实验04 Pandas基础
实验学时:2学时
实验类型:验证
实验要求:必修
一、实验目的
1.掌握pandas系列、数据帧和面板的使用
2.掌握pandas基本功能和操作
二、实验要求
- Pandas 程序的运行步骤。
2.pandas的数据结构
3.pandas系列、数据帧和面板 - pandas基本功能和操作
三、实验内容
任务1.使用pandas创建100个随机整数Series,使用系列函数输出该系列、系列的索引值,判断系列是否为空,输出系列的维度值、大小和值,输出系列的前10个和后6个元素。用numpy、pandas和python编程实现。
任务2. 使用pandas创建50个人的随机名字,名字要求符合中国习惯(即“姓+名字”),统计这些名字中含“刚”字的个数。用numpy、pandas和python编程实现。
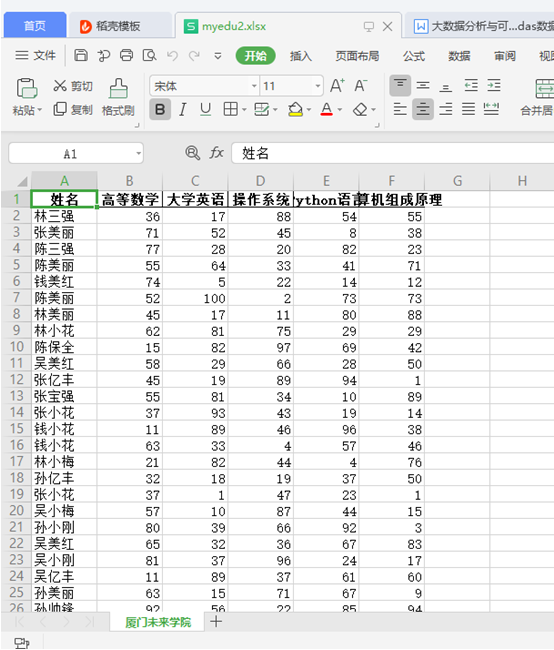
任务3. 产生某校5000个同学五门课程成绩数据,要求有“姓名、高等数学、大学英语、操作系统、Python语言、计算机组成原理”这些字段,将生成的数据存入“myedu.xlsx”文件中,sheet名称为“厦门未来学院”。用numpy、pandas和python编程实现。
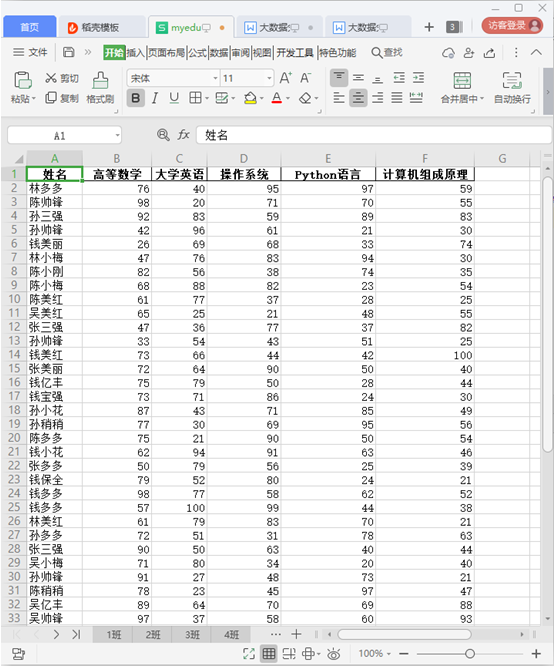
任务4. 产生500个班、每个班50名同学的五门课程成绩数据,要求有“姓名、高等数学、大学英语、操作系统、Python语言、计算机组成原理”这些字段,将生成的数据存入“myedu3.xlsx”文件中,工作表的名称为“1班”到“500班”。用numpy、pandas和python编程实现。
test4.py
import pandas as pd
import numpy as np
import random
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
def task1():
# 创建一个包含100个随机整数的Series
random_data = pd.Series(np.random.randint(1, 101, 100))
# 输出整个Series
print("整个Series:")
print(random_data)
# 输出Series的索引值
print("\nSeries的索引值:")
print(random_data.index)
# 判断Series是否为空
is_empty = random_data.empty
print("\nSeries是否为空:", is_empty)
# 输出Series的维度值
shape = random_data.shape
print("\nSeries的维度值:", shape)
# 输出Series的大小
size = random_data.size
print("\nSeries的大小:", size)
# 输出Series的值
values = random_data.values
print("\nSeries的值:")
print(values)
# 输出Series的前10个元素
print("\nSeries的前10个元素:")
print(random_data.head(10))
# 输出Series的后6个元素
print("\nSeries的后6个元素:")
print(random_data.tail(6))
def task2():
# 姓氏列表
surnames = ["赵", "钱", "孙", "李", "周", "吴", "郑", "王", "冯", "陈",
"楮", "卫", "蒋", "沈", "韩", "杨", "朱", "秦", "尤", "许",
"何", "吕", "施", "张", "孔", "曹", "严", "华", "金", "魏",
"陶", "姜", "戚", "谢", "邹", "喻", "柏", "水", "窦", "章",
"云", "苏", "潘", "葛", "奚", "范", "彭", "郎", "鲁"]
# 名字列表
names = ["刚", "强", "伟", "勇", "宏", "杰", "明", "峰", "飞", "军",
"创", "凯", "俊", "华", "兵", "龙", "良", "志", "威", "毅",
"洪", "涛", "建", "民", "文", "亮", "新", "波", "贵", "忠"]
# 随机生成50个名字
random_names = [random.choice(surnames) + random.choice(names) for _ in range(50)]
# 创建包含名字的Series
names_series = pd.Series(random_names)
# 统计含有“刚”字的名字个数
count_gang_names = names_series.str.count("刚").sum()
# 输出结果
print("50个随机名字:")
print(names_series)
print("\n含有“刚”字的名字个数:", count_gang_names)
def task3():
# 创建一个包含5000个同学的姓名数据
def generate_names(n):
first_names = ['张', '王', '李', '赵', '刘', '陈', '杨', '黄', '吴', '赖']
last_names = ['明', '伟', '芳', '刚', '婷', '华', '强', '亮', '艳', '静']
names = [f"{np.random.choice(first_names)}{np.random.choice(last_names)}" for _ in range(n)]
return names
data = {
'姓名': generate_names(5000),
'高等数学': np.random.randint(60, 101, 5000),
'大学英语': np.random.randint(60, 101, 5000),
'操作系统': np.random.randint(60, 101, 5000),
'Python语言': np.random.randint(60, 101, 5000),
'计算机组成原理': np.random.randint(60, 101, 5000)
}
# 创建数据框
df = pd.DataFrame(data)
# 保存到Excel文件
df.to_excel('myedu.xlsx', sheet_name='厦门未来学院', index=False)
print("数据已成功保存到myedu.xlsx文件。")
# 生成随机姓名数据
def generate_names(num_names):
names = []
for i in range(num_names):
names.append(f'Student {i + 1}')
return names
# 生成随机成绩数据
def generate_grades(num_students, num_courses):
return np.random.randint(0, 101, size=(num_students, num_courses))
def task4():
# 定义班级数和每班同学数
num_classes = 500
students_per_class = 50
# 创建一个Pandas DataFrame并存储为Excel文件
writer = pd.ExcelWriter('myedu1.xlsx', engine='xlsxwriter')
for i in range(num_classes):
class_name = f'{i + 1}班'
names = generate_names(students_per_class)
grades = generate_grades(students_per_class, 5)
data = {
'姓名': names,
'高等数学': grades[:, 0],
'大学英语': grades[:, 1],
'操作系统': grades[:, 2],
'Python语言': grades[:, 3],
'计算机组成原理': grades[:, 4]
}
df = pd.DataFrame(data)
df.to_excel(writer, sheet_name=class_name, index=False)
writer.save()
if __name__ == '__main__':
task1()
task2()
task3()
task4()