发表时间:2021(ICML 2021)
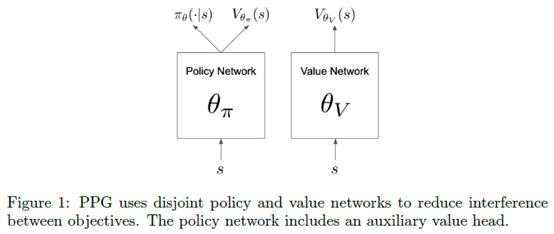
文章要点:这篇文章想说,通常强化都有一个policy网络一个value网络,这两部分要么分开训两个网络,要么合到一起作为一个网络的两个头。分开的好处是policy和value互相不会影响,合到一起的好处是feature是共享的,训练的时候相互之间会帮助训练。另一个观察到的现象是value function通常可以训练更多次,policy function通常只能更新少数几次,分开的好处就是policy和value的训练次数可以分开设置了。作者的想法是,既想共用feature,又不想policy和value之间互相影响彼此。作者提出了Phasic Policy Gradient (PPG)算法,将训练分成两个阶段,第一个阶段(policy phase)训练policy和value,第二个阶段(auxiliary phase)从value function里蒸馏feature。
具体的,PGG有两个网络,一个policy一个value,不过policy的网络也还有一个value的头,用来作为辅助任务来蒸馏value网络的feature。policy phase的训练和PPO一样,只不过policy和value是分开的网络了。优化policy的损失clipped surrogate objective
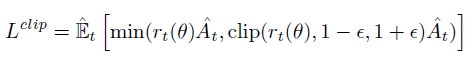
以及value的损失
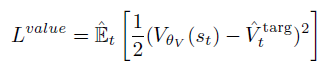
注意这两部分是分开的,所以他俩可以更新不同次数。
然后auxiliary phase的训练任务就是设置辅助任务提取feature,同时保证policy头尽可能不变
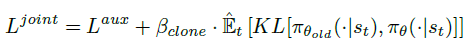
这里的辅助任务其实就是让policy network的value头和value network接近
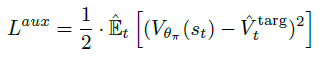
整个算法伪代码如下

就结束了。其他的就是调参了,看分别训练多少次效果最好。最后作者还尝试了一下用一个网络,通过冻结梯度的方式来分成两个训练阶段,然后说效果也比PPO好。
总结:感觉没啥创新,而且效果看起来也就那样吧,一共就跑了3个种子,什么结果都有可能。之前好像读了篇文章引了这个文章,也是这个路子,只不过分开的网络是value,合起来那个分支是advantage(Decoupling Value and Policy for Generalization in Reinforcement Learning)。另外,这篇文章告诉我们的道理就是,不要自己怀疑自己,就是一坨屎也要把它做出来,说不定就中了呢。
疑问:无。
Phasic Policy Gradient
发布时间 2023-04-06 23:45:55作者: initial_h