一、选题背景介绍及选题意义
本研究旨在探究影响数据科学家薪酬的因素,通过分析相关数据集来寻找这些因素与工资之间的关系。随着数据科学职业的不断发展,对于雇主和雇员来说,了解可能影响薪酬的因素非常重要。本分析将探讨各种因素,包括个人背景、工作经验、技能、地理位置等,以及这些因素对数据科学家薪酬的影响程度。该研究将对数据科学领域的从业者和招聘者提供有价值的信息,帮助他们做出更明智的职业和招聘决策。
二、大数据分析方案
准备数据:
获取科学家薪酬数据,包括work_year,experience_level,employment_type,job,_title,salary_currency,salayinusd,employee_resident,remote_ratio,company_location等数据
。
使用工具如Excel、Python的Pandas库、或其他数据处理工具整理和清理数据。
选择关键指标:
从财务报表中选择关键的财务指标,例如work_year,experience_level,employment_type,job,_title等。
确定分析方向:
定义您希望分析的方向,例如年纪对薪酬的影响,工作时间对薪酬的影响等等。
确定关键的业务问题,以便有针对性地进行可视化分析。
选择可视化工具:
选择适当的可视化工具,如Matplotlib、Seaborn、Plotly(Python库)、Tableau、Power BI等。
根据分析需求选择合适的图表类型,如折线图、柱状图、饼图等。
创建可视化图表:
根据选定的指标和分析方向,创建相应的可视化图表。
可以制作趋势图、对比图、饼图、雷达图等,以展示不同财务指标的变化。
三、数据集简介
数据集包括以下变量:work_year:支付工资的年份。experience_level:一年中工作的经验水平。EN>入门级/初级MI>中级/中级SE>高级/专家执行级/主任employment_type:角色的雇用类型。PT>兼职FT>全职CT>合同FL>自由职业者job_title:这一年中担任的角色。工资:支付的工资总额。salary_currency:作为ISO 4217货币代码支付的工资的货币。salayinusd:以美元为单位的工资。employee_resident:作为ISO 3166国家代码,员工在工作年度的主要居住国。remote_ratio:远程完成的总工作量。company_location:雇主主要办事处或合同分公司所在的国家。company_size:一年中为公司工作的人数中值。
四、数据分析步骤
1.数据源 kaggle,具体网址来源Data Science Job Salaries (kaggle.com)
2.数据清洗
1 import numpy as np 2 import pandas as pd 3 df = pd.read_csv('ds_salaries.csv') 4 print(df.head())
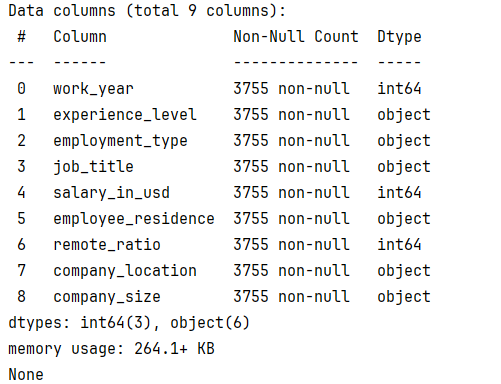
1 #这里统一用slary_in_usd为标准计量工资 2 df.drop(columns=['salary', 'salary_currency'], inplace=True) 3 4 print(df.info())
3.数据可视化
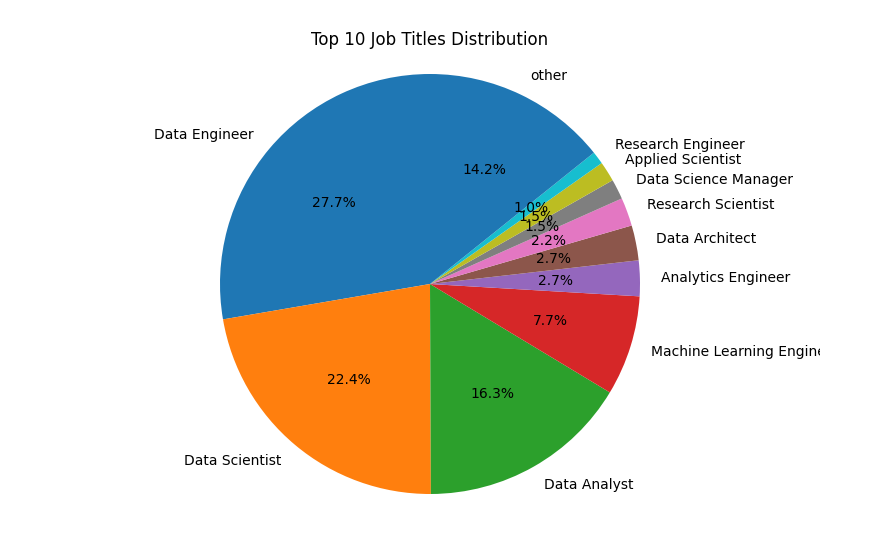
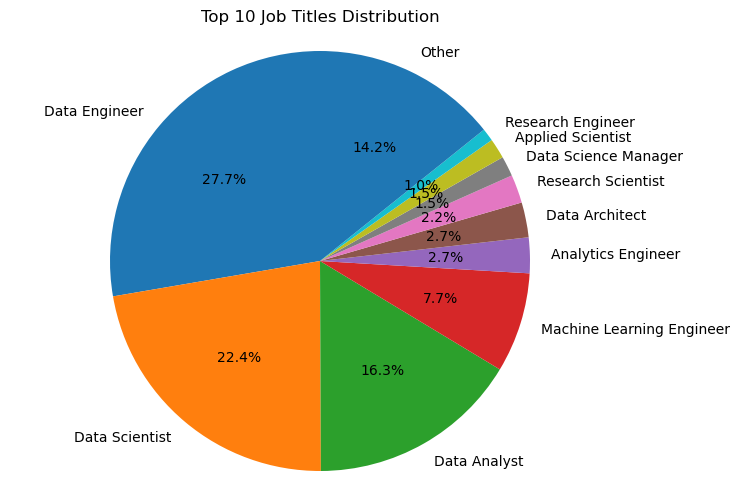
1 # 计算每个职位的出现次数 2 job_counts = df['job_title'].value_counts() 3 4 # 取前十个职位和其出现次数 5 top_10_jobs = job_counts.head(10) 6 other_jobs = job_counts[10:].sum() 7 8 # 构建饼图数据 9 job_labels = top_10_jobs.index.tolist() 10 job_labels.append('other') 11 job_sizes = top_10_jobs.tolist() 12 job_sizes.append(other_jobs) 13 14 15 # 绘制饼图 16 plt.figure(figsize=(8, 6)) 17 plt.pie(job_sizes, labels=job_labels, autopct='%1.1f%%', startangle=90) 18 plt.title('Top 10 Job Titles Distribution') 19 plt.axis('equal') 20 plt.show()
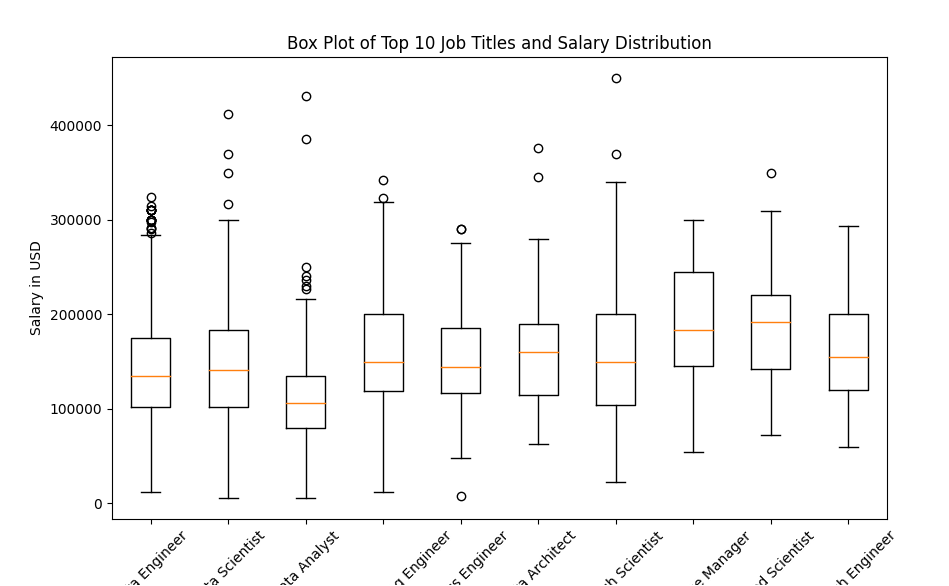
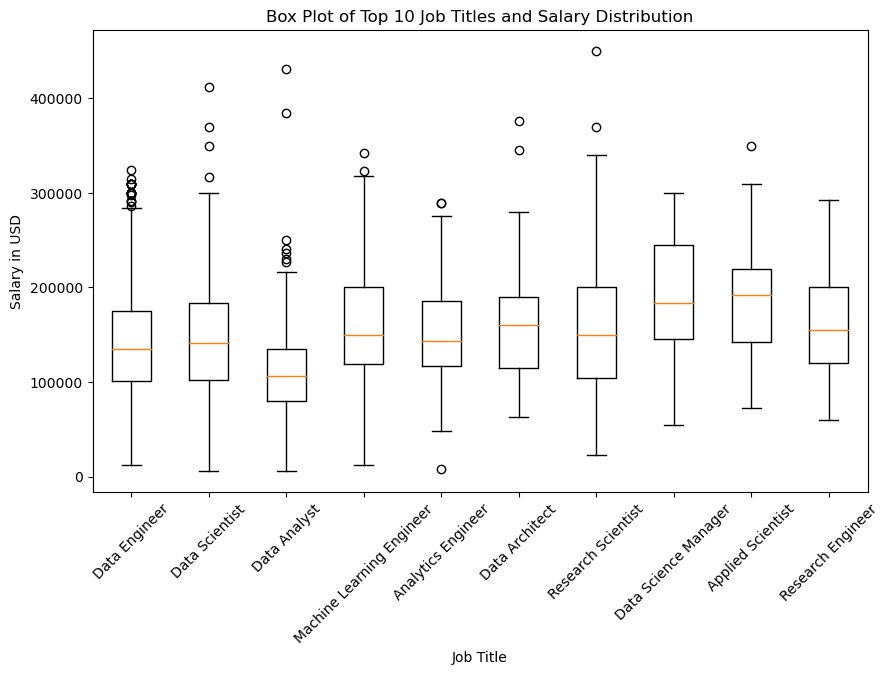
1 # 计算出现最多的前10个职位 2 top_10_jobs = df['job_title'].value_counts().head(10).index.tolist() 3 4 # 筛选出前十个职位的数据 5 df_top_10_jobs = df[df['job_title'].isin(top_10_jobs)] 6 7 # 绘制箱线图 8 plt.figure(figsize=(10, 6)) 9 plt.boxplot([df_top_10_jobs[df_top_10_jobs['job_title'] == job]['salary_in_usd'] for job in top_10_jobs], labels=top_10_jobs) 10 plt.title('Box Plot of Top 10 Job Titles and Salary Distribution') 11 plt.xlabel('Job Title') 12 plt.ylabel('Salary in USD') 13 plt.xticks(rotation=45) 14 plt.show()
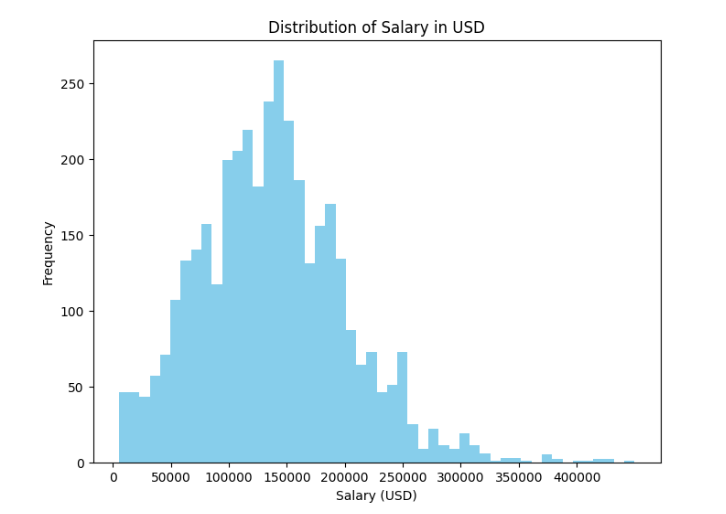
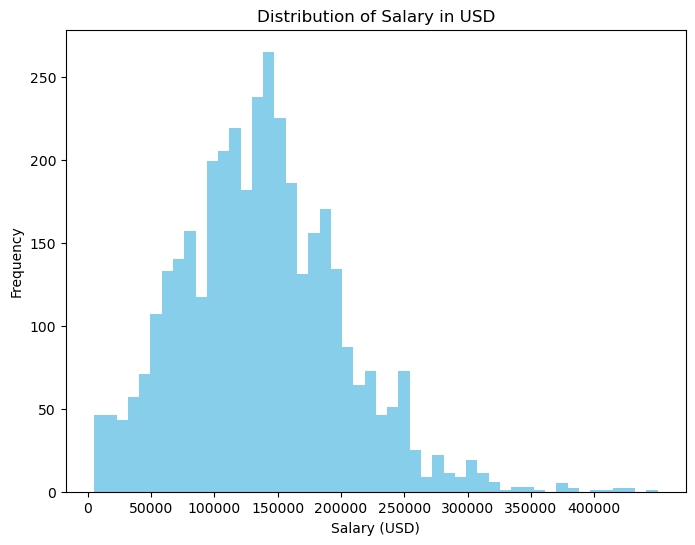
1 import matplotlib.pyplot as plt 2 3 # 绘制直方图 4 plt.figure(figsize=(8, 6)) 5 plt.hist(df['salary_in_usd'], bins=50, color='skyblue') 6 7 # 设置标题和坐标轴标签 8 plt.title('Distribution of Salary in USD') 9 plt.xlabel('Salary (USD)') 10 plt.ylabel('Frequency') 11 12 # 设置 x 轴刻度 13 plt.xticks(range(0, 450000, 50000)) 14 15 # 显示图形 16 plt.show()
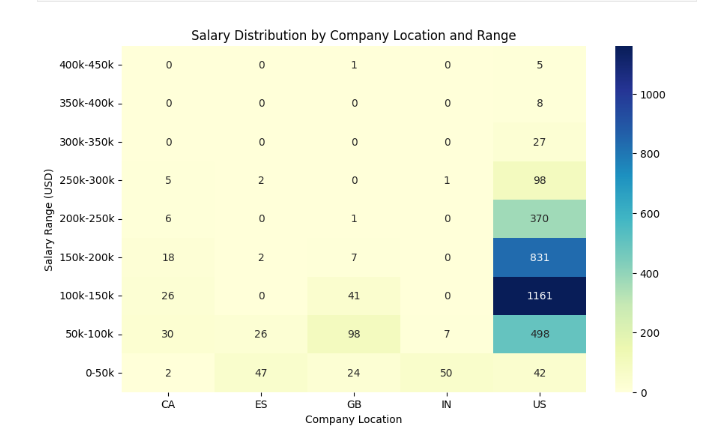
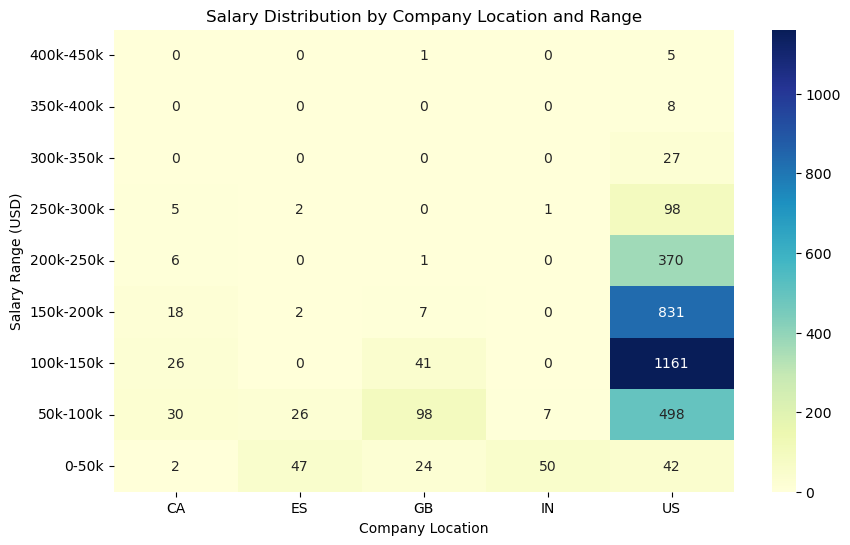
1 import seaborn as sns 2 import matplotlib.pyplot as plt 3 4 # 创建新的数据框,对 salary_in_usd 按照指定的范围进行分组 5 bins = [0, 50000, 100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000] 6 labels = ['0-50k', '50k-100k', '100k-150k', '150k-200k', '200k-250k', '250k-300k', '300k-350k', '350k-400k', '400k-450k'] 7 df_new = df[df['company_location'].isin(['US', 'GB', 'CA', 'ES', 'IN'])].copy() 8 df_new.loc[:, 'salary_range'] = pd.cut(df_new['salary_in_usd'], bins=bins, labels=labels) 9 10 # 对数据按照国家和工资水平排序 11 df_new = df_new.sort_values(by=['company_location', 'salary_range']) 12 13 # 生成热力图所需的数据格式 14 heatmap_data = df_new.groupby(['company_location', 'salary_range']).size().unstack(fill_value=0) 15 16 # 绘制热力图 17 plt.figure(figsize=(10, 6)) 18 sns.heatmap(heatmap_data.T[::-1], cmap='YlGnBu', annot=True, fmt='d', xticklabels=df_new['company_location'].unique(), yticklabels=labels[::-1]) 19 plt.title('Salary Distribution by Company Location and Range') 20 plt.xlabel('Company Location') 21 plt.ylabel('Salary Range (USD)') 22 plt.show()
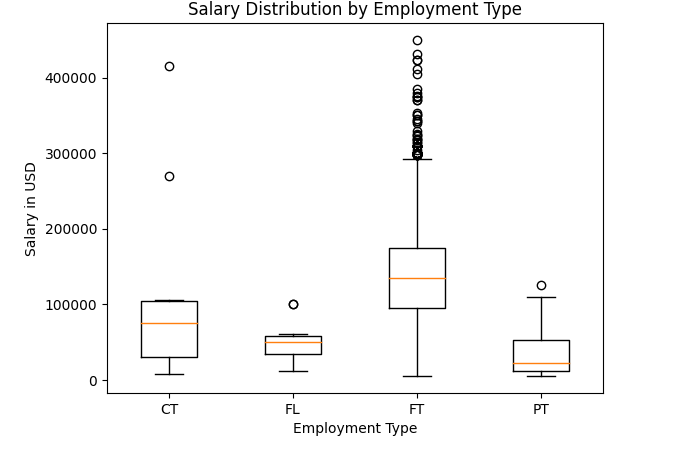
1 # 按employment_type分组,并获取salary_in_usd列的值 2 grouped_data = df.groupby('employment_type')['salary_in_usd'].apply(list) 3 4 # 绘制箱形图 5 plt.boxplot(grouped_data.values, labels=grouped_data.index) 6 plt.xlabel('Employment Type') 7 plt.ylabel('Salary in USD') 8 plt.title('Salary Distribution by Employment Type') 9 plt.show()
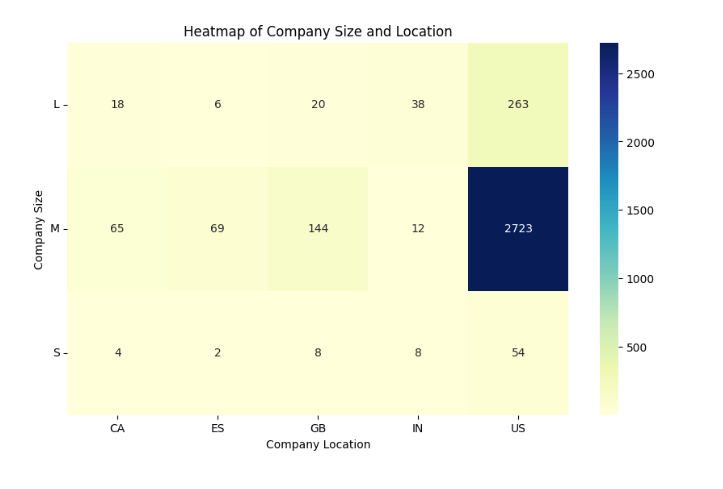
1 import seaborn as sns 2 import matplotlib.pyplot as plt 3 4 # 过滤符合条件的数据,并创建副本 5 df_new = df[df['company_location'].isin(['US', 'GB', 'CA', 'ES', 'IN'])].copy() 6 7 # 创建交叉表,注意调换行和列的顺序 8 cross_table = pd.crosstab(df_new['company_size'], df_new['company_location']) 9 10 # 绘制热力图 11 plt.figure(figsize=(10, 6)) 12 sns.heatmap(cross_table, cmap='YlGnBu', annot=True, fmt='d') 13 plt.xlabel('Company Location') 14 plt.ylabel('Company Size') 15 plt.title('Heatmap of Company Size and Location') 16 plt.yticks(rotation=0) 17 plt.show()
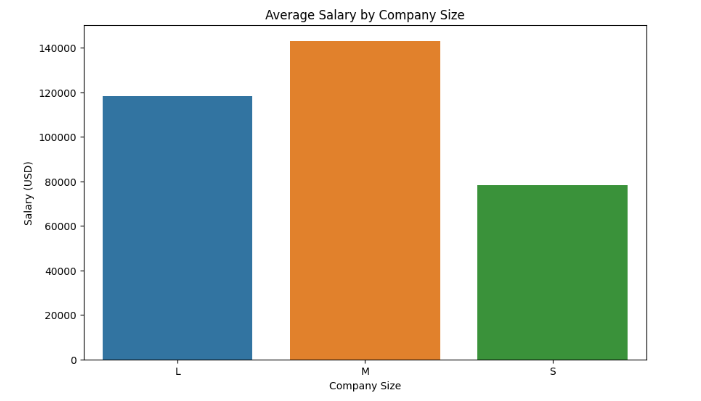
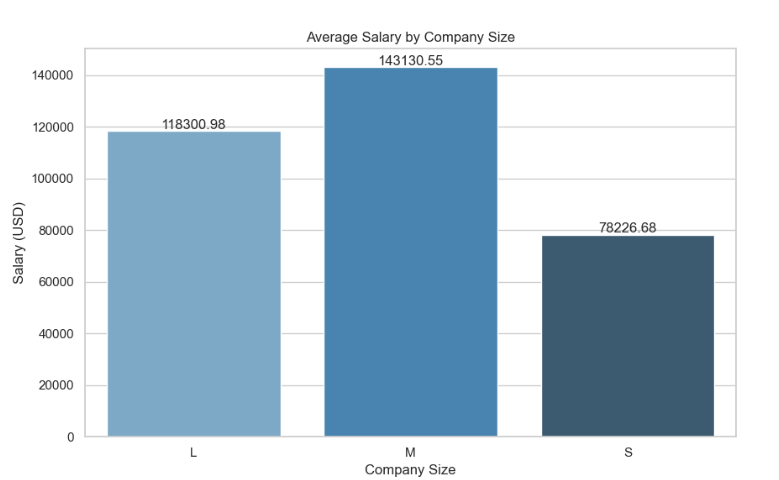
1 # 根据公司规模分组,计算不同规模公司的薪资、雇佣类型和工作经验水平的均值 2 grouped_df = df.groupby('company_size').agg({ 3 'salary_in_usd': 'mean', 4 'employment_type': pd.Series.mode, 5 'experience_level': pd.Series.mode 6 }).reset_index() 7 8 # 绘制薪资水平柱状图 9 plt.figure(figsize=(10, 6)) 10 sns.barplot(x='company_size', y='salary_in_usd', data=grouped_df) 11 plt.xlabel('Company Size') 12 plt.ylabel('Salary (USD)') 13 plt.title('Average Salary by Company Size') 14 plt.show()
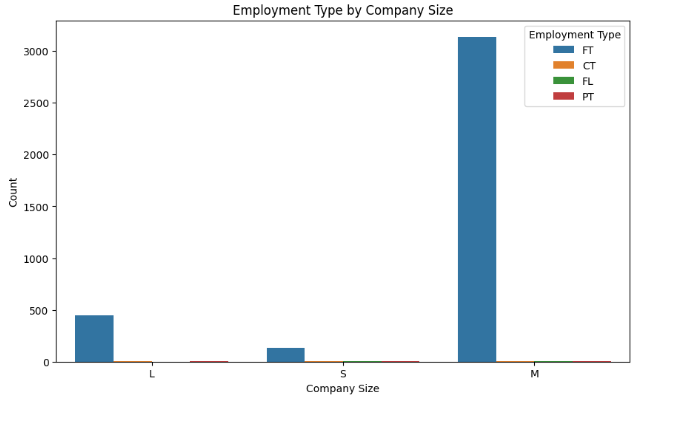
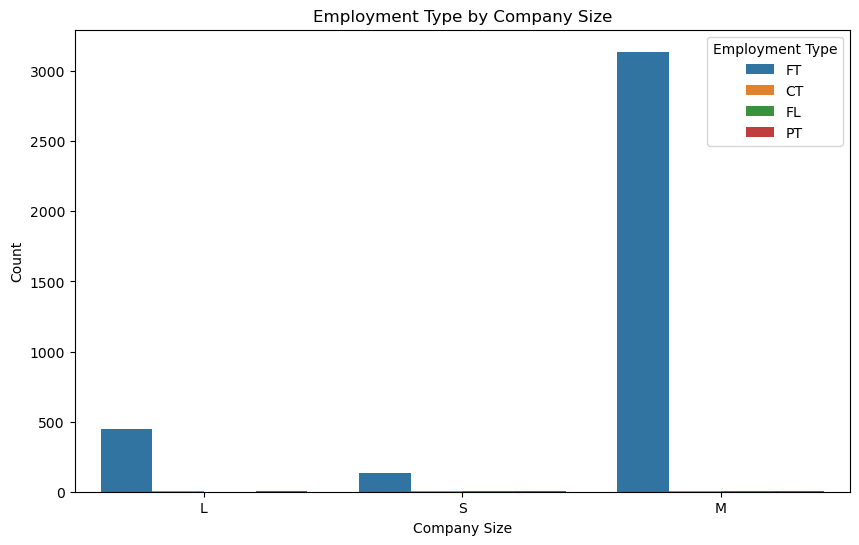
1 # 绘制雇佣类型和工作经验水平的堆叠柱状图 2 plt.figure(figsize=(10, 6)) 3 sns.countplot(x='company_size', hue='employment_type', data=df) 4 plt.xlabel('Company Size') 5 plt.ylabel('Count') 6 plt.title('Employment Type by Company Size') 7 plt.legend(title='Employment Type') 8 plt.show()
1 plt.figure(figsize=(10, 6)) 2 sns.countplot(x='company_size', hue='experience_level', data=df) 3 plt.xlabel('Company Size') 4 plt.ylabel('Count') 5 plt.title('Experience Level by Company Size') 6 plt.legend(title='Experience Level') 7 plt.show()

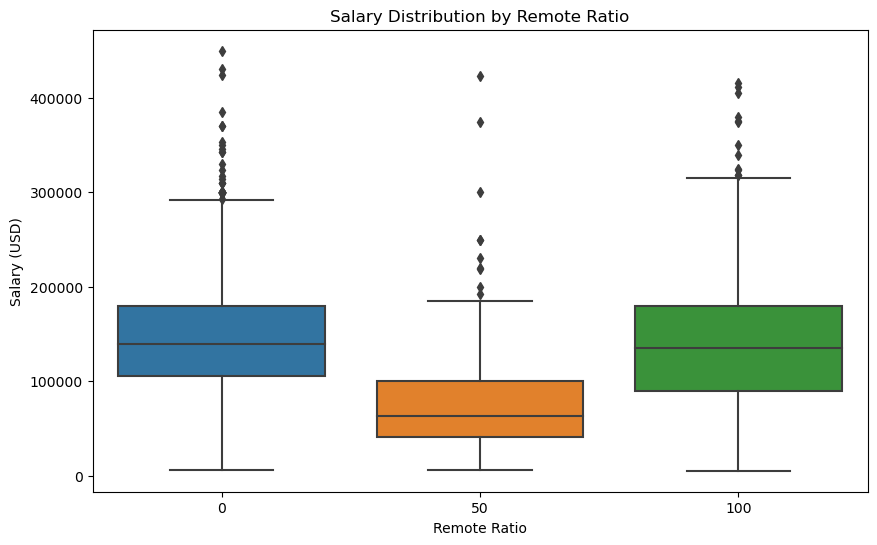
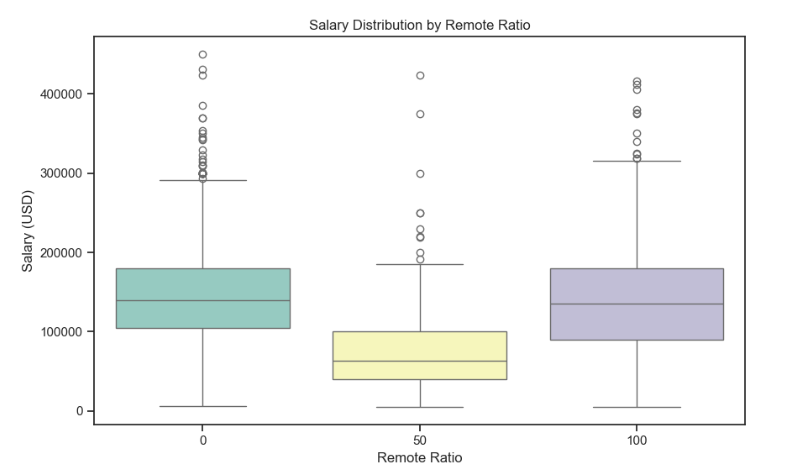
1 import seaborn as sns 2 import matplotlib.pyplot as plt 3 # 绘制远程工作职位不同类型的箱图 4 plt.figure(figsize=(10, 6)) 5 sns.boxplot(x='remote_ratio', y='salary_in_usd', data=df) 6 plt.xlabel('Remote Ratio') 7 plt.ylabel('Salary (USD)') 8 plt.title('Salary Distribution by Remote Ratio') 9 plt.show()
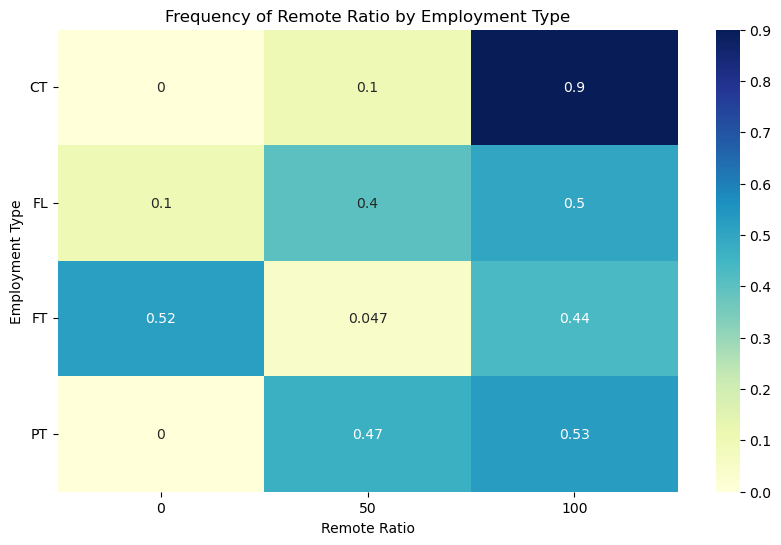
1 # 使用 crosstab 函数计算频率 2 frequency_table = pd.crosstab(df['employment_type'], df['remote_ratio'], normalize='index') 3 4 # 绘制热力图 5 plt.figure(figsize=(10, 6)) 6 sns.heatmap(frequency_table, annot=True, cmap='YlGnBu') 7 plt.xlabel('Remote Ratio') 8 plt.ylabel('Employment Type') 9 plt.title('Frequency of Remote Ratio by Employment Type') 10 plt.yticks(rotation=0) 11 plt.show()
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 6 df = pd.read_csv('ds_salaries.csv') 7 8 # 绘制职位出现次数的饼图 9 job_counts = df['job_title'].value_counts() 10 top_10_jobs = job_counts.head(10) 11 other_jobs = job_counts[10:].sum() 12 13 job_labels = top_10_jobs.index.tolist() 14 job_labels.append('Other') 15 job_sizes = top_10_jobs.tolist() 16 job_sizes.append(other_jobs) 17 18 plt.figure(figsize=(8, 6)) 19 plt.pie(job_sizes, labels=job_labels, autopct='%1.1f%%', startangle=90) 20 plt.title('Top 10 Job Titles Distribution') 21 plt.axis('equal') 22 plt.show()
1 # 绘制前十个职位的薪资分布的箱线图 2 top_10_jobs = df['job_title'].value_counts().head(10).index.tolist() 3 df_top_10_jobs = df[df['job_title'].isin(top_10_jobs)] 4 5 plt.figure(figsize=(10, 6)) 6 plt.boxplot([df_top_10_jobs[df_top_10_jobs['job_title'] == job]['salary_in_usd'] for job in top_10_jobs], labels=top_10_jobs) 7 plt.title('Box Plot of Top 10 Job Titles and Salary Distribution') 8 plt.xlabel('Job Title') 9 plt.ylabel('Salary in USD') 10 plt.xticks(rotation=45) 11 plt.show()
1 # 绘制工资水平的直方图 2 plt.figure(figsize=(8, 6)) 3 plt.hist(df['salary_in_usd'], bins=50, color='skyblue') 4 plt.title('Distribution of Salary in USD') 5 plt.xlabel('Salary (USD)') 6 plt.ylabel('Frequency') 7 plt.xticks(range(0, 450000, 50000)) 8 plt.show()
1 # 绘制公司地点和工资范围的热力图 2 bins = [0, 50000, 100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000] 3 labels = ['0-50k', '50k-100k', '100k-150k', '150k-200k', '200k-250k', '250k-300k', '300k-350k', '350k-400k', '400k-450k'] 4 df_new = df[df['company_location'].isin(['US', 'GB', 'CA', 'ES', 'IN'])].copy() 5 df_new.loc[:, 'salary_range'] = pd.cut(df_new['salary_in_usd'], bins=bins, labels=labels) 6 7 df_new = df_new.sort_values(by=['company_location', 'salary_range']) 8 heatmap_data = df_new.groupby(['company_location', 'salary_range']).size().unstack(fill_value=0) 9 10 plt.figure(figsize=(10, 6)) 11 sns.heatmap(heatmap_data.T[::-1], cmap='YlGnBu', annot=True, fmt='d', xticklabels=df_new['company_location'].unique(), yticklabels=labels[::-1]) 12 plt.title('Salary Distribution by Company Location and Range') 13 plt.xlabel('Company Location') 14 plt.ylabel('Salary Range (USD)') 15 plt.show()
1 # 绘制雇佣类型和工作经验水平的柱状图 2 plt.figure(figsize=(10, 6)) 3 sns.countplot(x='company_size', hue='employment_type', data=df) 4 plt.xlabel('Company Size') 5 plt.ylabel('Count') 6 plt.title('Employment Type by Company Size') 7 plt.legend(title='Employment Type') 8 plt.show()
1 # 根据公司规模分组,计算不同规模公司的薪资的均值 2 grouped_df = df.groupby('company_size')['salary_in_usd'].mean().reset_index() 3 4 # 设置图表样式 5 sns.set(style="whitegrid") 6 7 # 绘制柱状图 8 plt.figure(figsize=(10, 6)) 9 barplot = sns.barplot(x='company_size', y='salary_in_usd', data=grouped_df, palette="Blues_d") 10 11 # 添加数值标签 12 for p in barplot.patches: 13 barplot.annotate(format(p.get_height(), '.2f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 5), textcoords = 'offset points') 14 15 # 添加标题和坐标轴标签 16 plt.title('Average Salary by Company Size') 17 plt.xlabel('Company Size') 18 plt.ylabel('Salary (USD)') 19 20 # 显示图表 21 plt.show()
1 # 设置图表样式 2 sns.set(style="ticks") 3 4 # 绘制箱线图 5 plt.figure(figsize=(10, 6)) 6 boxplot = sns.boxplot(x='remote_ratio', y='salary_in_usd', data=df, palette="Set3") 7 8 # 添加标题和坐标轴标签 9 plt.title('Salary Distribution by Remote Ratio') 10 plt.xlabel('Remote Ratio') 11 plt.ylabel('Salary (USD)') 12 13 # 显示图表 14 plt.show()
总代码
1 import numpy as np 2 import pandas as pd 3 df = pd.read_csv('ds_salaries.csv') 4 print(df.head()) 5 6 #这里统一用slary_in_usd为标准计量工资 7 df.drop(columns=['salary', 'salary_currency'], inplace=True) 8 9 print(df.info()) 10 11 12 13 import matplotlib.pyplot as plt 14 15 # 计算每个职位的出现次数 16 job_counts = df['job_title'].value_counts() 17 18 # 取前十个职位和其出现次数 19 top_10_jobs = job_counts.head(10) 20 other_jobs = job_counts[10:].sum() 21 22 # 构建饼图数据 23 job_labels = top_10_jobs.index.tolist() 24 job_labels.append('other') 25 job_sizes = top_10_jobs.tolist() 26 job_sizes.append(other_jobs) 27 28 29 # 绘制饼图 30 plt.figure(figsize=(8, 6)) 31 plt.pie(job_sizes, labels=job_labels, autopct='%1.1f%%', startangle=90) 32 plt.title('Top 10 Job Titles Distribution') 33 plt.axis('equal') 34 plt.show() 35 36 # 计算出现最多的前10个职位 37 top_10_jobs = df['job_title'].value_counts().head(10).index.tolist() 38 39 # 筛选出前十个职位的数据 40 df_top_10_jobs = df[df['job_title'].isin(top_10_jobs)] 41 42 # 绘制箱线图 43 plt.figure(figsize=(10, 6)) 44 plt.boxplot([df_top_10_jobs[df_top_10_jobs['job_title'] == job]['salary_in_usd'] for job in top_10_jobs], labels=top_10_jobs) 45 plt.title('Box Plot of Top 10 Job Titles and Salary Distribution') 46 plt.xlabel('Job Title') 47 plt.ylabel('Salary in USD') 48 plt.xticks(rotation=45) 49 plt.show() 50 51 52 import matplotlib.pyplot as plt 53 54 # 绘制直方图 55 plt.figure(figsize=(8, 6)) 56 plt.hist(df['salary_in_usd'], bins=50, color='skyblue') 57 58 # 设置标题和坐标轴标签 59 plt.title('Distribution of Salary in USD') 60 plt.xlabel('Salary (USD)') 61 plt.ylabel('Frequency') 62 63 # 设置 x 轴刻度 64 plt.xticks(range(0, 450000, 50000)) 65 66 # 显示图形 67 plt.show() 68 69 70 71 import seaborn as sns 72 import matplotlib.pyplot as plt 73 74 # 创建新的数据框,对 salary_in_usd 按照指定的范围进行分组 75 bins = [0, 50000, 100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000] 76 labels = ['0-50k', '50k-100k', '100k-150k', '150k-200k', '200k-250k', '250k-300k', '300k-350k', '350k-400k', '400k-450k'] 77 df_new = df[df['company_location'].isin(['US', 'GB', 'CA', 'ES', 'IN'])].copy() 78 df_new.loc[:, 'salary_range'] = pd.cut(df_new['salary_in_usd'], bins=bins, labels=labels) 79 80 # 对数据按照国家和工资水平排序 81 df_new = df_new.sort_values(by=['company_location', 'salary_range']) 82 83 # 生成热力图所需的数据格式 84 heatmap_data = df_new.groupby(['company_location', 'salary_range']).size().unstack(fill_value=0) 85 86 # 绘制热力图 87 plt.figure(figsize=(10, 6)) 88 sns.heatmap(heatmap_data.T[::-1], cmap='YlGnBu', annot=True, fmt='d', xticklabels=df_new['company_location'].unique(), yticklabels=labels[::-1]) 89 plt.title('Salary Distribution by Company Location and Range') 90 plt.xlabel('Company Location') 91 plt.ylabel('Salary Range (USD)') 92 plt.show() 93 94 95 96 # 按employment_type分组,并获取salary_in_usd列的值 97 grouped_data = df.groupby('employment_type')['salary_in_usd'].apply(list) 98 99 # 绘制箱形图 100 plt.boxplot(grouped_data.values, labels=grouped_data.index) 101 plt.xlabel('Employment Type') 102 plt.ylabel('Salary in USD') 103 plt.title('Salary Distribution by Employment Type') 104 plt.show() 105 106 107 import seaborn as sns 108 import matplotlib.pyplot as plt 109 110 # 过滤符合条件的数据,并创建副本 111 df_new = df[df['company_location'].isin(['US', 'GB', 'CA', 'ES', 'IN'])].copy() 112 113 # 创建交叉表,注意调换行和列的顺序 114 cross_table = pd.crosstab(df_new['company_size'], df_new['company_location']) 115 116 # 绘制热力图 117 plt.figure(figsize=(10, 6)) 118 sns.heatmap(cross_table, cmap='YlGnBu', annot=True, fmt='d') 119 plt.xlabel('Company Location') 120 plt.ylabel('Company Size') 121 plt.title('Heatmap of Company Size and Location') 122 plt.yticks(rotation=0) 123 plt.show() 124 125 126 # 根据公司规模分组,计算不同规模公司的薪资、雇佣类型和工作经验水平的均值 127 grouped_df = df.groupby('company_size').agg({ 128 'salary_in_usd': 'mean', 129 'employment_type': pd.Series.mode, 130 'experience_level': pd.Series.mode 131 }).reset_index() 132 133 # 绘制薪资水平柱状图 134 plt.figure(figsize=(10, 6)) 135 sns.barplot(x='company_size', y='salary_in_usd', data=grouped_df) 136 plt.xlabel('Company Size') 137 plt.ylabel('Salary (USD)') 138 plt.title('Average Salary by Company Size') 139 plt.show() 140 141 142 # 绘制雇佣类型和工作经验水平的堆叠柱状图 143 plt.figure(figsize=(10, 6)) 144 sns.countplot(x='company_size', hue='employment_type', data=df) 145 plt.xlabel('Company Size') 146 plt.ylabel('Count') 147 plt.title('Employment Type by Company Size') 148 plt.legend(title='Employment Type') 149 plt.show() 150 151 152 plt.figure(figsize=(10, 6)) 153 sns.countplot(x='company_size', hue='experience_level', data=df) 154 plt.xlabel('Company Size') 155 plt.ylabel('Count') 156 plt.title('Experience Level by Company Size') 157 plt.legend(title='Experience Level') 158 plt.show() 159 160 161 import seaborn as sns 162 import matplotlib.pyplot as plt 163 # 绘制远程工作职位不同类型的箱图 164 plt.figure(figsize=(10, 6)) 165 sns.boxplot(x='remote_ratio', y='salary_in_usd', data=df) 166 plt.xlabel('Remote Ratio') 167 plt.ylabel('Salary (USD)') 168 plt.title('Salary Distribution by Remote Ratio') 169 plt.show() 170 171 172 173 # 使用 crosstab 函数计算频率 174 frequency_table = pd.crosstab(df['employment_type'], df['remote_ratio'], normalize='index') 175 176 # 绘制热力图 177 plt.figure(figsize=(10, 6)) 178 sns.heatmap(frequency_table, annot=True, cmap='YlGnBu') 179 plt.xlabel('Remote Ratio') 180 plt.ylabel('Employment Type') 181 plt.title('Frequency of Remote Ratio by Employment Type') 182 plt.yticks(rotation=0) 183 plt.show() 184 185 186 187 import numpy as np 188 import pandas as pd 189 import matplotlib.pyplot as plt 190 import seaborn as sns 191 192 df = pd.read_csv('ds_salaries.csv') 193 194 # 绘制职位出现次数的饼图 195 job_counts = df['job_title'].value_counts() 196 top_10_jobs = job_counts.head(10) 197 other_jobs = job_counts[10:].sum() 198 199 job_labels = top_10_jobs.index.tolist() 200 job_labels.append('Other') 201 job_sizes = top_10_jobs.tolist() 202 job_sizes.append(other_jobs) 203 204 plt.figure(figsize=(8, 6)) 205 plt.pie(job_sizes, labels=job_labels, autopct='%1.1f%%', startangle=90) 206 plt.title('Top 10 Job Titles Distribution') 207 plt.axis('equal') 208 plt.show() 209 210 211 # 绘制前十个职位的薪资分布的箱线图 212 top_10_jobs = df['job_title'].value_counts().head(10).index.tolist() 213 df_top_10_jobs = df[df['job_title'].isin(top_10_jobs)] 214 215 plt.figure(figsize=(10, 6)) 216 plt.boxplot([df_top_10_jobs[df_top_10_jobs['job_title'] == job]['salary_in_usd'] for job in top_10_jobs], labels=top_10_jobs) 217 plt.title('Box Plot of Top 10 Job Titles and Salary Distribution') 218 plt.xlabel('Job Title') 219 plt.ylabel('Salary in USD') 220 plt.xticks(rotation=45) 221 plt.show() 222 223 224 # 绘制工资水平的直方图 225 plt.figure(figsize=(8, 6)) 226 plt.hist(df['salary_in_usd'], bins=50, color='skyblue') 227 plt.title('Distribution of Salary in USD') 228 plt.xlabel('Salary (USD)') 229 plt.ylabel('Frequency') 230 plt.xticks(range(0, 450000, 50000)) 231 plt.show() 232 233 234 # 绘制公司地点和工资范围的热力图 235 bins = [0, 50000, 100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000] 236 labels = ['0-50k', '50k-100k', '100k-150k', '150k-200k', '200k-250k', '250k-300k', '300k-350k', '350k-400k', '400k-450k'] 237 df_new = df[df['company_location'].isin(['US', 'GB', 'CA', 'ES', 'IN'])].copy() 238 df_new.loc[:, 'salary_range'] = pd.cut(df_new['salary_in_usd'], bins=bins, labels=labels) 239 240 df_new = df_new.sort_values(by=['company_location', 'salary_range']) 241 heatmap_data = df_new.groupby(['company_location', 'salary_range']).size().unstack(fill_value=0) 242 243 plt.figure(figsize=(10, 6)) 244 sns.heatmap(heatmap_data.T[::-1], cmap='YlGnBu', annot=True, fmt='d', xticklabels=df_new['company_location'].unique(), yticklabels=labels[::-1]) 245 plt.title('Salary Distribution by Company Location and Range') 246 plt.xlabel('Company Location') 247 plt.ylabel('Salary Range (USD)') 248 plt.show() 249 250 251 # 绘制雇佣类型和工作经验水平的柱状图 252 plt.figure(figsize=(10, 6)) 253 sns.countplot(x='company_size', hue='employment_type', data=df) 254 plt.xlabel('Company Size') 255 plt.ylabel('Count') 256 plt.title('Employment Type by Company Size') 257 plt.legend(title='Employment Type') 258 plt.show() 259 # 绘制雇佣类型和工作经验水平的柱状图 260 plt.figure(figsize=(10, 6)) 261 sns.countplot(x='company_size', hue='employment_type', data=df) 262 plt.xlabel('Company Size') 263 plt.ylabel('Count') 264 plt.title('Employment Type by Company Size') 265 plt.legend(title='Employment Type') 266 plt.show() 267 # 根据公司规模分组,计算不同规模公司的薪资的均值 268 grouped_df = df.groupby('company_size')['salary_in_usd'].mean().reset_index() 269 270 # 设置图表样式 271 sns.set(style="whitegrid") 272 273 # 绘制柱状图 274 plt.figure(figsize=(10, 6)) 275 barplot = sns.barplot(x='company_size', y='salary_in_usd', data=grouped_df, palette="Blues_d") 276 277 # 添加数值标签 278 for p in barplot.patches: 279 barplot.annotate(format(p.get_height(), '.2f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 5), textcoords = 'offset points') 280 281 # 添加标题和坐标轴标签 282 plt.title('Average Salary by Company Size') 283 plt.xlabel('Company Size') 284 plt.ylabel('Salary (USD)') 285 286 # 显示图表 287 plt.show() 288 289 290 # 设置图表样式 291 sns.set(style="ticks") 292 293 # 绘制箱线图 294 plt.figure(figsize=(10, 6)) 295 boxplot = sns.boxplot(x='remote_ratio', y='salary_in_usd', data=df, palette="Set3") 296 297 # 添加标题和坐标轴标签 298 plt.title('Salary Distribution by Remote Ratio') 299 plt.xlabel('Remote Ratio') 300 plt.ylabel('Salary (USD)') 301 302 # 显示图表 303 plt.show()
5.总结
根据我的分析,这份数据集包含了数据科学家在不同公司、不同职位和不同地点的薪资情况。通过绘制不同类型的图表,可以得出以下几个结论:数据科学家的职位涵盖广泛,但前十个职位占据了大部分,其中“Data Scientist”和“Data Analyst”是最常见的两个职位。不同职位之间的薪资差异很大,且存在较多的离群值。其中,“Data Scientist”、“Data Engineer”和“Machine Learning Engineer”是薪资最高的三个职位。整体的薪资水平呈现正偏态分布,即大部分数据科学家的薪资都集中在较低的水平上,但也有少部分人的薪资非常高。美国是数据科学家薪资最高的国家,其次是英国、加拿大和西班牙。此外,薪资较高的数据科学家集中在大型公司中。全职工作和具有一定工作经验的数据科学家数量最多,而兼职工作和实习生数量相对较少。