并行执行的方式
本节内容围绕一个程序,针对如何改变处理器的结构来加速程序提出了多个idea
示例程序:该程序通过泰勒展开式来估算sin(x)的值
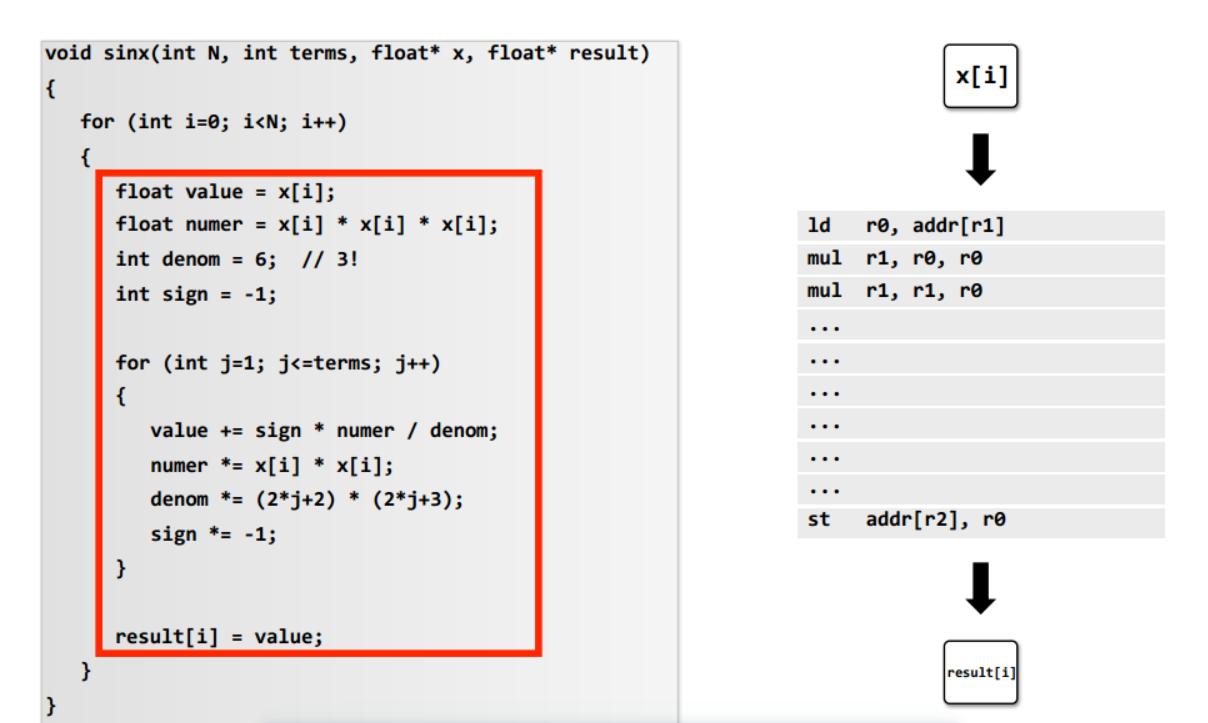
一个最简单的处理器,每个时钟周期只能执行一条指令,而利用ILP(指令级平行)的超标量处理器可同时执行两条指令(当指令间不存在依赖时),但示例程序存在数据依赖:
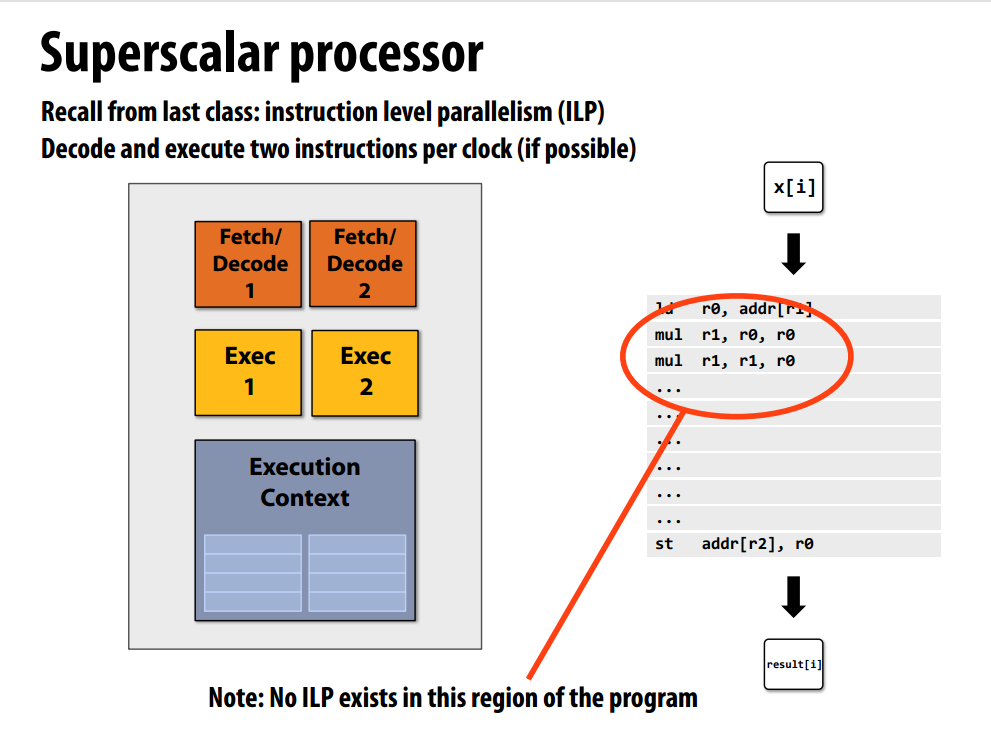
一个fancy的处理器,为上述的处理器增加包括乱序执行、分支预测、内存预取等复杂的逻辑部件加速程序。
idea1:增加处理器核心数
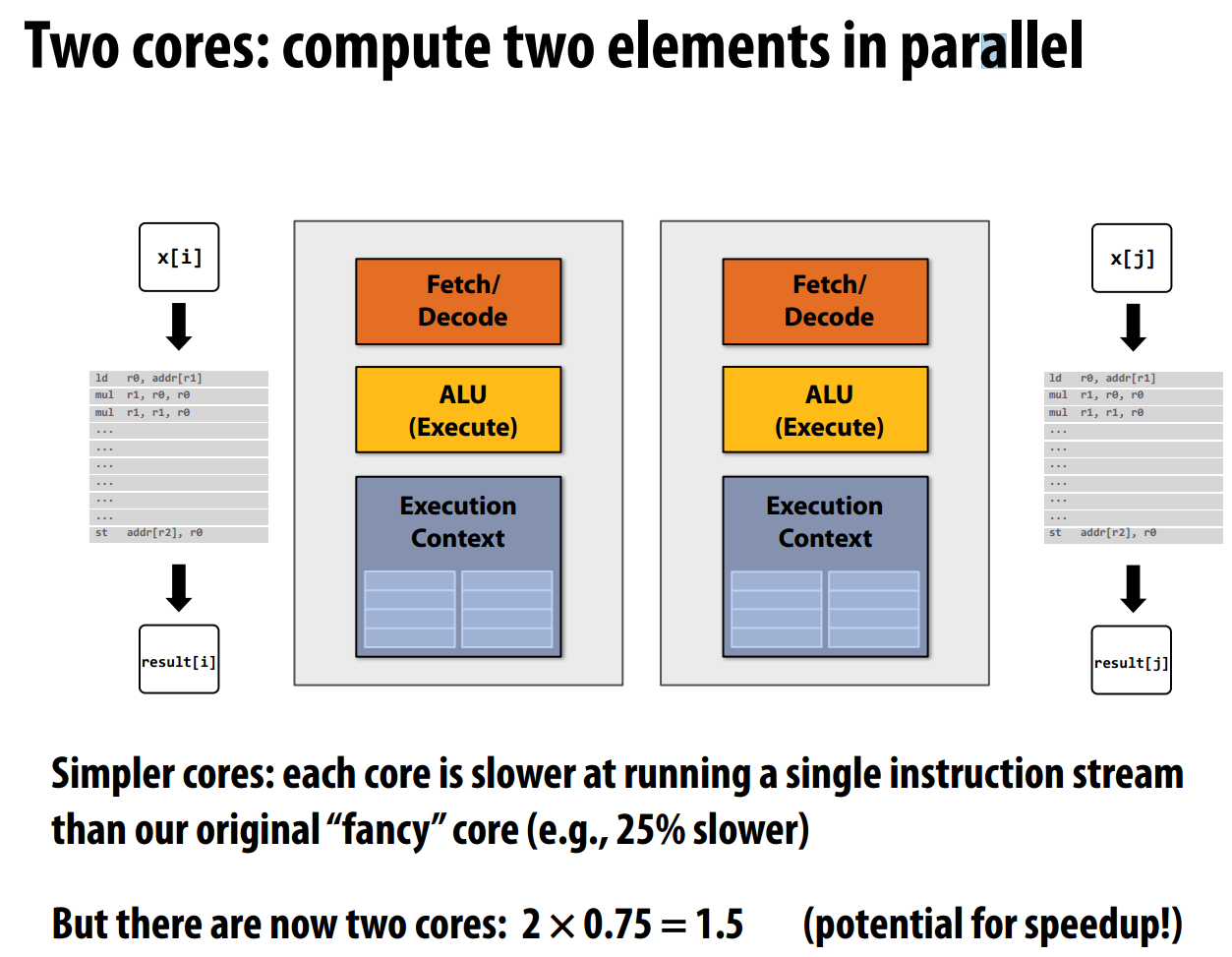
如果使用更多的晶体管来增加处理器核心数,而不是增加这些复杂的逻辑部件呢?我们可以得到两核处理器,由于去掉了复杂的逻辑部件,每个核心的速度会变慢,假设每个核心的速度只有原来的0.75,理想情况双核处理器的性能为0.75*2=1.5(由于示例程序存在数据依赖,实际加速达不到1.5)
利用pthread库不同的线程执行相互独立的任务,实现并行化。

利用forall循环并行化程序,在使用forall循环前,需要保证不同线程所执行的任务相互独立。

idea2:增加ALU提高计算能力
利用SIMD(单指令多数据),一条指令可以并行地在所有ALU中执行
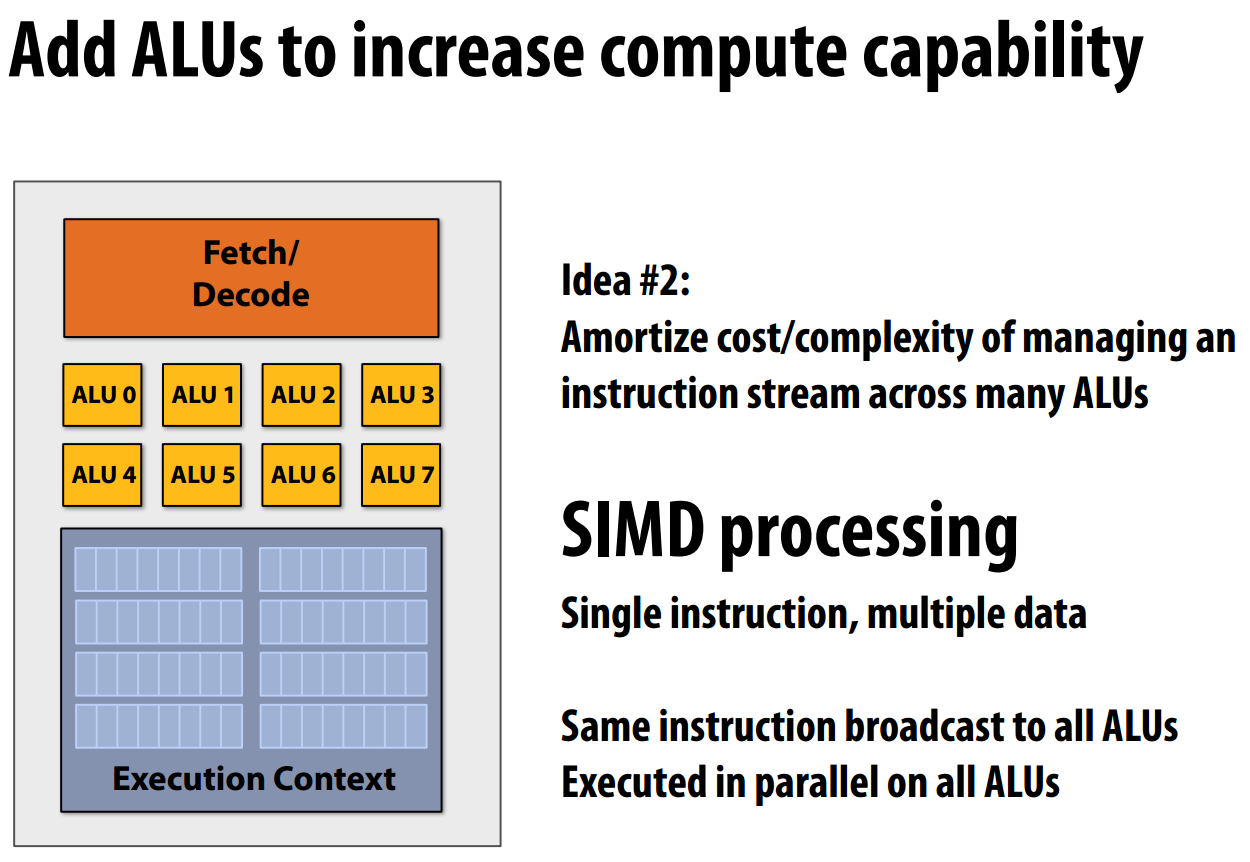
利用AVX指令可以每次同时处理8个数组元素,处理器中有专用的256位的寄存器,

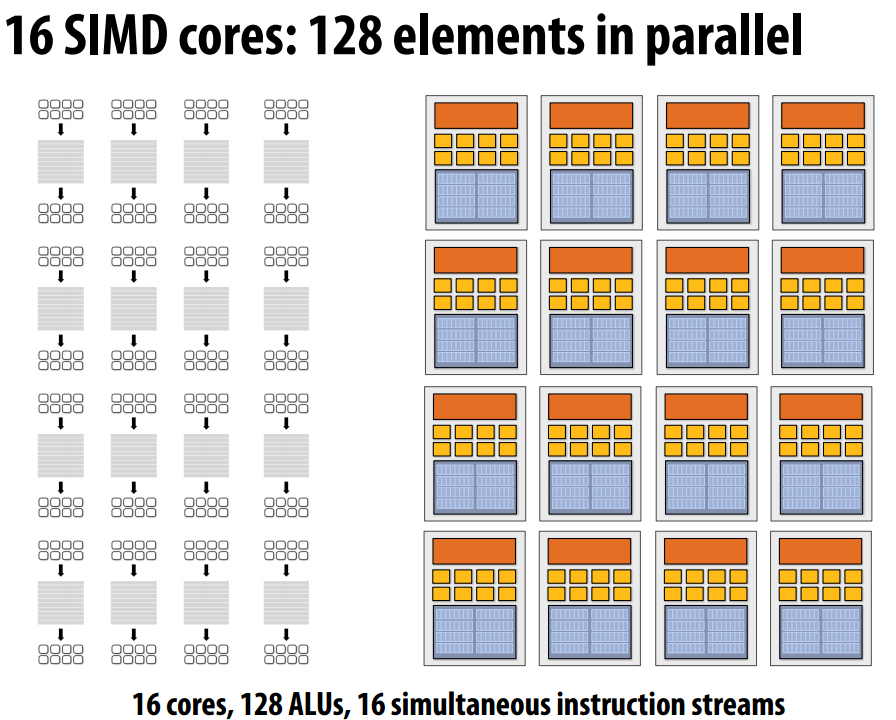
现在可以构建一个16核心数、128个ALU的处理器,该处理器每次可以并行地执行16条指令,每条指令可以处理八个数组元素的运算。
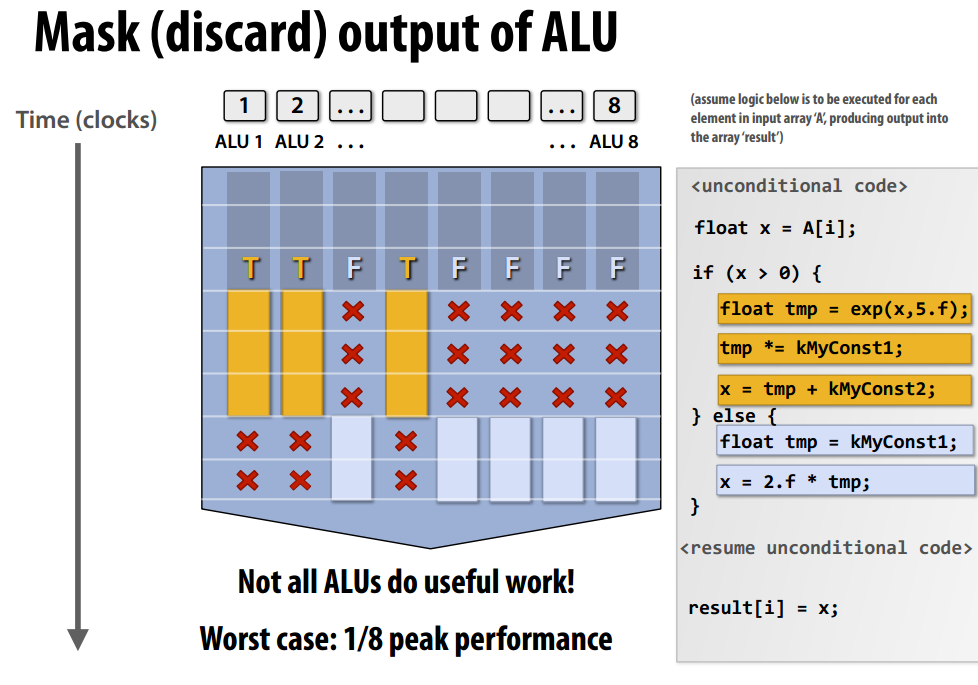
SIMD也可以处理if-else语句,SIMD会同时处理条件为true和false的分支,通过mask选择最终的结果,在下图中,ALU1、ALU2、ALU4处理if分支,因此后两个时钟周期的结果被忽略了。最差情况下,每个时钟周期只有一个ALU在工作,此时效率为理想情况的1/8。
小结
三种并行执行的方式:
- 多核:提供线程级并行,每个核可以执行不同的指令流,由软件决定何时创建线程。
- SIMD:相同指令流控制多个ALU(在单核中)。向量化可以由编译器或者硬件做,由于每个ALU执行的都是相同的操作,指令间的依赖关系需要由程序员声明。
- 超标量:提供指令级并行(在单核中),并行处理同一指令流的不同指令,并行性一般由硬件自动识别。
内存访问
首先给出两个术语:
- 内存延迟:指内存系统响应处理器一个请求(load、store)所需要的时间。
- 内存带宽:指内存系统提供处理器数据的速度。
降低、隐藏内存延迟的方式
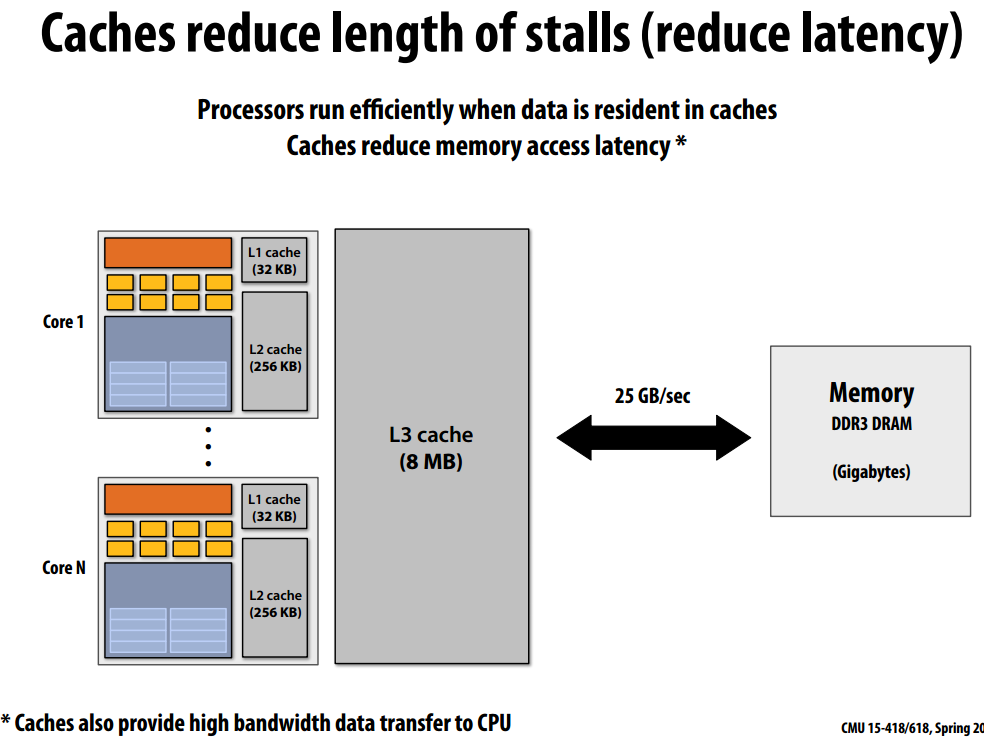
cache
当处理器不能执行下一条指令时(load、store操作),会暂停(stall),为了降低内存延迟,引入了cache,L1 cache存取延迟为3-4个时钟周期,而内存的存取延迟有上百个周期,引入cache降低了内存延迟。
预取
所有的现代CPU都会进行数据预取,通过某种预测逻辑将数据预先放到cache中。下图进行了对地址[r2]、[r3]的数据进行预取,这样两条load指令都能命中cache。预取是一种隐藏内存延迟的方法,内存数据被提前加载到cache中。

多线程
在同一核心上,利用多线程交错处理数据也是一种隐藏内存延迟的方法,为了实现多线程,每个线程都需要有独立的上下文环境。
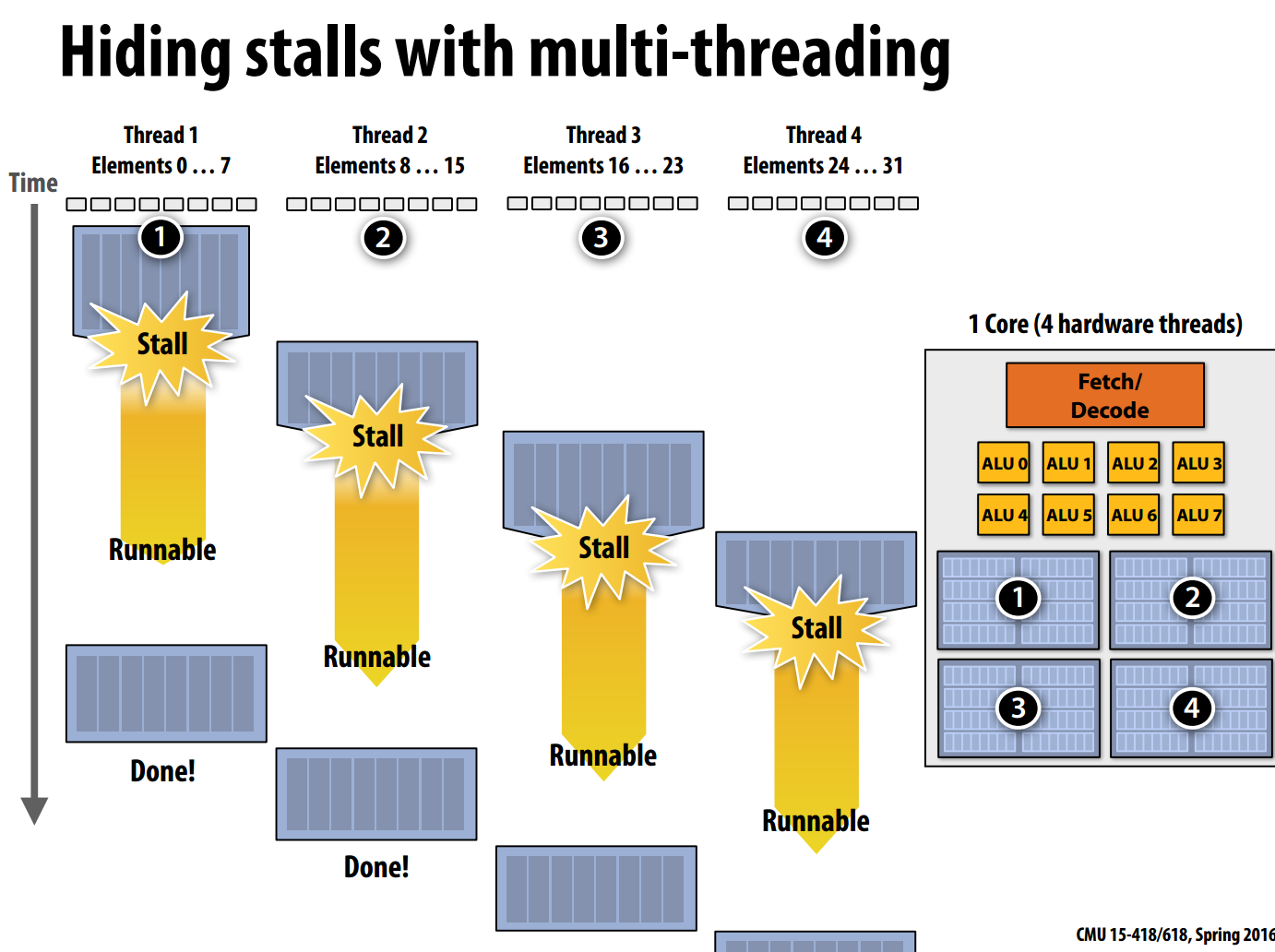
上图展示了四个线程交错处理数据,当Thread1需要stall时,处理器不会等待,而是切换到Thread2,依次类推。Thread1执行任务的延迟没有降低,反而升高了,但增加了处理器的吞吐量。通过多线程的方式来提高系统的吞吐量,这是面向吞吐量系统的设计原则。
多线程技术不在意内存延迟,但依赖内存带宽,只有当内存带宽足够大,才能充分发挥多线程的优势。

带宽的影响
即使处理器以高速请求数据,由于带宽的限制,再多的隐藏延迟的办法也没有用,下图是一个例子,由于显存带宽的速度为177GB/s,而为了使计算部件不停工作,需要至少6.4TB/s的带宽。

为了降低带宽的影响,高性能的并行程序需要做到两点:
- 重新组织计算尽可能少地访问内存。可以使用线程之前用过的数据(时间局部性),或者在线程之间共享数据。
- 做更多的算术运算,提高算术强度(arithmetic intensity)。
- Multi-Core Processor Lecture Modern Multimulti-core processor lecture modern multi-core processor lecture2 lecture multi-core parallelism multi-core exploring project multi-version concurrency lecture control processor two-processor processor homebrew install default processor 13023 text uva configuration annotation configured processor