Hello,大家好,上一篇博文聊了一下Hive的基本知识,为了让大家更深入地理解Hive,本篇就写一下Hive的体系架构吧。
先看一张图:
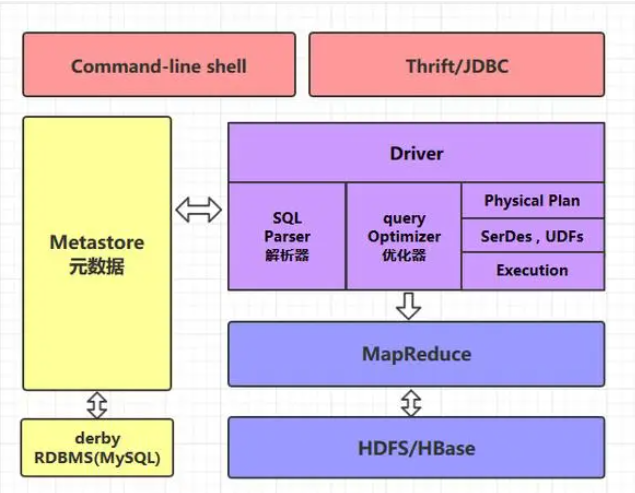
大概解释一下:
-
command-line shell & thrift/jdbc
可以用 command-line shell 和 thrift/jdbc 两种方式来操作数据:
command-line shell:通过 hive 命令行的的方式来操作数据;
thrift/jdbc:通过 thrift 协议按照标准的 JDBC 的方式操作数据。
-
Metastore
在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。所有的元数据默认存储在 Hive 内置的 derby 数据库中,但由于 derby 只能有一个实例,也就是说不能有多个命令行客户端同时访问,所以在实际生产环境中,通常使用 MySQL 代替 derby。
Hive 进行的是统一的元数据管理,也就是说你在 Hive 上创建了一张表,然后在 presto/impala/spark sql 中都是可以直接使用的,它们会从 Metastore 中获取统一的元数据信息。
- HQL的执行流程
Hive 在执行一条 HQL 的时候,会经过语法解析、优化、翻译等过程。
OK,关于Hive的体系架构就写到这里啦,大家加油哦~~~