Black-Box Attack-Based Security Evaluation Framework forCredit Card Fraud Detection Models
动机
AI模型容易受到对抗性攻击(对样本添加精心设计的扰动生成对抗性示例)
现有的对抗性攻击可以分为白盒攻击和黑盒攻击。
白盒攻击:攻击者可以访问有关目标模型的所有信息,包括训练集、类型、结构和参数。
黑盒攻击:只知道给定输入样本的输出。
其中黑盒模型可以分为三类:迁移、分数、决策。
黑盒攻击所需的信息更少,更难以实现。但是一旦实现了较好的黑盒攻击,将会使得银行和个人更加难以察觉盗刷、进而造成更大的损失。
一方面,难以确认现有算法在面对黑盒攻击时是否存在风险。另一方面,现有的黑盒算法来评估模型的安全性也并不容易,因为既不能直接得到预测分数,又会需要对模型进行大量的查询。没有分数,基于分数和决策的黑盒算法直接失效,而大量的测试会影响效率,也会增加被抓的风险,基于迁移的算法也难以实现。
因此,文章的目标是设计一种不需要大量查询的迁移算法,实现更强大的攻击模型。
模型
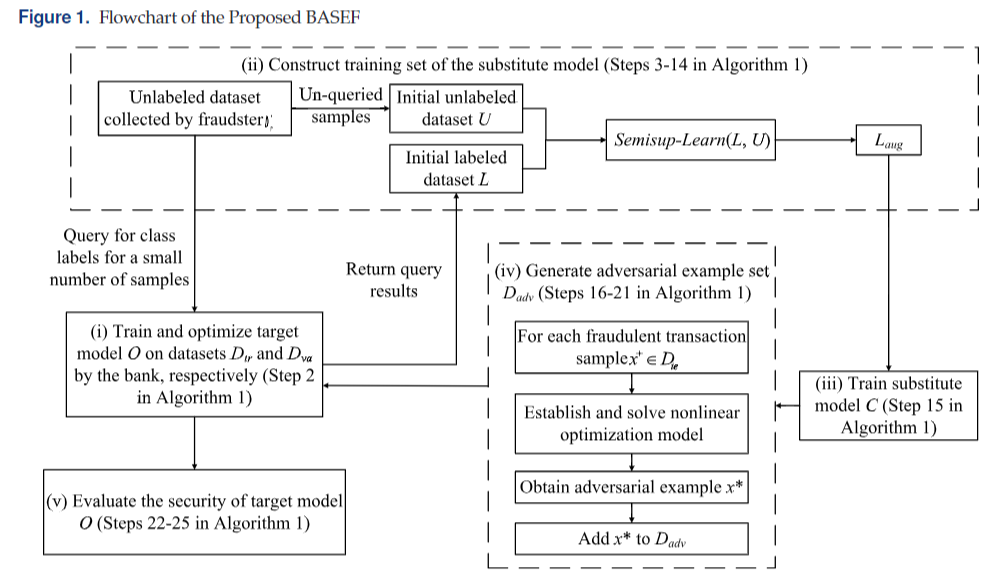
这个流程图画得挺乱的。
模型的流程:
-
银行使用训练集\(D_{tr}\)和验证集\(D_{va}\)训练和优化目标模型O
-
欺诈者随机选择\(\tau\)个训练集中的数据,并只保留\(\beta\)个特征,得到样本集\(D'_{tr}\),从中选取\(\delta\)个样本使用O得到标签\(L\),其余得构成无标签数据集\(U\),再使用半监督学习模型对\(U\)进行选择性标记,增强\(L\)得到增强数据集\(L_{aug}\)
-
使用\(L_{aug}\)训练替代模型\(C\),文章尝试了Linear-SVM和RBF-SVM两种替代模型。
-
基于替代模型\(C\)生成对抗样本集\(D_{adv}\),使用改进的非线性优化模型求解生成每个正样本的对抗样本。
-
评估O的安全性。在不同攻击强度\(p\)下计算O在\(D_{adv}\)上的分类准确率Acc(p),以及模型的安全性SEI
细节
对于第1步
文章使用了8种不同的模型训练O:LR(逻辑回归),DT(决策树),Linear-SVM,RBF-SVM,XGBoost,DNN,IF无监督异常检测算法,DAE无监督深度神经网络
对于第2步
半监督算法有两种:Co-Forest,先监督训练,再用得到的模型预测补充更多标签并迭代;FlexMatch(NIPS 21),比起前者,会从0开始动态提高预测阈值,让模型不偏科、提高数据利用率。
对于第4步
使用测试集\(D_{te}\)中的正样本(欺诈)x构建优化问题:
其中\(x^+\)是原始的欺诈样本,\(x\)是调整后的样本(调整中的中间变量),
\(\hat{g}=\omega^T\phi(x)+b=\sum^N_{i=1}\alpha_i y_i K(x_i, x) + b\),
这里的\(\alpha_i \geq 0\)是拉格朗日乘子,\(K(\cdot)\)是核函数,如线性核函数\(K(x_i, x) = x_i^Tx\)以及RBF核\(E^{-\gamma ||x_i-x||^2}\)等。
给该函数限制一个最大值\(d(x^+, x) \leq p\),是在限制生成的正样本和修改之后的样本之间的最大距离。
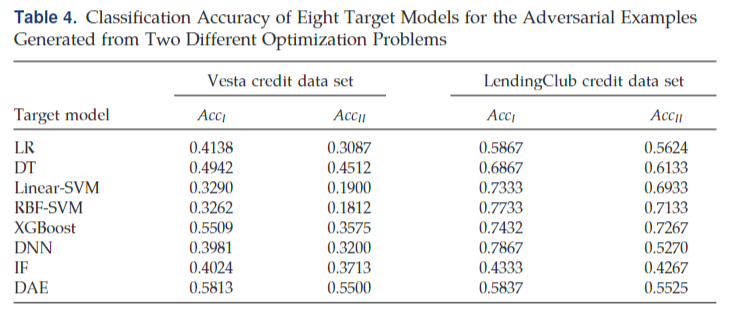
当模型为Linear-SVM时,该问题有最优解:
而当使用RBF-SVM时需要借助顺序最小二乘编程法数值求解上述优化问题。得到的\(x^*\)作为对应的对抗样本,构成最终的对抗样本集\(D_{adv}\)
对于第5步
算法伪代码


这里的13行应该位置错了,要调到第8行前。
实验
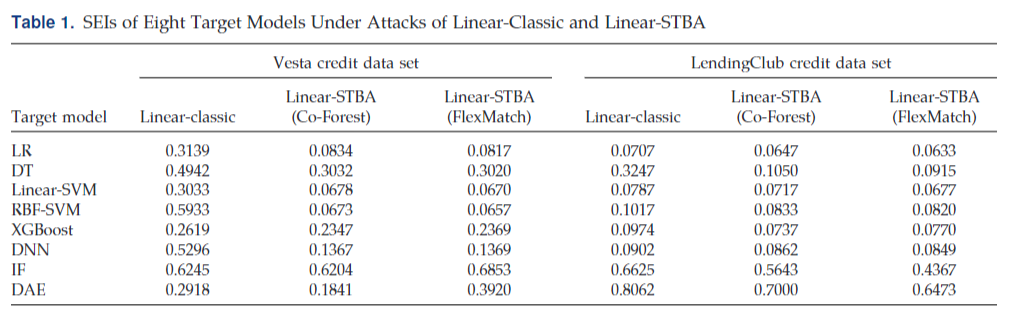
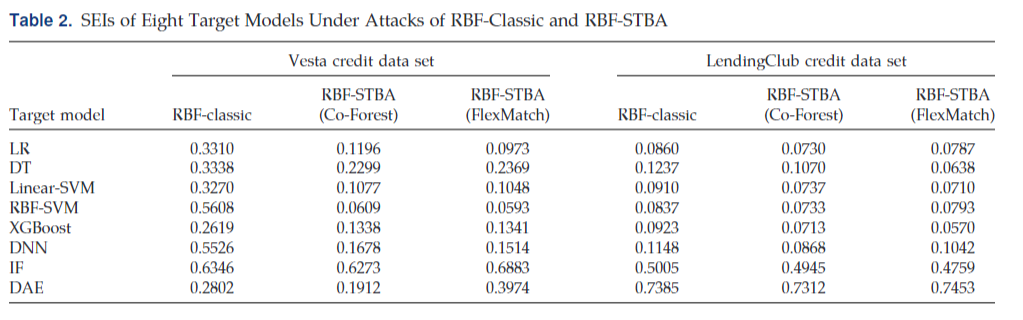
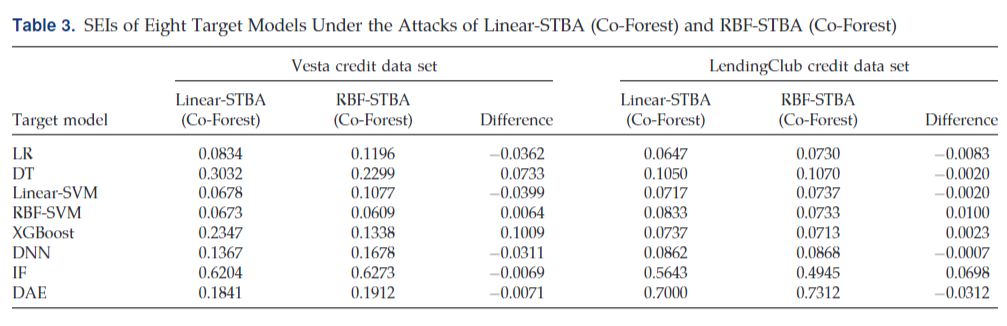
文中说了之前没有黑盒算法的安全评估算法,所以就只是用了传统的Linear和RBF作为baseline
- Attack-Based Evaluation Black-Box Detection Frameworkattack-based evaluation black-box detection attack-based black-box distillation source-free adaptation black-box evaluation evaluation language large model evaluation automatic generated language evaluation exploring humanized models cooperative evaluation selection feature evaluation isys 3401 it