前言 腾讯优图实验室联合厦门大学,在新建的评测基准MME上首次对现有10种开源MLLM模型 进行了全面定量评测并公布了16个排行榜。
本文转载自我爱计算机视觉
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
- 项目链接(已获1.8K Stars):https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
多模态大语言模型(Multimodal Large Language Model,MLLM)依赖于LLM丰富的知识储备以及强大的推理和泛化能力来解决多模态问题,目前已经涌现出一些令人惊叹的能力,比如看图写作和看图写代码。但仅根据这些样例很难充分反映MLLM的性能,目前仍然缺乏对MLLM的全面评测。
为此,腾讯优图实验室联合厦门大学全面定量评测并公布了 16个排行榜 ,包含感知和认知两个总榜以及14个子榜单:

- 论文链接:https://arxiv.org/pdf/2306.13394.pdf
- 项目链接:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
现有MLLM的定量评测方法主要分为三类,但都存在一定的局限导致难以全面反映其性能。第一类方法在传统的公开数据集上进行评测,例如图像描述(Image Caption)和视觉问答(VQA)数据集。但一方面这些传统数据集可能难以反映MLLM涌现的新能力,另一方面由于大模型时代的训练集都不再统一,因此难以保证这些评测数据集没有被其他MLLM训练过。第二种方式是收集新的数据进行开放式评测,但这些数据要么未公开[1],要么数量太少(仅有50张)[2]。第三种方式聚焦于MLLM的某个特定方面,比如物体幻觉(Object Hallucination)[3]或者对抗鲁棒性[4],无法做全面评测。
目前亟需一个全面的评测基准来匹配MLLM的快速发展。我们认为一个通用的全面评测基准应该具有以下特点:
- 它应该覆盖尽可能多的范围,包括感知和认知能力。前者指的是识别物体,包括其存在性、数量、位置和颜色等。后者指的是综合感知信息以及LLM中的知识来进行更复杂的推理。其中前者是后者的基础。
- 它的数据或者标注应该尽可能避免采用已有的公开数据集,以减少数据泄露的风险。
- 它的指令应该尽可能简洁并且符合人类的认知习惯。不同的指令设计可能会极大影响模型的输出,但所有的模型都在统一的简洁指令下进行评测可以保证公平性。一个好的MLLM模型应该具备泛化到这种简洁指令上的能力,避免陷入Prompt Engineering。
- MLLM在该简洁指令下的输出应该是直观的并且便于定量统计。MLLM开放式的回答给量化统计提出了很大挑战。现有方法倾向于使用GPT或者人工打分,但可能面临着不准确和主观性的问题。
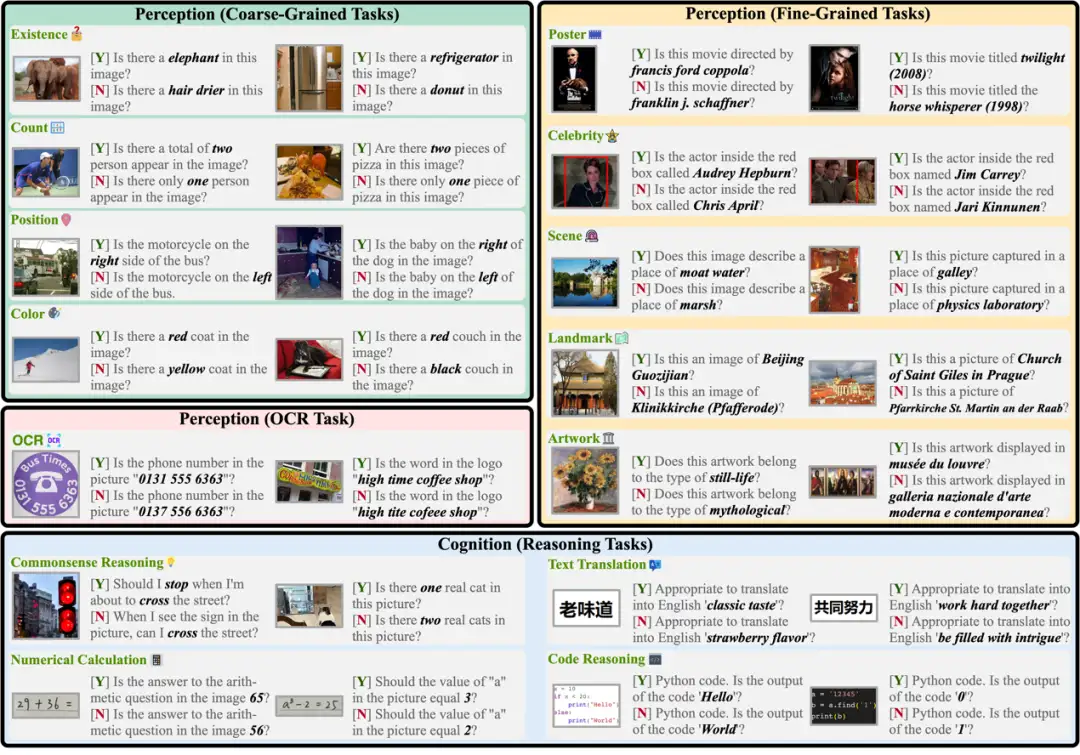
基于以上原因,一个新的MLLM评测基准MME被构建出来,它同时具备以上四个特点:
- MME同时评测感知和认知能力。除了OCR外,感知能力还包括粗粒度和细粒度目标识别。前者识别物体的存在性、数量、位置和颜色。后者识别电影海报、名人、场景、地标和艺术品。认知能力包括常识推理、数值计算、文本翻译和代码推理。总的子任务数达到14种,如图1所示。
- MME中所有的指令-答案对都是人工构建的。对于少量使用到的公开数据集,我们仅使用其图像而没有依赖其原始标注。同时,我们也尽力通过人工拍摄和图像生成的方式来采集数据。
- MME的指令被设计得尽量简洁以避免Prompt Engineering对模型输出的影响。我们再次申明一个好的MLLM应该泛化到这种简洁且使用频繁的指令,这对所有模型都是公平的。图1中显示了每个子任务的指令。
- 得益于我们的指令设计“Please answer yes or no”,我们可以方便地根据模型输出的“Yes”或“No”进行定量统计,这种方式可以同时保证准确性和客观性。值得注意的是我们也尝试过设计选择题的指令,但发现当前的MLLM还难以跟随这类较为复杂的指令。
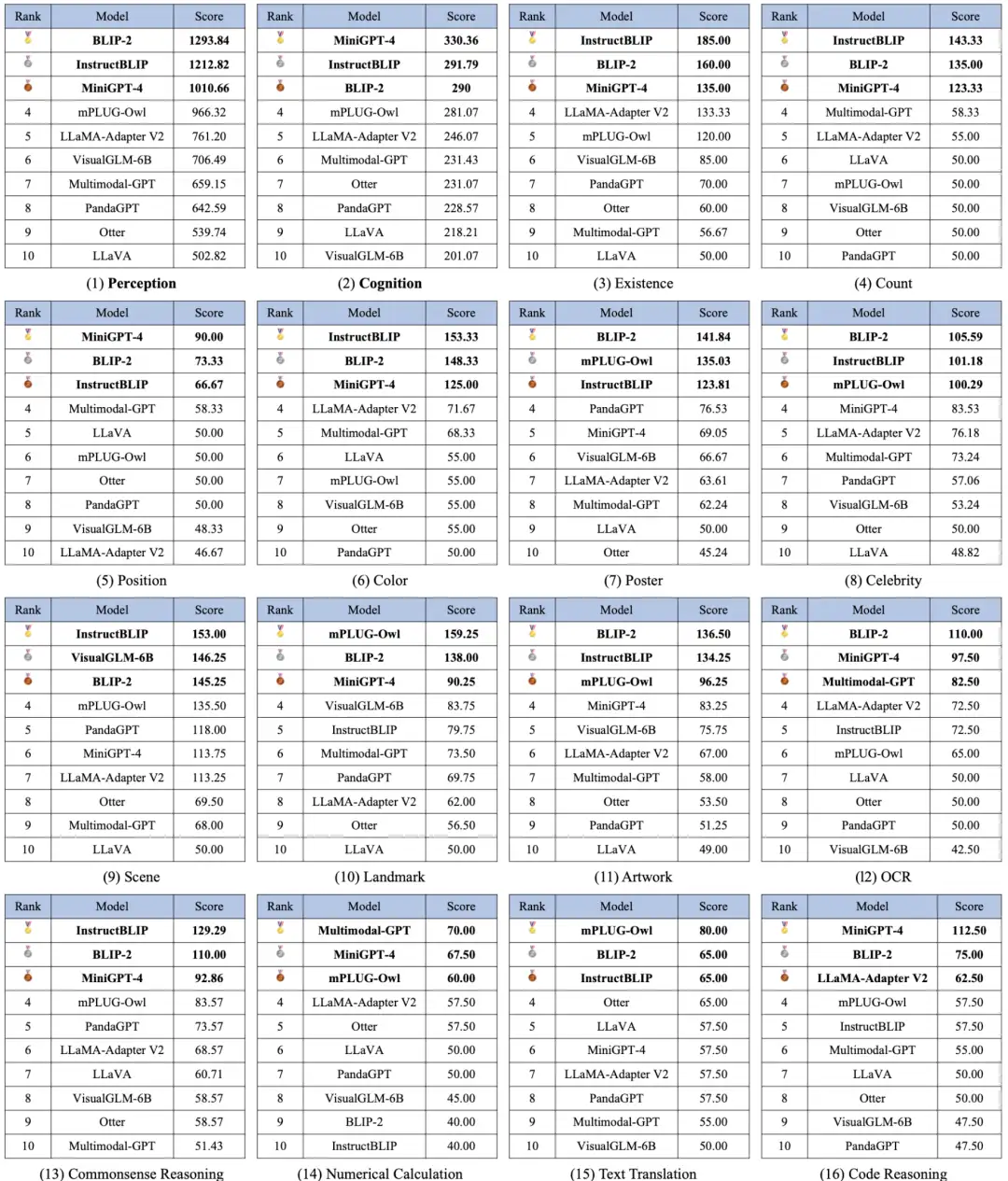
我们一共评测了10种先进的MLLM模型,包括BLIP-2 [5]、LLaVA [6]、MiniGPT-4 [7]、 mPLUG-Owl [2]、LLaMA-Adapter-v2 [8]、Otter [9]、Multimodal-GPT [10]、InstructBLIP [11]、 VisualGLM-6B [12]和PandaGPT [13]。我们的统计指标有三种,包括Accuracy,Accuracy+和Score。其中对于每个任务,Accuracy是基于问题统计而来,Accuracy+是基于图片统计而来(图片对应的两个问题都需要回答正确),Score是Accuracy和Accuracy+的和。感知的总分为10种感知类子任务Score的总和,认知的总分是4种认知类任务Score的总和。具体详见项目链接。10种模型在14种子任务上的测试比较如图2所示:
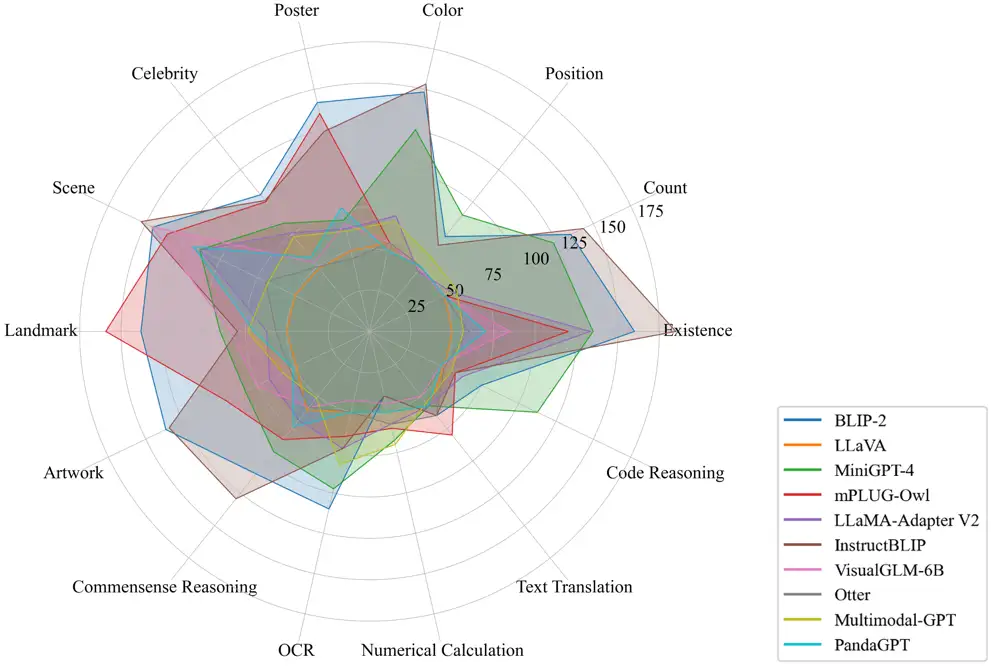
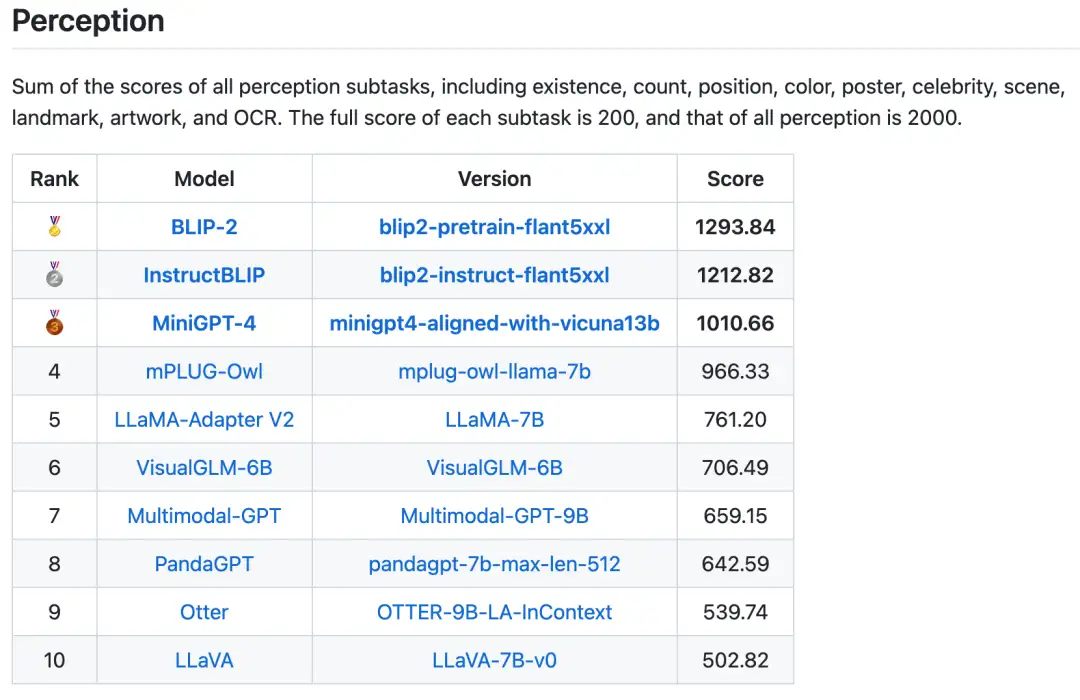
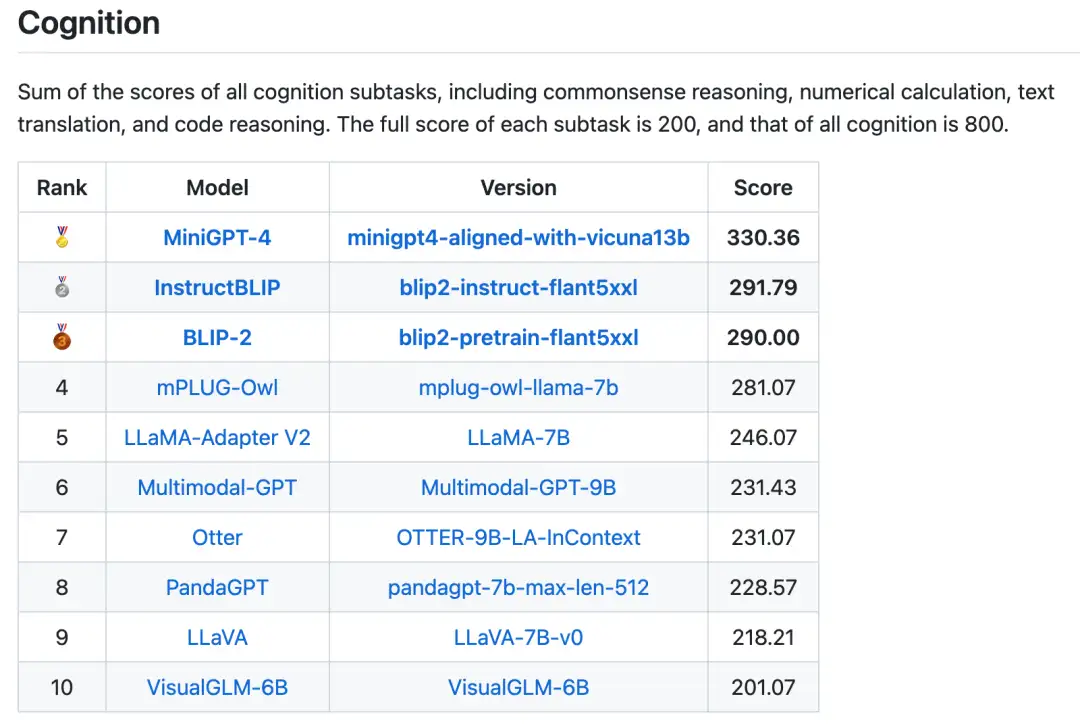
一共16个榜单,包括感知类和认知类的总榜单以及14个子任务的榜单也已发布。两个总榜单分别如图3和图4所示,其中BLIP-2、InstructBLIP和MiniGPT-4在这两个榜单中都保持在前三。在各个子任务中的榜单中也有其他模型冲进前三,如图5所示。值得注意的是InstructBLIP和MiniGPT-4都是基于BLIP-2进行多模态指令微调后得到。
另外我们也总结了MLLM模型在实验中暴露的一些通用问题,如图6所示,希望可以为后续的模型优化提供指导。

第一个问题是不跟随指令。尽管我们已经采用了非常简洁的指令设计,但仍然有MLLM自由回答问题而不是跟随指令。如图6中的第一行所示,指令已经申明“Please answer yes or no”,但MLLM仅给出了一个陈述性回答。如果在回答的开头没有出现“Yes”或者“No”,我们都判定该回答错误。一个好的MLLM,尤其是经过指令微调后,应该能够泛化到这种简单的指令上。
第二个问题是缺乏感知能力。如图6中的第二行所示,MLLM错误地识别了第一张图片中香蕉的数量和第二张图片中的数字,导致回答错误。我们也注意到感知的性能很容易受到指令变化的影响,因为同一张图的两个指令只相差一个单词,但导致了完全不同的感知结果。
第三个问题是缺乏推理能力。如图6中的第三行所示,从红色的文字可以看出MLLM已经知道了第一张图片不是一个办公场所,但仍然给出了一个错误的回答“Yes”。相似地,在第二张图片中,MLLM已经计算得到了正确的算数结果,但最终也给出了错误的答案。添加思维链Prompt,例如“Let’s think step by step”也许能带来更好的效果。我们期待这方面有更深入的研究。
第四个问题跟随指令的物体幻视。如图6中的第四行所示,当指令中含有图片中不存在的物体时,MLLM将会幻想该物体存在并最终给出一个“Yes”的回答。这种总是回答“Yes”的方式导致了Accuracy接近于50%,Accuracy+接近于0。这表明抑制目标幻视的重要性,并且我们也需要进一步思考MLLM生成的答案的可靠性。
更详细内容请查看论文和项目链接:
- 论文链接:https://arxiv.org/pdf/2306.13394.pdf
- 项目链接:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
参考文献:
[1] Zijia Zhao, Longteng Guo, Tongtian Yue, Sihan Chen, Shuai Shao, Xinxin Zhu, Zehuan Yuan, and Jing Liu. Chatbridge: Bridging modalities with large language model as a language catalyst. arXiv preprint:2305.16103, 2023.
[2] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint:2304.14178, 2023.
[3] Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. arXiv preprint:2305.10355, 2023.
[4] Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Chongxuan Li, Ngai-Man Cheung, and Min Lin. On evaluating adversarial robustness of large vision-language models. arXiv preprint:2305.16934, 2023.
[5] Junnan Li, DongxuLi, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint:2301.12597, 2023.
[6] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint:2304.08485, 2023.
[7] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint:2304.10592, 2023.
[8] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Con- ghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint:2304.15010, 2023.
[9] Bo Li,Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang,and ZiweiLiu. Otter: Amulti-modal model with in-context instruction tuning. arXiv preprint:2305.03726, 2023.
[10] Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang,Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans. arXiv preprint:2305.04790, 2023.
[11] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint:2305.06500, 2023.
[12] Visualglm-6b. https://github.com/THUDM/VisualGLM-6B, 2023.
[13] Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all. arXiv preprint:2305.16355, 2023.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
中科院自动化所发布FastSAM | 精度相当,速度提升50倍!!!
大核卷积网络是比 Transformer 更好的教师吗?ConvNets 对 ConvNets 蒸馏奇效
MaskFormer:将语义分割和实例分割作为同一任务进行训练
CVPR 2023 VAND Workshop Challenge零样本异常检测冠军方案
沈春华团队最新 | SegViTv2对SegViT进行全面升级,让基于ViT的分割模型更轻更强
刷新20项代码任务SOTA,Salesforce提出新型基础LLM系列编码器-解码器Code T5+
CVPR最佳论文颁给自动驾驶大模型!中国团队第一单位,近10年三大视觉顶会首例
最新轻量化Backbone | FalconNet汇聚所有轻量化模块的优点,成就最强最轻Backbone
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary