EfficientNet V2网络
目录
前言
EfficientNet V2是2021年4月份发布的,下图是论文中给出的性能参数。
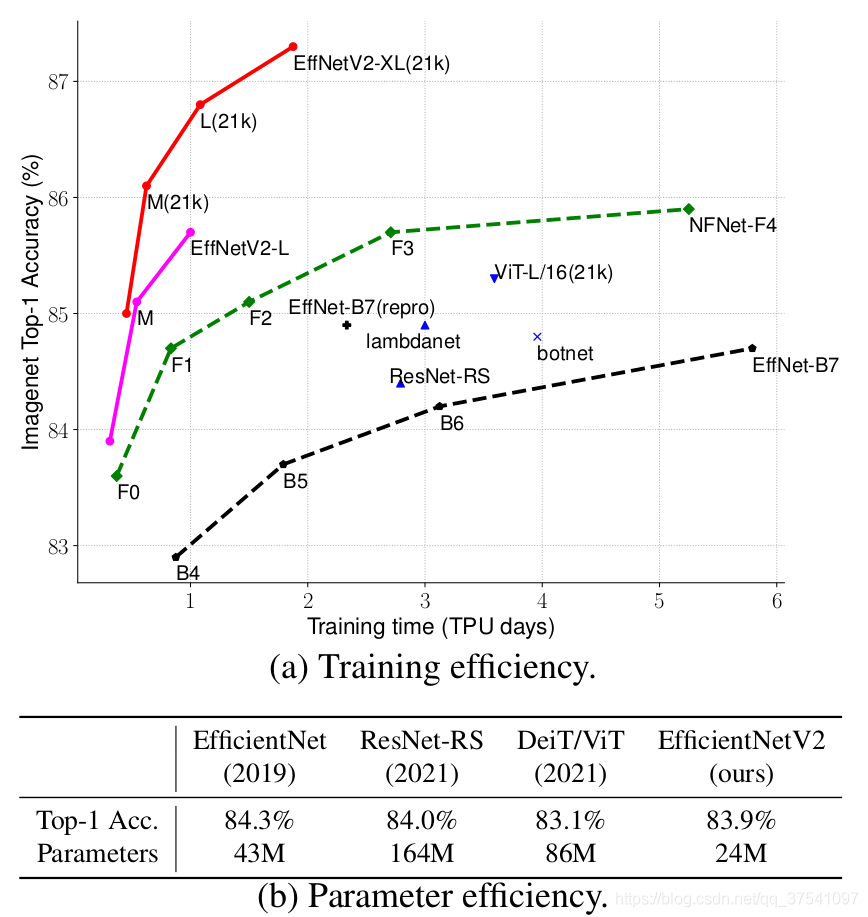
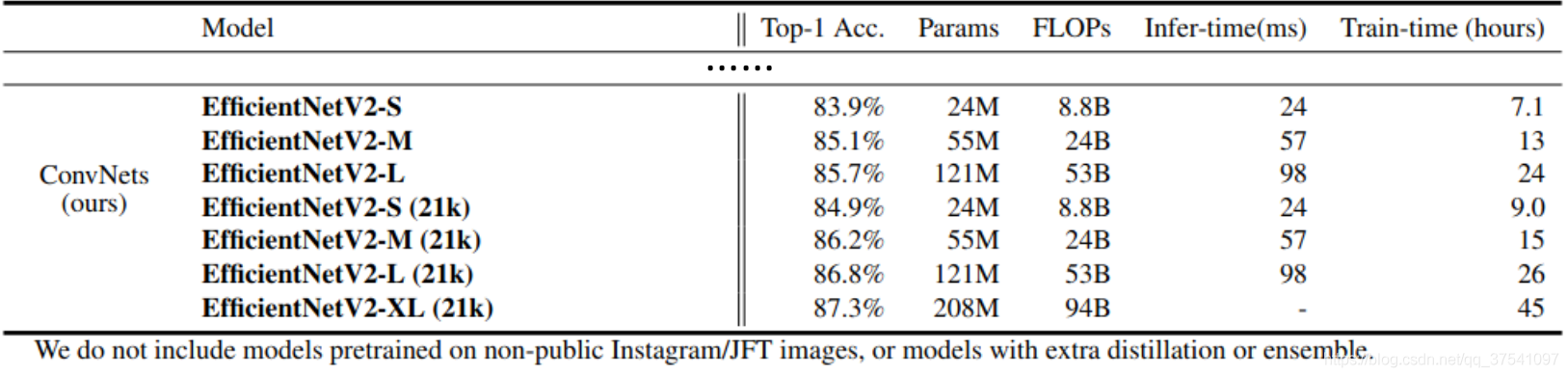
可以看到,EfficientNet V2网络不仅Accuracy达到了当前的SOTA水平,而且训练速度更快参数量更少。

EfficientNet V1中存在的问题
作者系统性的研究了EfficientNet的训练过程,并总结出了三个问题:
- 训练图像的尺寸很大时,训练速度非常慢。
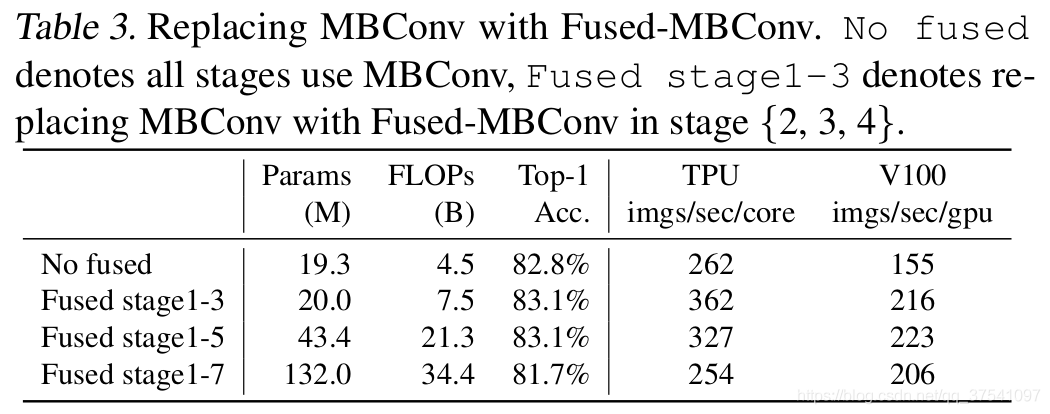
- 在网络浅层中使用Depthwise convolutions速度会很慢。虽然Depthwise convolutions结构相比普通卷积拥有更少的参数一i及更小的FLOPs,但通常无法充分利用现有的一些加速器。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv的结构也很简单,急将原来的MBConv结构住分支中的expansion conv1 x 1和depthwise conv3 x 3替换成一个普通的conv3 x 3。如下如所示:

- 同等的放大每个stage是次优的。在EfficientNet V1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度和参数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在本文中,作者采用了非均匀的缩放策略来缩放模型。
EfficientNet V2中的贡献
- 引入新的网络,该网络在训练速度和参数量上都优于先前的一些网络
- 提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如dropout、data augmentation 和mixup)。通过实验展示了该方法不仅能提升训练速度,同时还能提升准确率
- 通过实验与先前的网络对比,训练速度提升11倍,参数量减少为\(\frac{1}{6.8}\)
网络框架
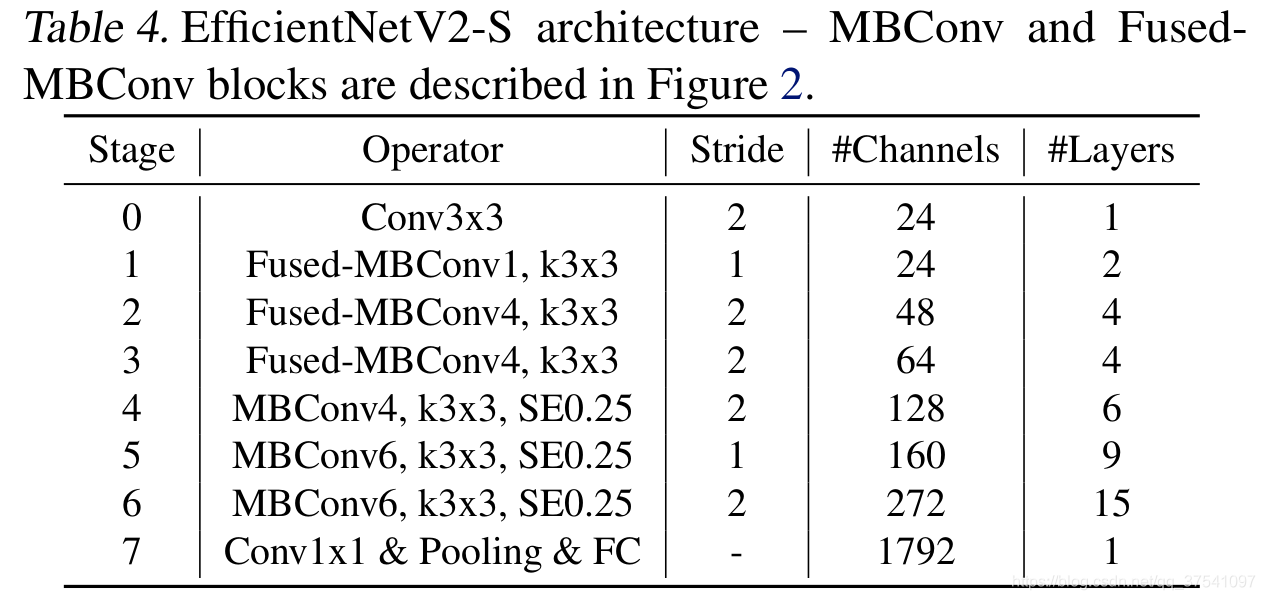
与EfficientV1相比,主要有以下不同:
- V2中除了使用MBConv模块外,还使用了Fused-MBConv模块
- V2中会使用较小的expansion ratio,在V1中基本都是6。这样的好处是能够减少内存访问开销
- V2中更偏向使用更小的kernel_size(3 x 3),在V1中很多5 x 5。优于3 x 3的感受野是比5 x 5小的,所以需要堆叠更多的层结构以增加感受野
- 移除了V1中最优一个步距为1的stage
Progressive Learning渐进学习策略
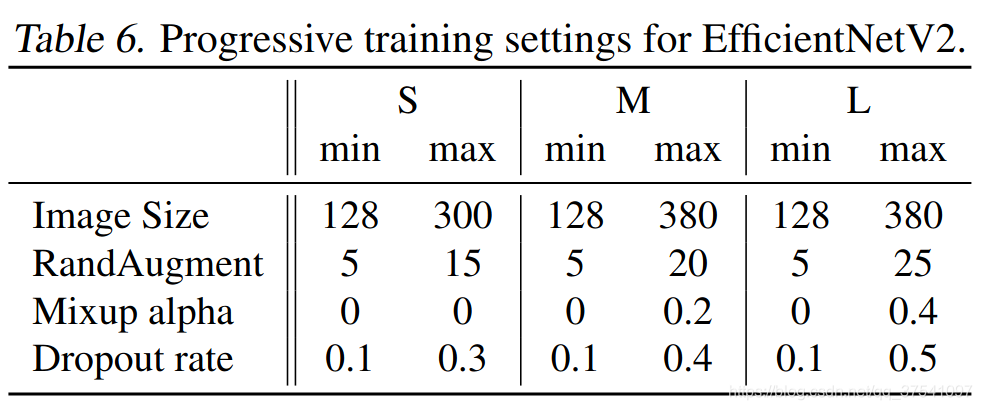
代码
class EfficientNetV2(nn.Module):
def __init__(self,
model_cnf: list,
num_classes: int = 1000,
num_features: int = 1280,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2):
super(EfficientNetV2, self).__init__()
for cnf in model_cnf:
assert len(cnf) == 8
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
stem_filter_num = model_cnf[0][4]
self.stem = ConvBNAct(3,
stem_filter_num,
kernel_size=3,
stride=2,
norm_layer=norm_layer) # 激活函数默认是SiLU
total_blocks = sum([i[0] for i in model_cnf])
block_id = 0
blocks = []
for cnf in model_cnf:
repeats = cnf[0]
op = FusedMBConv if cnf[-2] == 0 else MBConv
for i in range(repeats):
blocks.append(op(kernel_size=cnf[1],
input_c=cnf[4] if i == 0 else cnf[5],
out_c=cnf[5],
expand_ratio=cnf[3],
stride=cnf[2] if i == 0 else 1,
se_ratio=cnf[-1],
drop_rate=drop_connect_rate * block_id / total_blocks,
norm_layer=norm_layer))
block_id += 1
self.blocks = nn.Sequential(*blocks)
head_input_c = model_cnf[-1][-3]
head = OrderedDict()
head.update({"project_conv": ConvBNAct(head_input_c,
num_features,
kernel_size=1,
norm_layer=norm_layer)}) # 激活函数默认是SiLU
head.update({"avgpool": nn.AdaptiveAvgPool2d(1)})
head.update({"flatten": nn.Flatten()})
if dropout_rate > 0:
head.update({"dropout": nn.Dropout(p=dropout_rate, inplace=True)})
head.update({"classifier": nn.Linear(num_features, num_classes)})
self.head = nn.Sequential(head)
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x: Tensor) -> Tensor:
x = self.stem(x)
x = self.blocks(x)
x = self.head(x)
return x