Learning Continuous Image Representation with Local Implicit Image Function(阅读笔记)11.03
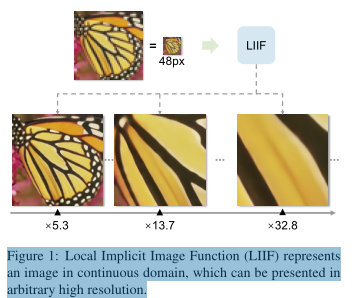
局部隐式图像函数(LIIF)表示连续中的图像,可以以任意高分辨率表示。
摘要:如何表示图像?当视觉世界以连续的方式呈现时,机器用二维像素数组以离散的方式存储和观看图像。本文中,试图学习图像的连续表示。受隐式神经表示在三维重建中的最新进展的启发,我们提出了局部隐式图像函数(LIIF),它以图像坐标和坐标周围的二维深度特征为输入,预测给定坐标的RGB值作为输出。由于坐标是连续的,LIIF可以以任意分辨率表示。为了生成图像的连续表示,我们通过具有超分辨率的自监督任务来训练具有LIIF表示的编码器。学习到的连续表示可以用任意分辨率表示,甚至可以外推到x30更高的分辨率,其中不提供训练任务。我们进一步证明,LIIF表示在二维离散和连续表示之间建立了一个桥梁,它自然地支持具有大小变化的图像(真实)的学习任务,并显著优于具有调整(真实)大小的方法。
- 介绍
视觉世界连续。机器处理场景要将图像存储表示为2D像素数组。分辨率控制复杂性和精度之间的权衡。各种计算机视觉任务中,这种像素表示受到分辨率限制。调整图像分辨率会牺牲保真度。本文建议研究图像的连续表示,不用固定分辨率表示图像。通过图像建模为连续域上的函数,可以在需要时以任意分辨率恢复和生成图像。
如何将图像表示为连续函数呢?本文灵感来源于最近3D形状重建的隐式神经表示的进展。隐式神经表示关键思想:将对象表示为一个函数,函数将坐标映射到相应的信号(例如三维物体的表面符号距离,图像中的RGB值),其中函数有深度神经网络参数化。跨实例共享知识,不是单个对象拟合单个函数,提出基于编码器的方法来预测不同的对象的潜码,解码函数由所有对象共享,将潜码作为坐标的额外输入。尽管隐式神经表示在3D任务中取得成功,但以往基于编码器的隐式神经表示方法仅仅能表示数字等简单图像。
本文中提出局部隐式图像函数(LIIF)来连续表示图像和复杂图像。LIIF中图像表示一组分布上在空间维度上的潜码。给定一个坐标,解码函数将坐标信息作为输入,查询坐标周围的局部潜码,然后预测给定坐标处的RGB值作为输出。因为坐标是连续的,LIIF可以以任意分辨率表示。
为了生成像素图像的连续表示,因为希望生成的连续表示比输入图像得到更高的精度,通过具有超分辨率的自监督任务训练带有LIIF表示的编码器,输入和ground-truth以连续变化的上采样尺度提供。本任务像素图像为输入,训练编码器的LIIF表示来预测输入的更高分辨率对应物。LIIF是连续的,可以表明它可以以任意高分辨率表示,甚至在不提供训练人物的情况下外推到x30更高分辨率。
本文证明LIIF在离散和连续表示之间建立了桥梁。在大小不等的图像真实学习任务中,LIIF可以很自然的利用不同分辨率提供的信息。之前方法固定大小输出要调整groundtruth到相同大小训练,可能牺牲保真度。但LIIF表示可以以任意分辨率表示,因此可以不调整ground truth的大小的情况下进行端到端的方式进行训练,效果明显优于调整ground truth的方法。
- 相关工作
隐神经表示:隐式神经表示中对象通常表示为一个多层感知机,它将坐标映射到信号。该方法广泛应用于三维物体形状建模、场景表面的三维表面建模以及三维结构的外观建模。例如:通过学习使用多个图像视图的特定场景的隐式表示来执行新颖的视图合成。连续隐式表示可以用少量参数捕捉形状的非常精细的细节。它的可微性也允许反向传播通过模型神经渲染。
学习内隐函数空间:最近的研究没有为每个对象学习一个独立的隐式神经表示,而是为不同对象的隐式表示共享一个函数空间。通常,潜空间定义为每一个对象对应一个潜码。潜码可以通过自动解码器优化获得。例如:学习每个物体形状的符号距离函数(SDF),通过改变输入潜码推断不同的SDF。本文没有使用自动解码器,而是使用自动编码器架构,为大量不同样本之间的知识共享一个高效有效的方式。例如:对给定图像作为输入的潜码进行估计,并对潜码使用占用函数条件作用对输入对象进行三维重构。
隐式神经表示在3D中成功,但在图像表示还不足。LIIF是基于局部潜码的,可以恢复自然和复杂图像的精细细节。类似的公式最经被提出来用于超分辨物理约束解。LIIF专注于学习连续图像表示,并有特定于图像的设计选择。
图像生成和超分辨率:给定一张图像作为输入,将其翻译成不同的格或域。与基于反卷积的方法不同,LIIF表示支持通过独立查询与生成的隐式表示在不同坐标上的像素来执行真实和高分辨的图像生成。以前的大多数超分辨模型都是为特定比例尺的上采样而设计的,而本文的目标是学习可以以任意高分辨率表示的连续表示。这方面,本文和MetaSR在放大任意超分辨率方面有关。他们的方法通过元网络生成一个卷积上采样层,虽然可以在训练尺度上进行任意上采样,但在推广到训练分布之外的更大规模综合时,其性能有限。另一方面,当使用从×1到×4的任务训练LIIF表示时,可以在一次正向传递中基于连续表示生成×30的高分辨率图像。
- 局部隐式图像函数
在LIIF表示中,每个连续图像I(i)表示为二维特征映射M (i)∈R[H×W ×D]。解码函数fθ(以θ为参数)为所有图像共享,它被参数化为MLP,形式为: s = fθ(z,x) (1) ,z表示一个向量,x ∈ X是连续图像域中的二维坐标 ,s ∈S是预测信号(RGB值)。在实践中,我们假设x的范围是[0,2h]和[0,2w]两个维度。在fθ有定义的情况下,每个向量z都可以被认为代表一个函数fθ(z,·):X→S,即一个将坐标映射到RGB值的函数。我们假设M (i)的H × W特征向量(从现在起称为潜码)均匀分布在I (i)连续图像域的二维空间中(如图2中的蓝色圆),然后为它们分别分配一个二维坐标。对于连续图像I(I),坐标xq处的RGB值定义为
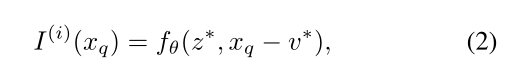
其中z *是M (i)中距xq最近的(欧氏距离)潜码,v *是潜码在像域中z *的坐标。以图2为例,在我们当前的定义中,z * 11是xq的z * ,而v * 则被定义为z * 11的坐标。
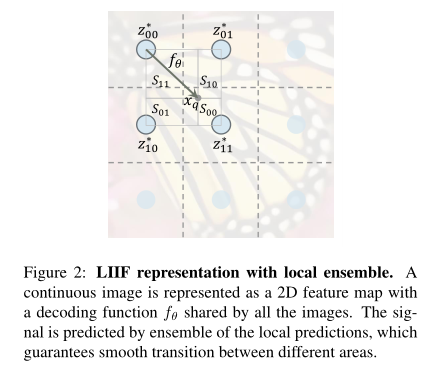
图2:带局部集成的LIIF表示。将连续图像表示为二维特征映射,所有图像共享解码函数f θ。采用局部预测集的方法对信号进行预测,保证了信号在不同区域之间的平滑过渡。
综上所述,在所有图像共享fθ的情况下,连续图像表示为二维特征映射M( I )∈R[H×W ×D],可视为均匀分布在二维域中的H x W潜码。 M ( I )中的每个潜码z代表连续图像的一个局部片段,它负责预测最接近自己的坐标集的信号。
特征展开:为了丰富M (i)中每个潜码所包含的信息,我们将特征展开应用到M ( I )中,得到M’( I )。M’( I )中的一个潜码是M( I ) 中3x3领潜码的拼接。在形式上,特征展开被定义为
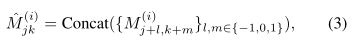
其中Concat指的是一组向量的拼接,M ( I )由其边界外的零向量填充。在特征展开之后,对任何计算,都用的M ‘( I )代替M ( I )。为了简单起见,我们将在以下部分中只使用符号M ( I ),而不考虑特征展开。
Local ensemble:方程2中的一个问题是不连续预测。具体来说,由于在xq处的信号预测是通过查询M (i)中最近的潜码z *来完成的,当xq在二维域中移动时,z *的选择可以突然从一个切换到另一个(即最近潜码的选择发生了变化)。例如,当xq穿过图2中的虚线时,就会发生这种情况。在那些选择z *开关的坐标周围,两个无限接近的坐标的信号将由不同的潜码预测出来。只要学习的函数fθ不是完美的,不连续的图案就会出现在这些z *选择开关的边界上。
为了解决这个问题,如图2所示,我们将等式2扩展为:
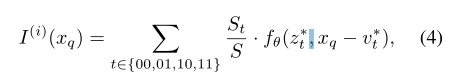
其中z * t (t∈{00,01,10,11})是左上、右上、左下、右下子空间中最接近的潜码,v * t是z * t的坐标,St是xq和v * t‘之间的矩形的面积,其中t‘是t的对角线(即00到11,10到01)。权值归一化通过
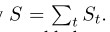 我们认为特征映射M (i)在边界外是镜面填充的,因此上述公式对边界附近的坐标也适用。
我们认为特征映射M (i)在边界外是镜面填充的,因此上述公式对边界附近的坐标也适用。
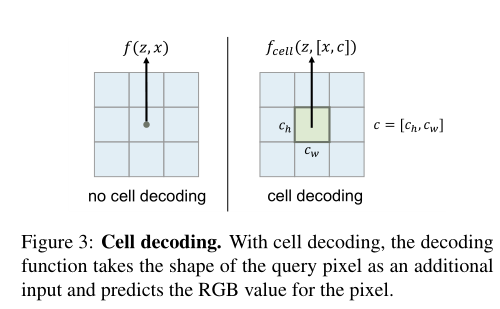
图3:单元解码。对于单元格解码,解码函数将查询像素的形状作为附加输入,并预测像素的RGB值。
直观地说,这是让局部潜码所代表的局部片段与其相邻的局部片段重叠,这样在每个坐标上都有四个独立预测信号的潜码。然后,通过使用归一化置信度投票将这四个预测合并,该置信度与查询点与其最近的潜码对角线对应点之间的矩形面积成正比,因此,当查询坐标越接近时,置信度越高。它在z∗开关的坐标处实现连续过渡(例如,图2中的虚线)。
Cell decoding:实践中,希望LIIF表示能够以任意分辨率的基于像素的形式表示。假设给定所需的分辨率,直接的方法是查询连续表示I( I )(x)中像素中心坐标处的RGB值。虽然这已经可以很好的工作,但它可能不是最佳的,因为查询像素的预测RGB值与它的大小无关,它的像素区域中的信息除了中心值外都被丢弃。
为了解决这个问题,我们添加1了如图三所示的单元解码。我们将等式1中的f重新表示为fcell:
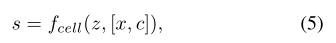
c = (ch, cw)包含两个值,指定查询的高度和宽度的像素,[x, c]是指x和c的连接。fcell的意义(z, [x, c])可以解释为:RGB值应该是什么,如果我们呈现一个像素为中心的坐标x形状c。在实验中,我们将展示在一个额外的输入c可以是有益的,当呈现连续表示在给定的分辨率。
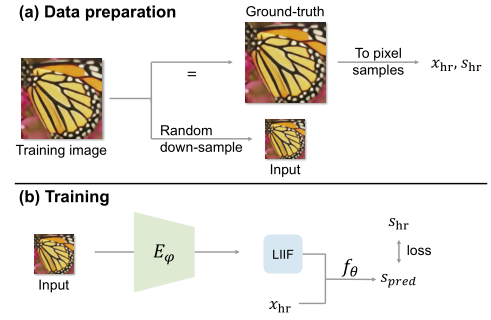
图4:学习像素图像的生成连续表示。自监督超分辨任务中,编码器LIIF表示联合训练,以鼓励LIIF表示在更高分辨率下保持高保真度。
- 学习连续图像表示
学习为图像生成连续表示的方法。图4展示了一个概述。形式上,在这个任务中,我们有一组图像作为训练集,目标是为一个看不见的图像生成一个连续的表示。
总体思想是训练一个编码器E,将图像映射到二位特征映射,作为其LIIF表示,联合训练所有图像共享的函数f θ。希望生成的LIIF表示不仅能重构输入,作为连续表示法,即使在较高的分辨率下也能保持较高的保真度。因此,建议在超分辨率的自监督任务中训练该框架。
先以单个训练图像为例,如图4,对于训练图像随机尺度下降采样生成一个输入。将训练图表示为像素样本xhr,shr,得到一个ground -truth, 其中xhr为像素在图像域中的中心坐标,shr为像素对应的RGB值。编码器Eφ将输入图像映射到2D特征映射作为其LIIF表示。然后使用坐标xhr对LIIF表示进行查询,其中fθ根据LIIF表示预测每个坐标的信号(RGB值)。让spred表示预测信号,然后在Spred和地面真相shr之间计算一个训练损耗(在我们的实验中是L1损耗)。对于批处理训练,我们从训练集中采样批,其中损失是实例的平均值。当进行单元解码时,我们将x替换为[x, c]。

学习连续表征的定性比较。输入是来自DIV2K验证集图像的48 × 48补丁,红色框表示用于演示的作物区域(×30)。SIREN是指对输入图像拟合一个独立的隐式函数。在×1 -×4上对MetaSR和LIIF进行了连续随机尺度的训练,并在×30上对其进行了测试,以评估连续表示对任意高精度的泛化能力。

- 实验
学习连续图像表示设置:DIV2K数据集(800张图片训练,验证集100张图像以及set5,set14,b100,urban100)进行学习连续图像表示的实验(下采样是双三次插值)。
目标是为基于像素的图像生成连续表示。连续表示期望具有无限的精度,可以在保持高保真的同时以任意的高分辨率表示。因此,为了定量评估学习到的连续表示的有效性,除了评估属于训练分布的标度的上采样任务外,我们还建议评估不属于训练分布的超大上采样标度。具体而言,在训练时间内,上采样标度在×1 -×4(连续范围)内统一采样。在测试期间,模型在不可见的图像上评估,具有更高的上采样尺度,即×6 -×30,这是训练期间不可见的尺度。非分布任务评估连续表示是否可以推广到任意精度。
实现细节:使用48x48的patch作为编码器输入,编码器(EDSR或RDN), 它们生成与输入图像相同大小的特征映射。解码函数fθ是一个具有ReLU激活的5层MLP,隐藏尺寸为256。我们遵循[24],使用L1损失。我们使用初始学习率为1·10−4的Adam[21]优化器,对模型进行1000课时的训练,批次大小为16,学习率每200课时衰减0.5因子.
定量结果:
- 结论
本文提出用于连续图像表示的局部隐式图像函数(LIIF)。在LIIF表示中,每幅图像都表示为二维特征映射,所有图像共享一个解码函数,根据输入坐标和相邻特征向量输出RGB值。
通过在具有超分辨率的自监督任务中训练具有LIIF表示的编码器,可以为基于像素的图像生成连续的LIIF表示。连续表示可以以极高的分辨率呈现,我们证明它可以推广到比训练量表更高的精度,同时保持高保真度。我们进一步证明了LIIF表示在二维离散和连续表示之间建立了一座桥梁,它提供了一个框架,可以自然和有效地利用来自不同分辨率图像的ground-truth信息。在未来的工作中,我们可能会探索解码功能更好的架构,以及在其他图像到图像任务上的更多应用。
二遍:
局部隐式图像函数(LIIF):
将每一个连续的图像I都会表达成2D的特征图M(H*W*D)(D代表图像的通道数?)。解码函数所有图像共享参数,解码的函数由带有参数的MLP获得,数学表达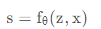 ,z代表一个向量,理解为隐藏的特征编码,x是连续图像坐标域上的一个2D的坐标,s是预测的值,比如rgb的颜色值。
,z代表一个向量,理解为隐藏的特征编码,x是连续图像坐标域上的一个2D的坐标,s是预测的值,比如rgb的颜色值。
有一个所有图像共享的函数F,图像的连续表达形式是M,被视为H*W大小的潜在编码。在M中的潜在编码,表示连续图像的局部特征,将为该局部块的所有连续坐标的输出负责。
特征展开:
为了丰富M中每个潜在编码的信息丰富度,将M扩展为M’,在M‘中,每一个潜在编码都变成原本3*3的相邻潜在编码的连接。超出边界的部分直接补零,然后所有需要2D特征图的地方都换成M’。
局部集和:
预测公式而言,预测也是不连续的。就是由于xq区域的预测是通过查询最近的潜在编码z*获得的,xq随在2D域上的移动,z*会突然变化。
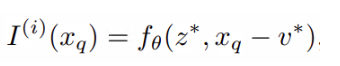
解决方式:zt*表示左上、右上、左下、右下四个位置的潜在编码,vt*是zt*的坐标,St表示xq和vt’*之间的矩阵,t‘和t呈对角关系。这里S是四个St的和。用来进行归一化。
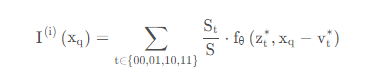
这样做的目的是使得由局部潜在编码所表示的局部片段能够和其周围的局部片段有所重合,进而使得每一个坐标处都有四个独立的潜在编码对其进行独立的预测,且这四个独立预测的结果将进行加权,即为最终的预测结果。
这样就可以在z*变化换的时候平滑的过渡。?
单元解码:
解决查询像素的预测RGB与其大小无关,像素区域中的信息除了中心值外都被丢弃。添加单元解码c = [ch,cw]包含两个指定查询像素的高度和宽度的值,[x,c]表示x和c的连接(即c是附加输入)。使用形状c渲染以坐标x为中心的像素(例如,对于64 × 64分辨率的渲染,c是图像宽度的1/64),则可以将fcell(z,[x,c])的含义解释为RGB值。逻辑上,当c → 0时,f(z,x) = fcell(z,[x,c]),即连续图像可以被视为具有无限小像素的图像。
生成的特征图大小与输入图像相同。隐式函数fθ是一个5层MLP函数,其ReLU激活和隐藏维数为256。我们利用L1损失。
- Image Representation Continuous Learning Functionimage representation continuous learning representation incremental classifier learning representation sparsification learning robust representation generative synthesis learning representation unsupervised degradation learning continuous continuous-time applications lightweight continuous framework addressing continuous prediction feedback interpolation neighborhood experience continuous