 大于它们之前响应的准备请求的提案编号 1,而且两个节点都没有通过任何提案,所以它将返回一个 “尚无提案”的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案。
当节点 C收到提案编号为 1 的准备请求的时候,由于提案编号 1 小于它之前响应的准备请求的提案编号 5,所以丢弃该准备请求,不做响应。
(2)接受请求
第二个阶段也就是接受阶段,首先客户端 1、2 在收到大多数节点的准备响应之后,会分别发送接受请求:

当客户端 1 收到大多数的接受者(节点 A、B)的准备响应后,根据响应中提案编号最大的提案的值,设置接受请求中的值。因为该值在来自节点 A、B 的准备响应中都为空(也就是图 5 中的“尚无提案”),所以就把自己的提议值 3 作为提案的值,发送接受请求[1, 3]。
当**客户端 2 **收到大多数的接受者的准备响应后(节点 A、B 和节点 C),根据响应中提案编号最大的提案的值,来设置接受请求中的值。因为该值在来自节点 A、B、C 的准备响应中都为空(也就是图 5 和图 6 中的“尚无提案”),所以就把自己的提议值 7 作为提案的值,发送接受请求[5, 7]。
当三个节点收到 2 个客户端的接受请求时,会进行这样的处理:

当节点 A、B、C 收到接受请求[1, 3]的时候,由于提案的提案编号 1 小于三个节点承诺能通过的提案的最小提案编号 5,所以提案[1, 3]将被拒绝。
当节点 A、B、C 收到接受请求[5, 7]的时候,由于提案的提案编号 5 不小于三个节点承诺能通过的提案的最小提案编号 5,所以就通过提案[5, 7],也就是接受了值 7,三个节点就 X 值为 7 达成了共识。
2.Multi-Paxos
兰伯特提到的 Multi-Paxos 是一种思想,不是算法。而Multi-Paxos 算法是一个统称,它是指基于 Multi-Paxos 思想,通过多个 Basic Paxos实例实现一系列值的共识的算法(比如 Chubby 的 Multi-Paxos 实现、Raft 算法等)
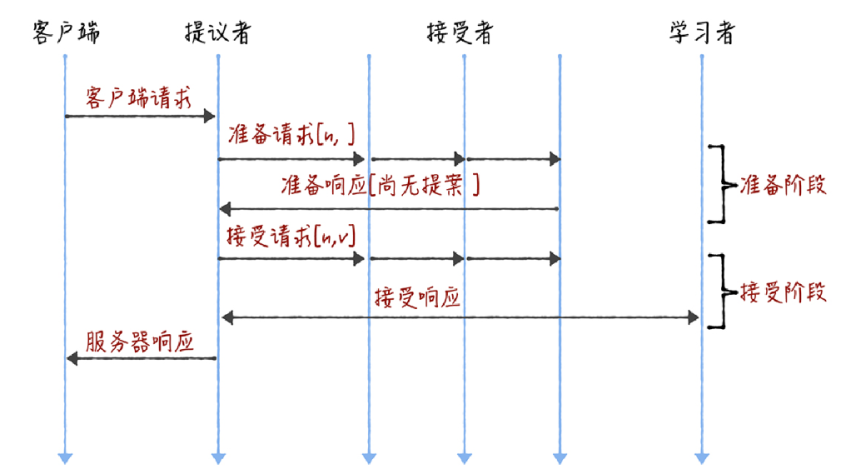
Basic Paxos 是通过二阶段提交来达成共识的。在第一阶段,也就是准备阶段,接收到大多数准备响应的提议者,才能发起接受请求进入第二阶段(也就是接受阶段):
多次执行 Basic Paxos的局限性:
而如果我们直接通过多次执行 Basic Paxos 实例,来实现一系列值的共识,就会存在这样几个问题:
一、如果多个提议者同时提交提案,可能出现因为提案冲突,在准备阶段没有提议者接收到大多数准备响应,协商失败,需要重新协商。你想象一下,一个 5 节点的集群,如果 3个节点作为提议者同时提案,就可能发生因为没有提议者接收大多数响应(比如 1 个提议者接收到 1 个准备响应,另外 2 个提议者分别接收到 2 个准备响应)而准备失败,需要重新协商。
二、2 轮 RPC 通讯(准备阶段和接受阶段)往返消息多、耗性能、延迟大。你要知道,分布式系统的运行是建立在 RPC 通讯的基础之上的,因此,延迟一直是分布式系统的痛点,是需要我们在开发分布式系统时认真考虑和优化的。
如何解决:
引入领导者和优化 Basic Paxos 执行来解决。
2.1Chubby 的 Multi-Paxos实例
首先,它通过引入主节点,实现了兰伯特提到的领导者(Leader)节点的特性。也就是说,主节点作为唯一提议者,这样就不存在多个提议者同时提交提案的情况,也就不存在提案冲突的情况了。
另外,在 Chubby 中,主节点是通过执行 Basic Paxos 算法,进行投票选举产生的,并且在运行过程中,主节点会通过不断续租的方式来延长租期(Lease)。比如在实际场景中,几天内都是同一个节点作为主节点。如果主节点故障了,那么其他的节点又会投票选举出新的主节点,也就是说主节点是一直存在的,而且是唯一的。
其次,在 Chubby 中实现了兰伯特提到的,“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制。
最后,在 Chubby 中,实现了成员变更(Group membership),以此保证节点变更的时候集群的平稳运行。
在 Chubby 中,为了实现了强一致性,读操作也只能在主节点上执行。 也就是说,只要数据写入成功,之后所有的客户端读到的数据都是一致的。具体的过程,就是下面的样子:
所有的读请求和写请求都由主节点来处理。当主节点从客户端接收到写请求后,作为提议者,执行 Basic Paxos 实例,将数据发送给所有的节点,并且在大多数的服务器接受了这个写请求之后,再响应给客户端成功:
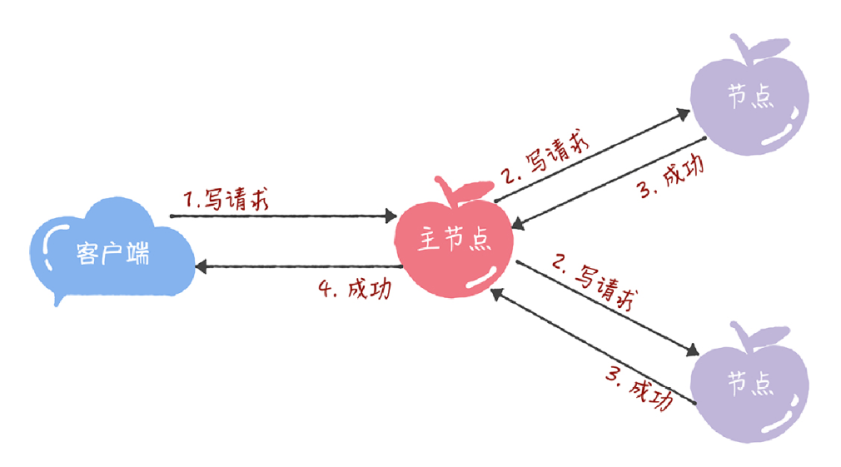
当主节点接收到读请求后,处理就比较简单了,主节点只需要查询本地数据,然后返回给客户端就可以了:

3.内容小结
1.兰伯特提到的 Multi-Paxos 是一种思想,不是算法,而且还缺少算法过程的细节和编程所必须的细节,比如如何选举领导者等,这也就导致了每个人实现的 Multi-Paxos 都不一样。而 Multi-Paxos 算法是一个统称,它是指基于 Multi-Paxos 思想,通过多个Basic Paxos 实例实现一系列数据的共识的算法(比如 Chubby 的 Multi-Paxos 实现、Raft 算法等)。
2.Chubby 实现了主节点(也就是兰伯特提到的领导者),也实现了兰伯特提到的“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段” 这个优化机制,省掉 Basic Paxos 的准备阶段,提升了数据的提交效率,但是所有写请求都在主节点处理,限制了集群处理写请求的并发能力,约等于单机。
3.因为Chubby 的 Multi-Paxos 实现中,也约定了“大多数原则”,也就是说,只要大多数节点正常运行时,集群就能正常工作,所以 Chubby 能容错(n - 1)/2 个节点的故障。
4.本质上而言,“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制,是通过减少非必须的协商步骤来提升性能的。这种方法非常常用,也很有效。比如,Google 设计的 QUIC 协议,是通过减少 TCP、TLS 的协商步骤,优化 HTTPS 性能。我希望你能掌握这种性能优化思路,后续在需要时,可以通过减少非必须的步骤,优化系统性能。