数据仓库理论
数仓是一种思想,数仓是一种规范,数仓是一种解决方案!
1、数据处理方式
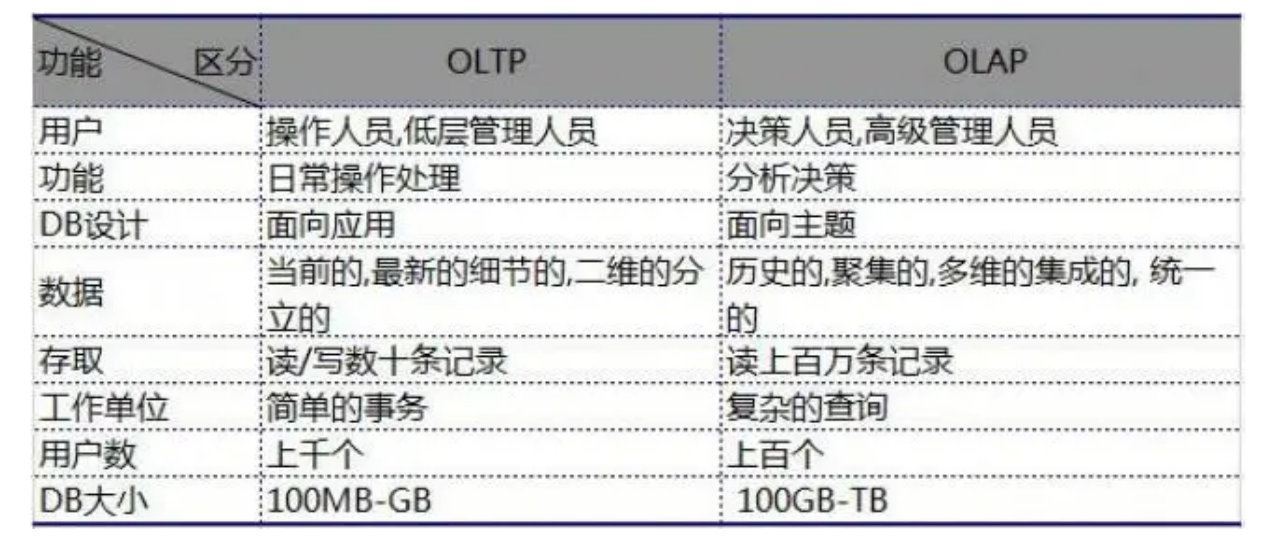
数据处理大致可以分为两大类:联机事务处理:OLTP(On_Line Transaction Processing)、联机分析处理OLAP(On_Line Analytical Processing)
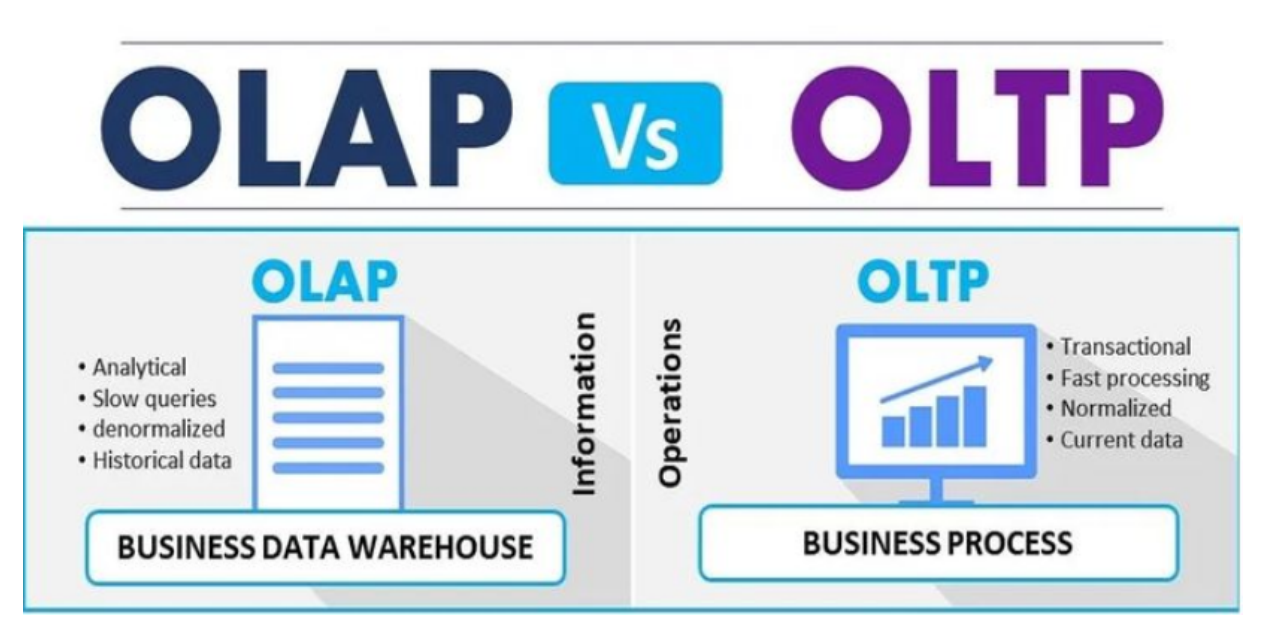
OLTP(On_Line Transactions Processing):中文名称是联机事务处理。其特点是会有高并发且数据量级不大的查询,是主要用于管理事务的系统。此类系统专注于short on-line-transactions如Insert,update,delete,Query操作。通常存在此类系统中的数据都是以实体对象模型来存储数据,并满足3NF(数据库第三范式)。
OLAP(On_Line Analytical Processing):中文名称是联机分析处理。其特点是查询频率较OLTP系统更低,通常会涉及到非常复杂的聚合计算。一般用于大数据分析,数据分析结果是宏观,用于决策层进行决策作用。
2、数据建模
将经过系统分析后抽象出来的概念模型转化为物理模型。
数据建模指的是对现实世界各类数据的抽象组织,确定数据库需管辖的范围、数据的组织形式等直至转化成现实的数据库。
- ER建模
主要用于OLTP,主要用于基于联机事务处理,企业高度设计一个3NF模型的方法,用实体加关系描述的数据模型描述企业业务架构,站在企业角度面向主题的抽象,而不是针对某个业务流程的实体对象关系抽象。简而言之就是三大范式:第一范式每个列不能再分(原子性)。第二范式就是非主键完全依赖与主键。第三范式:属性不依赖其他非主键字段。(所有范式是在前面范式基础上叠加)
优点:规范性好,冗余小,数据集成和数据一致性方面得到重视。
缺点:需全面了解业务,成本昂贵,对建模人员要求高,容易烂尾。
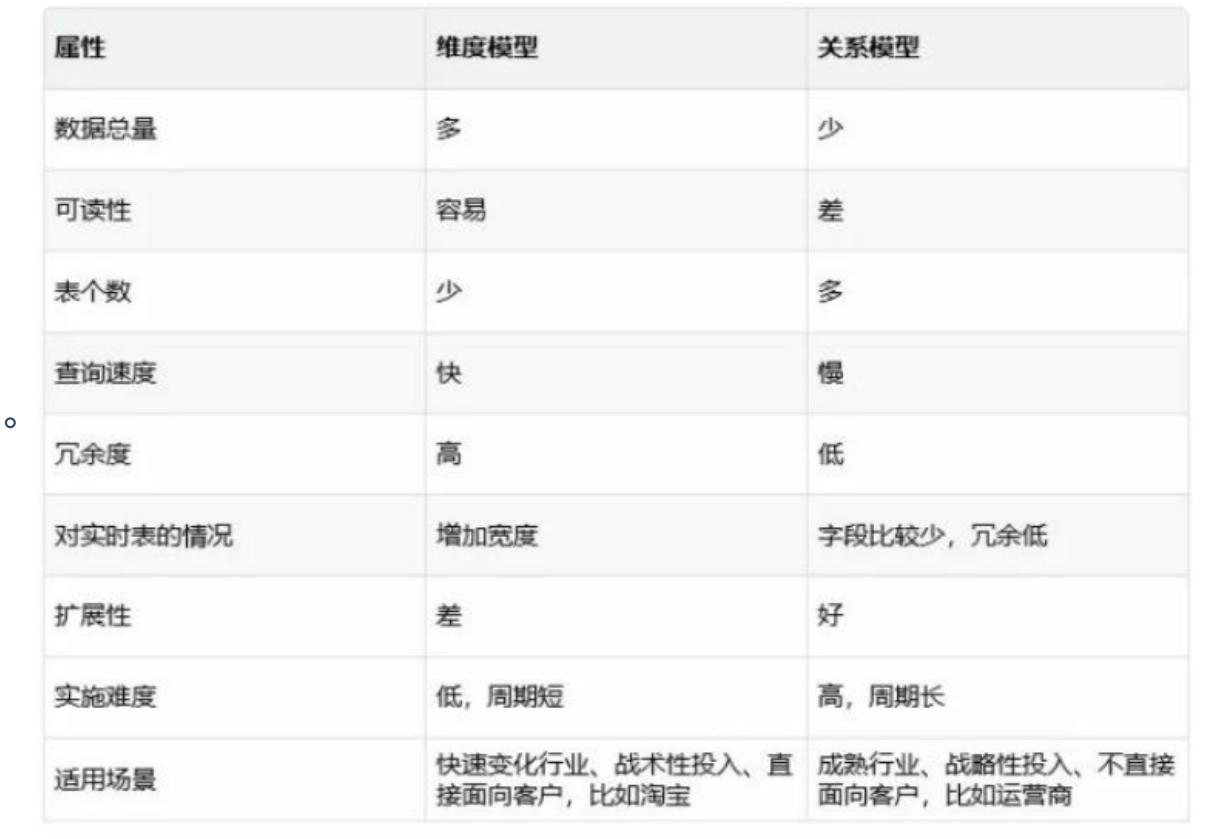
- 维度建模
以分析决策为需求构建模型,面向重点解决用于如何快速完成分析需求,同时还有较好的大规模复杂查询的响应性能,更直接面向业务。
重要概念=> 事实表:发生在现实世界中的操作事件,其产生的可度量数值,存储在事实表中。
维度表:每个纬度表都包含单一的主键列。
度量值:对一次行为的度量。
- 总结
ER建模是面向应用,遵循三范式,以消除冗余为目标的技术。
维度建模以面向分析,为了提高查询性能可以增加数据冗余,反规范化的技术。
优点:技术要求不高,快速上手,敏捷迭代,快速交付。
缺点:维度表冗余比较多,视野狭窄。
3、维度建模表分类
维度是纬度建模的基础和灵魂。在维度建模中,将度量称为
事实,将环境描述为维度,维度是用于分析事实所需要的多样的环境。特征:表范围很宽(具有多个属性、列比较多) 跟事实表相比,行数较少(通常小于10万条) 内容相对固定。
DWS:DataWareHouse Service(数据仓库服务)
DWD:DataWarehouseDetail(数仓详情)
ODS:Operation Data Store(操作数据存储)
ADS:Application Data Service(应用数据服务)
Dim:Dimension(维度表)
- 举例说明
今天张三买了一瓶两块钱的矿泉水。
分析:“今天”,“张三”,“买”,“矿泉水”是维度,“一瓶”,“两块”是事实。
- 维度表的设计原则
1、维度属性尽可能丰富,为数据打下基础,尽可能为维度表添加描述信息。
2、区分数值型属性和事实。一般用于查询约束条件和分组统计,则作为维度属性;用于参与度量的计算,则作为事实表。
3、沉淀出通用的维度属性,为建立一致性维度做好铺垫。
4、退化维度:把一些简单的维度表放进事实表中。
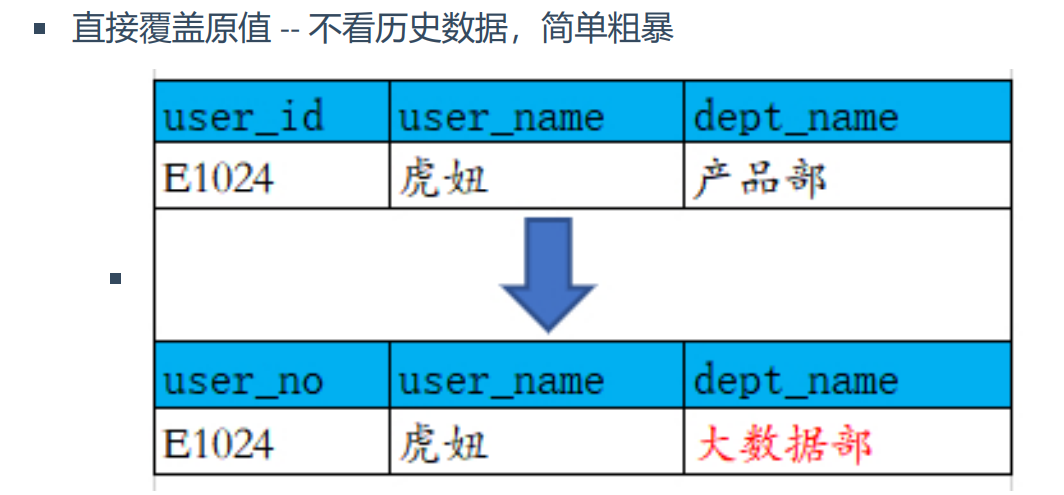
5、缓慢变化维:维度的属性并不是始终不变的,它会随着时间的流逝发生缓慢变化的维。
处理方式:一、直接覆盖原值,不看历史数据,简单粗暴
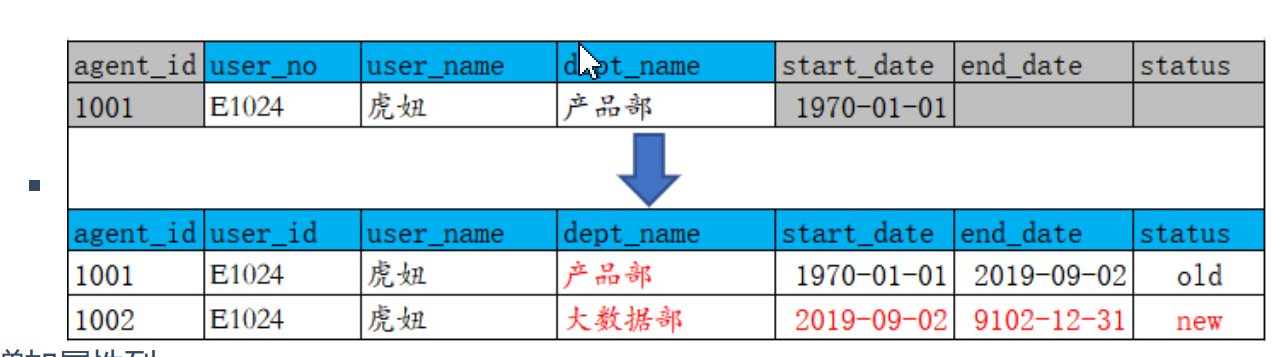
二、拉链表--在需要的维度行增加三列:有效日期、截止日期、行标识(可选)。
三、增加属性列
例如:比如商品价格,可以用于查询约束条件或统计价格区间的商品数量,此时是作为维度属性使用的;也可以用于统计某类目下商品的平均价格,此时是作为事实使用的。
- 拉链表
- 增加属性列
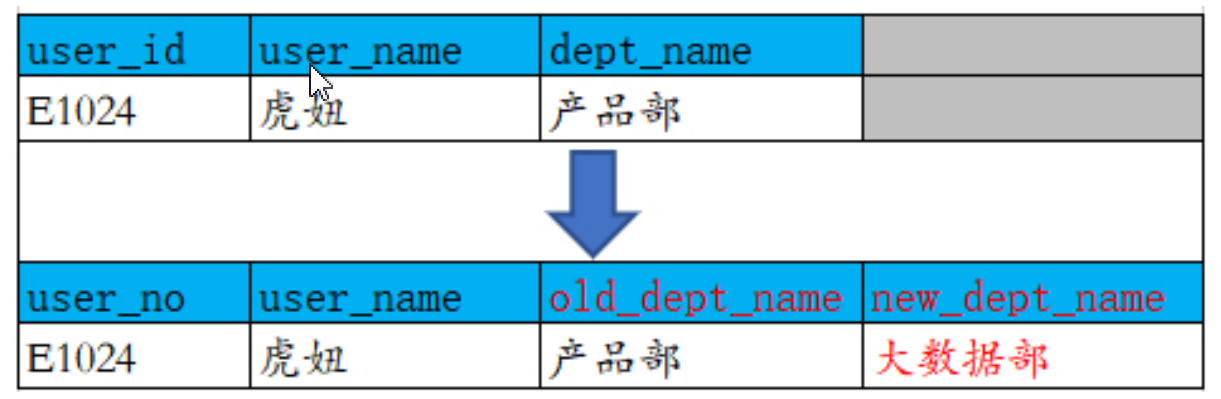
- 总结
为了提升效率,把常用的维度冗余到事实表中。
- 维度设计高级主题
维度整合:一、垂直整合:即不同的来源表包含相同的数据集,只是存储的信息不同。比如学生信息表、成绩表、课程表、老师表,每个表都以学号为关联字段,可以把所有表整合到学生信息表中(增加字段)。
二、水平整合:即不同的来源表包含不同的数据集,不同子集之间无交叉,也可以存在部分交叉。比如蚂蚁金服仓库,采集的数据有淘宝会员、1688会员、国际站会员、支付宝会员等,由于查询业务需求把所有会员整合到一张表中。通俗点讲把每个表中每行数据进行整合。
同时水平整合又要考虑,是否存在交叉,存在交叉需要去重。如果不存在交叉,则需要考虑不同子集的自然键是否存在冲突,如果不冲突,则可以考虑将各子集的自然键作为整合后的表的自然键;另一种方式是设置超自然键, 将来源表各子集的自然键加工成一个字段作为超自然键。比如qq、微信、qq炫舞、qq飞车同属腾讯的,腾讯为了查询账户信息,可以把表整合一起设置主键记录是:
qq_123456,vx_123456,xw_123456,fc_123456。维度拆分:一、水平拆分:将维度的不同分类实例化为不同的维度,同时在主维度中保存公共属性;维护单一维度,包含所有可能的属性。
二、垂直拆分:维度属性的丰富程度直接决定了数据仓库的能力;尽可能丰富维度属性,进行反规范化处理。
- 事实表的设计原则
1、尽可能包含所有与业务相关的事实。
2、只选择与业务过程相关的事实。
3、分解不可加性事实为可加组件。
4、在选择维度和事实之前必须先声明粒度--越细越好(最低级别的原子粒度开始)
5、在同一个事实表中不能有多种不同粒度的事实。
6、事实的单位要保持一致。比如时间日期格式、距离长度等
7、对事实的null值要统一处理,null值没处理好会导致数据倾斜或者无法计算。
8、使用退化维度提高事实表的易用性。
- 事实表概念
事实表中的每行数据代表一个业务事件。“事实”表示的是业务事件的度量值(可以统计次数、个数、金额等)。
可加性事实是指可以按照与事实表关联的任意维度进行汇总。比如:销售记录表(事实表)对应商品销售事实,销售记录中是多个销售事实,其中销售金额是可以累加的,或者某个商品的销售金额可以累加。
半可加性事实只能按照特定维度汇总,不能对所有维度汇总,比如库存可以按照地点和商品进行汇总,而按时间维度把一年中每个月的库存累加起来则毫无意义。
不可加性事实,比如比率型事实。对于不可加性事实可分解为可加的组件来实现聚集。比如每个班的语文成绩及格率,把每个班的及格率进行相加,没有意义,但是全年级的语文及格成绩以及总人数是有意义的,可以求出全年级及格率。
相对维表来说,通常事实表要细长得多,行的增加速度也比维表快很多。
- 事实表设计方法
1、选择业务过程以及确定事实表类型。
2、明确业务过程后,根据业务需求来选择与维度建模有关的业务过程。
3、声明粒度(粒度越细,数据越多,查询越复杂),确定维度、确定事实、冗余维度。
4、如果维度表能够进行复用,并且维度表字段较多,一般就不会进行退化。
- 事实表分类
1、事务型事实表:单事务事实表(对每个业务设计一个事实表)、多事务事实表(一个事实表包含不同的业务过程)。
2、周期性快照事务表:周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,以具有规律性的、可预见的时间间隔记录事实,例如每天或每月的总销售金额,或每月的账户余额等。
3、累积型快照事实表:跟踪事务变化,覆盖整个生命周期,通常多个日期字段记录时间点,业务过程进行时,事务表的记录也要不断更新。
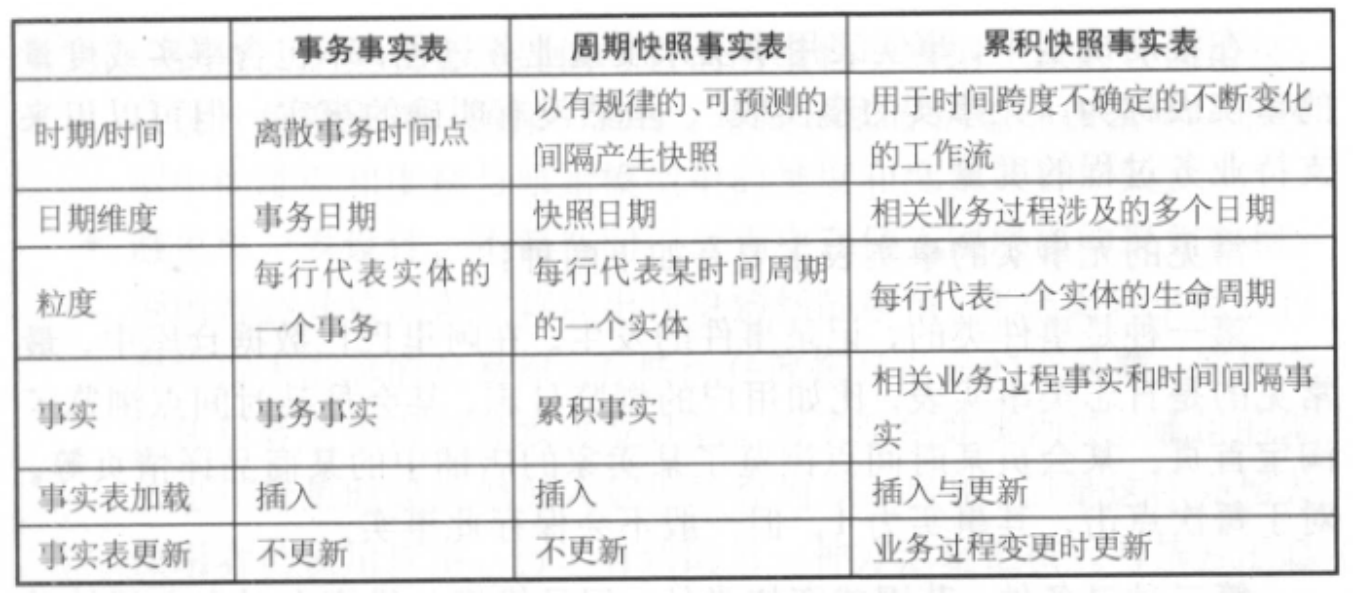
4、数据组织类型
维度建模按数据组织类型划分可分为星型模型、雪花模型、星座模型。
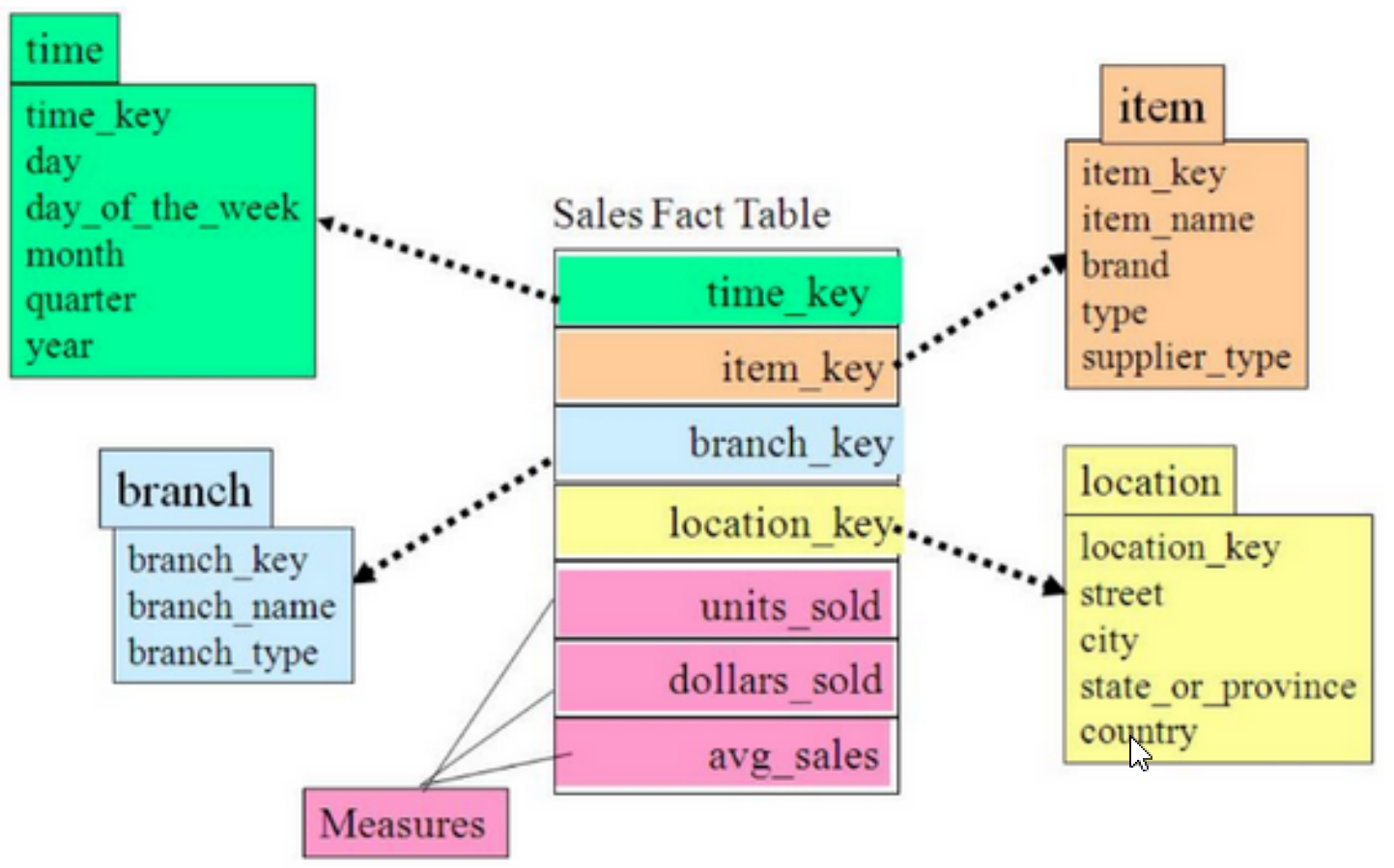
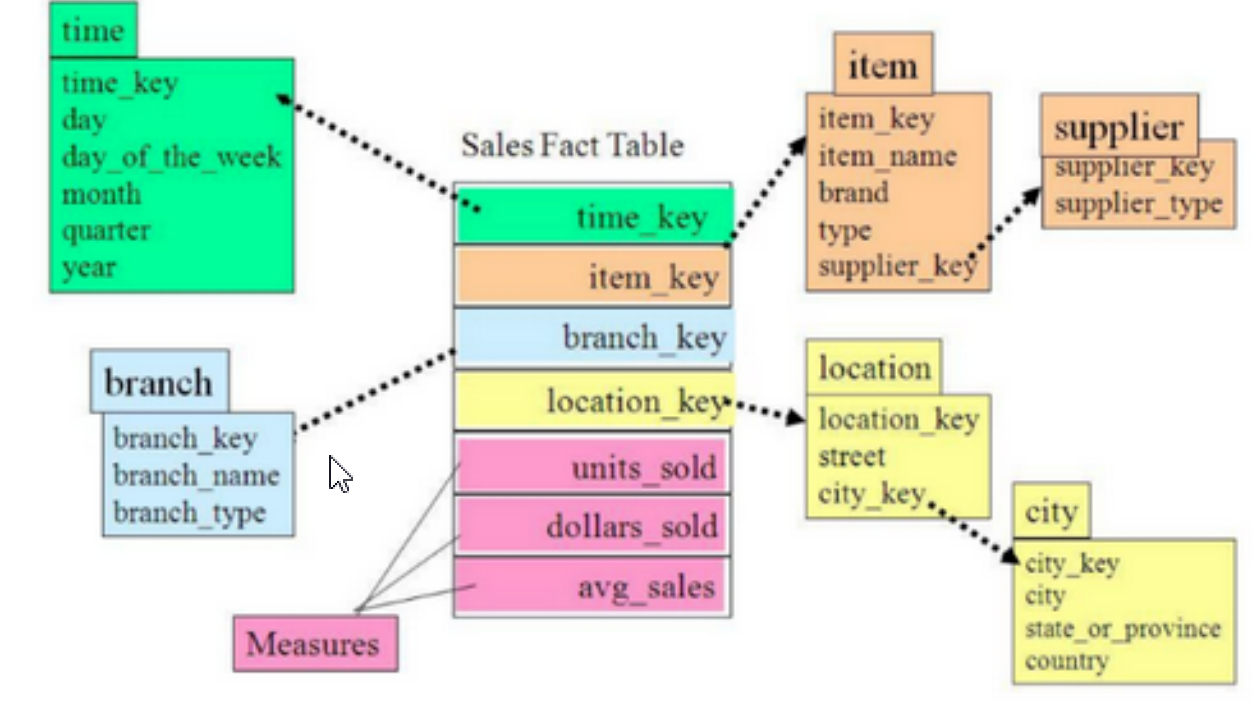
- 星型模型
是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每 个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。多维数据集每一个维度直接与事实表相连接。
- 雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像 多个雪花连接在一起。
雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小 的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。通过减少数据存储量,联合较小维表改善查询性能,去除数据冗余。
- 星座模型
多个事实表共享多个维度表,因而当作星型模型的集合,故称为星座模型。
- 模型选择
模型的选择跟数据和需求有关系,跟设计没有关系。
星型还是雪花,取决于性能优先,还是避免冗余、灵活更优先。
实际企业开发中,一般不会只选择一种,需要根据情况灵活组合,甚至并存(一层维度和多层维度都保存)。
整体来看,更倾向于维度更少的星型模型。尤其是大型数据仓库项目,减少表连接的次数,可以显著提升查询效率。
5、维度表建模步骤
- 选择业务处理过程>声明粒度>选择维度>确定事实
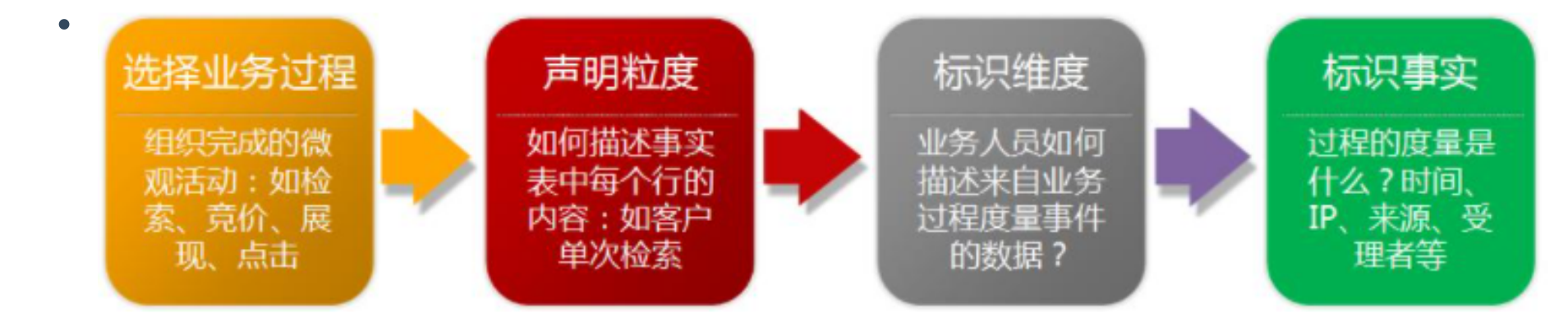
选择业务:选择感兴趣的业务线,如下单,支付,退款,活动 。
声明粒度:一行代表信息:一条订单?一天的订单?一周的订单? 选择最小粒度。
确认维度:维度退化:谁 。 什么时间 什么地点:牢牢掌握事实表 的粒度,就能将所有可能存在的维度区分开,并且要确保维度表中不能出现重复数据,应使 维度主键唯一。
确认事实:度量值:如个数,件数,金额:是同一事实表中的所有度量必须具有相同的粒度。最实用的事实就是数值类型和可加类事实。
6、数据仓库分层
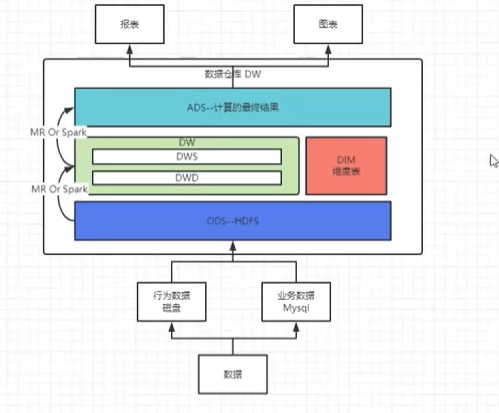
- 原因
用空间换时间:通过大量的预处理提升应用系统的用户体验,数仓会有大量冗余数据。
增强扩展性:不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大.
分层管理:通过数据分层管理可以简化数据清洗的过程。
隔离原始数据:把原始数据异常隔离。
- 优点
清晰数据结构、方便数据血缘追踪、把复杂问题简单化、屏蔽原始数据异常。
- 介绍
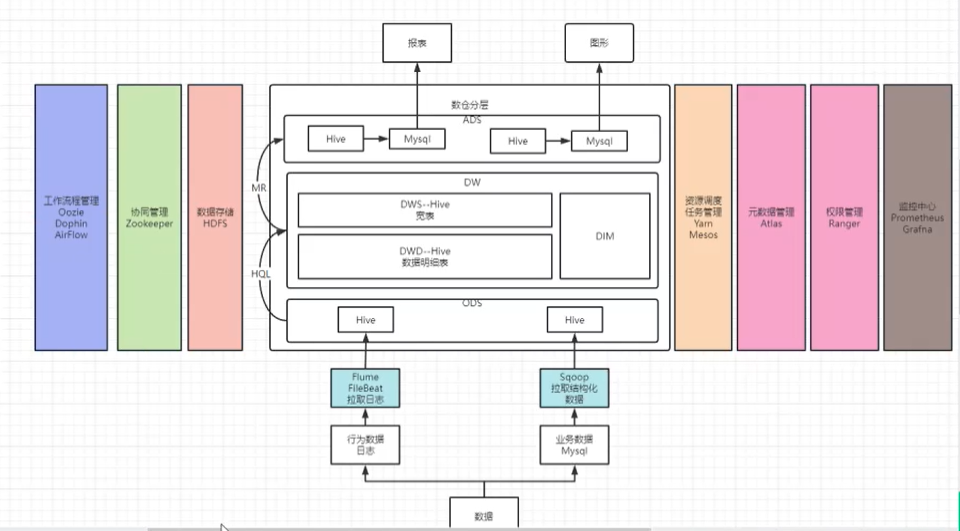
ODS原始数据层:该层最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL 之后,装入ODS层。
DW数据仓库层:该层从ODS层中获得的数据按照主题建立各种数据模型。四个概念:维度(dimension)、事实(Fact)、指标(Index)和粒度( Granularity)。还细分为DWS(Data WareHouse Service)、DWD(Data WareHouse Detail)、DIM(Dimension)
DWS:服务数据层,主要整合汇总最终的结果供应用表使用,一般存储大宽表和高度压缩表。
DWD:数据源的细节层,是业务层与数据仓库的隔离层,该层可以把业务表分的更细。此层一般用于维度建模、事实建模。
DIM:存放维度表层。
ADS:存放数据产品个性化的统计指标数据,一般会存放在ES、MySQL等系统中供线上系统使 用,也可能会存在Hive或者Druid中供数据分析和数据挖掘使用。
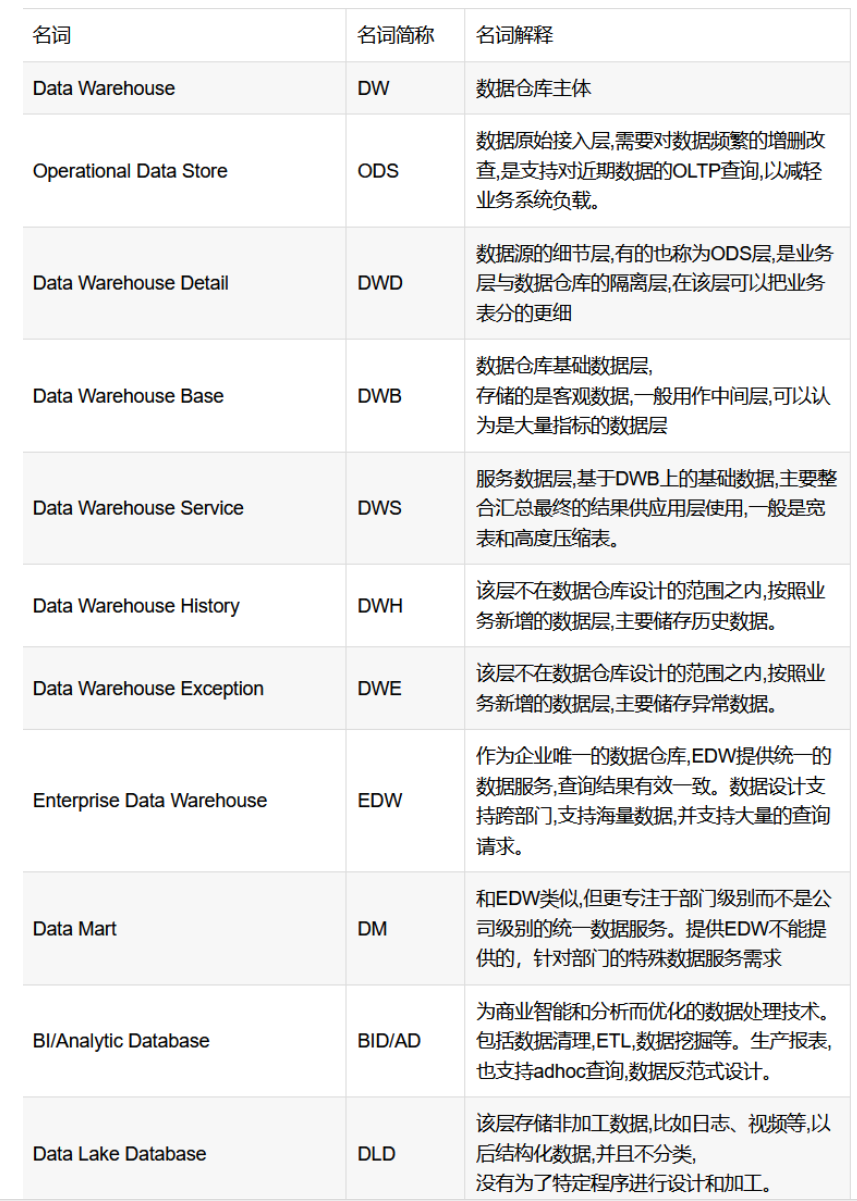
7、阿里数仓架构
模型层级:阿里巴巴的数据团队把表数据模型分为三层:操作数据层(ODS) 、公共维度模型层(CDM)和应 用数据层(ADS) ,公共维度模型层包括明细数据层(DWD)和汇总数据层(DWS)。

8、ETL
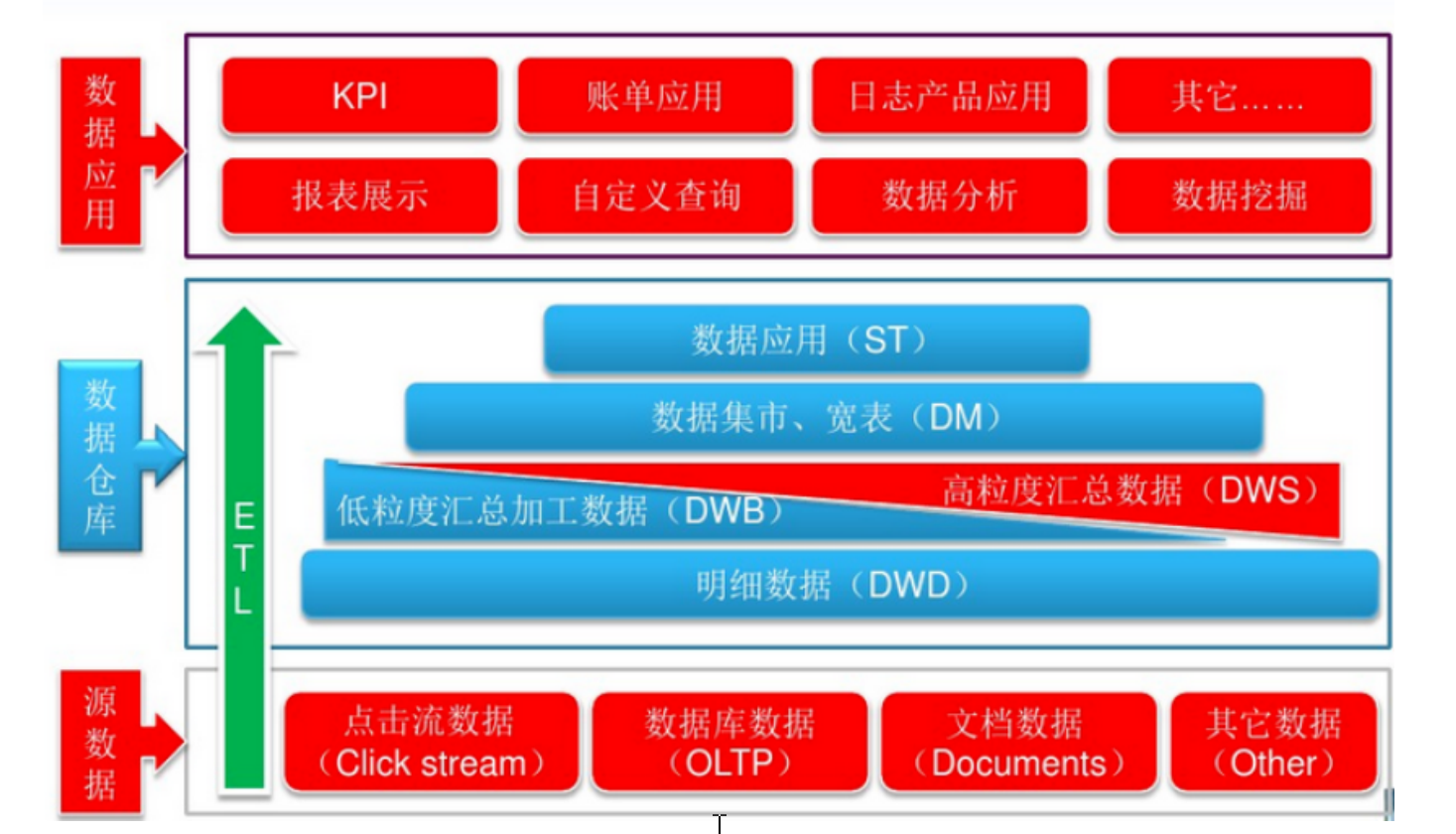
TL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分 散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
数据抽取、数据清洗、库内转换、规则检查、数据加载。 各模块可灵活进行组合,形成ETL处理流程。
数据清洗转换:通常的做法是从业务系统到ODS做清洗,将脏数据和不完整数据过滤掉,在从ODS到DW的过 程中转换,进行一些业务规则的计算和聚合。不一致数据转换、数据细粒度转换、商务规则设计、空值处理、数据标准、数据拆分、数据验证、数据替换、数据关联。
- ETL工具
数据整合解决方案,通俗点讲就是倒数据工具。
工具:Sqoop、DataX、Kettle、Canal、StreamSets
- 加载策略
系统日志分析方式:通过分析数据库自身的日志来判断变化的数据。
触发器方式:直接进行数据加载 利用增量日志表进行增量加载。
时间戳方式:在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值。
全表对比方式:全表比对即在增量抽取时,ETL 进程逐条比较源表和目标表的记录,将新增和修改的记录读 取出来。
源系统增量数据直接或者转换后加载:全表比对即在增量抽取时,ETL 进程逐条比较源表和目标表的记录,将新增和修改的记录读 取出来。
9、常见概念描述
- 数据仓库
数据仓库是一个面向主题、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理中的决策制定的。
数据仓库是一个功能概念,是将企业的各业务系统产生的基础数据,通过维度建模的方式,将业务数据划分为多个主题(集市)统一存储,统一管理。
- 数据集市
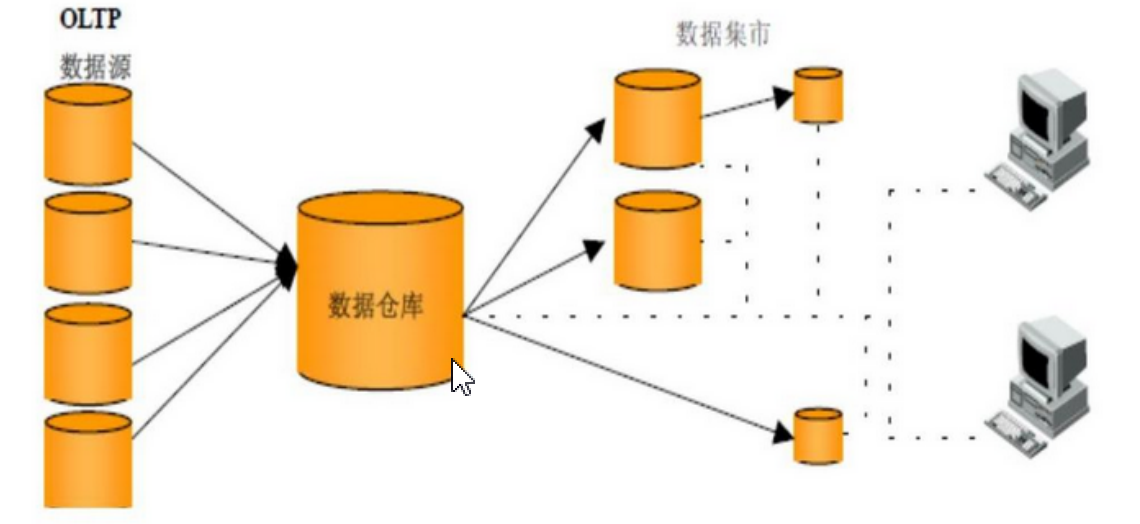
数据集市可以理解为是一种"小型数据仓库",它只包含单个主题,且关注范围也非全局。数据集市分为:独立数据集市(集市有自己的源数据和ETL架构)、非独立数据集市(没有自己的源数据,来自数据仓库),数据集市是一个结构概念,是企业级数据仓库的一个子集,面向部门、面向主题。
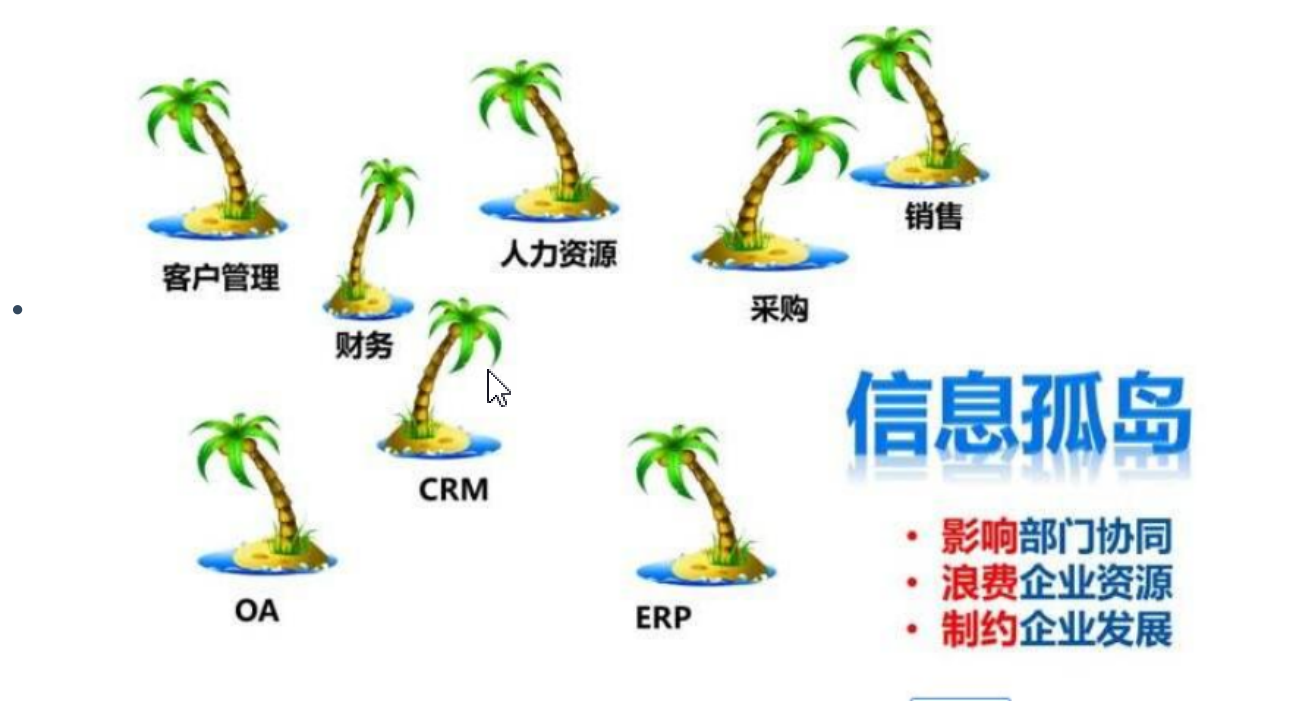
- 数据孤岛
业务系统之间各自为政,相互独立造成数据孤岛,业务不集成、流程不互通、数据不共享。
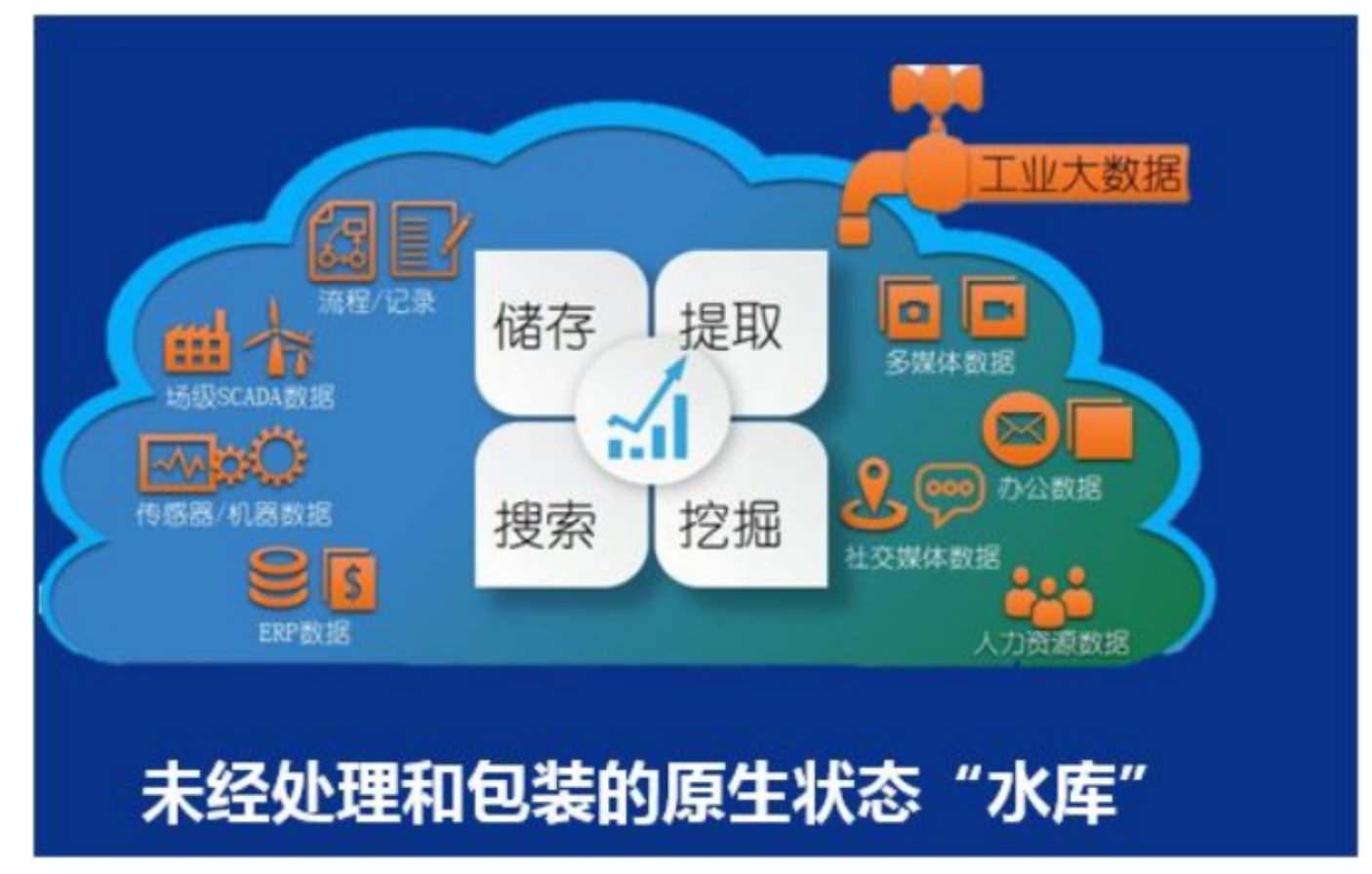
- 数据湖
数据湖是一种数据存储理念,存储企业各种各样的原始数据的大型仓库,包括结构化、非结构、 二进制图像、音频、视频等等。从源系统导入所有的数据,没有数据流失。数据存储时没有经过转换或只是简单的处理。数据转换和定义schema 用于满足分析需求。通俗点讲:就是存放未处理的数据存储理念。
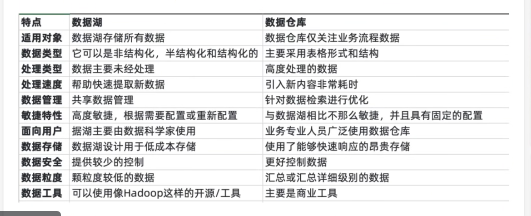
- 数据中台
通过企业内外部多源异构的数据采集、治理、建模、分析、应用,使数据对内优化管理提高业务,对外数据合作价值释放,成为企业数据资产管理中枢。
数据中台是一个逻辑概念,为业务提供服务的主要方式是数据API,它包括了数据仓库,大数据、 数据治理领域的内容。
- 宽窄表
宽表:通常是指业务主题相关的指标、维度、属性关联在一起的一张数据库表,不符合三范式模型,数据产生冗余,但是可以提高查询效率。
窄表:严格按照数据库设计三范式。尽量减少数据冗余,但是缺点是修改一个数据可能需要修改多表。
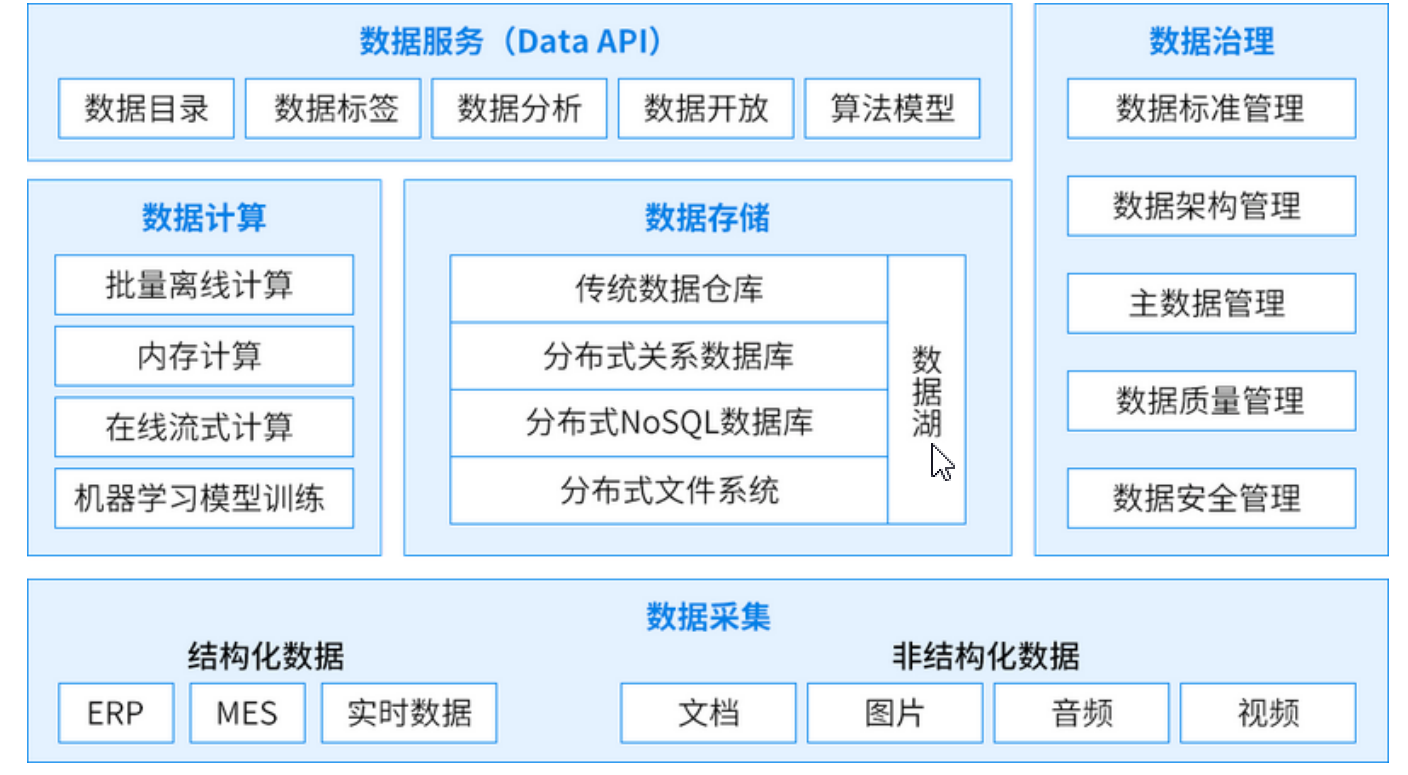
10、大数据架构
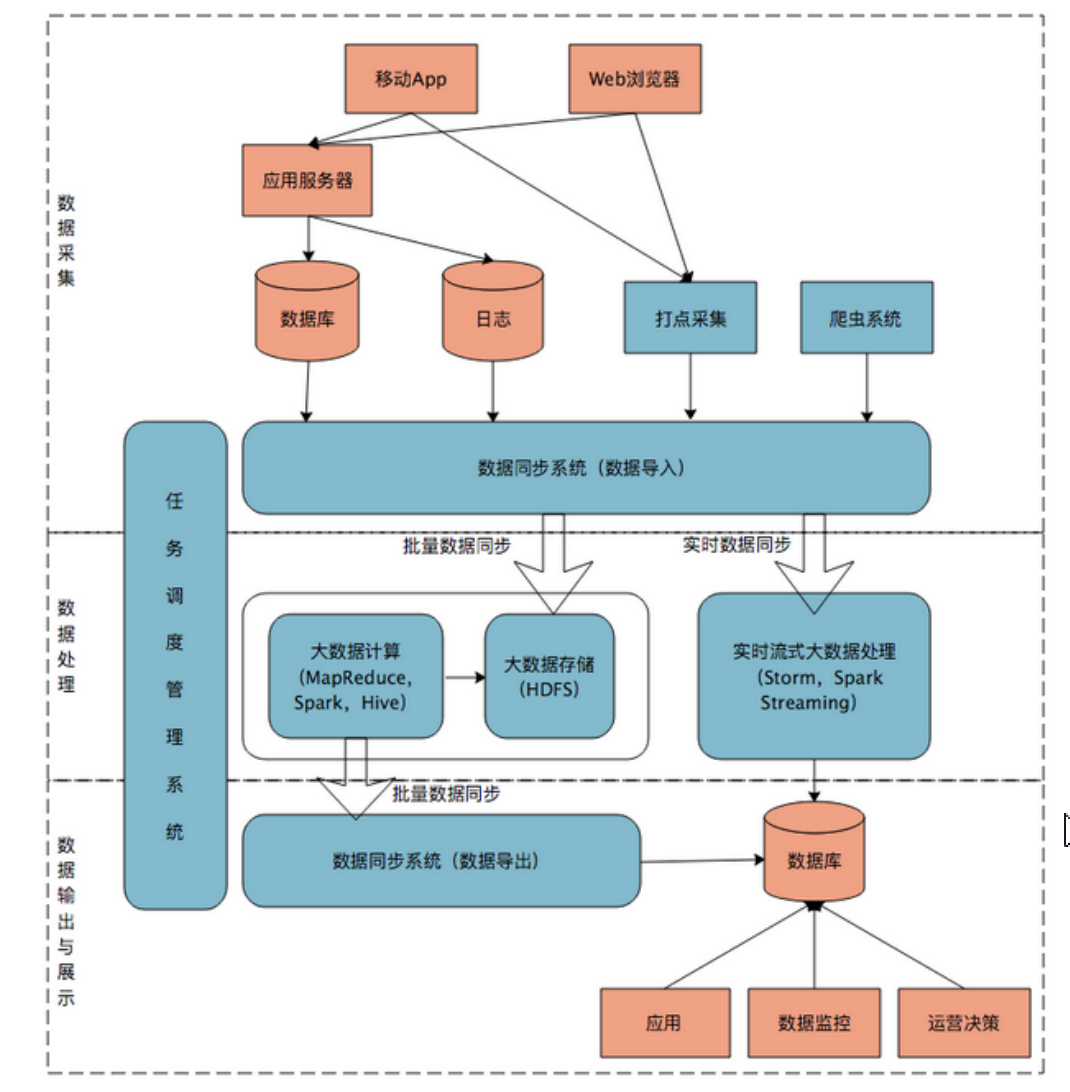
大数据平台由上到下,可分为三个部分:数据采集、数据处理、数据输出与展示。
蓝色图案为大数据组件,红色图案为互联网组件。
数据采集:将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系 统实际上是多个相关系统的组合。数据库同步通常用 Sqoop,日志同步可以选择 Flume,打点采集的数据经过格式化转换后通过 Kafka 等消息队列进行传递。
数据处理:这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在 HDFS。MapReduce、 Hive、Spark 等计算任务读取 HDFS 上的数据进行计算,再将计算结果写入 HDFS。
数据输出和展示:大数据计算产生的数据还是写入到 HDFS 中,但应用程序不可能到 HDFS 中读取数据,所以必 须要将 HDFS 中的数据导出到数据库中。应用程序就可以直接访问数据库中的数据,实时展示给用户,比如展示给用户关联推荐的商 品。
- Lambda架构(现在使用的架构)
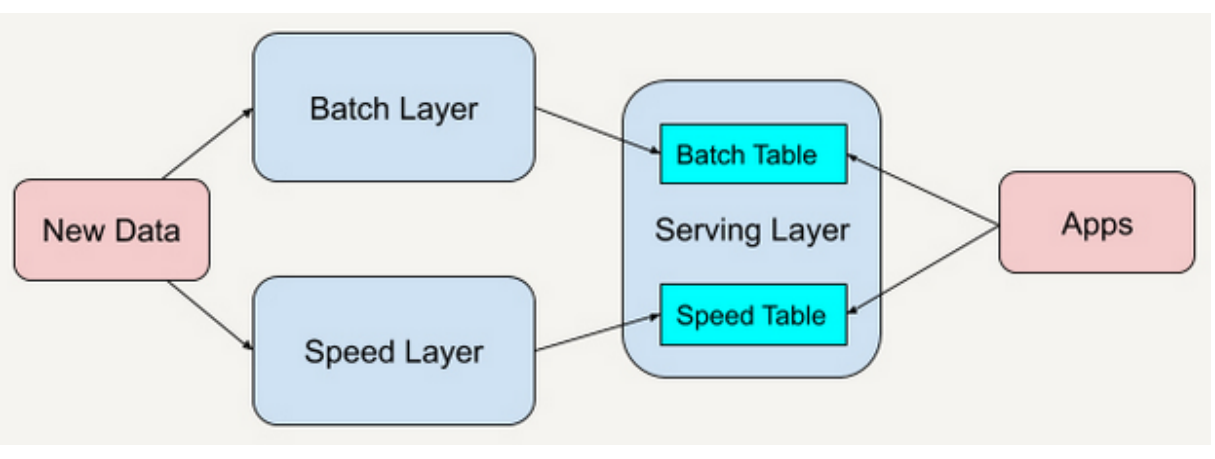
Lambda 架构总共由三层系统组成:批处理层(Batch Layer),速度处理层(Speed Layer),以及用于响应查询的服务层(Serving Layer)。
批处理层:批处理层存储管理主数据集(不可变的数据集)和预先批处理计算好的视图。批处理层使用可处理大量数据的分布式处理系统预先计算结果。
速度处理层:速度处理层会实时处理新来的大数据。速度层通过提供最新数据的实时视图来最小化延迟。
服务层:批处理层和速度层处理完的结果都输出存储在服务层中,服务层通过返回预先计算的数 据视图或从速度层处理构建好数据视图来响应查询。
- Kappa架构
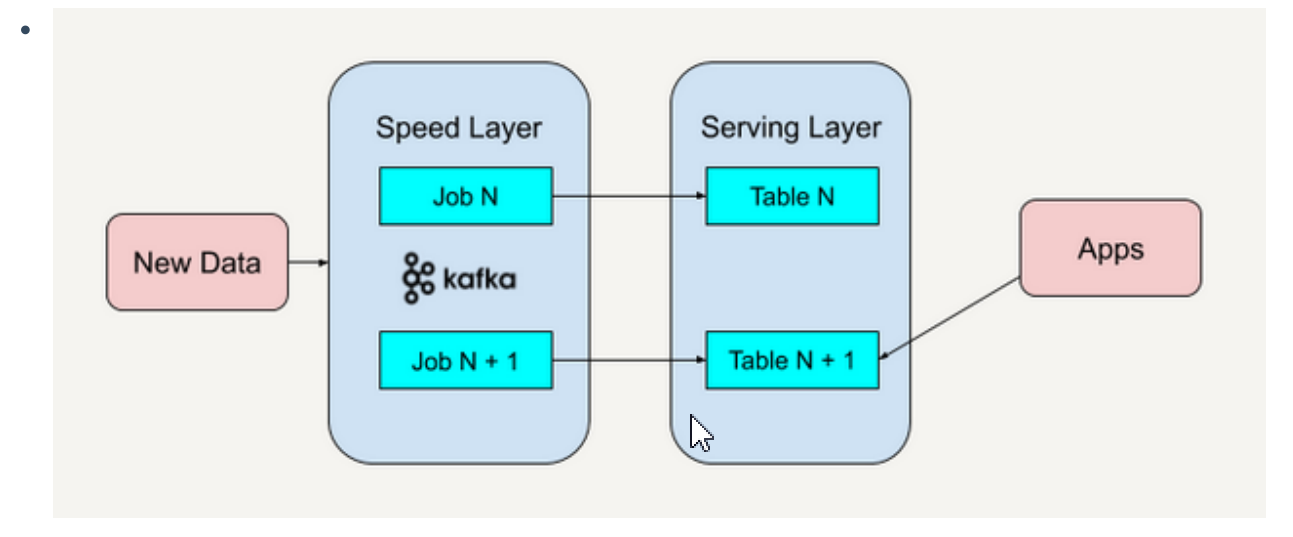
是一种架构思想,通俗点讲就是把流处理和批处理都在速度处理层进行处理,没有处理层。也就是我们说的流批一体。
缺点:缺少处理层,在速度层上处理大数据可能会出错,会耗费大量时间处理错误。
把流处理和批处理放在同一层,就需要使用同一代码算法逻辑,不适用流批处理不一致的场景。
11、数据仓库元数据
- 业务元数据
描述 ”数据”背后的业务含义 主题定义:每段 ETL、表背后的归属业务主题。
业务描述:每段代码实现的具体业务逻辑。
标准指标:类似于 BI 中的语义层、数仓中的一致性事实;将分析中的指标进行规范化。
标准维度:同标准指标,对分析的各维度定义实现规范化、标准化。 不断的进行维护且与业务方进行沟通确认。
- 技术元数据
数据源元数据、ETL元数据、数据仓库元数据、BI元数据
- 管理元数据
管理领域相关,包括管理流程、人员组织、角色职责等。