#coding:utf-8 from sklearn.neural_network import MLPRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import numpy as np def ellipse(x): y = np.sqrt(1 - x**2/4.0) return y data = np.linspace(-2, 2, 2000) labels = ellipse(data) X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.1) X_train=X_train.reshape(-1,1) X_test=X_test.reshape(-1,1) mlp = MLPRegressor(hidden_layer_sizes=(5, 5, 5), max_iter=1000, batch_size=1, activation='tanh') mlp.fit(X_train, y_train) y_pred = mlp.predict(X_test) print('X_train.shape:', X_train.shape) print('y_train.shape:', y_train.shape) print('X_test.shape:', X_test.shape) print('y_test.shape:', y_test.shape) print('y_pred.shape:', y_pred.shape) print("mlp train score:", mlp.score(X_train, y_train)) print("mlp test score:", mlp.score(X_test, y_test)) print("预测的损失值:", mean_squared_error(y_pred, y_test)) print('查看预测情况:') for i in range(10): print(y_pred[i], y_test[i])
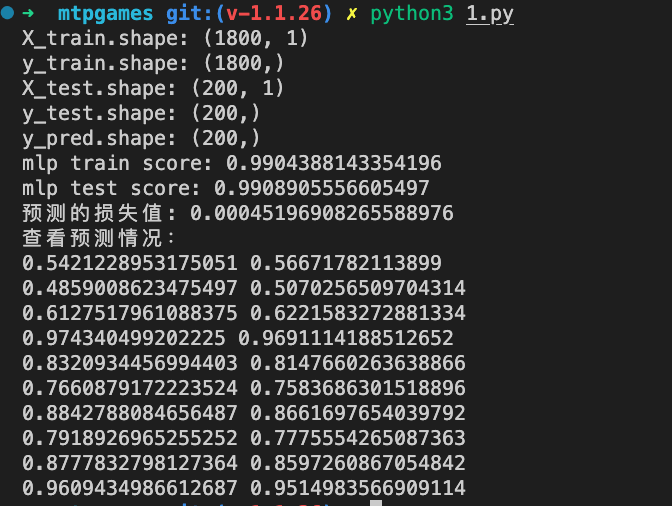
通过几次实验发现
初始化的权重对结果影响很大, batch_size并不总是越大越好