es 的索引生命周期管理 index lifecycle management 即 ILM,控制着索引的创建、滚动、删除、归档,属实好用,那么它是如何实现的呢?
可以想象得到,es 的 master 执行一个定时任务,定期检查关联了 ilm 的索引,判断索引的状态,执行状态的流转。
ILM 相关代码在 x-pack 的 plugin 目录中,主类是 IndexLifecycleService,它实现了 SchedulerEngine.Listener 接口,其实现的 triggered 方法就是上面提到的定时任务。
通过源码启动 elastic search,创建好 ilm,模板,索引,并写入一条数据。
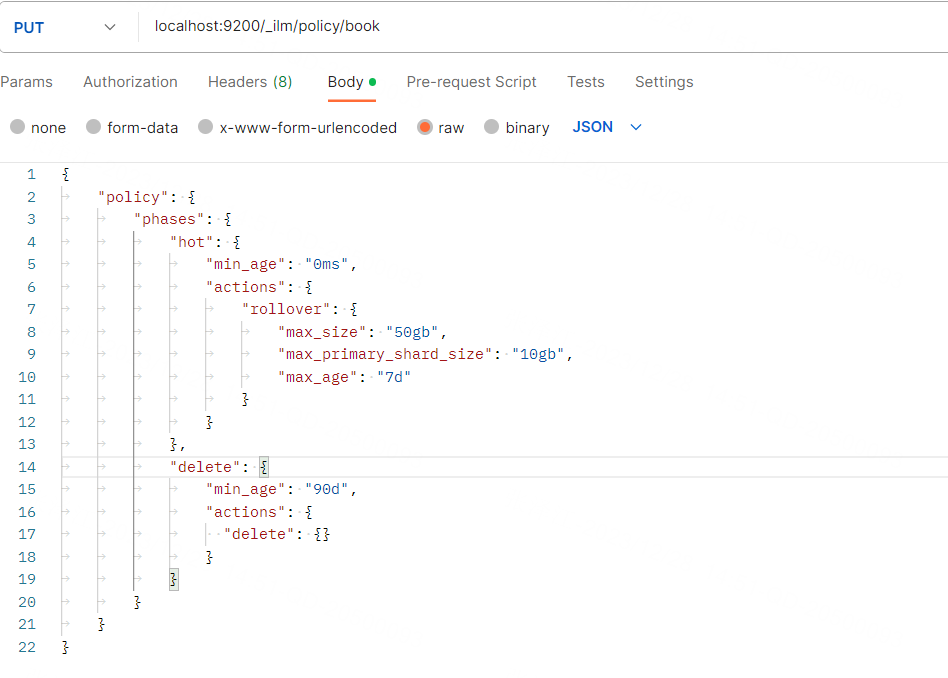
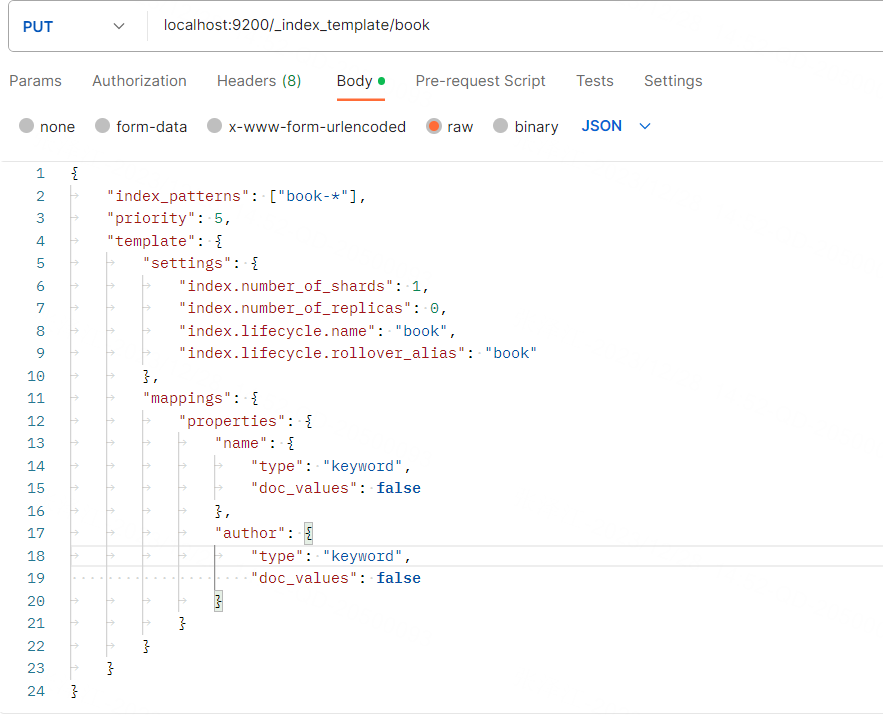
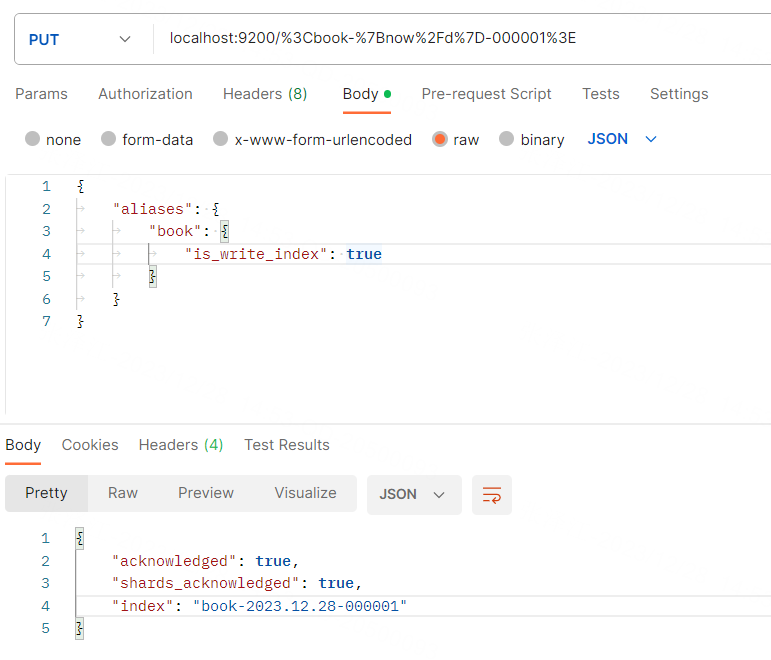
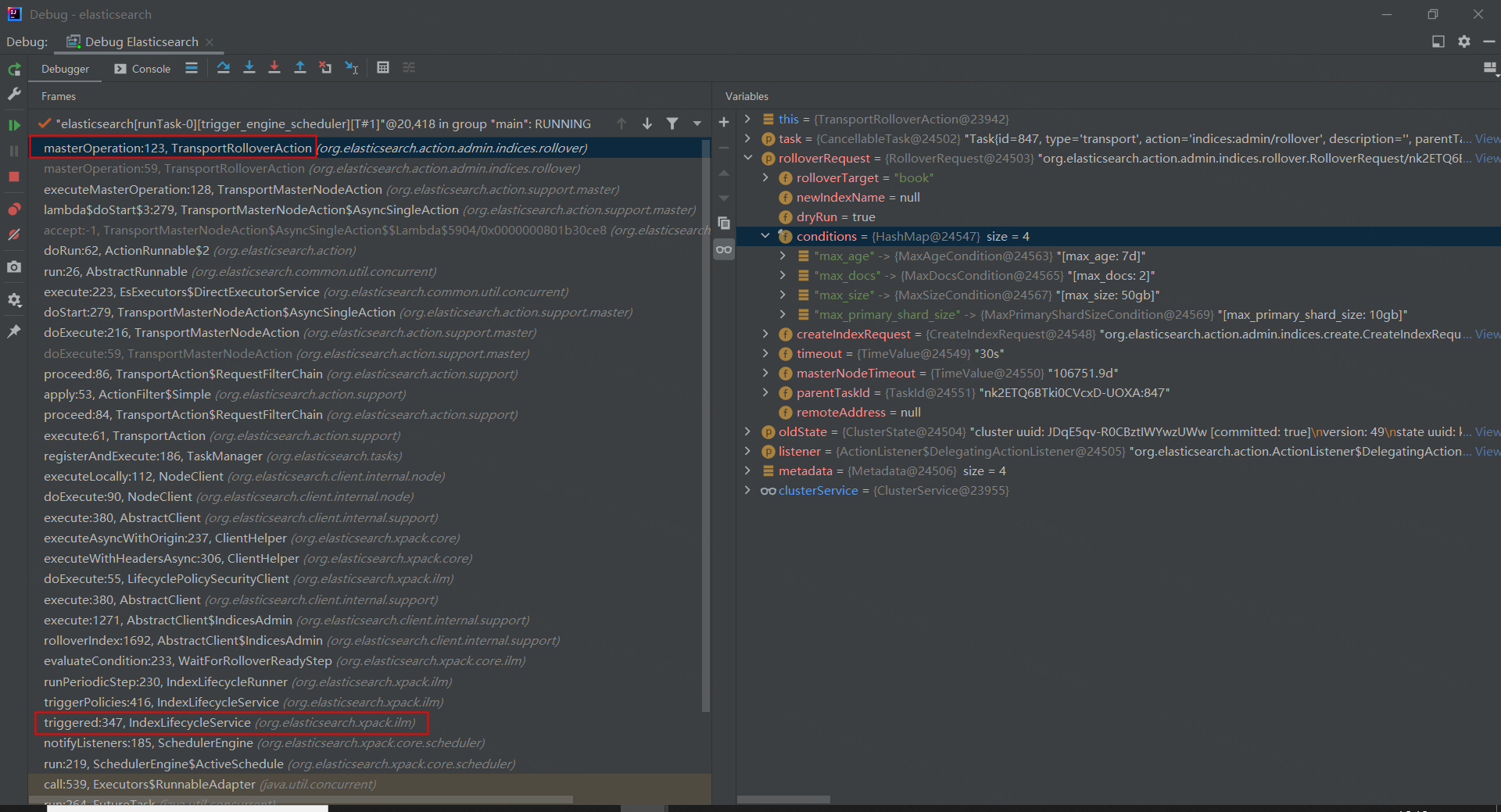
为方便调试,可以设置 ilm rollover 的 max_doc 为 2,es 代码的执行流充满了异步操作,对代码有了一定的基础了解后,我们知道索引 rollover 的操作在 TransportRolloverAction 中:
真正执行 rollover 的逻辑如下,即创建新的索引,并绑定别名和新建索引,更新集群状态版本号
// org.elasticsearch.action.admin.indices.rollover.MetadataRolloverService#rolloverAlias private RolloverResult rolloverAlias( ClusterState currentState, IndexAbstraction.Alias alias, String aliasName, String newIndexName, CreateIndexRequest createIndexRequest, List<Condition<?>> metConditions, boolean silent, boolean onlyValidate ) throws Exception { final NameResolution names = resolveAliasRolloverNames(currentState.metadata(), alias, newIndexName); final String sourceIndexName = names.sourceName; final String rolloverIndexName = names.rolloverName; final String unresolvedName = names.unresolvedName; final Metadata metadata = currentState.metadata(); final IndexMetadata writeIndex = currentState.metadata().index(alias.getWriteIndex()); final AliasMetadata aliasMetadata = writeIndex.getAliases().get(alias.getName()); final boolean explicitWriteIndex = Boolean.TRUE.equals(aliasMetadata.writeIndex()); final Boolean isHidden = IndexMetadata.INDEX_HIDDEN_SETTING.exists(createIndexRequest.settings()) ? IndexMetadata.INDEX_HIDDEN_SETTING.get(createIndexRequest.settings()) : null; MetadataCreateIndexService.validateIndexName(rolloverIndexName, currentState); // fails if the index already exists checkNoDuplicatedAliasInIndexTemplate(metadata, rolloverIndexName, aliasName, isHidden); if (onlyValidate) { return new RolloverResult(rolloverIndexName, sourceIndexName, currentState); } CreateIndexClusterStateUpdateRequest createIndexClusterStateRequest = prepareCreateIndexRequest( unresolvedName, rolloverIndexName, createIndexRequest ); ClusterState newState = createIndexService.applyCreateIndexRequest(currentState, createIndexClusterStateRequest, silent); newState = indexAliasesService.applyAliasActions( newState, rolloverAliasToNewIndex(sourceIndexName, rolloverIndexName, explicitWriteIndex, aliasMetadata.isHidden(), aliasName) ); RolloverInfo rolloverInfo = new RolloverInfo(aliasName, metConditions, threadPool.absoluteTimeInMillis()); newState = ClusterState.builder(newState) .metadata( Metadata.builder(newState.metadata()) .put(IndexMetadata.builder(newState.metadata().index(sourceIndexName)).putRolloverInfo(rolloverInfo)) ) .build(); return new RolloverResult(rolloverIndexName, sourceIndexName, newState); }
到此,可以认为 rollover 的请求得到了处理,那么往前推,这个 rollover 的请求是如何生成的呢,仍然是在 TransportRolloverAction 中打断点,通过下图的调用栈,可以看到与前面的定时任务关联上了。