一、为什么引入ResNet
通过上一篇分类网络的介绍,我们知道网络的宽度和深度可以很好的提高网络的性能,深的网络一般都比浅的的网络效果好,但训练一个很深的网络是非常困难的,一方面是网络越深越容易出现梯度消失和梯度爆炸问题, 然而这个问题通过BN层和ReLU激活函数等方法在很大程度上已经得到解决;另一方面当网络层数达到一定的数目以后,网络的性能就会趋于饱和,再增加网络层数的话性能就会开始退化,这说明当网络变得很深以后,网络就变得难以训练了。下图展示了不同深度网络的效果。

二、ResNet是什么
要理解ResNet,首先要知道什么是残差块。
残差块
以一个两层神经网络为例,普通网络输入\(a^{[l]}\) 首先经过线性变换生成\(z^{[l+1]}\),然后通过ReLU激活层输出\(a^{[l+1]}\) ,同样再经过一个线性变换生成\(z^{[l+2]}\),最后通过ReLU生成 $a^{[l+2]} $,最终
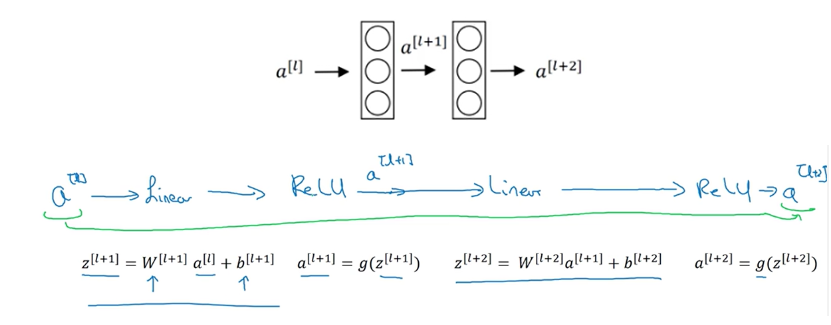
如果直接将\(a{[l]}\)连接到第二个线性变换和第二个ReLU激活层之间,形成一条更便捷的路径(short cut),此时$$a^{[l+2]} = g(z^{[l+2]}). $$变为$$a^{[l+2]} = g(z^{[l+2]} + a^{[l]}). $$也就是加上short cut后形成了一个残差块。
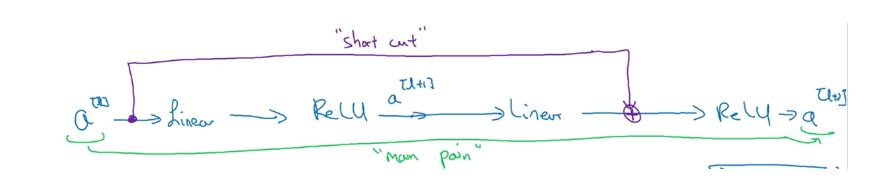
ResNet
ResNet是由多个残差块组成的残差网络。在论文中,作者给出了不同层数的ResNet网络,包括18层、34层、50层、101层和152层,50层及以上的称为深度残差网络,后面再介绍其差异点。
三、ResNet为什么有效
原文中如下图所示,设\(x\)为浅层输出,\(H(x)\)为深层输出,\(F(x)\)为中间层结果,当\(x\) 表示的特征已经达到一个很好的程度时,中间层继续学习会导致损失增大,\(F(x)\)就会慢慢趋近于0,\(x\)将从short cut路径继续往下传播,这样就实现了当浅层特征很好时,后面的深层网络能达到一个恒等变换的效果。
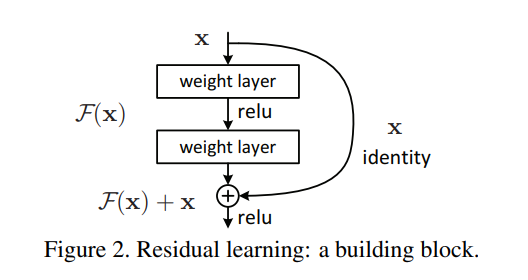
这里从前向推理和反向传播两个方面来分析。
前向推理
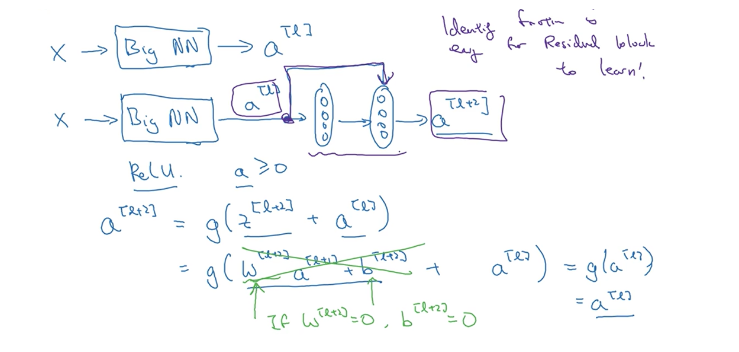
假设输入\(x\)通过一个很深的网络后通过ReLU激活函数输出为\(a^{[l]}\),根据ReLU的特性此时\(a \geq 0\),再其后面再接一个两层的残差块输出\(a^{[l+2]}\),则\(a^{[l+2]}\)可以表示为
当\(w^{[l+2]}\)和偏置\(w^{[l+2]}\)都为0时,$$ a^{[l+2]} = g(a{[l]})=a.$$,这说明残差块学习这个恒等变换并不难,另外如果中间这两层学习到了一些其他有用的特征信息的话,它可能比学习恒等变换的效果更好,但是如果不加入残差块的话随着网络的不断加深,学习一个恒等变换的参数都可能变得很难,因此残差网络能在不减慢学习效率(恒等变换)的情况下还有可能提高模型的性能。
反向传播
一方面是残差块将输出\(y = H(x)\) 分成了 \(F(x) + x\),变换后\(F(x) = H(x) - x\),即从原来学习一个\(x\)到\(y\)的映射变为学习 \(y\)与\(x\) 之间的差值,这样学习任务变得更简单。 另一方面因为前向过程中存在short cut路径下的恒等映射,因此在反向传播过程中也存在这样一条捷径,只需要通过一个ReLU函数就可以将梯度传到上一个模块。
下图是论文中给的实验结果
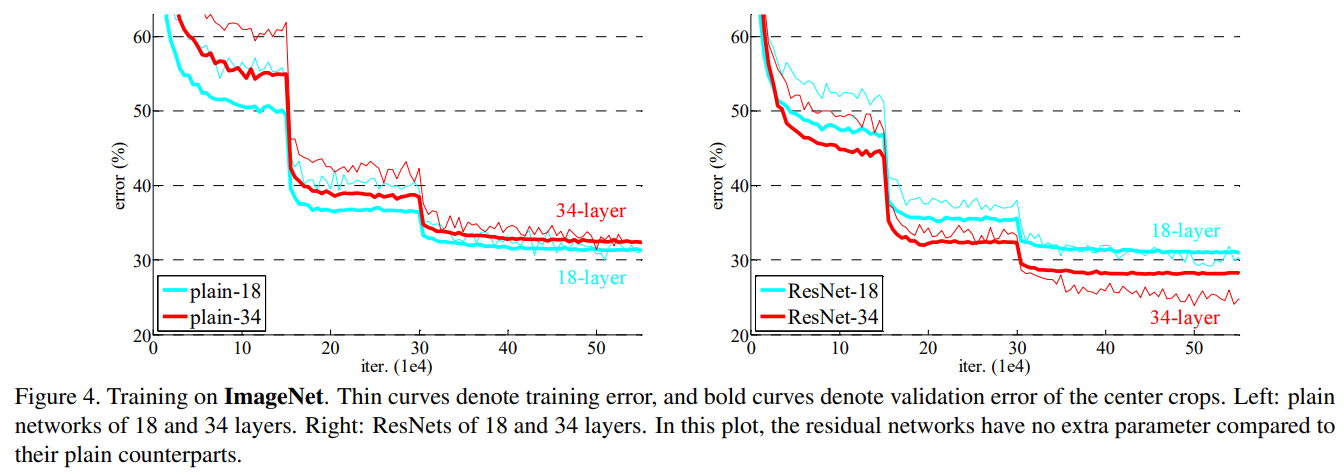
四、ResNet有哪些
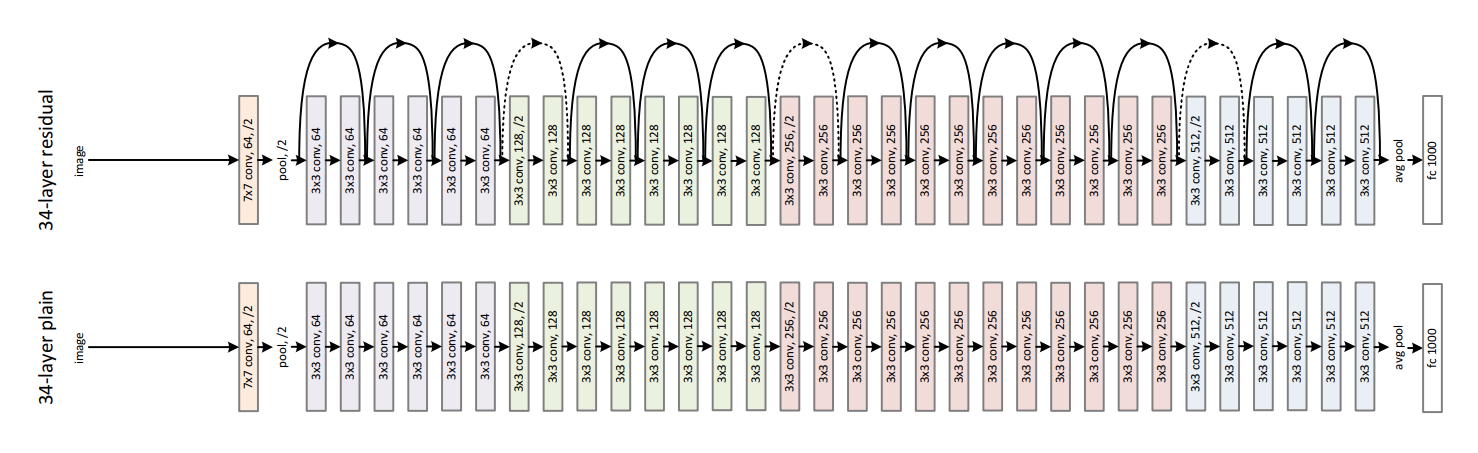
前面提到ResNet网络包括18层、34层、50层、101层和152层,其中50层及以上的称为**深度残差网络**,它们网络结构如下图所示。

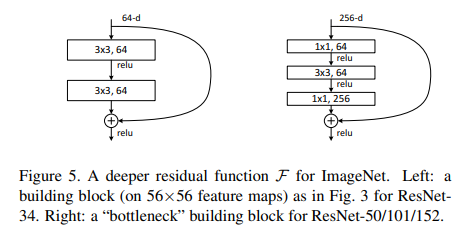
深度残差网络和浅层残差网络的主要区别在于基本结构由原来的残差块(Residual Block)变为了瓶颈残差块(Residual Bottleneck),瓶颈残差块输出通道数为输入的四倍,而残差块输入和输出通道数相等,以50层的残差网络为例,在conv2_x层中包括了3个瓶颈残差块,第一层和最后一层的通道数相差4倍, 由原来的64变为了256。
五、ResNet变种
ResNet 模型至今已经有很多变种,在保持其基本优点的同时,不断对其结构进行改良以适应不同任务的需求。例如,
- ResNeXt 提出一种新的卡片连通方式;
- DenseNet 引入了密集块,支持更深的神经网络;
- SENet 则在 ResNet 基础上加入了注意力机制。
总之,ResNet 通过引入残差块和恒等映射机制,使神经网络可以逐渐加深,降低实现难度同时还提高了性能,进而在计算机视觉领域得到广泛应用。