原文:Advanced Deep Learning with TensorFlow 2 and Keras
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
十一、对象检测
目标检测是计算机视觉最重要的应用之一。 对象检测是同时定位和识别图像中存在的对象的任务。 为了使自动驾驶汽车安全地在街道上行驶,该算法必须检测到行人,道路,车辆,交通信号灯,标志和意外障碍物的存在。 在安全方面,入侵者的存在可以用来触发警报或通知适当的当局。
尽管很重要,但是对象检测一直是计算机视觉中的一个长期存在的问题。 已经提出了许多算法,但是通常很慢,并且精度和召回率很低。 与 AlexNet [1]在 ImageNet 大规模图像分类问题中所取得的成就类似,深度学习显着提高了对象检测领域。 最新的对象检测方法现在可以实时运行,并且具有更高的精度和召回率。
在本章中,我们重点介绍实时对象检测。 特别是,我们讨论了tf.keras中单发检测(SSD)[2]的概念和实现。 与其他深度学习检测算法相比,SSD 可在现代 GPU 上实现实时检测速度,而表现不会显着下降。 SSD 还易于端到端训练。
总之,本章的目的是介绍:
- 对象检测的概念
- 多尺度目标检测的概念
- SSD 作为多尺度目标检测算法
tf.keras中 SSD 的实现
我们将从介绍对象检测的概念开始。
1. 对象检测
在对象检测中,目标是在图像中定位和识别物体。“图 11.1.1”显示了目标汽水罐的目标物检测。 本地化意味着必须估计对象的边界框。 使用左上角像素坐标和右下角像素坐标是用于描述边界框的通用约定。 在“图 11.1.1”中,左上角像素具有坐标(x_min, y_min),而右下角像素的坐标为(x_max, y_max)。像素坐标系的原点(0, 0)位于整个图像的左上角像素。
在执行定位时,检测还必须识别对象。 识别是计算机视觉中的经典识别或分类任务。 至少,对象检测必须确定边界框是属于已知对象还是背景。 可以训练对象检测网络以仅检测一个特定对象,例如“图 11.1.1”中的汽水罐。 其他所有内容均视为背景,因此无需显示其边界框。 同一对象的多个实例,例如两个或多个汽水罐,也可以通过同一网络检测到,如图“图 11.1.2”所示。

图 11.1.1 说明了对象检测是在图像中定位和识别对象的过程。

图 11.1.2 被训练为检测一个对象实例的同一网络可以检测到同一对象的多个实例。
如果场景中存在多个对象,例如在“图 11.1.3”中,则对象检测方法只能识别在其上训练的一个对象。 其他两个对象将被分类为背景,并且不会分配边界框。

图 11.1.3 如果仅在检测汽水罐方面训练了对象检测,它将忽略图像中的其他两个对象。
但是,如果重新训练了网络以检测三个对象:1)汽水罐,2)果汁罐和 3)水瓶会同时定位和识别,如图“图 11.1.4”所示。

图 11.1.4 即使背景杂乱或照明发生变化,也可以重新训练对象检测网络以检测所有三个对象。
一个好的对象检测器必须在现实环境中具有鲁棒性。“图 11.1.4”显示了一个好的对象检测网络,即使背景杂乱甚至在弱光条件下,也可以定位和识别已知对象。 对象检测器必须具有鲁棒性的其他因素是物体变换(旋转和/或平移),表面反射,纹理变化和噪声。
总之,对象检测的目标是针对图像中每个可识别的对象同时预测以下内容:
y_cls或单热向量形式的类别或类y_box = ((x_min, y_min), (x_max, y_max))或像素坐标形式的边界框坐标
通过解释了对象检测的基本概念,我们可以开始讨论对象检测的某些特定机制。 我们将从介绍锚框开始。
2. 锚框
从上一节的讨论中,我们了解到,对象检测必须预测边界框区域以及其中的对象类别。 假设与此同时,我们的重点是边界框坐标估计。
网络如何预测坐标(x_min, y_min)和(x_max, y_max)? 网络可以做出与图像的左上角像素坐标和右下角像素坐标相对应的初始猜测,例如(0, 0)和(w, h)。w是图像宽度,而h是图像高度。 然后,网络通过对地面真实边界框坐标执行回归来迭代地校正估计。
由于可能的像素值存在较大差异,因此使用原始像素估计边界框坐标不是最佳方法。 SSD 代替原始像素,将地面真值边界框和预测边界框坐标之间的像素误差值最小化。 对于此示例,像素的误差值为(x_min, y_min)和(x_max - w, y_max - h)。 这些值称为offsets。
为了帮助网络找出正确的边界框坐标,将图像划分为多个区域。 每个区域称为定位框。 然后,网络估计每个锚框的偏移。 这样得出的预测更接近于基本事实。
例如,如图“图 11.2.1”所示,将普通图像尺寸640 x 480分为2 x 1个区域,从而产生两个锚框。 与2 x 2的大小不同,2 x 1的划分创建了近似方形的锚框。 在第一个锚点框中,新的偏移量是(x_min, y_min)和{x_max - w/2, y_max - h},它们比没有锚框的像素误差值更小。 第二个锚框的偏移量也较小。
在“图 11.2.2”中,图像被进一步分割。 这次,锚框为3 x 2。第二个锚框偏移为{x_min - w/3, y_min}和{x_max - 2w/3, y_max - h/2},这是迄今为止最小的。 但是,如果将图像进一步分为5 x 4,则偏移量开始再次增加。 主要思想是,在创建各种尺寸的区域的过程中,将出现最接近地面真值边界框的最佳锚框大小。 使用多尺度锚框有效地检测不同大小的对象将巩固多尺度对象检测算法的概念。
找到一个最佳的锚框并不是零成本。 尤其是,有些外部锚框的偏移量比使用整个图像还要差。 在这种情况下,SSD 建议这些锚定框不应对整个优化过程有所帮助,而应予以抑制。 在以下各节中,将更详细地讨论排除非最佳锚框的算法。
到目前为止,我们已经有三套锚框。
第一个创建一个2 x 1的锚框网格,每个锚框的尺寸为(w/2, h)。
第二个创建一个3 x 2的锚框网格,每个锚框的尺寸为(w/3, h/2)。
第三个创建一个5 x 4的锚框网格,每个锚框的尺寸为(w/5, h/4)。
我们还需要多少套锚盒? 它取决于图像的尺寸和对象最小边框的尺寸。 对于此示例中使用的640 x 480图像,其他锚点框为:
10 x 8格的锚框,每个框的尺寸为(w/10, h/8)
20 x 15格的锚框,每个锚框的尺寸为(w/20, h/15)
40 x 30格的锚框,每个框的尺寸为(w/40, h/30)
对于具有40 x 30网格的锚框的640 x 480图像,最小的锚框覆盖输入图像的16 x 16像素斑块,也称为接收域。 到目前为止,包围盒的总数为 1608。对于所有尺寸,最小的缩放因子可以总结为:
 (Equation 11.2.1)
(Equation 11.2.1)
锚框如何进一步改进? 如果我们允许锚框具有不同的纵横比,则可以减少偏移量。 每个调整大小的锚点框的质心与原始锚点框相同。 除宽高比 1 外,SSD [2]包括其他宽高比:
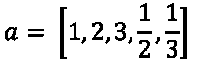 (Equation 11.2.2)
(Equation 11.2.2)
对于每个纵横比a[i],对应的锚框尺寸为:
 (Equation 11.2.3)
(Equation 11.2.3)
(s[xj], s[yj])是“公式 11.2.1”中的第j个比例因子。
使用每个锚框五个不同的长宽比,锚框的总数将增加到1,608 x 5 = 8,040。“图 11.2.3”显示了(s[x4], s[y4]) = (1/3, 1/2)和a[i ∈ {0, 1, 3}] = 1, 2, 1/2情况下的锚框。
请注意,为了达到一定的纵横比,我们不会使锚框变形。 而是调整锚框的宽度和高度。
对于a[0] = 1,SSD 建议使用其他尺寸的锚框:
 (Equation 11.2.4)
(Equation 11.2.4)
现在每个区域有六个锚定框。 有五个是由于五个纵横比,另外还有一个纵横比为 1。新的锚框总数增加到 9,648。

图 11.2.1 将图像划分为多个区域(也称为锚框),使网络可以进行更接近地面真实情况的预测。

图 11.2.2 使用较小的锚框可以进一步减少偏移。

图 11.2.3 具有比例因子(s[x4], s[y4]) = (1/3, 1/2)和纵横比a[i ∈ {0, 1, 3}] = 1, 2, 1/2的一个区域的锚框。
下面的“列表 11.2.1”显示了锚框生成函数anchor_boxes()。 给定输入的图像形状(image_shape),纵横比(aspect_ratios)和缩放因子(sizes),将计算不同的锚框大小并将其存储在名为width_height的列表中。 从给定的特征映射形状(feature_shape或(h_fmap, w_fmap)和width_height, 生成具有尺寸(h_fmap, w_fmap, n_boxes, 4)。n_boxes或每个特征映射点的锚点框数是基于纵横比和等于 1 的纵横比的一个附加大小计算的。
“列表 11.2.1”:锚框生成函数的layer_utils.py函数:
def anchor_boxes(feature_shape,
image_shape,
index=0,
n_layers=4,
aspect_ratios=(1, 2, 0.5)):
""" Compute the anchor boxes for a given feature map.
Anchor boxes are in minmax format
Arguments:
feature_shape (list): Feature map shape
image_shape (list): Image size shape
index (int): Indicates which of ssd head layers
are we referring to
n_layers (int): Number of ssd head layers
Returns:
boxes (tensor): Anchor boxes per feature map
"""
# anchor box sizes given an index of layer in ssd head
sizes = anchor_sizes(n_layers)[index]
# number of anchor boxes per feature map pt
n_boxes = len(aspect_ratios) + 1
# ignore number of channels (last)
image_height, image_width, _ = image_shape
# ignore number of feature maps (last)
feature_height, feature_width, _ = feature_shape
# normalized width and height
# sizes[0] is scale size, sizes[1] is sqrt(scale*(scale+1))
norm_height = image_height * sizes[0]
norm_width = image_width * sizes[0]
# list of anchor boxes (width, height)
width_height = []
# anchor box by aspect ratio on resized image dims
# Equation 11.2.3
for ar in aspect_ratios:
box_width = norm_width * np.sqrt(ar)
box_height = norm_height / np.sqrt(ar)
width_height.append((box_width, box_height))
# multiply anchor box dim by size[1] for aspect_ratio = 1
# Equation 11.2.4
box_width = image_width * sizes[1]
box_height = image_height * sizes[1]
width_height.append((box_width, box_height))
# now an array of (width, height)
width_height = np.array(width_height)
# dimensions of each receptive field in pixels
grid_width = image_width / feature_width
grid_height = image_height / feature_height
# compute center of receptive field per feature pt
# (cx, cy) format
# starting at midpoint of 1st receptive field
start = grid_width * 0.5
# ending at midpoint of last receptive field
end = (feature_width - 0.5) * grid_width
cx = np.linspace(start, end, feature_width)
start = grid_height * 0.5
end = (feature_height - 0.5) * grid_height
cy = np.linspace(start, end, feature_height)
# grid of box centers
cx_grid, cy_grid = np.meshgrid(cx, cy)
# for np.tile()
cx_grid = np.expand_dims(cx_grid, -1)
cy_grid = np.expand_dims(cy_grid, -1)
# tensor = (feature_map_height, feature_map_width, n_boxes, 4)
# aligned with image tensor (height, width, channels)
# last dimension = (cx, cy, w, h)
boxes = np.zeros((feature_height, feature_width, n_boxes, 4))
# (cx, cy)
boxes[..., 0] = np.tile(cx_grid, (1, 1, n_boxes))
boxes[..., 1] = np.tile(cy_grid, (1, 1, n_boxes))
# (w, h)
boxes[..., 2] = width_height[:, 0]
boxes[..., 3] = width_height[:, 1]
# convert (cx, cy, w, h) to (xmin, xmax, ymin, ymax)
# prepend one dimension to boxes
# to account for the batch size = 1
boxes = centroid2minmax(boxes)
boxes = np.expand_dims(boxes, axis=0)
return boxes
def centroid2minmax(boxes):
"""Centroid to minmax format
(cx, cy, w, h) to (xmin, xmax, ymin, ymax)
Arguments:
boxes (tensor): Batch of boxes in centroid format
Returns:
minmax (tensor): Batch of boxes in minmax format
"""
minmax= np.copy(boxes).astype(np.float)
minmax[..., 0] = boxes[..., 0] - (0.5 * boxes[..., 2])
minmax[..., 1] = boxes[..., 0] + (0.5 * boxes[..., 2])
minmax[..., 2] = boxes[..., 1] - (0.5 * boxes[..., 3])
minmax[..., 3] = boxes[..., 1] + (0.5 * boxes[..., 3])
return minmax
我们已经介绍了锚框如何协助对象检测以及如何生成它们。 在下一节中,我们将介绍一种特殊的锚点框:真实情况锚点框。 给定图像中的对象,必须将其分配给多个锚点框之一。 这就是,称为真实情况锚定框。
3. 真实情况锚框
从“图 11.2.3”看来,给定一个对象边界框,有许多可以分配给对象的真实情况锚定框。 实际上,仅出于“图 11.2.3”中的说明,已经有 3 个锚定框。 如果考虑每个区域的所有锚框,则仅针对(s[x4], s[y4]) = (1/3, 1/2)就有6 x 6 = 36个地面真实框。 使用所有 9,648 个锚点框显然过多。 所有锚定框中只有一个应与地面真值边界框相关联。 所有其他锚点框都是背景锚点框。 选择哪个对象应被视为图像中对象的真实情况锚定框的标准是什么?
选择锚框的基础称为交并比(IoU)。 IoU 也称为 Jaccard 指数。 在“图 11.3.1”中说明了 IoU。 给定 2 个区域,对象边界框B[0]和锚定框A[1],IoU 等于重叠除以合并区域的面积:
 (Equation 11.3.1)
(Equation 11.3.1)

图 11.3.1 IoU 等于(左)候选锚点框A[1]与(右)对象边界框B[0]之间的相交面积除以并集面积。
我们删除了该等式的下标。 对于给定的对象边界框B[i],对于所有锚点框A[j],地面真值锚点框A[j(gt)]是具有最大 IoU 的一个:
 (Equation 11.3.2)
(Equation 11.3.2)
请注意,对于每个对象,只有一个基于“公式 11.3.2”的地面真值锚定框。 此外,必须在所有比例因子和尺寸(长宽比和附加尺寸)中对所有锚框进行最大化。 在“图 11.3.1”中,在 9,648 个锚框中仅显示了一个比例因子大小。
为了说明“公式 11.3.2”,假设考虑了“图 11.3.1”中纵横比为 1 的锚框。 对于每个锚框,估计的 IoU 均显示在“表 11.3.1”中。 由于边界框B[0]的最大 IoU 为 0.32,因此带有锚框A[1],A[1]被分配为地面真值边界框B[0]。A[1]也被称为正锚框。
正锚定框的类别和偏移量是相对于其地面真值边界框确定的。 正锚定框的类别与其地面真值边界框相同。 同时,可以将正锚框偏移量计算为等于地面真实边界框坐标减去其自身的边界框坐标。
其余锚框发生了什么,A[0],A[2],A[3],A[4],和A[5]? 我们可以通过找到他们的 IoU 大于某个阈值的边界框来给他们第二次机会。
例如,如果阈值为 0.5,则没有可分配给它们的地面真理边界框。 如果阈值降低到 0.25,则A[4]也分配有地面真值边界框B[0],因为其 IoU 为 0.30 。 将A[4]添加到肯定锚框列表中。 在这本书中,A[4]被称为额外的正面锚盒。 没有地面边界框的其余锚框称为负锚框。
在以下有关损失函数的部分中,负锚框不构成偏移损失函数。
B[0] |
|
|---|---|
A[0] |
0 |
A[1] |
0.32 |
A[2] |
0 |
A[3] |
0 |
A[4] |
0.30 |
A[5] |
0 |
“表 11.3.1”每个锚框A[j ∈ 0 .. 5]的 IoU,带有对象边界框B[0],如“图 11.3.1”所示。
如果加载了另一个带有 2 个要检测的对象的图像,我们将寻找 2 个正 IoU,最大 IoU,并带有边界框B[0]和B[1]。 然后,我们使用边界框B[0]和B[1]寻找满足最小 IoU 准则的额外正锚框。
为了简化讨论,我们只考虑每个区域一个锚框。 实际上,应该考虑代表不同缩放比例,大小和纵横比的所有锚框。 在下一节中,我们讨论如何制定损失函数,这些损失函数将通过 SSD 网络进行优化。
“列表 11.3.1”显示了get_gt_data()的实现,该实现计算锚定框的真实情况标签。
“列表 11.3.1”:layer_utils.py
def get_gt_data(iou,
n_classes=4,
anchors=None,
labels=None,
normalize=False,
threshold=0.6):
"""Retrieve ground truth class, bbox offset, and mask
Arguments:
iou (tensor): IoU of each bounding box wrt each anchor box
n_classes (int): Number of object classes
anchors (tensor): Anchor boxes per feature layer
labels (list): Ground truth labels
normalize (bool): If normalization should be applied
threshold (float): If less than 1.0, anchor boxes>threshold
are also part of positive anchor boxes
Returns:
gt_class, gt_offset, gt_mask (tensor): Ground truth classes,
offsets, and masks
"""
# each maxiou_per_get is index of anchor w/ max iou
# for the given ground truth bounding box
maxiou_per_gt = np.argmax(iou, axis=0)
# get extra anchor boxes based on IoU
if threshold < 1.0:
iou_gt_thresh = np.argwhere(iou>threshold)
if iou_gt_thresh.size > 0:
extra_anchors = iou_gt_thresh[:,0]
extra_classes = iou_gt_thresh[:,1]
extra_labels = labels[extra_classes]
indexes = [maxiou_per_gt, extra_anchors]
maxiou_per_gt = np.concatenate(indexes,
axis=0)
labels = np.concatenate([labels, extra_labels],
axis=0)
# mask generation
gt_mask = np.zeros((iou.shape[0], 4))
# only indexes maxiou_per_gt are valid bounding boxes
gt_mask[maxiou_per_gt] = 1.0
# class generation
gt_class = np.zeros((iou.shape[0], n_classes))
# by default all are background (index 0)
gt_class[:, 0] = 1
# but those that belong to maxiou_per_gt are not
gt_class[maxiou_per_gt, 0] = 0
# we have to find those column indexes (classes)
maxiou_col = np.reshape(maxiou_per_gt,
(maxiou_per_gt.shape[0], 1))
label_col = np.reshape(labels[:,4],
(labels.shape[0], 1)).astype(int)
row_col = np.append(maxiou_col, label_col, axis=1)
# the label of object in maxio_per_gt
gt_class[row_col[:,0], row_col[:,1]] = 1.0
# offsets generation
gt_offset = np.zeros((iou.shape[0], 4))
#(cx, cy, w, h) format
if normalize:
anchors = minmax2centroid(anchors)
labels = minmax2centroid(labels)
# bbox = bounding box
# ((bbox xcenter - anchor box xcenter)/anchor box width)/.1
# ((bbox ycenter - anchor box ycenter)/anchor box height)/.1
# Equation 11.4.8 Chapter 11
offsets1 = labels[:, 0:2] - anchors[maxiou_per_gt, 0:2]
offsets1 /= anchors[maxiou_per_gt, 2:4]
offsets1 /= 0.1
# log(bbox width / anchor box width) / 0.2
# log(bbox height / anchor box height) / 0.2
# Equation 11.4.8 Chapter 11
offsets2 = np.log(labels[:, 2:4]/anchors[maxiou_per_gt, 2:4])
offsets2 /= 0.2
offsets = np.concatenate([offsets1, offsets2], axis=-1)
# (xmin, xmax, ymin, ymax) format
else:
offsets = labels[:, 0:4] - anchors[maxiou_per_gt]
gt_offset[maxiou_per_gt] = offsets
return gt_class, gt_offset, gt_mask
def minmax2centroid(boxes):
"""Minmax to centroid format
(xmin, xmax, ymin, ymax) to (cx, cy, w, h)
Arguments:
boxes (tensor): Batch of boxes in minmax format
Returns:
centroid (tensor): Batch of boxes in centroid format
"""
centroid = np.copy(boxes).astype(np.float)
centroid[..., 0] = 0.5 * (boxes[..., 1] - boxes[..., 0])
centroid[..., 0] += boxes[..., 0]
centroid[..., 1] = 0.5 * (boxes[..., 3] - boxes[..., 2])
centroid[..., 1] += boxes[..., 2]
centroid[..., 2] = boxes[..., 1] - boxes[..., 0]
centroid[..., 3] = boxes[..., 3] - boxes[..., 2]
return centroid
maxiou_per_gt = np.argmax(iou, axis=0)实现了“公式 11.3.2”。 额外的阳性锚框是基于由iou_gt_thresh = np.argwhere(iou>threshold)实现的用户定义的阈值确定的。
仅当阈值小于 1.0 时,才会查找额外的正锚框。 所有带有地面真值边界框的锚框(即组合的正锚框和额外的正锚框)的索引成为真实情况掩码的基础:
gt_mask[maxiou_per_gt] = 1.0。
所有其他锚定框(负锚定框)的掩码为 0.0,并且不影响偏移损失函数的优化。
每个锚定框的类别gt_class被分配为其地面实况边界框的类别。 最初,为所有锚框分配背景类:
# class generation
gt_class = np.zeros((iou.shape[0], n_classes))
# by default all are background (index 0)
gt_class[:, 0] = 1
然后,将每个正面锚点框的类分配给其非背景对象类:
# but those that belong to maxiou_per_gt are not
gt_class[maxiou_per_gt, 0] = 0
# we have to find those column indexes (classes)
maxiou_col = np.reshape(maxiou_per_gt,
(maxiou_per_gt.shape[0], 1))
label_col = np.reshape(labels[:,4],
(labels.shape[0], 1)).astype(int)
row_col = np.append(maxiou_col, label_col, axis=1)
# the label of object in maxio_per_gt
gt_class[row_col[:,0], row_col[:,1]] = 1.0
row_col[:,0]是正锚框的索引,而row_col[:,1]是它们的非背景对象类的索引。 请注意,gt_class是单热点向量的数组。 这些值都为零,除了锚点框对象的索引处。 索引 0 是背景,索引 1 是第一个非背景对象,依此类推。 最后一个非背景对象的索引等于n_classes-1。
例如,如果锚点框 0 是负锚点框,并且有 4 个对象类别(包括背景),则:
gt_class[0] = [1.0, 0.0, 0.0, 0.0]
如果锚定框 1 是正锚定框,并且其地面真值边界框包含带有标签 2 的汽水罐,则:
gt_class[1] = [0.0, 0.0, 1.0, 0.0]
最后,偏移量只是地面真实边界框坐标减去锚框坐标:
# (xmin, xmax, ymin, ymax) format
else:
offsets = labels[:, 0:4] - anchors[maxiou_per_gt]
注意,我们仅计算正锚框的偏移量。
如果选择了该选项,则可以将偏移量标准化。 下一部分将讨论偏移量归一化。 我们将看到:
#(cx, cy, w, h) format
if normalize:
anchors = minmax2centroid(anchors)
labels = minmax2centroid(labels)
# bbox = bounding box
# ((bbox xcenter - anchor box xcenter)/anchor box width)/.1
# ((bbox ycenter - anchor box ycenter)/anchor box height)/.1
# Equation 11.4.8
offsets1 = labels[:, 0:2] - anchors[maxiou_per_gt, 0:2]
offsets1 /= anchors[maxiou_per_gt, 2:4]
offsets1 /= 0.1
# log(bbox width / anchor box width) / 0.2
# log(bbox height / anchor box height) / 0.2
# Equation 11.4.8
offsets2 = np.log(labels[:, 2:4]/anchors[maxiou_per_gt, 2:4])
offsets2 /= 0.2
offsets = np.concatenate([offsets1, offsets2], axis=-1)
只是“公式 11.4.8”的实现,下一节将进行讨论,为方便起见,在此处显示:
 (Equation 11.4.8)
(Equation 11.4.8)
现在我们已经了解了地面真锚框的作用,我们将继续研究对象检测中的另一个关键组件:损失函数。
4. 损失函数
在 SSD 中,有数千个锚定框。 如本章前面所述,对象检测的目的是预测每个锚框的类别和偏移量。 我们可以对每个预测使用以下损失函数:
L_cls-y_cls的分类交叉熵损失L_off- L1 或 L2,用于y_cls。 请注意,只有正锚框有助于L_offL1,也称为平均绝对误差(MAE)损失,而 L2 也称为均方误差(MSE)损失。
总的损失函数为:
 (Equation 11.4.1)
(Equation 11.4.1)
对于每个定位框,网络都会预测以下内容:
y_cls或单热向量形式的类别或类y_off = ((x_omin, y_omin), (x_omax, y_omax))或相对于锚框的像素坐标形式的偏移。
为了方便计算,可以将偏移量更好地表示为以下形式:
y_off = ((x_omin, y_omin), (x_omax, y_omax)) (Equation 11.4.2)
SSD 是一种监督对象检测算法。 可以使用以下基本真值:
y_label或要检测的每个对象的类标签y_gt = (x_gmin, x_gmax, y_gmin, y_gmax)或地面真实偏差,其计算公式如下:
y_gt = (x_bmin – x_amin, x_bmax – x_amax, y_bmin – y_amin, y_bmax – y_amax) (Equation 11.4.3)
换句话说,将地面真实偏移量计算为对象包围盒相对于锚定框的地面真实偏移量。 为了清楚起见,y_box下标中的细微调整。 如上一节所述,基本真值是通过get_gt_data()函数计算的。
但是,SSD 不建议直接从预测原始像素误差值y_off。 而是使用归一化的偏移值。 地面真值边界框和锚点框坐标首先以质心尺寸格式表示:


(Equation 11.4.4)
哪里:
 (Equation 11.4.5)
(Equation 11.4.5)
是边界框中心的坐标,并且:
(w[b], h[b]) = (x_max – x_min, y_max - y_min) (Equation 11.4.6)
分别对应于宽度和高度。 锚框遵循相同的约定。 归一化的真实情况偏移量表示为:
 (Equation 11.4.7)
(Equation 11.4.7)
通常,y_gt的元素值很小,||y_gt|| << 1.0。 较小的梯度会使网络训练更加难以收敛。
为了缓解该问题,将每个元素除以其估计的标准差。 由此产生的基本事实抵消了:
(Equation 11.4.8)
推荐值为:σ[x] = σ[y] = 0.1和σ[w] = σ[h] = 0.2。 换句话说,沿着x和y轴的像素误差的预期范围是± 10%,而对于宽度和高度,则是`± 20%。 这些值纯粹是任意的。
“列表 11.4.1”:loss.py L1 和平滑 L1 损失函数
from tensorflow.keras.losses import Huber
def mask_offset(y_true, y_pred):
"""Pre-process ground truth and prediction data"""
# 1st 4 are offsets
offset = y_true[..., 0:4]
# last 4 are mask
mask = y_true[..., 4:8]
# pred is actually duplicated for alignment
# either we get the 1st or last 4 offset pred
# and apply the mask
pred = y_pred[..., 0:4]
offset *= mask
pred *= mask
return offset, pred
def l1_loss(y_true, y_pred):
"""MAE or L1 loss
"""
offset, pred = mask_offset(y_true, y_pred)
# we can use L1
return K.mean(K.abs(pred - offset), axis=-1)
def smooth_l1_loss(y_true, y_pred):
"""Smooth L1 loss using tensorflow Huber loss
"""
offset, pred = mask_offset(y_true, y_pred)
# Huber loss as approx of smooth L1
return Huber()(offset, pred)
此外,代替y_cls的 L1 损失,SSD 受 Fast-RCNN [3]启发,使用平滑 L1:
 (Equation 11.4.9)
(Equation 11.4.9)
其中u代表地面真实情况与预测之间的误差中的每个元素:
 (Equation 11.4.10)
(Equation 11.4.10)
与 L1 相比,平滑 L1 更健壮,并且对异常值的敏感性较低。 在 SSD 中,σ = 1。 作为σ -> ∞,平滑 L1 接近 L1。 L1 和平滑 L1 损失函数都在“列表 11.4.1”中显示。 mask_offset()方法可确保仅在具有地面真实边界框的预测上计算偏移量。 平滑的 L1 函数与σ = 1[8]时的 Huber 损失相同。
作为对损失函数的进一步改进,RetinaNet [3]建议将 CEy_cls的分类交叉熵函数替换为焦点损失 FL:
 (Equation 11.4.11)
(Equation 11.4.11)
 (Equation 11.4.12)
(Equation 11.4.12)
区别在于额外因素α(1 - p[i])^γ。 在 RetinaNet 中,当γ = 2和α = 0.25时,对象检测效果最好。 焦点损失在“列表 11.4.2”中实现。
“列表 11.4.2”:loss.py焦点损失
def focal_loss_categorical(y_true, y_pred):
"""Categorical cross-entropy focal loss"""
gamma = 2.0
alpha = 0.25
# scale to ensure sum of prob is 1.0
y_pred /= K.sum(y_pred, axis=-1, keepdims=True)
# clip the prediction value to prevent NaN and Inf
epsilon = K.epsilon()
y_pred = K.clip(y_pred, epsilon, 1\. - epsilon)
# calculate cross entropy
cross_entropy = -y_true * K.log(y_pred)
# calculate focal loss
weight = alpha * K.pow(1 - y_pred, gamma)
cross_entropy *= weight
return K.sum(cross_entropy, axis=-1)
聚焦损失的动机是,如果我们检查图像,则大多数锚框应分类为背景或负锚框。 只有很少的正锚框是代表目标对象的良好候选对象。 负熵损失是造成交叉熵损失的主要因素。 因此,负锚框的贡献使优化过程中正锚框的贡献无法实现。 这种现象也称为类不平衡,其中一个或几个类占主导地位。 有关其他详细信息,Lin 等。 文献[4]讨论了对象检测中的类不平衡问题。
有了焦点损失,我们在优化过程的早期就确信负锚框属于背景。 因此,由于p[i] -> 1.0,项(1 - p[i])^γ减少了负锚框的贡献。 对于正锚框,其贡献仍然很大,因为p[i]远非 1.0。
既然我们已经讨论了锚定框,地面真值锚定框和损失函数的概念,我们现在准备介绍实现多尺度目标检测算法的 SSD 模型架构。
5. SSD 模型架构
“图 11.5.1”显示了 SSD 的模型架构,该模型实现了多尺度单发目标检测的概念框架。 网络接受 RGB 图像,并输出几个预测级别。 基本或骨干网络提取用于分类和偏移量预测的下游任务的特征。 ResNet50 是骨干网络的一个很好的例子,它类似于“第 2 章”,“深度神经网络”中讨论,实现和评估的内容。 在骨干网络之后,对象检测任务由执行其余的网络,我们将其称为 SSD 头。
骨干网络可以是具有冻结权重的预训练网络(例如,以前为 ImageNet 分类而训练),也可以是与对象检测一起训练的网络。 如果使用预先训练的基础网络,则可以利用重用以前从大型数据集中学习的特征提取过滤器的优势。 此外,由于冻结了骨干网参数,因此可以加快学习速度。 仅训练对象检测中的顶层。 在这本书中,骨干网是与对象检测联合训练的,因为我们假设我们不一定需要访问预先训练的骨干网。
骨干网网络通常使用跨步 2 或通过最大池化实现几轮下采样。 对于 ResNet50,这是 4 倍。 基本网络变为(w/2^4, h/2^4) = (w/16, h/16)之后,特征映射的结果尺寸。 如果图像的宽度和高度均可以被 16 整除,则尺寸是精确的。
例如,对于640 x 480的图像,生成的特征映射的尺寸为40 x 30 = 1200。 如前几节所述,这是基础网络之后长宽比等于 1 的锚点框的数量。 此数字乘以每个锚定框的大小数。 在前面的部分中,由于长宽比,有 6 种不同的尺寸,而长宽比为 1 时,还有一个其他尺寸。
在本书中,我们将纵横比限制为a[i ∈ {0, 1, 3}] = 1, 2, 1/2。 因此,将只有 4 种不同的大小。 对于640 x 480图像,第一组锚框的锚框总数为n[1] = 4,800。
在“图 11.5.1”中,指示密集网格以表明对于第一组预测,存在大量预测(例如:40 x 30 x 4),从而导致大量补丁 。 尽管每个锚点框有 4 种尺寸,但为清楚起见,仅显示了与宽高比 1 对应的16 x 16锚点框。
此锚框也是40 x 30 x n_filter特征映射中每个元素的接受字段大小。n_filter是骨干网最后卷积层中过滤器的数量。 对于每个锚框,都将预测类别和偏移量。
总共有n[1]类和n[1]偏移量预测。 单热类预测的维数等于要检测的对象类别的数量,背景为 1。 每个偏移量变量预测的尺寸为 4,对应于(x, y)到预测边界框的 2 个角的偏移量。
类预测器由卷积层组成,该卷积层由使用 softmax 进行分类交叉熵损失的激活层终止。 偏移量预测值是具有线性激活的独立卷积层。
在基础网络之后可以应用其他特征提取模块。 每个特征提取器块都是Conv2D(strides=2)-BN-ELU的形式。 在特征提取块之后,特征映射的大小减半,并且过滤器的数量增加一倍。 例如,基本网络之后的第一个特征提取器块具有20 x 15 x 2 n_filter特征映射。 根据该特征映射,使用卷积层进行n[2]类和n[2]偏移量预测。n[2] = 20 x 15 x 4 = 1,200
可以继续添加具有类和偏移量预测变量的特征提取块的过程。 在前面的部分中,对于640 x 480的图像,最大可达2 x 1 x 2^5 n_filter特征映射产生n[6]类和n[6]抵消了其中n[6] = 2 x 1 x 4 = 8的预测。 到 6 层特征提取和预测块。 在第 6 个块之后,一个640 x 480图像的锚点映射预测总数为 9,648。
在前面的部分中,锚定框的比例因子大小按降序排列:
 Equation 11.5.1)
Equation 11.5.1)
这样做是为了使讨论清晰。 在本节中,应该意识到比例因子的大小实际上是从骨干网之后的特征映射大小开始的。 实际上,缩放因子应按升序排列:
 (Equation 11.5.2)
(Equation 11.5.2)
这意味着如果将特征提取块的数量减少到 4,则缩放因子为:
 (Equation 11.5.3)
(Equation 11.5.3)
如果特征映射的宽度或高度不能被 2 整除(例如:15),则将应用天花板函数(例如:ceil(15/2) = 8)。 但是,在原始的 SSD [2]实现中,所使用的缩放因子被简化为[0.2, 0.9]范围,该范围通过缩放因子的数量或特征提取块的数量n_layers进行线性缩放:
s = np.linspace(0.2, 0.9, n_layers + 1)

图 11.5.1 SSD 模型架构。请注意,对于w/16 x h/16网格,锚框的数量可能不准确。 网格显示了锚框的紧密包装。
讨论了 SSD 模型架构之后,现在让我们看一下如何在 Keras 中实现 SSD 模型架构。
6. Keras 中的 SSD 模型架构
与前面章节中的代码示例不同,SSD 的tf.keras实现更加复杂。 与 SSD 的其他tf.keras实现相比,本章中提供的代码示例重点介绍多尺度目标检测的关键概念。 可以进一步优化代码实现的某些部分,例如缓存地面真锚框类,偏移量和掩码。 在我们的示例中,每次从文件系统加载图像时,线程都会计算出地面真实值。
“图 11.6.1”显示了包含 SSD 的tf.keras实现的代码块的概述。 ssd-11.6.1.py中的 SSD 对象可以构建,训练和评估 SSD 模型。 它借助model.py和resnet.py以及data_generator.py中的多线程数据生成器,位于 SSD 模型创建器的顶部。 SSD 模型实现了“图 11.5.1”中所示的 SSD 架构。 每个主要模块的实现将在后续部分中详细讨论。
SSD 模型使用 ResNet 作为其骨干网络。 它在resnet.py中调用 ResNet V1 或 V2 模型创建者。 与前几章中的示例不同,SSD 使用的数据集由数千个高分辨率图像组成。 多线程数据生成器将加载文件,并且将这些文件从文件系统排队。 它还计算锚点箱的地面真值标签。 如果没有多线程数据生成器,则在训练期间图像的加载和排队以及地面真值的计算将非常缓慢。
有许多小的但重要的例程在后台运行。 这些都集中存储在工具块中。 这些例程创建锚框,计算 IoU,建立真实情况标签,运行非最大抑制,绘制标签和框,在视频帧上显示检测到的对象,提供损失函数等。

图 11.6.1 实现 SSD 的代码块。
7. Keras 中的 SSD 对象
“列表 11.7.1”(很快显示)显示了 SSD 类。 说明了两个主要例程:
-
使用
build_model()创建 SSD 模型 -
通过
build_generator()实例化数据生成器
build_model首先根据训练标签创建数据字典。 字典存储图像文件名以及每个图像中每个对象的地面真实边界框坐标和类。 之后,构建骨干网和 SSD 网络模型。 模型创建的最重要产品是self.ssd – SSD 的网络模型。
标签存储在 csv 文件中。 对于本书中使用的示例训练图像,标签以以下格式保存在dataset/drinks/labels_train.csv中:
frame,xmin,xmax,ymin,ymax,class_id
0001000.jpg,310,445,104,443,1
0000999.jpg,194,354,96,478,1
0000998.jpg,105,383,134,244,1
0000997.jpg,157,493,89,194,1
0000996.jpg,51,435,207,347,1
0000995.jpg,183,536,156,283,1
0000994.jpg,156,392,178,266,2
0000993.jpg,207,449,119,213,2
0000992.jpg,47,348,213,346,2
…
“列表 11.7.1”:ssd-11.6.1.py
class SSD:
"""Made of an ssd network model and a dataset generator.
SSD defines functions to train and validate
an ssd network model.
Arguments:
args: User-defined configurations
Attributes:
ssd (model): SSD network model
train_generator: Multi-threaded data generator for training
"""
def __init__(self, args):
"""Copy user-defined configs.
Build backbone and ssd network models.
"""
self.args = args
self.ssd = None
self.train_generator = None
self.build_model()
def build_model(self):
"""Build backbone and SSD models."""
# store in a dictionary the list of image files and labels
self.build_dictionary()
# input shape is (480, 640, 3) by default
self.input_shape = (self.args.height,
self.args.width,
self.args.channels)
# build the backbone network (eg ResNet50)
# the number of feature layers is equal to n_layers
# feature layers are inputs to SSD network heads
# for class and offsets predictions
self.backbone = self.args.backbone(self.input_shape,
n_layers=self.args.layers)
# using the backbone, build ssd network
# outputs of ssd are class and offsets predictions
anchors, features, ssd = build_ssd(self.input_shape,
self.backbone,
n_layers=self.args.layers,
n_classes=self.n_classes)
# n_anchors = num of anchors per feature point (eg 4)
self.n_anchors = anchors
# feature_shapes is a list of feature map shapes
# per output layer - used for computing anchor boxes sizes
self.feature_shapes = features
# ssd network model
self.ssd = ssd
def build_dictionary(self):
"""Read input image filenames and obj detection labels
from a csv file and store in a dictionary.
"""
# train dataset path
path = os.path.join(self.args.data_path,
self.args.train_labels)
# build dictionary:
# key=image filaname, value=box coords + class label
# self.classes is a list of class labels
self.dictionary, self.classes = build_label_dictionary(path)
self.n_classes = len(self.classes)
self.keys = np.array(list(self.dictionary.keys()))
def build_generator(self):
"""Build a multi-thread train data generator."""
self.train_generator = \
DataGenerator(args=self.args,
dictionary=self.dictionary,
n_classes=self.n_classes,
feature_shapes=self.feature_shapes,
n_anchors=self.n_anchors,
shuffle=True)
“列表 11.7.2”显示了 SSD 对象中的另一种重要方法train()。 指示了使用默认损失函数或改进的损失函数的选项,如先前部分所述。 还有一个选项可以选择仅平滑 L1。
self.ssd.fit_generator()是此函数中最重要的调用。 它借助多线程数据生成器启动有监督的训练。 在每个周期,都会执行两个回调函数。 首先,将模型权重保存到文件中。 然后,对于 ResNet 模型,以与“第 2 章”,“深度神经网络”相同的方式使用的改进的学习率调度器称为:
“列表 11.7.2”:ssd-11.6.1.py
def train(self):
"""Train an ssd network."""
# build the train data generator
if self.train_generator is None:
self.build_generator()
optimizer = Adam(lr=1e-3)
# choice of loss functions via args
if self.args.improved_loss:
print_log("Focal loss and smooth L1", self.args.verbose)
loss = [focal_loss_categorical, smooth_l1_loss]
elif self.args.smooth_l1:
print_log("Smooth L1", self.args.verbose)
loss = ['categorical_crossentropy', smooth_l1_loss]
else:
print_log("Cross-entropy and L1", self.args.verbose)
loss = ['categorical_crossentropy', l1_loss]
self.ssd.compile(optimizer=optimizer, loss=loss)
# prepare callbacks for saving model weights
# and learning rate scheduler
# learning rate decreases by 50% every 20 epochs
# after 60th epoch
checkpoint = ModelCheckpoint(filepath=filepath,
verbose=1,
save_weights_only=True)
scheduler = LearningRateScheduler(lr_scheduler)
callbacks = [checkpoint, scheduler]
# train the ssd network
self.ssd.fit_generator(generator=self.train_generator,
use_multiprocessing=True,
callbacks=callbacks,
epochs=self.args.epochs,
workers=self.args.workers)
在下一部分中,我们将讨论 Keras 中 SSD 架构实现的其他详细信息。 特别是 SSD 模型和多线程数据生成器的实现。
8. Keras 中的 SSD 模型
“列表 11.8.1”显示了 SSD 模型创建函数build_ssd()。 该模型在“图 11.5.1”中进行了说明。 该函数通过调用base_outputs = backbone(inputs)从骨干网或基础网络检索输出特征的n_layers。
在本书中,backbone()是build_resnet()。 build_resnet()可以生成的 ResNet 模型类似于“第 2 章”,“深度神经网络”中讨论的残差网络。 build_resnet()函数可以由构建基础网络的任何函数名称代替。
如图“图 11.5.1”所示,返回值base_outputs是输出特征的列表,这些特征将作为类别和偏移预测层的输入。 例如,第一输出base_outputs[0]用于生成n[1]类预测和n[1]偏移量预测。
在build_ssd()的for循环中,类别预测是classes变量,而偏移量预测是offsets变量。 在for循环迭代之后,将类别预测连接,并最终合并为一个具有以下尺寸的classes变量:

对offsets变量执行相同的过程。 结果尺寸为:

其中n_mini_batch是迷你批量大小,n_anchor_box是锚定框的数量。 for循环迭代的次数等于n_layers。 该数目也等于锚定框缩放因子的所需数目或 SSD 头的特征提取块的数目。
函数build_ssd()返回每个特征点或区域的锚框数量,每个前类的特征形状,偏移量预测层以及 SSD 模型本身。
“列表 11.8.1”:model.py
def build_ssd(input_shape,
backbone,
n_layers=4,
n_classes=4,
aspect_ratios=(1, 2, 0.5)):
"""Build SSD model given a backbone
Arguments:
input_shape (list): input image shape
backbone (model): Keras backbone model
n_layers (int): Number of layers of ssd head
n_classes (int): Number of obj classes
aspect_ratios (list): annchor box aspect ratios
Returns:
n_anchors (int): Number of anchor boxes per feature pt
feature_shape (tensor): SSD head feature maps
model (Keras model): SSD model
"""
# number of anchor boxes per feature map pt
n_anchors = len(aspect_ratios) + 1
inputs = Input(shape=input_shape)
# no. of base_outputs depends on n_layers
base_outputs = backbone(inputs)
outputs = []
feature_shapes = []
out_cls = []
out_off = []
for i in range(n_layers):
# each conv layer from backbone is used
# as feature maps for class and offset predictions
# also known as multi-scale predictions
conv = base_outputs if n_layers==1 else base_outputs[i]
name = "cls" + str(i+1)
classes = conv2d(conv,
n_anchors*n_classes,
kernel_size=3,
name=name)
# offsets: (batch, height, width, n_anchors * 4)
name = "off" + str(i+1)
offsets = conv2d(conv,
n_anchors*4,
kernel_size=3,
name=name)
shape = np.array(K.int_shape(offsets))[1:]
feature_shapes.append(shape)
# reshape the class predictions, yielding 3D tensors of
# shape (batch, height * width * n_anchors, n_classes)
# last axis to perform softmax on them
name = "cls_res" + str(i+1)
classes = Reshape((-1, n_classes),
name=name)(classes)
# reshape the offset predictions, yielding 3D tensors of
# shape (batch, height * width * n_anchors, 4)
# last axis to compute the (smooth) L1 or L2 loss
name = "off_res" + str(i+1)
offsets = Reshape((-1, 4),
name=name)(offsets)
# concat for alignment with ground truth size
# made of ground truth offsets and mask of same dim
# needed during loss computation
offsets = [offsets, offsets]
name = "off_cat" + str(i+1)
offsets = Concatenate(axis=-1,
name=name)(offsets)
# collect offset prediction per scale
out_off.append(offsets)
name = "cls_out" + str(i+1)
#activation = 'sigmoid' if n_classes==1 else 'softmax'
#print("Activation:", activation)
classes = Activation('softmax',
name=name)(classes)
# collect class prediction per scale
out_cls.append(classes)
if n_layers > 1:
# concat all class and offset from each scale
name = "offsets"
offsets = Concatenate(axis=1,
name=name)(out_off)
name = "classes"
classes = Concatenate(axis=1,
name=name)(out_cls)
else:
offsets = out_off[0]
classes = out_cls[0]
outputs = [classes, offsets]
model = Model(inputs=inputs,
outputs=outputs,
name='ssd_head')
return n_anchors, feature_shapes, model
如前面所述,与 MNIST 和 CIFAR-10 等小型数据集不同,SSD 中使用的映像很大。 因此,不可能将图像加载到张量变量中。 在下一节中,我们将介绍一个多线程数据生成器,该生成器将使我们能够从文件系统并发加载图像,并避免内存瓶颈。
9. Keras 中的数据生成器模型
SSD 需要大量带标签的高分辨率图像来进行对象检测。 与之前的章节中使用的数据集可以加载到到内存中以训练模型不同,SSD 实现了多线程数据生成器。 多线程生成器的任务是加载图像的多个迷你批量及其相应的标签。 由于具有多线程,GPU 可以保持繁忙,因为一个线程向其提供数据,而其余的 CPU 线程处于队列中,准备从文件系统中馈入另一批数据或加载一批图像并计算基本真值 。“列表 11.9.1”显示了 Keras 中的数据生成器模型。
DataGenerator类继承自 Keras 的Sequence类,以确保它支持多处理。 DataGenerator保证在一个周期内使用整个数据集。
给定批量大小的整个周期的长度由__len__()方法返回。 对小批量数据的每个请求都可以通过__getitem__()方法来满足。 在每个周期之后,如果self.shuffle为True,则调用on_epoch_end()方法以随机播放整个批量。
“列表 11.9.1”:data_generator.py
class DataGenerator(Sequence):
"""Multi-threaded data generator.
Each thread reads a batch of images and their object labels
Arguments:
args: User-defined configuration
dictionary: Dictionary of image filenames and object labels
n_classes (int): Number of object classes
feature_shapes (tensor): Shapes of ssd head feature maps
n_anchors (int): Number of anchor boxes per feature map pt
shuffle (Bool): If dataset should be shuffled bef sampling
"""
def __init__(self,
args,
dictionary,
n_classes,
feature_shapes=[],
n_anchors=4,
shuffle=True):
self.args = args
self.dictionary = dictionary
self.n_classes = n_classes
self.keys = np.array(list(self.dictionary.keys()))
self.input_shape = (args.height,
args.width,
args.channels)
self.feature_shapes = feature_shapes
self.n_anchors = n_anchors
self.shuffle = shuffle
self.on_epoch_end()
self.get_n_boxes()
def __len__(self):
"""Number of batches per epoch"""
blen = np.floor(len(self.dictionary) / self.args.batch_size)
return int(blen)
def __getitem__(self, index):
"""Get a batch of data"""
start_index = index * self.args.batch_size
end_index = (index+1) * self.args.batch_size
keys = self.keys[start_index: end_index]
x, y = self.__data_generation(keys)
return x, y
def on_epoch_end(self):
"""Shuffle after each epoch"""
if self.shuffle == True:
np.random.shuffle(self.keys)
def get_n_boxes(self):
"""Total number of bounding boxes"""
self.n_boxes = 0
for shape in self.feature_shapes:
self.n_boxes += np.prod(shape) // self.n_anchors
return self.n_boxes
数据生成器的大部分工作都是通过__data_generation()方法完成的,如“列表 11.9.2”所示。 给定一个小批量,该方法执行:
imread()从文件系统读取图像。labels = self.dictionary[key]访问词典中存储的边界框和类标签。 前四个项目是边界框偏移量。 最后一个是类标签。anchor_boxes()生成锚框。iou()计算相对于地面真值边界框的每个锚点框的 IoU。get_gt_data()为每个锚框分配地面真实等级和偏移量。
样本数据扩充函数也包括在内,但此处不再讨论,例如添加随机噪声,强度重新缩放和曝光调整。 __data_generation()返回输入x和输出y对,其中张量x存储输入图像,而张量y捆绑类,偏移量 ,和面具一起。
“列表 11.9.2”:data_generator.py
import layer_utils
from skimage.io import imread
def __data_generation(self, keys):
"""Generate train data: images and
object detection ground truth labels
Arguments:
keys (array): Randomly sampled keys
(key is image filename)
Returns:
x (tensor): Batch images
y (tensor): Batch classes, offsets, and masks
"""
# train input data
x = np.zeros((self.args.batch_size, *self.input_shape))
dim = (self.args.batch_size, self.n_boxes, self.n_classes)
# class ground truth
gt_class = np.zeros(dim)
dim = (self.args.batch_size, self.n_boxes, 4)
# offsets ground truth
gt_offset = np.zeros(dim)
# masks of valid bounding boxes
gt_mask = np.zeros(dim)
for i, key in enumerate(keys):
# images are assumed to be stored in self.args.data_path
# key is the image filename
image_path = os.path.join(self.args.data_path, key)
image = skimage.img_as_float(imread(image_path))
# assign image to a batch index
x[i] = image
# a label entry is made of 4-dim bounding box coords
# and 1-dim class label
labels = self.dictionary[key]
labels = np.array(labels)
# 4 bounding box coords are 1st four items of labels
# last item is object class label
boxes = labels[:,0:-1]
for index, feature_shape in enumerate(self.feature_shapes):
# generate anchor boxes
anchors = anchor_boxes(feature_shape,
image.shape,
index=index,
n_layers=self.args.layers)
# each feature layer has a row of anchor boxes
anchors = np.reshape(anchors, [-1, 4])
# compute IoU of each anchor box
# with respect to each bounding boxes
iou = layer_utils.iou(anchors, boxes)
# generate ground truth class, offsets & mask
gt = get_gt_data(iou,
n_classes=self.n_classes,
anchors=anchors,
labels=labels,
normalize=self.args.normalize,
threshold=self.args.threshold)
gt_cls, gt_off, gt_msk = gt
if index == 0:
cls = np.array(gt_cls)
off = np.array(gt_off)
msk = np.array(gt_msk)
else:
cls = np.append(cls, gt_cls, axis=0)
off = np.append(off, gt_off, axis=0)
msk = np.append(msk, gt_msk, axis=0)
gt_class[i] = cls
gt_offset[i] = off
gt_mask[i] = msk
y = [gt_class, np.concatenate((gt_offset, gt_mask), axis=-1)]
return x, y
现在我们有一个多线程生成器,我们可以用它来从文件系统加载图像。 在下一节中,我们将演示如何通过拍摄目标对象的图像并对其进行标记来构建自定义数据集。
10. 示例数据集
使用便宜的 USB 相机(A4TECH PK-635G)收集了一个由 1,000 640 X 480 RGB 训练图像和 50 640 X 480 RGB 测试图像组成的小型数据集。 使用 VGG 图像标注器(VIA)[5]标记数据集图像,以检测三个对象:1)汽水罐,2)果汁罐和 3)水瓶。“图 11.10.1”显示了标记过程的示例 UI。
可以在GitHub存储库的utils/video_capture.py中找到用于收集图像的工具脚本。 该脚本每 5 秒自动捕获一次图像,因此可以加快数据收集过程。

图 11.10.1 使用 VGG 图像标注器(VIA)进行数据集标记的过程
数据收集和标记是一项耗时的活动。 在行业中,通常将其外包给第三方标注公司。 使用自动数据标记软件是加快数据标记任务的另一种选择。
有了这个示例数据集,我们现在可以训练我们的对象检测网络。
11. SSD 模型训练
可以从以下链接下载包含 csv 格式标签的 train 和测试数据集。
在顶层文件夹(即“第 11 章”,“对象检测”)中,创建数据集文件夹,将下载的文件复制到此处,然后运行以下命令将其解压缩:
mkdir dataset
cp drinks.tar.gz dataset
cd dataset
tar zxvf drinks.tar.gz
cd..
通过执行以下步骤,将 SSD 模型训练 200 个周期:
python3 ssd-11.6.1.py --train
可以根据 GPU 内存调整默认的批量大小--batch-size=4。 在 1080Ti 上,批量大小为 2。在 32GB V100 上,每个 GPU 可以为 4 或 8。 --train代表模型训练选项。
为了支持边界框偏移量的归一化,包含--normalize选项。 为了使用改进的损失函数,添加了--improved_loss选项。 如果仅需要平滑的 L1(无焦点损失),请使用–smooth-l1。 为了显示:
- L1,无规范化:
python3 ssd-11.1.1.py –-train
- 改进的损失函数,无规范化:
python3 ssd-11.1.1.py –-train --improved-loss
- 改进的损失函数,具有规范化:
python3 ssd-11.1.1.py –-train –improved-loss --normalize
- 平滑 L1,具有规范化:
python3 ssd-11.1.1.py –-train –-smooth-l1 --normalize
训练完 SSD 网络之后,我们需要解决另一个问题。 我们如何处理给定对象的多个预测? 在测试训练好的模型之前,我们将首先讨论非最大抑制(NMS)算法。
12. 非最大抑制(NMS)算法
模型训练完成后,网络将预测边界框偏移量和相应的类别。 在某些情况下,两个或更多边界框引用同一对象,从而创建冗余预测。 图 11.12.1 中的汽水罐表示了这种情况。 为了删除多余的预测,将调用 NMS 算法。 本书涵盖了经典 NMS 和软 NMS [6],如“算法 11.12.1”中所示。 两种算法都假定边界框和相应的置信度得分或概率是已知的。

图 11.12.1 网络预测了汽水罐对象的两个重叠边界框。 只选择一个有效的边界框,即得分为 0.99 的边界框。
在经典 NMS 中,基于概率选择最终边界框,并将其存储在列表D中,并带有相应的分数S。 所有边界框和相应的概率都存储在初始列表B和P中。 在第 3 行和第 4 行中,将具有最高分数p[m]的边界框用作参考,b[m]。
参考边界框被添加到最终选择的边界框D的列表中,并从列表B中删除,如第 5 行所示。 并且列表S从P中删除。 对于其余边界框,如果 IoU 与b[m]大于或等于设置的阈值N[t],将其从B中删除。 其相应的分数也从P中删除。
步骤在第 6 和 9-11 行中显示。 这些步骤将删除所有分数较小的冗余边界框。 在检查完所有其余的边界框之后,重复从第 3 行开始的过程。 该过程继续进行,直到边界框B的列表为空。 该算法返回选定的边界框D和相应的分数S。
经典 NMS 的问题是边界盒包含另一个对象,但其中的 IoU 和b[m]会从列表中删除。 Soft NMS [6]提出,与其从列表中彻底删除,不如以b[m],如第 8 行所示。
重叠的边界框具有第二次机会。 IoU 较小的边界框在将来的迭代中具有更高的生存机会。 在将来的选择中,它实际上可能证明它包含一个与b[m]不同的对象。 如“算法 11.12.1”中所示,Soft NMS 是传统 NMS 的便捷替代。 无需重新训练 SSD 网络。 与经典 NMS 相比,Soft NMS 具有更高的平均精度。
“列表 11.12.1”说明了经典 NMS 和软 NMS。 除了最终的边界框和相应的分数外,还返回相应的对象。 当其余边界框的最大分数小于某个阈值(例如:0.2)时,该代码将实现 NMS 的提前终止。
“算法 11.12.1”NMS 和软 NMS
要求:边界框预测:B = {b[1], b[2], …, b[n]}
要求:边界框类别的置信度或分数:B = {b[1], b[2], …, b[n]}
要求:最小 NMS IoU 阈值:N[t]
-
D <- {};S <- {} -
当
B ≠ empty,执行 -
m <- argmax P -
M <- b[m];N <- p[m], -
D <- D ∪ M;B <- B - M;S <- S ∪ N;P <- P - N; -
对于步骤
b[i] ∈ B,执行 -
如果
soft_NMS = True -
p[i] = p[i] exp(-IOU(M, b[i])^2 / σ) -
否则如果
IOU(M, b[i]) >= N[t],那么 -
B = B - b[i];P = P - p[i] -
结束
-
结束
-
结束
-
返回
D, S
“列表 11.12.1”:boxes.py
def nms(args, classes, offsets, anchors):
"""Perform NMS (Algorithm 11.12.1).
Arguments:
args: User-defined configurations
classes (tensor): Predicted classes
offsets (tensor): Predicted offsets
Returns:
objects (tensor): class predictions per anchor
indexes (tensor): indexes of detected objects
filtered by NMS
scores (tensor): array of detected objects scores
filtered by NMS
"""
# get all non-zero (non-background) objects
objects = np.argmax(classes, axis=1)
# non-zero indexes are not background
nonbg = np.nonzero(objects)[0]
# D and S indexes in Line 1
indexes = []
while True:
# list of zero probability values
scores = np.zeros((classes.shape[0],))
# set probability values of non-background
scores[nonbg] = np.amax(classes[nonbg], axis=1)
# max probability given the list
# Lines 3 and 4
score_idx = np.argmax(scores, axis=0)
score_max = scores[score_idx]
# get all non max probability & set it as new nonbg
# Line 5
nonbg = nonbg[nonbg != score_idx]
# if max obj probability is less than threshold (def 0.8)
if score_max < args.class_threshold:
# we are done
break
# Line 5
indexes.append(score_idx)
score_anc = anchors[score_idx]
score_off = offsets[score_idx][0:4]
score_box = score_anc + score_off
score_box = np.expand_dims(score_box, axis=0)
nonbg_copy = np.copy(nonbg)
# get all overlapping predictions (Line 6)
# perform Non-Max Suppression (NMS)
for idx in nonbg_copy:
anchor = anchors[idx]
offset = offsets[idx][0:4]
box = anchor + offset
box = np.expand_dims(box, axis=0)
iou = layer_utils.iou(box, score_box)[0][0]
# if soft NMS is chosen (Line 7)
if args.soft_nms:
# adjust score: Line 8
iou = -2 * iou * iou
classes[idx] *= math.exp(iou)
# else NMS (Line 9), (iou threshold def 0.2)
elif iou >= args.iou_threshold:
# remove overlapping predictions with iou>threshold
# Line 10
nonbg = nonbg[nonbg != idx]
# Line 2, nothing else to process
if nonbg.size == 0:
break
# get the array of object scores
scores = np.zeros((classes.shape[0],))
scores[indexes] = np.amax(classes[indexes], axis=1)
return objects, indexes, scores
假设我们具有训练有素的 SSD 网络和一种抑制冗余预测的方法,则下一节将讨论对测试数据集的验证。 基本上,我们想知道我们的 SSD 是否可以对从未见过的图像执行对象检测。
13. SSD 模型验证
在对 SSD 模型进行 200 个周期的训练之后,可以验证表现。 用于评估的三个可能指标:1)IoU,2)精度和 3)召回。
第一个指标是平均 IoU(mIoU)。 给定真实情况测试数据集,计算真实情况边界框和预测边界框之间的 IoU。 在执行 NMS 之后,对所有真实情况和预测的边界框执行此操作。 所有 IoU 的平均值计算为 mIoU:
 (Equation 11.13.1)
(Equation 11.13.1)
其中n_box是地面真值边界框b[i]的数量和n_pred是预测边界框d[j]的数量。 请注意,该度量标准无法验证两个重叠的边界框是否属于同一类。 如果需要,则可以轻松修改代码。“列表 11.13.1”显示了代码实现。
第二个度量是精度,如“公式 11.3.2”所示。 它是正确预测的对象类别的数量(真阳性或 TP)除以正确预测的对象类别的数量(真阳性或 TP)与错误预测的对象类别的数量(假阳性或 FP)之和。 精度是衡量 SSD 正确识别图像中对象的表现的指标。 精度越接近 1.0 越好。
 (Equation 11.3.2)
(Equation 11.3.2)
第三个度量是召回,如“公式 11.3.3”所示。 它是正确预测的对象类别的数量(真阳性或 TP)除以正确预测的对象类别的数量(真阳性或 TP)加上错过的对象数量(假阴性或 FN)之和。 召回率是衡量 SSD 在不对图像中的对象进行错误分类方面有多出色的度量。 召回率越接近 1.0,则越好。
 (Equation 11.3.3)
(Equation 11.3.3)
如果我们对测试数据集中的所有图像取均值,则它们称为平均精度和平均召回率。 在目标检测中,使用不同 mIoU 的精度和召回曲线来衡量表现。 为了简单起见,我们仅针对特定类别阈值(默认值为 0.5)计算这些指标的值。 感兴趣的读者可以参考 Pascal VOC [7]文章,以获取有关对象检测指标的更多详细信息。
评价结果示于“表 11.13.1”。 结果可以通过运行:
- 无规范化:
python3 ssd-11.6.1.py --restore-weights=ResNet56v2-4layer-extra_anchors-drinks-200.h5 --evaluate
- 无规范化,平滑 L1:
python3 ssd-11.6.1.py --restore-weights=ResNet56v2-4layer-smooth_l1-extra_anchors-drinks-200.h5 --evaluate
- 具有规范化:
python3 ssd-11.6.1.py --restore-weights=ResNet56v2-4layer-norm-extra_anchors-drinks-200.h5 --evaluate --normalize
- 具有规范化,平滑 L1:
python3 ssd-11.6.1.py --restore-weights=ResNet56v2-4layer-norm-smooth_l1-extra_anchors-drinks-200.h5 --evaluate --normalize
- 具有规范化,平滑 L1,焦点损失:
python3 ssd-11.6.1.py --restore-weights=ResNet56v2-4layer-norm-improved_loss-extra_anchors-drinks-200.h5 --evaluate --normalize
权重在 GitHub 上可用。
在 mIoU 上,最佳表现是非归一化偏移选项,而归一化偏移设置具有最高的平均精度和召回率。 考虑到训练数据集中只有 1,000 张图像,表现并不是最新技术。 也没有应用数据扩充。
从结果来看,使用损失函数的改进会降低表现。 使用平滑 L1 或焦距损失函数或同时使用两者时,会发生这种情况。“图 11.13.1”至“图 11.13.5”显示了样本预测。 可以通过执行以下操作获得图像上的对象检测:
python3 ssd-11.6.1.py –-restore-weights=<weights_file>
--image-file=<target_image_file> --evaluate
例如,要在dataset/drinks/0010050.jpg上运行对象检测:
python3 ssd-11.6.1.py --restore-weights=ResNet56v2-4layer-extra_anchors-drinks-200.h5 --image-file=dataset/drinks/0010050.jpg --evaluate
如果模型权重文件名中包含单词norm,请附加--normalize option。
“列表 11.13.1”:ssd-11.6.1.py
def evaluate_test(self):
# test labels csv path
path = os.path.join(self.args.data_path,
self.args.test_labels)
# test dictionary
dictionary, _ = build_label_dictionary(path)
keys = np.array(list(dictionary.keys()))
# sum of precision
s_precision = 0
# sum of recall
s_recall = 0
# sum of IoUs
s_iou = 0
# evaluate per image
for key in keys:
# ground truth labels
labels = np.array(dictionary[key])
# 4 boxes coords are 1st four items of labels
gt_boxes = labels[:, 0:-1]
# last one is class
gt_class_ids = labels[:, -1]
# load image id by key
image_file = os.path.join(self.args.data_path, key)
image = skimage.img_as_float(imread(image_file))
image, classes, offsets = self.detect_objects(image)
# perform nms
_, _, class_ids, boxes = show_boxes(args,
image,
classes,
offsets,
self.feature_shapes,
show=False)
boxes = np.reshape(np.array(boxes), (-1,4))
# compute IoUs
iou = layer_utils.iou(gt_boxes, boxes)
# skip empty IoUs
if iou.size ==0:
continue
# the class of predicted box w/ max iou
maxiou_class = np.argmax(iou, axis=1)
# true positive
tp = 0
# false positiove
fp = 0
# sum of objects iou per image
s_image_iou = []
for n in range(iou.shape[0]):
# ground truth bbox has a label
if iou[n, maxiou_class[n]] > 0:
s_image_iou.append(iou[n, maxiou_class[n]])
# true positive has the same class and gt
if gt_class_ids[n] == class_ids[maxiou_class[n]]:
tp += 1
else:
fp += 1
# objects that we missed (false negative)
fn = abs(len(gt_class_ids) - tp)
s_iou += (np.sum(s_image_iou) / iou.shape[0])
s_precision += (tp/(tp + fp))
s_recall += (tp/(tp + fn))
n_test = len(keys)
print_log("mIoU: %f" % (s_iou/n_test),
self.args.verbose)
print_log("Precision: %f" % (s_precision/n_test),
self.args.verbose)
print_log("Recall: %f" % (s_recall/n_test),
self.args.verbose)
结果如下,在“表 11.13.1”中:
| 未归一化的偏移 | 未归一化的偏移,平滑 L1 | 归一化的偏移 | 归一化偏移,平滑 L1 | 归一化偏移,平滑 L1,焦点损失 | |
|---|---|---|---|---|---|
| IoU | 0.64 | 0.61 | 0.53 | 0.50 | 0.51 |
| 平均精度 | 0.87 | 0.86 | 0.90 | 0.85 | 0.85 |
| 平均召回率 | 0.87 | 0.85 | 0.87 | 0.83 | 0.83 |
表 11.13.1 测试数据集上 SSD 的表现基准。

图 11.13.1 来自测试数据集的图像上的示例预测示例(未归一化的偏移量)。

图 11.13.2 来自测试数据集的图像上的示例预测示例(未归一化的偏移量,平滑 L1)。

图 11.13.3 来自测试数据集的图像预测示例(标准化偏移)。

图 11.13.4 对来自测试数据集的图像进行的预测示例(标准化偏移,平滑 L1)。

图 11.13.5 对来自测试数据集的图像进行的预测示例(归一化偏移,平滑 L1,聚焦损失)。
本节中的结果验证了我们的 SSD 模型。 一个重要的经验教训是,只要我们理解了问题,无论问题多么复杂,我们都可以逐步构建一个可行的解决方案。 SSD 是迄今为止我们在本书中介绍过的最复杂的模型。 它需要许多工具,模块以及大量数据准备和管理才能工作。
14. 总结
在本章中,讨论了多尺度单发对象检测的概念。 使用以接收场斑块的质心为中心的锚框,可以计算地面真值边界框偏移量。 代替原始像素误差,归一化像素误差会鼓励更适合优化的有限范围。
每个锚框都分配有地面实况类别标签。 如果锚点框不与对象重叠,则为其分配背景类,并且其偏移量不包括在偏移量损失计算中。 已经提出了焦点损失以改善类别损失函数。 可以使用平滑的 L1 损失函数代替默认的 L1 偏置损失函数。
对测试数据集的评估表明,使用默认损失函数的归一化偏移可实现平均精度和召回率方面的最佳表现,而当消除偏移归一化时,mIoU 会得到改善。 通过增加训练图像的数量和变化可以提高性能。
在“第 12 章”中,“语义分割”建立在本章中开发的概念的基础上。 特别是,我们重用 ResNet 骨干网络来构建分段网络和 IoU 指标进行验证。
15. 参考
Krizhevsky Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012.Liu Wei, et al. "SSD: Single Shot MultiBox Detector." European conference on computer vision. Springer, Cham, 2016.Girshick Ross. "Fast R-CNN." Proceedings of the IEEE international conference on computer vision. 2015.Lin Tsung-Yi, et al. "Focal loss for Dense Object Detection. "Proceedings of the IEEE international conference on computer vision. 2017.Dutta, et al. VGG Image Annotator http://www.robots.ox.ac.uk/~vgg/software/via/Bodla Navaneeth, et al. "Soft-NMS--Improving Object Detection With One Line of Code." Proceedings of the IEEE international conference on computer vision. 2017.Everingham Mark, et al. "The Pascal Visual Object Classes (VOC) challenge." International journal of computer vision 88.2 (2010): 303-338."Huber Loss." https://en.wikipedia.org/wiki/Huber_loss
十二、语义分割
在“第 11 章”,“对象检测”中,我们讨论了对象检测作为一种重要的计算机视觉算法,具有多种实际应用。 在本章中,我们将讨论另一种称为语义分割的相关算法。 如果对象检测的目的是对图像中的每个对象同时执行定位和标识,则在语义分割中,目的是根据每个像素的对象类别对它们进行分类。
进一步扩展类比,在对象检测中,我们使用边界框显示结果。 在语义分割中,同一对象的所有像素都属于同一类别。 在视觉上,同一对象的所有像素将具有相同的颜色。 例如,属于*汽水**类别的所有像素均为蓝色。 非苏打罐对象的像素将具有不同的颜色。
类似于对象检测,语义分割有许多实际应用。 在医学成像中,它可用于分离和测量正常细胞与异常细胞的区域。 在卫星成像中,语义分段可用于度量森林覆盖率或灾难期间的洪水程度。 通常,语义分割可用于识别属于同一类对象的像素。 识别每个对象的各个实例并不重要。
好奇的读者可能会想知道,一般而言,不同的分割算法与特别是语义分割算法之间有什么区别? 在以下部分中,我们将对不同的分割算法进行限定。
总而言之,本章的目的是为了提出:
- 不同类型的分割算法
- 全卷积网络(FCN)作为语义分割算法的实现
tf.keras中 FCN 的实现和评估
我们将从讨论不同的分割算法开始。
1. 分割
分割算法将图像划分为像素或区域集。 分区的目的是为了更好地理解图像表示的内容。 像素组可以表示图像中特定应用感兴趣的对象。 我们划分的方式区分了不同的分割算法。
在某些应用中,我们对给定图像中的特定可数对象感兴趣。 例如,在自主导航中,我们对车辆,交通标志,行人和道路上的其他物体的实例感兴趣。 这些可计数对象统称为,称为事物。 所有其他像素都集中在一起作为背景。 这种类型的细分称为实例细分。
在其他应用中,我们对可数对象不感兴趣,而对无定形的不可数区域感兴趣,例如天空,森林,植被,道路,草地,建筑物和水体。 这些对象统称为东西。 这种类型的分段称为语义分段。
大致上,事物和事物共同构成了整个图像。 如果算法可以识别事物像素和填充像素,则其称为全光分割,如 Kirilov 等人所定义 [1]。
但是,事物与事物之间的区别并不严格。 应用可能将可数对象统称为东西。 例如,在百货商店中,不可能识别机架上的服装实例。 它们可以作为布料一起集中在一起。
“图 12.1.1”显示了不同类型的细分之间的区别。 输入的图像在桌子的顶部显示了两个汽水罐和两个果汁罐。 背景杂乱无章。 假设我们只对汽水罐和果汁罐感兴趣,在实例细分中,我们为每个对象实例分配唯一的颜色以分别区分四个对象。 对于语义分割,我们假设将所有的汽水罐都塞在一起,将果汁罐作为另一罐塞在一起,将背景作为最后的罐塞在一起。 基本上,我们为每种物料分配了唯一的颜色。 最后,在全景分割中,我们假设只有背景才是背景,而我们只对苏打水和果汁罐感兴趣。
对于这本书,我们仅探讨语义分割。 按照“图 12.1.1”中的示例,我们将为“第 11 章”,“对象检测”中使用的对象分配唯一的填充类别:1)水瓶,2)汽水罐和 3)果汁罐。 第四个也是最后一个类别是背景。

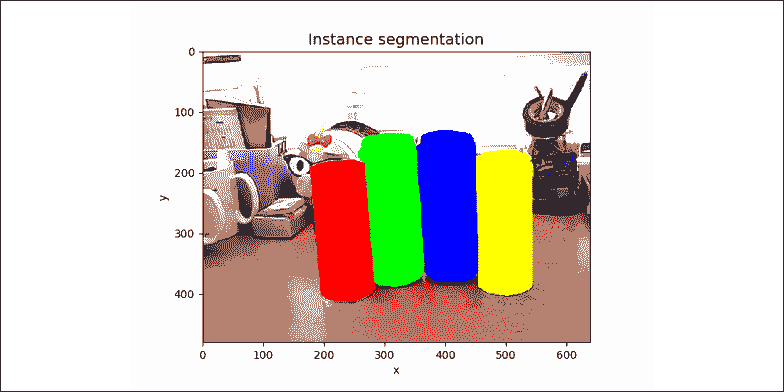
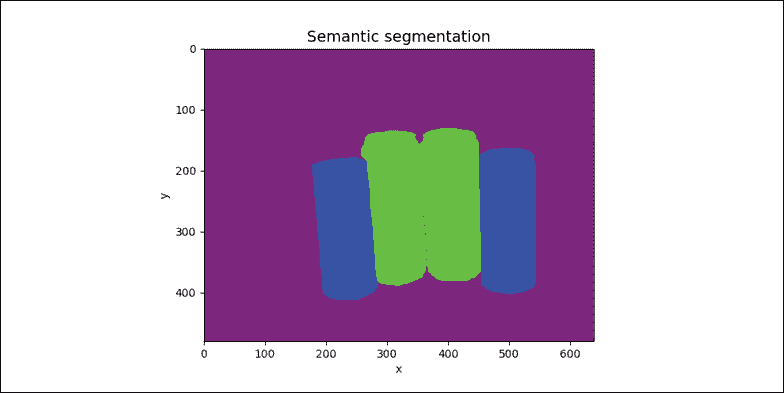
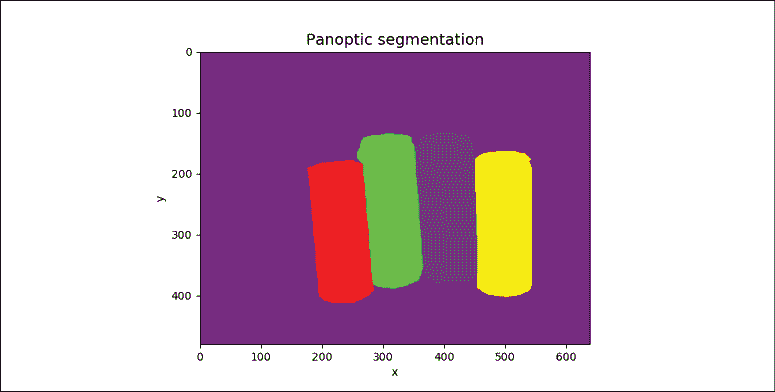
图 12.1.1:显示不同分割算法的四幅图像。 彩色效果最佳。 原始图像可以在这个页面中找到。
2. 语义分割网络
从上一节中,我们了解到语义分割网络是一个像素级分类器。 网络框图显示在“图 12.2.1”中。 但是,与简单分类器不同(例如,“第 1 章”,“Keras 深度神经网络”和“第 2 章”,“MNIST 分类器简介”) 其中只有一个分类器生成one-hot vector作为输出,在语义分段中,我们有并行运行的并行分类器。 每个人都在生成自己的单热点向量预测。 分类器的数量等于输入图像中的像素数量或图像宽度与高度的乘积。 每个one-hot vector预测的维数等于感兴趣的填充对象类别的数量。
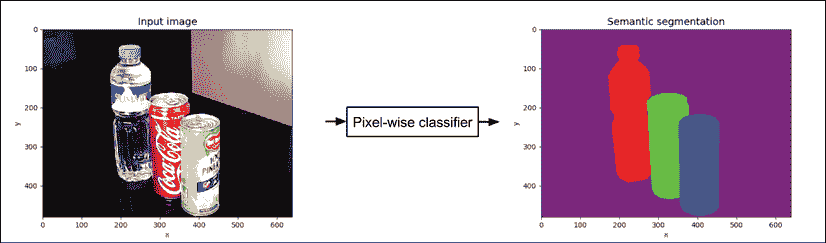
图 12.2.1:可以将语义分割网络视为按像素分类器。 彩色效果最佳。 原始图像可以在这个页面中找到
例如,假设我们对以下四个类别感兴趣:0)背景,1)水瓶,2)汽水罐和 3)果汁罐,我们可以在“图 12.2.2”中看到,每个对象类别有四个像素。
相应地,使用 4 维one-hot vector对每个像素进行分类。 我们使用阴影表示像素的类别。 利用这一知识,我们可以想象一个语义分割网络预测image_width x image_height 4 维一热向量作为输出,每个像素一个 4 维一热向量:
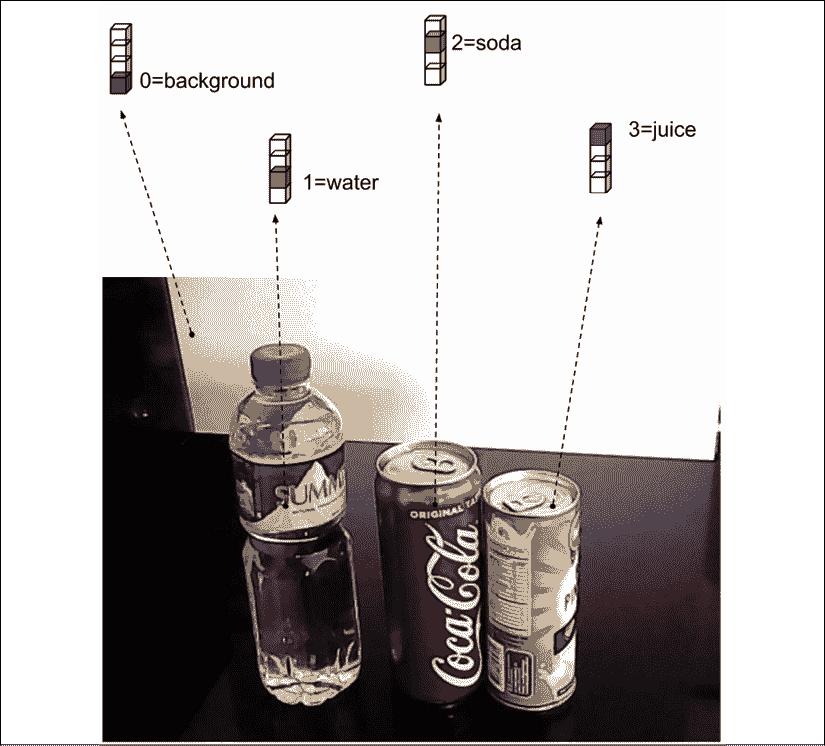
图 12.2.2:四个不同的样本像素。 使用 4 维一热向量,每个像素根据其类别进行分类。 彩色效果最佳。 原始图像可以在这个页面中找到
了解了语义分割的概念后,我们现在可以介绍神经网络像素级分类器。 Long 等人的《全卷积网络(FCN)》启发了我们的语义分段网络架构 [2]。FCN 的关键思想是在生成最终预测时使用多个比例的特征映射。
我们的语义分段网络显示在“图 12.2.3”中。 它的输入是 RGB 图像(例如640 x 480 x 3),并且输出具有类似尺寸的张量,但最后一个尺寸是填充类别的数量(例如,对于 4 种填充类别而言是640 x 480 x 4)。 出于可视化目的,我们通过为每种类别分配颜色来将输出映射到 RGB:
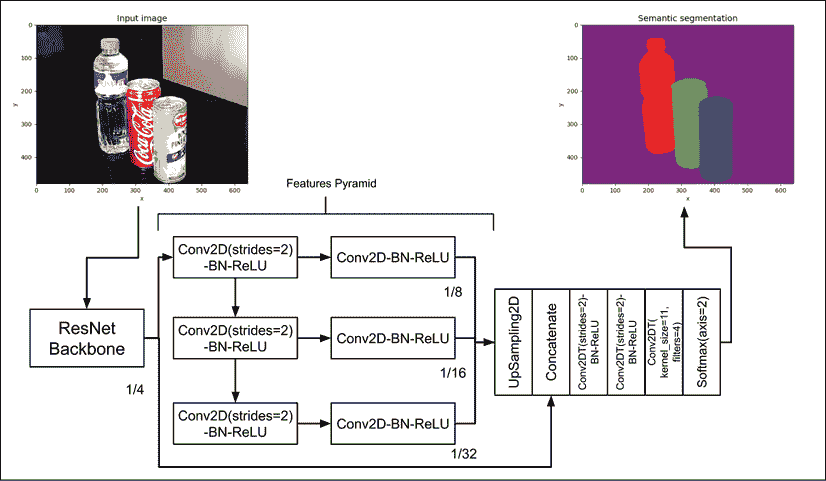
图 12.2.3:语义分割的网络架构。 除非另有说明,否则核大小为 3。 除非另有说明,否则跨步为 1。 彩色效果最佳。 原始图像可以在这个页面中找到
类似于“第 11 章”,“对象检测”中讨论的 SSD,我们采用骨干网作为特征提取器。 我们在 SSD 中使用类似的 ResNetv2 网络。 ResNet 主干网执行两次最大池化,以到达第一组特征映射,其尺寸为输入图像的 1/4。 通过使用连续的Conv2D(strides=2)-BN-ReLU层生成其他特征映射集,从而生成具有输入图像尺寸(1/8, 1/16, 1/32)的特征映射。
Zhao 等人的《金字塔场景解析网络(PSPNet)》进行了改进,进一步增强了我们的语义分割网络架构 [3]。 在 PSPNet 中,每个特征映射由另一个卷积层进一步处理。 此外,还使用了第一组特征映射。
FCN 和 PSPNet 都对特征金字塔进行了上采样,以达到与第一组特征映射相同的大小。 之后,使用Concatenate层将所有上采样特征融合在一起。 然后级联层通过步长等于 2 的转置卷积处理两次,以恢复原始图像的宽度和高度。 最后,使用核大小为 1 且过滤器等于 4(换句话说,类别数)和Softmax层的转置卷积生成按像素分类预测。
在下一节中,我们将讨论细分网络的tf.keras实现。 我们可以重用“第 11 章”,“对象检测”中的 SSD 中的某些网络块,以加快实现速度。
3. Keras 中的语义分割网络
如图“图 12.2.3”所示,我们已经有了语义细分网络的一些关键构建块。 我们可以重用“第 2 章”,“深度神经网络”中介绍的 ResNet 模型。 我们只需要构建特征的金字塔以及上采样和预测层。
借用我们在“第 2 章”,“深度神经网络”中开发的 ResNet 模型,并在“第 11 章”,“对象检测”中重用了该模型, 我们提取具有四个级别的特征金字塔。“列表 12.3.1”显示了从 ResNet 提取特征的金字塔。 conv_layer()只是创建Conv2D(strides=2)-BN-ReLU层的辅助函数。
“列表 12.3.1”:resnet.py:
特征的金字塔函数:
def features_pyramid(x, n_layers):
"""Generate features pyramid from the output of the
last layer of a backbone network (e.g. ResNetv1 or v2)
Arguments:
x (tensor): Output feature maps of a backbone network
n_layers (int): Number of additional pyramid layers
Return:
outputs (list): Features pyramid
"""
outputs = [x]
conv = AveragePooling2D(pool_size=2, name='pool1')(x)
outputs.append(conv)
prev_conv = conv
n_filters = 512
# additional feature map layers
for i in range(n_layers - 1):
postfix = "_layer" + str(i+2)
conv = conv_layer(prev_conv,
n_filters,
kernel_size=3,
strides=2,
use_maxpool=False,
postfix=postfix)
outputs.append(conv)
prev_conv = conv
return outputs
“列表 12.3.1”只是特征金字塔的一半。 剩下的一半是每组特征之后的卷积。 另一半显示在“列表 12.3.2”中,以及金字塔各层的上采样。 例如,图像尺寸为 1/8 的特征会被上采样 2 倍,以使其尺寸与图像尺寸为 1/4 的第一组特征相匹配。 在同一清单中,我们还建立了完整的分割模型,从骨干网络到特征金字塔,再连接上采样特征金字塔,最后进一步进行特征提取,上采样和预测。 我们在输出层使用n维(例如 4 维)Softmax层执行逐像素分类。
“列表 12.3.2”:model.py:
构建语义分割网络:
def build_fcn(input_shape,
backbone,
n_classes=4):
"""Helper function to build an FCN model.
Arguments:
backbone (Model): A backbone network
such as ResNetv2 or v1
n_classes (int): Number of object classes
including background.
"""
inputs = Input(shape=input_shape)
features = backbone(inputs)
main_feature = features[0]
features = features[1:]
out_features = [main_feature]
feature_size = 8
size = 2
# other half of the features pyramid
# including upsampling to restore the
# feature maps to the dimensions
# equal to 1/4 the image size
for feature in features:
postfix = "fcn_" + str(feature_size)
feature = conv_layer(feature,
filters=256,
use_maxpool=False,
postfix=postfix)
postfix = postfix + "_up2d"
feature = UpSampling2D(size=size,
interpolation='bilinear',
name=postfix)(feature)
size = size * 2
feature_size = feature_size * 2
out_features.append(feature)
# concatenate all upsampled features
x = Concatenate()(out_features)
# perform 2 additional feature extraction
# and upsampling
x = tconv_layer(x, 256, postfix="up_x2")
x = tconv_layer(x, 256, postfix="up_x4")
# generate the pixel-wise classifier
x = Conv2DTranspose(filters=n_classes,
kernel_size=1,
strides=1,
padding='same',
kernel_initializer='he_normal',
name="pre_activation")(x)
x = Softmax(name="segmentation")(x)
model = Model(inputs, x, name="fcn")
return model
给定分割网络模型,我们使用学习速度为1e-3的 Adam 优化器和分类交叉熵损失函数来训练网络。“列表 12.3.3”显示了模型构建和训练函数调用。 在 40 个周期之后,学习率每 20 个周期减半。 我们使用AccuracyCallback监视网络表现,类似于“第 11 章”,“对象检测”中的 SSD 网络。 回调使用类似于对象检测平均 IoU 的平均 IoU(mIoU)指标计算表现。 表现最佳的平均值 IoU 的权重保存在文件中。 通过调用fit_generator()将网络训练 100 个周期。
“列表 12.3.3”:fcn-12.3.1.py:
语义分割网络的初始化和训练:
def build_model(self):
"""Build a backbone network and use it to
create a semantic segmentation
network based on FCN.
"""
# input shape is (480, 640, 3) by default
self.input_shape = (self.args.height,
self.args.width,
self.args.channels)
# build the backbone network (eg ResNet50)
# the backbone is used for 1st set of features
# of the features pyramid
self.backbone = self.args.backbone(self.input_shape,
n_layers=self.args.layers)
# using the backbone, build fcn network
# output layer is a pixel-wise classifier
self.n_classes = self.train_generator.n_classes
self.fcn = build_fcn(self.input_shape,
self.backbone,
self.n_classes)
def train(self):
"""Train an FCN"""
optimizer = Adam(lr=1e-3)
loss = 'categorical_crossentropy'
self.fcn.compile(optimizer=optimizer, loss=loss)
log = "# of classes %d" % self.n_classes
print_log(log, self.args.verbose)
log = "Batch size: %d" % self.args.batch_size
print_log(log, self.args.verbose)
# prepare callbacks for saving model weights
# and learning rate scheduler
# model weights are saved when test iou is highest
# learning rate decreases by 50% every 20 epochs
# after 40th epoch
accuracy = AccuracyCallback(self)
scheduler = LearningRateScheduler(lr_scheduler)
callbacks = [accuracy, scheduler]
# train the fcn network
self.fcn.fit_generator(generator=self.train_generator,
use_multiprocessing=True,
callbacks=callbacks,
epochs=self.args.epochs,
workers=self.args.workers)
多线程数据生成器类DataGenerator与“第 11 章”,“对象检测”中使用的类类似。 如“列表 12.3.4”所示,对__data_generation(self, keys)签名方法进行了修改,以生成一对图像张量及其相应的按像素方向的真实情况标签或分割蒙版 。 在下一节中,我们将讨论如何生成基本事实标签。
“列表 12.3.4”:data_generator.py:
DataGenerator类用于语义分割的数据生成方法:
def __data_generation(self, keys):
"""Generate train data: images and
segmentation ground truth labels
Arguments:
keys (array): Randomly sampled keys
(key is image filename)
Returns:
x (tensor): Batch of images
y (tensor): Batch of pixel-wise categories
"""
# a batch of images
x = []
# and their corresponding segmentation masks
y = []
for i, key in enumerate(keys):
# images are assumed to be stored
# in self.args.data_path
# key is the image filename
image_path = os.path.join(self.args.data_path, key)
image = skimage.img_as_float(imread(image_path))
# append image to the list
x.append(image)
# and its corresponding label (segmentation mask)
labels = self.dictionary[key]
y.append(labels)
return np.array(x), np.array(y)
语义分割网络现已完成。 使用tf.keras,我们讨论了其架构实现,初始化和训练。
在运行训练程序之前,我们需要训练和测试带有地面真实性标签的数据集。 在的下一部分中,我们将讨论将在本章中使用的语义分割数据集。
4. 示例数据集
我们可以使用在“第 11 章”,“对象检测”中使用的数据集。 回想一下,我们使用了一个小型数据集,其中包含使用便宜的 USB 相机(A4TECH PK-635G)收集的 1,000 640 x 480 RGB 训练图像和 50 640 x 480 RGB 测试图像。 但是,我们没有使用边界框和类别进行标记,而是使用多边形形状跟踪了每个对象类别的边缘。 我们使用相同的数据集标注器 VGG 图像标注器(VIA)[4]手动跟踪边缘并分配以下标签:1)水瓶,2)汽水罐和 3)果汁罐。
“图 12.4.1”显示了标记过程的示例 UI。

图 12.4.1:使用 VGG 图像标注器(VIA)进行语义分割的数据集标记过程
威盛标签软件将标签保存在 JSON 文件中。 对于训练和测试数据集,这些是:
segmentation_train.json
segmentation_test.json
无法原样使用存储在 JSON 文件中的多边形区域。 每个区域都必须转换成分割蒙版,即张量,其尺寸为img_w x img_h x px – wise_category。 在此数据集中,分割蒙版的尺寸为640 x 480 x 4。类别 0 为背景,其余为 1)对于水瓶,2)对于苏打罐,以及 3)表示果汁罐。 在utils文件夹中,我们创建了一个generate_gt_segmentation.py工具,用于将 JSON 文件转换为分段掩码。 为了方便起见,用于训练和测试的地面真实数据存储在压缩数据集中,该数据集是从上一章下载的:
segmentation_train.npy
segmentation_test.npy
每个文件都包含image filename: segmentation mask格式的真实情况数据字典,该字典在训练和验证期间加载。“图 12.4.2”显示了使用彩色像素可视化的“图 12.4.1”中图像的分割蒙版的示例。
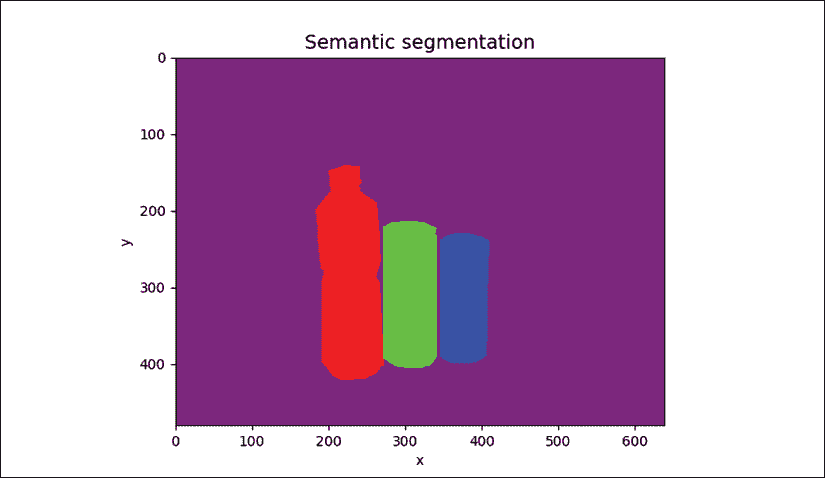
图 12.4.2:可视化图 12.4.1 中所做标注的分段蒙版
现在,我们准备训练和验证语义分割网络。 在下一节中,我们将显示在本节中标注的数据集上语义分割的结果。
5. 语义分割验证
要训练语义分段网络,请运行以下命令:
python3 fcn-12.3.1.py --train
在每个周期,也会执行验证以确定表现最佳的参数。 对于语义分割,可以使用两个度量。 首先是平均 IOU。 这类似于上一章中目标检测中的平均 IoU。 区别在于针对每个填充类别在真实情况分割掩码和预测的分割掩码之间计算 IoU。 这包括背景。 平均 IoU 只是测试数据集所有 IoU 的平均值。
“图 12.5.1”显示了在每个周期使用 mIoU 的语义分割网络的表现。 最大 mIoU 为 0.91。 这个比较高。 但是,我们的数据集只有四个对象类别:
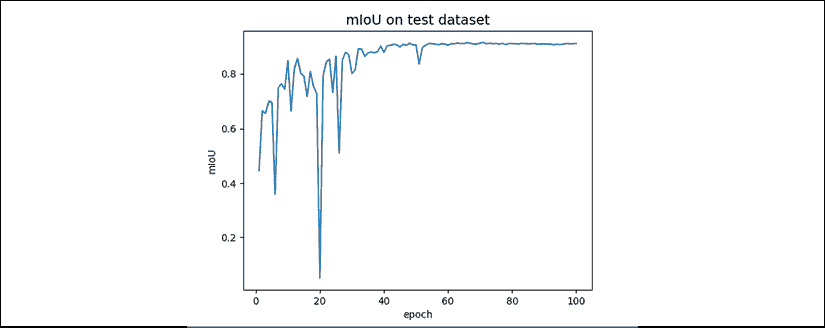
图 12.5.1:使用 mIoU 进行测试数据集训练期间的语义分割表现
第二个指标是平均像素精度。 这类似于在分类器预测上计算准确率的方式。 不同之处在于,分割网络具有的预测数量等于图像中的像素数量,而不是具有一个预测。 对于每个测试输入图像,计算平均像素精度。 然后,计算所有测试图像的平均值。
“图 12.5.2”显示了在每个周期使用平均像素精度的语义分割网络的表现。 最大平均像素精度为 97.9%。 我们可以看到平均像素精度与 mIoU 之间的相关性:
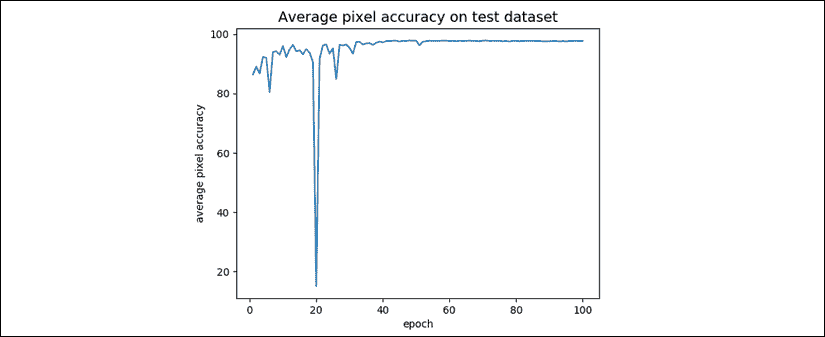
图 12.5.2:使用测试数据集的平均像素精度在训练期间的语义分割表现
“图 12.5.3”显示了输入图像,地面实况语义分割掩码和预测的语义分割掩码的样本:



图 12.5.3:样本输入,基本事实和语义细分的预测。 我们将黑色分配为背景类,而不是紫色,如先前所用
总体而言,我们基于 FCN 并经过 PSPNet 的思想改进的语义分割网络的表现相对较好。 我们的语义分割网络绝不是最优化的。 可以减少特征金字塔中的过滤器数量,以最大程度地减少参数的数量,该参数约为 1110 万。 探索增加特征金字塔中的级别数也很有趣。 读者可以通过执行以下命令来运行验证:
python3 fcn-12.3.1.py --evaluate
--restore-weights=ResNet56v2-3layer-drinks-best-iou.h5
在下一章中,我们将介绍无监督的学习算法。 考虑到监督学习中所需的昂贵且费时的标签,强烈地开发了无监督学习技术。 例如,在本章的语义分割数据集中,一个人花了大约 4 天的手工标签。 如果深度学习始终需要人工标记,那么它就不会前进。
6. 总结
在本章中,讨论了分割的概念。 我们了解到细分有不同类别。 每个都有自己的目标应用。 本章重点介绍语义分段的网络设计,实现和验证。
我们的语义分割网络受到 FCN 的启发,FCN 已成为许多现代,最先进的分割算法(例如 Mask-R-CNN [5])的基础。 PSPNet 的构想进一步增强了我们的网络,该构想在 ImageNet 2016 解析挑战赛中获得第一名。
使用 VIA 标记工具,使用与“第 11 章”,“对象检测”中使用的相同图像集生成用于语义分割的新数据集标签。 分割蒙版标记属于同一对象类的所有像素。
我们使用平均 IoU 和平均像素准确率指标对语义分割网络进行了训练和验证。 测试数据集上的表现表明,它可以有效地对测试图像中的像素进行分类。
如本章最后一部分所述,由于所涉及的成本和时间,深度学习领域正在意识到监督学习的局限性。 下一章重点介绍无监督学习。 它利用了通信领域信息理论中使用的互信息概念。
7. 参考
Kirillov, Alexander, et al.: Panoptic Segmentation. Proceedings of the IEEE conference on computer vision and pattern recognition. 2019.Long, Jonathan, Evan Shelhamer, and Trevor Darrell: Fully Convolutional Networks for Semantic Segmentation. Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.Zhao, Hengshuang, et al.: Pyramid Scene Parsing Network. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.Dutta, et al.: VGG Image Annotator http://www.robots.ox.ac.uk/~vgg/software/via/He Kaiming, et al.: Mask R-CNN. Proceedings of the IEEE international conference on computer vision. 2017.
十三、使用互信息的无监督学习
许多机器学习任务(例如分类,检测和分段)都依赖于标记的数据。 网络在这些任务上的表现直接受到标记质量和数据量的影响。 问题在于产生足够数量的高质量标注数据既昂贵又费时。
为了继续机器学习的发展,新算法应减少对人类标签的依赖。 理想情况下,网络应该从无标签数据中学习,由于互联网的发展以及诸如智能手机和物联网(IoT)。 从未标记的数据中学习是无监督学习的领域。 在某些情况下,无监督学习也称为自我监督学习,以强调使用纯净的未标记数据进行训练和缺乏人工监督。 在本文中,我们将使用术语无监督学习。
在机器学习中,有一些方法可以从未标记的数据中学习。 可以使用深度神经网络和无监督学习中的新思想来改善这些方法的表现。 当处理高度非结构化的数据(例如文本,图像,音频和视频)时,尤其如此。
在无监督学习中成功的方法之一是最大化给定神经网络中两个随机变量之间的互信息。 在信息论领域,互信息(MI)是两个随机变量之间依存性的量度。
MI 最近已成功地从未标记的数据中提取了有用的信息,可以帮助学习下游任务。 例如,MI 能够对潜在代码向量进行聚类,从而使分类任务成为简单的线性分离问题。
总之,本章的目的是介绍:
- 互信息的概念
- 使用神经网络估计 MI
- 下游任务的离散和连续随机变量上的 MI 最大化
- Keras 中 MI 估计网络的实现
我们将从介绍互信息的概念开始。
1. 互信息
互信息是对两个随机变量X和Y之间依赖性的度量。 有时,MI 也定义为通过观察Y得出的有关X的信息量。 MI 也被称为信息获取或观察Y时X不确定性的降低。
与相关性相反,MI 可以测量X和Y之间的非线性统计依赖性。 在深度学习中,MI 是一种合适的方法,因为大多数现实世界中的数据都是非结构化的,并且输入和输出之间的依赖关系通常是非线性的。 在深度学习中,最终目标是对输入数据和预先训练的模型执行特定任务,例如分类,翻译,回归或检测。 这些任务也称为下游任务。
由于 MI 可以发现输入,中间特征,表示和输出中的相关性的重要方面,这些方面本身就是随机变量,因此共享信息通常可以提高下游任务中模型的表现。
在数学上,两个随机变量X和Y之间的 MI 可以定义为:
 (Equation 13.1.1)
(Equation 13.1.1)
哪里:
P(X,Y)是 X 和 Y 在样本空间XxY上的联合分布 。P(X)P(Y)是边际分布P(X)和P(Y)分别位于样本空间X和Y上。
换句话说,MI 是联合分布与边际分布乘积之间的 Kullback-Leibler(KL)散度。 回顾“第 5 章”,“改进的 GAN” ,KL 是两个分布之间距离的度量。 在 MI 的上下文中,KL 距离越大,两个随机变量X和Y之间的 MI 越高。 通过扩展,MI 越高,X对Y的依赖性越高。
由于 MI 等于边际分布的联合与乘积之间的 KL 散度,因此它暗示它大于或等于零:I(X; Y) > 0。 当X和Y是独立随机变量时,MI 完全等于零。 当X和Y是独立的时,观察一个随机变量(例如Y)不会提供关于另一个随机变量的信息(例如X)。 因此,MI 是X和Y独立程度的度量。
如果X和Y是离散随机变量,则通过扩展 KL 散度,MI 可以计算为:
 (Equation 13.1.2)
(Equation 13.1.2)
哪里:
P(X,Y)是联合概率质量函数(PMF)。P(X)和P(Y)是边际 PMF。
如果联合和边际分布已知,则 MI 可以进行精确计算。
如果X和Y是连续随机变量,则通过扩展 KL 散度,MI 可以表示为:
 (Equation 13.1.3)
(Equation 13.1.3)
哪里:
p(x,y)是联合概率密度函数(PDF)。p(x)和p(y)是边缘 PDF。
连续随机变量的 MI 通常很难处理,并且可以通过变分方法进行估计。 在本章中,我们将讨论估计两个连续随机变量之间的 MI 的技术。
在讨论用于计算互信息的技术之前,让我们首先解释一下 MI 与熵之间的关系。 熵在“第 6 章”,“纠缠表示 GAN”中非正式引入,并在 InfoGAN 中得到了应用。
2. 互信息和熵
MI 也可以用熵来解释。 回想一下“第 6 章”,“纠缠表示 GAN” ,熵H(X)是对预期信息量的度量。 随机变量X的:
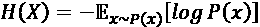 (Equation 13.2.1)
(Equation 13.2.1)
“公式 13.2.1”表示熵还是不确定性的量度。 不确定事件的发生给我们带来了更多的惊喜或信息。 例如,有关员工意外晋升的新闻具有大量信息或熵。
使用“公式 13.2.1”,MI 可以表示为:
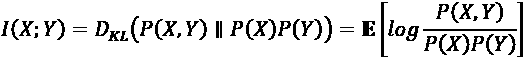


 (Equation 13.2.2)
(Equation 13.2.2)
“公式 13.2.2”表示 MI 随着边际熵增加而增加,但随联合熵而减少。 就熵而言,MI 的一个更常见的表达式如下:


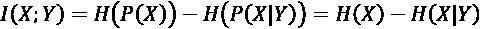 (Equation 13.2.3)
(Equation 13.2.3)
“公式 13.2.3”告诉我们,MI 随随机变量的熵增加而减小,而随另一个随机变量的条件熵而减小。 或者,如果我们知道Y,则 MI 是的信息减少量或X的不确定性。
等效地,

 (Equation 13.2.4)
(Equation 13.2.4)
“公式 13.2.4”表示 MI 是对称的:
 (Equation 13.2.5)
(Equation 13.2.5)
MI 也可以用X和Y的条件熵表示:
 (Equation 13.2.6)
(Equation 13.2.6)
使用贝叶斯定理:



 (Equation 13.2.7)
(Equation 13.2.7)
“图 13.2.1”总结了到目前为止我们讨论的 MI 与条件熵和边际熵之间的所有关系:
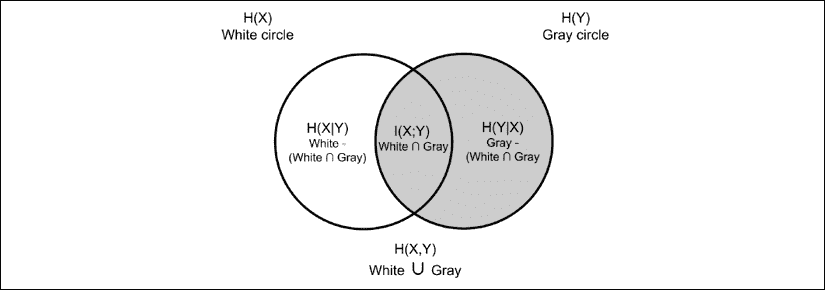
图 13.2.1 维恩图显示了 MI 与条件熵和边际熵之间的关系
MI 的另一种有趣解释是根据“公式 13.2.3”,可以将其重写为:
 (Equation 13.2.8)
(Equation 13.2.8)
由于H(X | Y)是观察到Y时的X的不确定性,因此“公式 13.2.8”告诉我们, 如果可以最大化 MI,则可以确定X给定Y。 在“图 13.2.1”中,新月形H(X | Y)的面积随着代表 MI 的圆之间的交点增加而减小。
再举一个的具体例子,假设X是一个随机变量,表示观察到在给定随机字节中的 0 到 255 之间的数字。 假设分布均匀,则转换为P(X) = 1/256的概率。 以 2 为底的X的熵为:

假设随机变量Y代表随机字节的 4 个最高有效位。 如果我们观察到 4 个最高有效位全为零,则数字 0 到 15 包含P(X) = 1/16,其余数字具有P(X) = 0。条件熵在基数 2 中是:

这为我们提供了I(X; Y) = 8 - 4 = 4的 MI。 注意,随机变量X的不确定性或预期信息量在知道Y后降低。X和Y共享的互信息为 4,这也等于两个随机变量共享的位数。“图 13.2.2”说明了两种情况,其中所有位都是随机的,而四个最高有效位都为 0。
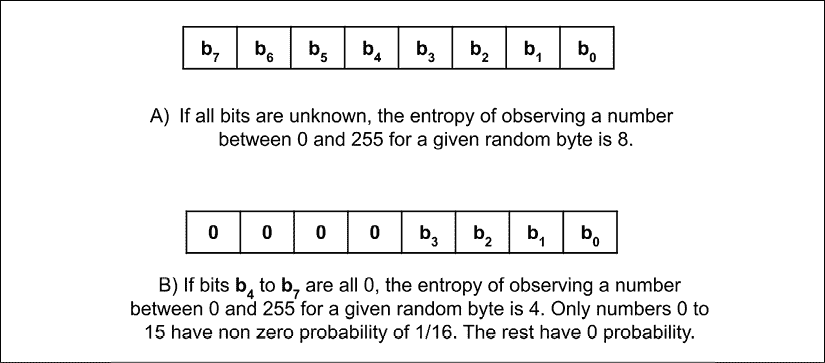
图 13.2.2 当所有位未知时与某些位已知时的熵
鉴于我们已经对 MI 和熵有了很好的了解,我们现在可以将此概念用作无监督学习的一种方法。
3. 通过最大化离散随机变量的互信息来进行无监督学习
深度学习中的经典问题是监督分类。 在“第 1 章”,“Keras 简介”和“第 2 章”,“深度神经网络”中,我们了解到,在监督分类下,我们需要标记输入图像。 我们对 MNIST 和 CIFAR10 数据集都进行了分类。 对于 MNIST,三层 CNN 和密集层可实现高达 99.3% 的精度。 对于使用 ResNet 或 DenseNet 的 CIFAR10,我们可以实现大约 93% 至 94% 的精度。 MNIST 和 CIFAR10 都被标记为数据集。
与监督学习不同,本章的目标是执行无监督学习。 我们的重点是没有标签的分类。 这个想法是,如果我们学习如何对所有训练数据的潜在代码向量进行聚类,那么线性分离算法可以对每个测试输入数据潜在向量进行分类。
为了学习没有标签的潜在代码向量的聚类,我们的训练目标是在输入图像X和其潜在代码Y之间最大化 MI。X和Y都是随机变量。 这个想法是外观相似的图像将具有聚集到相同区域的潜在向量。 线性分配问题可以很容易地将彼此远离的区域分开。 因此,可以以无监督的方式完成分类问题。 数学上,目标是最大化:
 (Equation 13.2.3)
(Equation 13.2.3)
直观地,一旦我们观察到Y,我们对X充满信心。 “公式 13.2.3”的问题在于,我们无法很好地估计要测量的密度P(X | Y) H(X | Y)。
Ji 等人的不变信息聚类(IIC)[1] 建议从联合和边际分布直接测量I(X; Y)。 目的是使用“公式 13.1.2”测量引用同一输入的两个潜在代码随机变量之间的 MI。 假设输入X编码为Z:

将相同的输入X转换为X_bar = G(X),以便X仍可清晰地归类为与X相同的类别。 在图像处理中,G可以是常见的操作,例如小旋转,随机裁剪和剪切。 有时,只要结果图像的含义相同,就可以接受诸如对比度和亮度调整,边缘检测,少量噪声添加以及归一化之类的操作。 例如,如果X是狗的图像,则在G之后,X_bar显然仍是狗。
使用相同编码器网络的潜在代码向量为:

因此,我们可以用两个随机变量Z和Z_bar将“公式 13.1.2”重写为:
 (Equation 13.3.1)
(Equation 13.3.1)
其中P(Z)和P(Z_bar)可以解释为Z和Z_bar的边际分布。 对于离散随机变量,Z和Z_bar都是P(Z)和P(Z_bar)都是分类分布。 我们可以想象,编码器输出是 softmax ,其维数等于训练和测试数据分布中的类数N。 例如,对于 MNIST,编码器输出是与训练和测试数据集中的 10 位数字相对应的 10 维一热向量。
为了确定“公式 13.3.1”中的每个项,我们首先估计P(Z, Z_bar)。 IIC 假设Z和Z_bar是独立的,因此联合分布可以估计为:
 (Equation 13.3.2)
(Equation 13.3.2)
这将创建一个N x N矩阵P(Z, Z_bar),其中每个元素Z[ij]对应于同时观察两个随机变量(Z[i], Z_bar[j])的概率。 如果对大批量进行此估计,则大样本均值将估计联合概率。
由于我们将使用 MI 来估计密度函数,因此 IIC 将采样限制为(Z[i], Z_bar[i])。 本质上,对于每个样本x[i],我们计算其潜在代码P(Z[i]) = E(X[i])。 然后,我们将x[i]转换,并计算其潜在代码P(Z_bar[i]) = E(X_bar[i])。 联合分布计算如下:
 (Equation 13.3.3)
(Equation 13.3.3)
其中M是批量大小。 由于我们对x[i]和x_bar[i]使用相同的编码器E,因此联合分布应该对称。 我们通过执行以下命令来增强对称性:
 (Equation 13.3.4)
(Equation 13.3.4)
给定P(Z, Z_bar),边际分布可以计算为:
 (Equation 13.3.5)
(Equation 13.3.5)
我们按行求和矩阵的所有条目。 类似地:
 (Equation 13.3.6)
(Equation 13.3.6)
我们按矩阵汇总矩阵的所有条目。
给定“公式 13.3.1”中的所有项,我们可以训练神经网络编码器E,该编码器使用损失函数来最大化 MI 或最小化负 MI:
 (Equation 13.3.7)
(Equation 13.3.7)
在实现无监督聚类之前,让我们再次反思目标–最大化I(Z; Z_bar)。 由于X和X_bar = G(X)及其对应的潜在代码向量Z和Z_bar共享相同的信息,因此神经网络编码器E应该学习映射X和X_bar成为潜在向量Z和Z_bar,它们具有几乎相同的值以最大化其 MI。 在 MNIST 的背景下,看起来相似的数字将具有潜在代码向量,它们聚集在空间的同一区域中。
如果潜在代码向量是 softmax 的输出,则表明我们正在执行无监督聚类,可以使用线性分配算法将其转换为分类器。 在本章中,我们将介绍两种可能的线性分配算法,这些算法可用于将无监督的聚类转换为无监督的分类。
在下一节中,我们将讨论可用于实现无监督聚类的编码器网络模型。 特别是,我们将介绍可用于估计P(Z)和P(Z_bar)的编码器网络。
4. 用于无监督聚类的编码器网络
图 13.4.1 中显示了用于无监督聚类的编码器网络实现。 它是一种编码器,具有类似 VGG 的[2]主干和Dense层,并具有 softmax 输出。 最简单的 VGG-11 具有主干,如“图 13.4.2”所示。
对于 MNIST,使用最简单的 VGG-11 骨干将特征映射大小从MaxPooling2D操作的 5 倍减至零。 因此,当在 Keras 中实现时,将使用按比例缩小的 VGG-11 主干版本,如图“图 13.4.3”所示。 使用同一组过滤器。

图 13.4.1 IIC 编码器网络E的网络实现。 输入的 MNIST 图像被中心裁剪为24 x 24像素。 在此示例中,X_bar = G(X)是随机的24 x 24像素裁剪操作。

图 13.4.2 VGG-11 分类器主干
在“图 13.4.3”中,有 4 个Conv2D-BN-ReLU Activation-MaxPooling2D层,其过滤器大小为(64, 128, 256, 512)。 最后的Conv2D层不使用MaxPooling2D。 因此,最后的Conv2D层针对24 x 24 x 1裁剪的 MNIST 输入输出(3, 3, 512)特征映射。

图 13.4.3 缩小的 VGG 用作编码器主干
“图 13.4.4”显示了“图 13.4.1”的 Keras 模型图。 为了提高性能,IIC 执行了超集群。 两个或更多编码器用于生成两个或更多个边际分布P(Z)和P(Z_bar)。 生成相应的联合分布。 就网络模型的而言,这是由具有两个或更多头的编码器实现的。
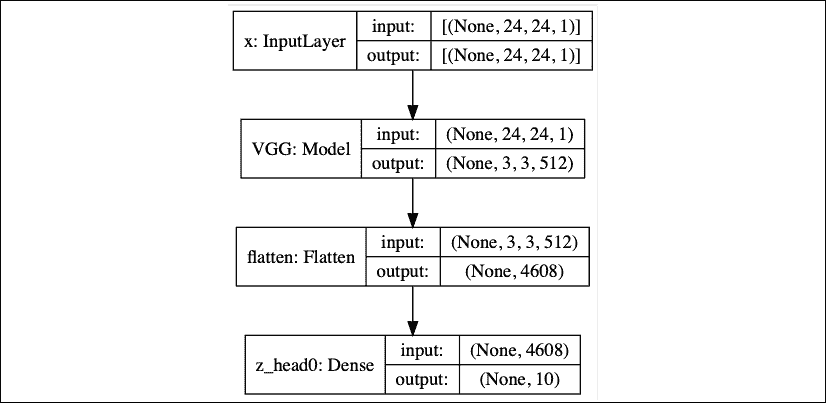
图 13.4.4 Keras 中 IIC 编码器E的网络实现
“图 13.4.4”是单头编码器,而“图 13.4.5”是双头编码器。 请注意,两个头共享相同的 VGG 主干。

图 13.4.5 Keras 中的两头编码器网络E
在以下两个部分的中,我们将研究[II]网络模型是如何实现,训练和评估的。 我们还将研究线性分配问题,作为为每个聚类指定标签的工具。
5. Keras 中的无监督聚类实现
Keras 中用于无监督聚类的网络模型实现在“列表 13.5.1”中显示。 仅显示初始化。 网络超参数存储在args中。 VGG 主干对象在初始化期间提供。 给定骨干,模型实际上只是具有 softmax 激活的Dense层,如build_model()方法所示。 有创建多个头的选项。
与“第 11 章”,“对象检测”相似,我们实现了DataGenerator类以多线程方式有效地提供输入数据。 DataGenerator对象生成由输入图像X及其变换后的图像X_bar组成的所需配对训练输入数据(即,连体输入图像)。 DataGenerator类中最关键的方法__data_generation()显示在“列表 13.5.2”中。 输入图像X从原始输入图像中央裁切。 对于 MNIST,这是24 x 24像素中心裁剪。 变换后的输入图像X_bar可以随机旋转±20范围内的某个角度,也可以从图像的任何部分随机裁剪16 x 16、18 x 18或20 x 20像素,然后将其调整为24 x 24像素。 作物尺寸存储在crop_sizes列表中。
注意,仅输入图像和变换图像在DataGenerator对象生成的数据中很重要。 同样,损失函数所需的配对数据沿批量轴连接。 这将使我们能够在单批配对数据中计算损失函数。
“列表 13.5.1”:iic-13.5.1.py。 显示初始化和模型创建的 IIC 类:IIC 类:
def __init__(self,
args,
backbone):
"""Contains the encoder model, the loss function,
loading of datasets, train and evaluation routines
to implement IIC unsupervised clustering via mutual
information maximization
Arguments:
args : Command line arguments to indicate choice
of batch size, number of heads, folder to save
weights file, weights file name, etc
backbone (Model): IIC Encoder backbone (eg VGG)
"""
self.args = args
self.backbone = backbone
self._model = None
self.train_gen = DataGenerator(args, siamese=True)
self.n_labels = self.train_gen.n_labels
self.build_model()
self.load_eval_dataset()
self.accuracy = 0
def build_model(self):
"""Build the n_heads of the IIC model
"""
inputs = Input(shape=self.train_gen.input_shape, name='x')
x = self.backbone(inputs)
x = Flatten()(x)
# number of output heads
outputs = []
for i in range(self.args.heads):
name = "z_head%d" % i
outputs.append(Dense(self.n_labels,
activation='softmax',
name=name)(x))
self._model = Model(inputs, outputs, name='encoder')
optimizer = Adam(lr=1e-3)
self._model.compile(optimizer=optimizer, loss=self.mi_loss)
“列表 13.5.2”:data_generator.py。 用于生成成对的输入数据以训练 IIC 编码器的DataGenerator类方法:
def __data_generation(self, start_index, end_index):
"""Data generation algorithm. The method generates
a batch of pair of images (original image X and
transformed imaged Xbar). The batch of Siamese
images is used to trained MI-based algorithms:
1) IIC and 2) MINE (Section 7)
Arguments:
start_index (int): Given an array of images,
this is the start index to retrieve a batch
end_index (int): Given an array of images,
this is the end index to retrieve a batch
"""
d = self.crop_size // 2
crop_sizes = [self.crop_size*2 + i for i in range(0,5,2)]
image_size = self.data.shape[1] - self.crop_size
x = self.data[self.indexes[start_index : end_index]]
y1 = self.label[self.indexes[start_index : end_index]]
target_shape = (x.shape[0], *self.input_shape)
x1 = np.zeros(target_shape)
if self.siamese:
y2 = y1
x2 = np.zeros(target_shape)
for i in range(x1.shape[0]):
image = x[i]
x1[i] = image[d: image_size + d, d: image_size + d]
if self.siamese:
rotate = np.random.randint(0, 2)
# 50-50% chance of crop or rotate
if rotate == 1:
shape = target_shape[1:]
x2[i] = self.random_rotate(image,
target_shape=shape)
else:
x2[i] = self.random_crop(image,
target_shape[1:],
crop_sizes)
# for IIC, we are mostly interested in paired images
# X and Xbar = G(X)
if self.siamese:
# If MINE Algorithm is chosen, use this to generate
# the training data (see Section 9)
if self.mine:
y = np.concatenate([y1, y2], axis=0)
m1 = np.copy(x1)
m2 = np.copy(x2)
np.random.shuffle(m2)
x1 = np.concatenate((x1, m1), axis=0)
x2 = np.concatenate((x2, m2), axis=0)
x = (x1, x2)
return x, y
x_train = np.concatenate([x1, x2], axis=0)
y_train = np.concatenate([y1, y2], axis=0)
y = []
for i in range(self.args.heads):
y.append(y_train)
return x_train, y
return x1, y1
为了实现 VGG 骨干,在 Keras 中实现了VGG类,如“列表 13.5.3”所示。 VGG类的灵活性在于可以用不同的方式(或 VGG 的不同样式)进行配置。 显示了用于 IIC VGG 主干配置cfg的选项'F'。 我们使用一个辅助函数来生成Conv2D-BN-ReLU-MaxPooling2D层。
“列表 13.5.3”:vgg.py。
Keras 中的VGG backbone类方法:
cfg = {
'F': [64, 'M', 128, 'M', 256, 'M', 512],
}
class VGG:
def __init__(self, cfg, input_shape=(24, 24, 1)):
"""VGG network model creator to be used as backbone
feature extractor
Arguments:
cfg (dict): Summarizes the network configuration
input_shape (list): Input image dims
"""
self.cfg = cfg
self.input_shape = input_shape
self._model = None
self.build_model()
def build_model(self):
"""Model builder uses a helper function
make_layers to read the config dict and
create a VGG network model
"""
inputs = Input(shape=self.input_shape, name='x')
x = VGG.make_layers(self.cfg, inputs)
self._model = Model(inputs, x, name='VGG')
@property
def model(self):
return self._model
@staticmethod
def make_layers(cfg,
inputs,
batch_norm=True,
in_channels=1):
"""Helper function to ease the creation of VGG
network model
Arguments:
cfg (dict): Summarizes the network layer
configuration
inputs (tensor): Input from previous layer
batch_norm (Bool): Whether to use batch norm
between Conv2D and ReLU
in_channel (int): Number of input channels
"""
x = inputs
for layer in cfg:
if layer == 'M':
x = MaxPooling2D()(x)
elif layer == 'A':
x = AveragePooling2D(pool_size=3)(x)
else:
x = Conv2D(layer,
kernel_size=3,
padding='same',
kernel_initializer='he_normal'
)(x)
if batch_norm:
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x
回到IIC类,IIC的关键算法是使负 MI 最小的损失函数。 此方法显示在“列表 13.5.4”中。 为了评估单个批量中的损失,我们研究了y_pred,并将其分为上下两半,分别对应于输入图像X及其变换后的图像X_bar的编码器输出的。 回想一下,配对数据是通过将一批图像X和一批其变换后的图像X_bar连接在一起而制成的。
y_pred的下半部分为Z,而上半部分为Z_bar遵循“公式 10.3.2”至“公式 10.3.7”,联合分布P(Z, Z_bar)和边际分布被计算。 最后,返回负数 MI。 注意,每个头对总损失函数的贡献均等。 因此,损失是根据头部的数量来缩放的。
“列表 13.5.4”:iic-13.5.1.py。
Keras 中的IIC类损失函数。 损失函数使负 MI 最小化(即,使 MI 最大化):
def mi_loss(self, y_true, y_pred):
"""Mutual information loss computed from the joint
distribution matrix and the marginals
Arguments:
y_true (tensor): Not used since this is
unsupervised learning
y_pred (tensor): stack of softmax predictions for
the Siamese latent vectors (Z and Zbar)
"""
size = self.args.batch_size
n_labels = y_pred.shape[-1]
# lower half is Z
Z = y_pred[0: size, :]
Z = K.expand_dims(Z, axis=2)
# upper half is Zbar
Zbar = y_pred[size: y_pred.shape[0], :]
Zbar = K.expand_dims(Zbar, axis=1)
# compute joint distribution (Eq 10.3.2 & .3)
P = K.batch_dot(Z, Zbar)
P = K.sum(P, axis=0)
# enforce symmetric joint distribution (Eq 10.3.4)
P = (P + K.transpose(P)) / 2.0
# normalization of total probability to 1.0
P = P / K.sum(P)
# marginal distributions (Eq 10.3.5 & .6)
Pi = K.expand_dims(K.sum(P, axis=1), axis=1)
Pj = K.expand_dims(K.sum(P, axis=0), axis=0)
Pi = K.repeat_elements(Pi, rep=n_labels, axis=1)
Pj = K.repeat_elements(Pj, rep=n_labels, axis=0)
P = K.clip(P, K.epsilon(), np.finfo(float).max)
Pi = K.clip(Pi, K.epsilon(), np.finfo(float).max)
Pj = K.clip(Pj, K.epsilon(), np.finfo(float).max)
# negative MI loss (Eq 10.3.7)
neg_mi = K.sum((P * (K.log(Pi) + K.log(Pj) - K.log(P))))
# each head contribute 1/n_heads to the total loss
return neg_mi/self.args.heads
IIC 网络训练方法显示在“列表 13.5.5”中。 由于我们使用的是从Sequence类派生的DataGenerator对象,因此可以使用 Keras fit_generator()方法来训练模型。
我们使用学习率调度器,每 400 个周期将学习率降低 80%。 AccuracyCallback调用eval()方法,因此我们可以在每个周期之后记录网络的表现。
可以选择保存表现最佳的模型的权重。 在eval()方法中,我们使用线性分类器为每个聚类分配标签。 线性分类器unsupervised_labels()是一种匈牙利算法,它以最小的成本将标签分配给群集。
最后一步将无监督的聚类转换为无监督的分类。 unsupervised_labels()函数在“列表 13.5.6”中显示。
“列表 13.5.5”:iic-13.5.1.py。
IIC 网络训练和评估:
def train(self):
"""Train function uses the data generator,
accuracy computation, and learning rate
scheduler callbacks
"""
accuracy = AccuracyCallback(self)
lr_scheduler = LearningRateScheduler(lr_schedule,
verbose=1)
callbacks = [accuracy, lr_scheduler]
self._model.fit_generator(generator=self.train_gen,
use_multiprocessing=True,
epochs=self.args.epochs,
callbacks=callbacks,
workers=4,
shuffle=True)
def eval(self):
"""Evaluate the accuracy of the current model weights
"""
y_pred = self._model.predict(self.x_test)
print("")
# accuracy per head
for head in range(self.args.heads):
if self.args.heads == 1:
y_head = y_pred
else:
y_head = y_pred[head]
y_head = np.argmax(y_head, axis=1)
accuracy = unsupervised_labels(list(self.y_test),
list(y_head),
self.n_labels,
self.n_labels)
info = "Head %d accuracy: %0.2f%%"
if self.accuracy > 0:
info += ", Old best accuracy: %0.2f%%"
data = (head, accuracy, self.accuracy)
else:
data = (head, accuracy)
print(info % data)
# if accuracy improves during training,
# save the model weights on a file
if accuracy > self.accuracy \
and self.args.save_weights is not None:
self.accuracy = accuracy
folder = self.args.save_dir
os.makedirs(folder, exist_ok=True)
path = os.path.join(folder, self.args.save_weights)
print("Saving weights... ", path)
self._model.save_weights(path)
“列表 13.5.6”:utils.py。
匈牙利语算法将标签分配给具有最低成本的集群:
from scipy.optimize import linear_sum_assignment
def unsupervised_labels(y, yp, n_classes, n_clusters):
"""Linear assignment algorithm
Arguments:
y (tensor): Ground truth labels
yp (tensor): Predicted clusters
n_classes (int): Number of classes
n_clusters (int): Number of clusters
"""
assert n_classes == n_clusters
# initialize count matrix
C = np.zeros([n_clusters, n_classes])
# populate count matrix
for i in range(len(y)):
C[int(yp[i]), int(y[i])] += 1
# optimal permutation using Hungarian Algo
# the higher the count, the lower the cost
# so we use -C for linear assignment
row, col = linear_sum_assignment(-C)
# compute accuracy
accuracy = C[row, col].sum() / C.sum()
return accuracy * 100
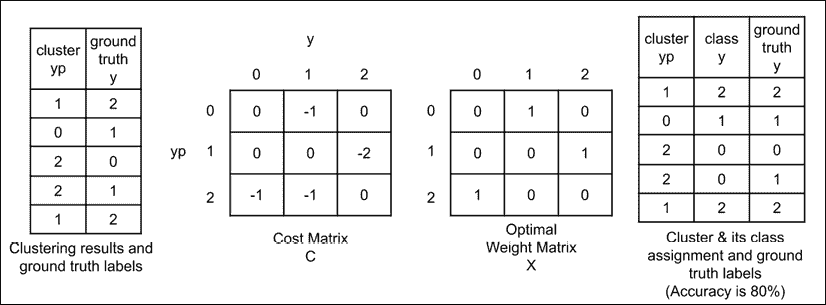
图 13.5.1 在三个群集的简单场景中说明的线性分配算法,可以将其最佳地分配给三个类别
如图“图 13.5.1”所示,线性分配问题最好使用将三个群集分配给三个类别的简化方案来解释。 线性分配问题找到了类对类的一对一分配,从而使总成本最小。 在“图 13.5.1*”的左侧,显示了聚类结果和真实情况标签。
线性分配问题可以找到每个群集的类或类别,或者如何为每个群集分配标签。 还显示了成本矩阵C。 对于每个聚类-真实情况对,成本矩阵像元递减 1。该像元的行-列索引是聚类编号-真实情况标签索引。 使用成本矩阵,线性分配问题的工作是找到导致总成本最小的最优矩阵X:
 (Equation 13.5.1)
(Equation 13.5.1)
其中c[ij]和x[ij]分别是矩阵C和X的元素 。i和j是索引。X的元素受的以下约束:
x[ij] ∈ {0, 1}
Σ[j] x[ij] = 1对于i = 1, 2, ..., N
Σ[i] x[ij] = 1对于j = 1, 2, ..., N
X是一个二进制矩阵。 每行仅分配给一列。 因此,线性分配问题是组合问题。 最佳解决方案的详细信息超出了本书的范围,此处不再讨论。
最佳权重矩阵X显示在“图 13.5.1”中。 群集 0 被分配了标签 1。群集 1 被分配了标签 2。群集 2 被分配了标签 0。这可以从成本矩阵中直观地进行验证,因为这导致最低成本为 -4,同时确保每行仅分配给一列。
使用此矩阵,群集类的分配显示在最右边的表中。 使用群集类分配时,第四行上只有一个错误。 结果精度为五分之四,即 80%。
我们可以将的线性分配问题扩展到为 10 个 MNIST 集群分配标签的问题。 我们在scipy包中使用linear_sum_assignment()函数。 该函数基于匈牙利算法。“列表 13.5.6”显示了群集标记过程的实现。 有关linear_sum_assignment()函数的更多详细信息,请参见这里。
要训练 1 头情况下的 IIC 模型,请执行:
python3 iic-13.5.1.py --heads=1 --train --save-weights=head1.h5
对于其他数量的打印头,应相应地修改选项--heads和--save-weights。 在下一部分中,我们将检查 IIC 作为 MNIST 分类器的表现。
6. 将 MNIST 用于验证
在本节中,我们将研究使用 MNIST 测试数据集对 IIC 进行验证之后的结果。 在测试数据集上运行聚类预测后,线性分配问题为每个聚类分配标签,从本质上将聚类转换为分类。 我们计算了分类精度,如“表 13.6.1”所示。 IIC 的准确率高于论文中报告的 99.3%。 但是,应该注意的是,并非每次训练都会导致高精度分类。
有时,由于优化似乎停留在局部最小值中,我们不得不多次运行训练。 此外,在多头 IIC 模型中,对于所有头部,我们都无法获得相同水平的表现。“表 13.6.1”报告了最佳表现的头部。
| 头部数 | 1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|
| 精度,% | 99.49 | 99.47 | 99.54 | 99.52 | 99.53 |
表 13.6.1 不同头数的 IIC 精度
权重在 GitHub 上可用。 例如,要在单头 IIC 上运行验证:
python3 iic-13.5.1.py --heads=1 --eval --restore-weights=head1-best.h5
总之,我们可以看到可以执行无监督分类。 结果实际上比我们在“第 2 章”,“深度神经网络”中检查的监督分类更好。 在以下各节中,我们将把注意力转向对连续随机变量的无监督学习。
7. 通过最大化连续随机变量的互信息进行无监督学习
在前面的章节中,我们了解到可以很好地估计离散随机变量的 MI。 我们还证明了借助线性分配算法,通过最大化 MI 来执行聚类的网络可以得出准确的分类器。
如果 IIC 是离散随机变量 MI 的良好估计者,那么连续随机变量又如何呢? 在本节的中,我们讨论 Belghazi 等人的互信息网络估计器(MINE)。 [3]作为连续随机变量 MI 的估计量。
MINE 在“公式 13.1.1”中提出了 KL 散度的另一种表示形式,以使用神经网络实现 MI 估计器。 在 MINE 中,使用 KL 散度的 Donsker-Varadhan(DV)表示:
 (Equation 13.7.1)
(Equation 13.7.1)
在函数T的整个空间中占据最高位的位置。T是从输入空间(例如图像)映射到实数的任意函数。 回想一下,最高被粗略地解释为最大值。 对于T,我们可以从θ ∈ Θ参数化的函数T[θ] = X x Y -> R系列中进行选择。 因此,我们可以用估计 KL 散度的深度神经网络表示T[θ],因此代表T。
给定作为 MI 的精确(但难处理)表示I(X; Y)及其参数化的估计值I[θ](X; Y)作为易于处理的下限,我们可以安全地说:
 (Equation 13.7.2)
(Equation 13.7.2)
其中参数化的 MI 估计为:
 (Equation 13.7.3)
(Equation 13.7.3)
I[θ](X; Y)也称为神经信息测度。 在第一个期望中,样本(x, y) ~ P(X, Y)从联合分布P(X,Y)中获取。 在第二个期望中,样本x ~ P(X), y ~ P(Y)来自边际分布P(X)和P(Y)。
“算法 13.7.1”:MINE。
初始化所有网络参数θ。
θ尚未收敛时,请执行:
-
从联合分布
{(x^(1), y^(1)), (x^(2), y^(2)), ..., (x^(b), y^(b))} ~ P(X, Y)中抽取一个小批量的b -
从边际分布
{x^(1), x^(2), ..., x^(b)} ~ P(X)和{y^(1), y^(2), ..., y^(b)} ~ P(Y)中抽取一个小批量的b。 -
评估下界:

-
评估偏差校正后的梯度:

-
更新网络参数:

其中
ε是学习率。
“算法 13.7.1”总结了 MINE 算法。 来自边际分布的样本是来自联合分布的样本,另一个变量已删除。 例如,样本x只是简单的样本(x, y),变量y被丢弃。 在降为变量y的值之后,将x的样本进行混洗。 对y执行相同的采样方法。 为了清楚起见,我们使用符号x_bar和y_bar从边际分布中识别样本。
在下一部分中,在双变量高斯分布的情况下,我们将使用 MINE 算法估计 MI。 我们将展示使用解析方法估计的 MI 和使用 MINE 估计 MI 的方法。
8. 估计二元高斯的互信息
在本节中,我们将验证 MINE 的二元高斯分布。“图 13.8.1”显示具有均值和协方差的双变量高斯分布:
 (Equation 13.8.1)
(Equation 13.8.1)
 (Equation 13.8.2)
(Equation 13.8.2)
图 13.8.1 具有均值和协方差的二维高斯分布,如公式 13.8.1 和公式 13.8.2 所示
我们的目标是通过近似“公式 13.1.3”来估计 MI。 可以通过获得大量样本(例如 1 百万个)并创建具有大量箱子(例如 100 个箱子)的直方图来进行近似。“列表 13.8.1”显示了使用装仓对二元高斯分布的 MI 进行的手动计算。
“列表 13.8.1”:mine-13.8.1.py:
def sample(joint=True,
mean=[0, 0],
cov=[[1, 0.5], [0.5, 1]],
n_data=1000000):
"""Helper function to obtain samples
fr a bivariate Gaussian distribution
Arguments:
joint (Bool): If joint distribution is desired
mean (list): The mean values of the 2D Gaussian
cov (list): The covariance matrix of the 2D Gaussian
n_data (int): Number of samples fr 2D Gaussian
"""
xy = np.random.multivariate_normal(mean=mean,
cov=cov,
size=n_data)
# samples fr joint distribution
if joint:
return xy
y = np.random.multivariate_normal(mean=mean,
cov=cov,
size=n_data)
# samples fr marginal distribution
x = xy[:,0].reshape(-1,1)
y = y[:,1].reshape(-1,1)
xy = np.concatenate([x, y], axis=1)
return xy
def compute_mi(cov_xy=0.5, n_bins=100):
"""Analytic computation of MI using binned
2D Gaussian
Arguments:
cov_xy (list): Off-diagonal elements of covariance
matrix
n_bins (int): Number of bins to "quantize" the
continuous 2D Gaussian
"""
cov=[[1, cov_xy], [cov_xy, 1]]
data = sample(cov=cov)
# get joint distribution samples
# perform histogram binning
joint, edge = np.histogramdd(data, bins=n_bins)
joint /= joint.sum()
eps = np.finfo(float).eps
joint[joint<eps] = eps
# compute marginal distributions
x, y = margins(joint)
xy = x*y
xy[xy<eps] = eps
# MI is P(X,Y)*log(P(X,Y)/P(X)*P(Y))
mi = joint*np.log(joint/xy)
mi = mi.sum()
return mi
运行的结果:
python3 mine-13.8.1.py --gaussian
表示手动计算的 MI:
Computed MI: 0.145158
可以使用--cov_xy选项更改协方差。 例如:
python3 mine-13.8.1.py --gaussian --cov_xy=0.8
表示手动计算的 MI:
Computed MI: 0.510342
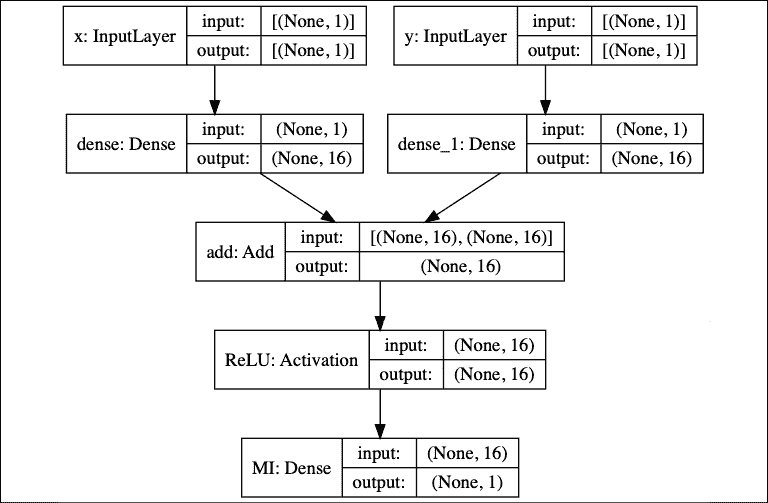
图 13.8.2 一个简单的 MINE 模型,用于估计双变量高斯分布的随机变量X和Y的 MI
“列表 13.8.2”:mine-13.8.1.py。
一个简单的 MINE 模型,用于估计双变量高斯分布的随机变量的 MI:
class SimpleMINE:
def __init__(self,
args,
input_dim=1,
hidden_units=16,
output_dim=1):
"""Learn to compute MI using MINE (Algorithm 13.7.1)
Arguments:
args : User-defined arguments such as off-diagonal
elements of covariance matrix, batch size,
epochs, etc
input_dim (int): Input size dimension
hidden_units (int): Number of hidden units of the
MINE MLP network
output_dim (int): Output size dimension
"""
self.args = args
self._model = None
self.build_model(input_dim,
hidden_units,
output_dim)
def build_model(self,
input_dim,
hidden_units,
output_dim):
"""Build a simple MINE model
Arguments:
See class arguments.
"""
inputs1 = Input(shape=(input_dim), name="x")
inputs2 = Input(shape=(input_dim), name="y")
x1 = Dense(hidden_units)(inputs1)
x2 = Dense(hidden_units)(inputs2)
x = Add()([x1, x2])
x = Activation('relu', name="ReLU")(x)
outputs = Dense(output_dim, name="MI")(x)
inputs = [inputs1, inputs2]
self._model = Model(inputs,
outputs,
name='MINE')
self._model.summary()
def mi_loss(self, y_true, y_pred):
""" MINE loss function
Arguments:
y_true (tensor): Not used since this is
unsupervised learning
y_pred (tensor): stack of predictions for
joint T(x,y) and marginal T(x,y)
"""
size = self.args.batch_size
# lower half is pred for joint dist
pred_xy = y_pred[0: size, :]
# upper half is pred for marginal dist
pred_x_y = y_pred[size : y_pred.shape[0], :]
# implentation of MINE loss (Eq 13.7.3)
loss = K.mean(pred_xy) \
- K.log(K.mean(K.exp(pred_x_y)))
return -loss
def train(self):
"""Train MINE to estimate MI between
X and Y of a 2D Gaussian
"""
optimizer = Adam(lr=0.01)
self._model.compile(optimizer=optimizer,
loss=self.mi_loss)
plot_loss = []
cov=[[1, self.args.cov_xy], [self.args.cov_xy, 1]]
loss = 0.
for epoch in range(self.args.epochs):
# joint dist samples
xy = sample(n_data=self.args.batch_size,
cov=cov)
x1 = xy[:,0].reshape(-1,1)
y1 = xy[:,1].reshape(-1,1)
# marginal dist samples
xy = sample(joint=False,
n_data=self.args.batch_size,
cov=cov)
x2 = xy[:,0].reshape(-1,1)
y2 = xy[:,1].reshape(-1,1)
# train on batch of joint & marginal samples
x = np.concatenate((x1, x2))
y = np.concatenate((y1, y2))
loss_item = self._model.train_on_batch([x, y],
np.zeros(x.shape))
loss += loss_item
plot_loss.append(-loss_item)
if (epoch + 1) % 100 == 0:
fmt = "Epoch %d MINE MI: %0.6f"
print(fmt % ((epoch+1), -loss/100))
loss = 0.
现在,让我们使用 MINE 估计此双变量高斯分布的 MI。“图 13.8.2”显示了一个简单的 2 层 MLP 作为T[θ]的模型。 输入层从联合分布中接收一批(x,y),从边缘分布中接收一批(x_bar, y_bar)。 该网络在build_model()中的“列表 13.8.2”中实现。 在同一清单中还显示了此简单 MINE 模型的训练例程。
实现“公式 13.7.3”的损失函数也在“列表 13.8.2”中显示。 请注意,损失函数不使用基本真值。 它只是最小化了 MI 的负估计(从而使 MI 最大化)。 对于此简单的 MINE 模型,未实现移动平均损失。 我们使用“列表 13.8.1”中的相同函数sample()来获得联合和边际样本。
现在,我们可以使用同一命令来估计双变量高斯分布的 MI:
python3 mine-13.8.1.py --gaussian
“图 13.8.3”显示了 MI 估计(负损失)与历时数的关系。 以下是每隔 100 个特定周期的定量结果。手动和 MINE 计算的结果接近。 这证明了 MINE 是连续随机变量 MI 的良好估计。
Epoch 100 MINE MI: 0.112297
Epoch 200 MINE MI: 0.141723
Epoch 300 MINE MI: 0.142567
Epoch 400 MINE MI: 0.142087
Epoch 500 MINE MI: 0.142083
Epoch 600 MINE MI: 0.144755
Epoch 700 MINE MI: 0.141434
Epoch 800 MINE MI: 0.142480
Epoch 900 MINE MI: 0.143059
Epoch 1000 MINE MI: 0.142186
Computed MI: 0.147247
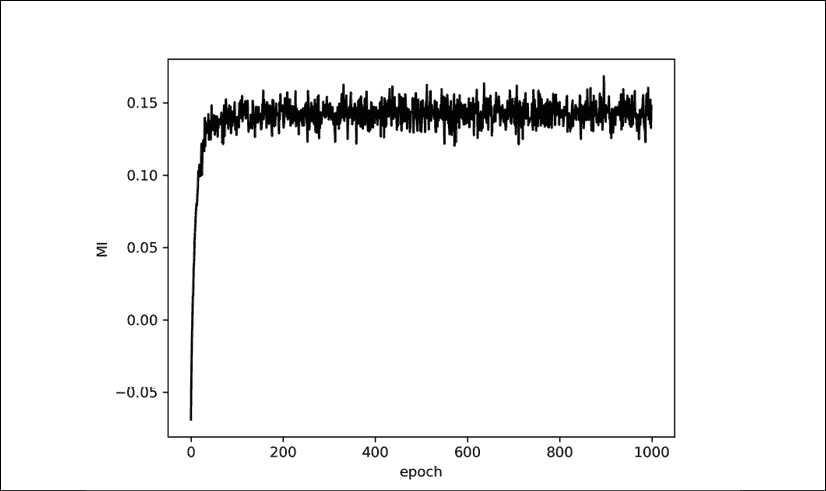
图 13.8.3 MI 估计作为简单 MINE 模型的函数周期。
到目前为止,我们已经针对二元高斯分布情况证明了 MINE。 在下一节中,我们将使用 MINE 来处理与 IIC 相同的 MNIST 无监督聚类问题。
9. Keras 中的使用连续随机变量的无监督聚类
在 MNIST 数字的无监督分类中,我们使用 IIC,因为可以使用离散的联合和边际分布来计算 MI 。 我们使用线性分配算法获得了良好的准确率。
在此部分中,我们将尝试使用 MINE 进行聚类。 我们将使用来自 IIC 的相同关键思想:从一对图像及其转换后的版本(X, X_bar)中,最大化对应的编码潜向量(Z, Z_bar)的 MI。 通过最大化 MI,我们对编码的潜在向量进行聚类。 与 MINE 的不同之处在于,编码后的潜在向量是连续的,而不是 IIC 中使用的单热向量格式。 由于聚类的输出不是单热向量格式,因此我们将使用线性分类器。 线性分类器是没有诸如ReLU之类的非线性激活层的 MLP。 如果输出不是单热点向量格式,则使用线性分类器替代线性分配算法。
“图 13.9.1”显示了 MINE 的网络模型。 对于 MNIST,从 MNIST 训练数据集中采样了x。 与 IIC 相似,称为变量y的其他输入只是图像x的变换后的版本。 在测试过程中,输入图像x来自 MNIST 测试数据集。 从本质上讲,数据生成与 IIC 中的相同,如“列表 13.5.2”中所示。
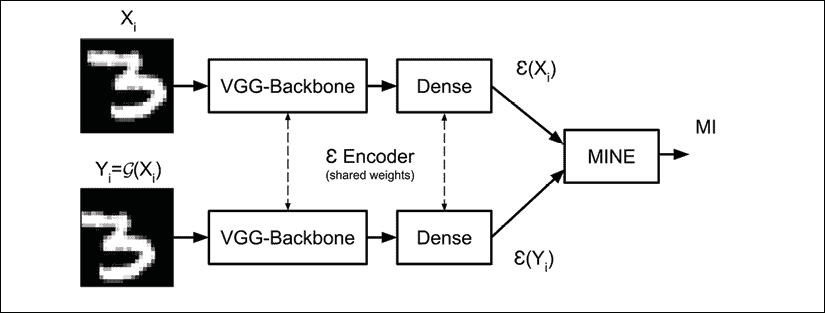
图 13.9.1 使用编码器网络E的 MINE 的网络实现。 输入的 MNIST 图像被中心裁剪为24 x 24像素。 在此示例中,X_bar = Y = G(X)是随机的24 x 24像素裁剪操作。
当在 Keras 中实现时,“图 13.9.1”的编码器网络显示在“图 13.9.2”中。 我们在 Dense 输出中省略了维数,以便我们可以尝试不同的维数(例如 10、16 和 32)。
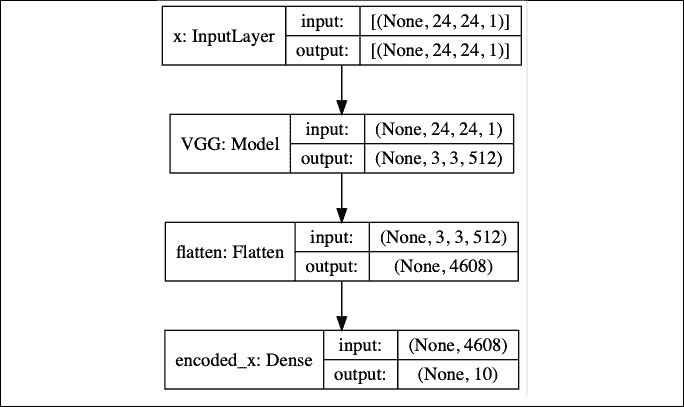
图 13.9.2 编码器网络E是 VGG 网络,类似于 IIC 中使用的网络
MINE 网络模型显示在“图 13.9.3”中,代码显示在“列表 13.9.1”中。 它在架构中与上一节中实现的简单 MINE 类似,不同之处在于,我们在 MLP 中使用了 1,024 个隐藏单元,而不是 16 个。
“列表 13.9.1”:mine-13.8.1.py。
MINE 网络模型用于无监督群集:
class MINE:
def __init__(self,
args,
backbone):
"""Contains the encoder, SimpleMINE, and linear
classifier models, the loss function,
loading of datasets, train and evaluation routines
to implement MINE unsupervised clustering via mutual
information maximization
Arguments:
args : Command line arguments to indicate choice
of batch size, folder to save
weights file, weights file name, etc
backbone (Model): MINE Encoder backbone (eg VGG)
"""
self.args = args
self.latent_dim = args.latent_dim
self.backbone = backbone
self._model = None
self._encoder = None
self.train_gen = DataGenerator(args,
siamese=True,
mine=True)
self.n_labels = self.train_gen.n_labels
self.build_model()
self.accuracy = 0
def build_model(self):
"""Build the MINE model unsupervised classifier
"""
inputs = Input(shape=self.train_gen.input_shape,
name="x")
x = self.backbone(inputs)
x = Flatten()(x)
y = Dense(self.latent_dim,
activation='linear',
name="encoded_x")(x)
# encoder is based on backbone (eg VGG)
# feature extractor
self._encoder = Model(inputs, y, name="encoder")
# the SimpleMINE in bivariate Gaussian is used
# as T(x,y) function in MINE (Algorithm 13.7.1)
self._mine = SimpleMINE(self.args,
input_dim=self.latent_dim,
hidden_units=1024,
output_dim=1)
inputs1 = Input(shape=self.train_gen.input_shape,
name="x")
inputs2 = Input(shape=self.train_gen.input_shape,
name="y")
x1 = self._encoder(inputs1)
x2 = self._encoder(inputs2)
outputs = self._mine.model([x1, x2])
# the model computes the MI between
# inputs1 and 2 (x and y)
self._model = Model([inputs1, inputs2],
outputs,
name='encoder')
optimizer = Adam(lr=1e-3)
self._model.compile(optimizer=optimizer,
loss=self.mi_loss)
self._model.summary()
self.load_eval_dataset()
self._classifier = LinearClassifier(\
latent_dim=self.latent_dim)

图 13.9.3 MINE 网络模型
如“列表 13.9.2”中所示,训练例程类似于 IIC 中的训练例程。 区别在于在每个周期之后执行的评估。 在这种情况下,我们针对个周期训练线性分类器,并将其用于评估聚类的潜在代码向量。 当精度提高时,可以选择保存模型权重。 损失函数和优化器与SimpleMINE中的类似,如“列表 13.8.2”中所示,此处不再赘述。
“列表 13.9.2”:mine-13.8.1.py。
矿山训练和评估职能:
def train(self):
"""Train MINE to estimate MI between
X and Y (eg MNIST image and its transformed
version)
"""
accuracy = AccuracyCallback(self)
lr_scheduler = LearningRateScheduler(lr_schedule,
verbose=1)
callbacks = [accuracy, lr_scheduler]
self._model.fit_generator(generator=self.train_gen,
use_multiprocessing=True,
epochs=self.args.epochs,
callbacks=callbacks,
workers=4,
shuffle=True)
def eval(self):
"""Evaluate the accuracy of the current model weights
"""
# generate clustering predictions fr test data
y_pred = self._encoder.predict(self.x_test)
# train a linear classifier
# input: clustered data
# output: ground truth labels
self._classifier.train(y_pred, self.y_test)
accuracy = self._classifier.eval(y_pred, self.y_test)
info = "Accuracy: %0.2f%%"
if self.accuracy > 0:
info += ", Old best accuracy: %0.2f%%"
data = (accuracy, self.accuracy)
else:
data = (accuracy)
print(info % data)
# if accuracy improves during training,
# save the model weights on a file
if accuracy > self.accuracy \
and self.args.save_weights is not None:
folder = self.args.save_dir
os.makedirs(folder, exist_ok=True)
args = (self.latent_dim, self.args.save_weights)
filename = "%d-dim-%s" % args
path = os.path.join(folder, filename)
print("Saving weights... ", path)
self._model.save_weights(path)
if accuracy > self.accuracy:
self.accuracy = accuracy
图 13.9.4 线性分类器模型
线性分类器模型显示在“图 19.3.4”中。 它是一个具有 256 个单元的隐藏层的 MLP。 由于此模型不使用诸如ReLU之类的非线性激活,因此可以将其用作线性分配算法的近似值,以对 VGG-Dense 编码器E的输出进行分类。“列表 13.9.3”显示了在 Keras 中实现的线性分类器网络模型构建器。
“列表 13.9.3”:mine-13.8.1.py。
线性分类器网络:
class LinearClassifier:
def __init__(self,
latent_dim=10,
n_classes=10):
"""A simple MLP-based linear classifier.
A linear classifier is an MLP network
without non-linear activations like ReLU.
This can be used as a substitute to linear
assignment algorithm.
Arguments:
latent_dim (int): Latent vector dimensionality
n_classes (int): Number of classes the latent
dim will be converted to.
"""
self.build_model(latent_dim, n_classes)
def build_model(self, latent_dim, n_classes):
"""Linear classifier model builder.
Arguments: (see class arguments)
"""
inputs = Input(shape=(latent_dim,), name="cluster")
x = Dense(256)(inputs)
outputs = Dense(n_classes,
activation='softmax',
name="class")(x)
name = "classifier"
self._model = Model(inputs, outputs, name=name)
self._model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
self._model.summary()
可以通过执行以下命令来训练 MINE 非监督分类器:
python3 mine-13.8.1.py --train --batch-size=1024 --epochs=200
可以根据可用的 GPU 内存来调整批量的大小。 要使用其他潜在尺寸大小(例如 64),请使用--latent-dim选项:
python3 mine-13.8.1.py --train --batch-size=1024 --latent-dim=64 --epochs=200
在 200 个周期内,MINE 网络具有“图 13.9.5”中所示的精度:
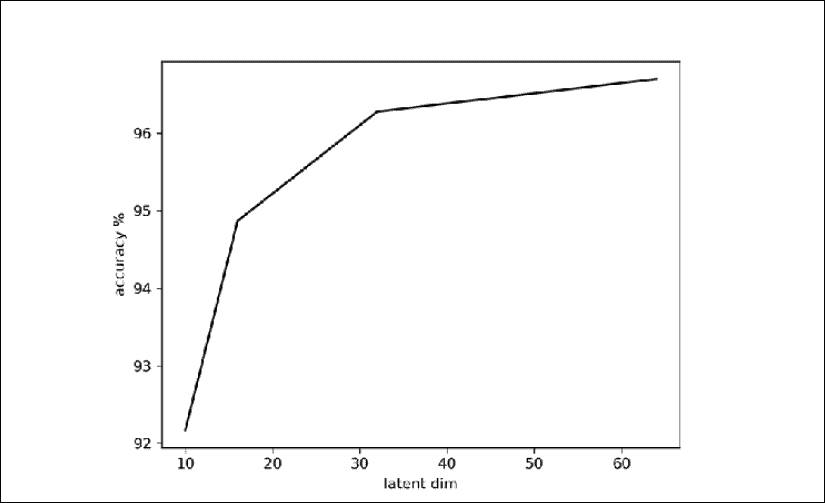
图 13.9.5 MNIST 分类中的 MINE 准确率
如图“图 13.9.5”所示,在默认潜伏昏暗 10 时,类似于 IIC,使用线性分类器的 MINE 可以达到 93.86% 的精度。 精度随潜在尺寸的值而增加。 由于 MINE 是真实 MI 的近似值,因此预计其精度会低于 IIC。
到此结束本章和书。 无监督学习的领域是新生的。 鉴于人工智能发展的当前障碍之一是人工标签,这是一个巨大的研究机会,这既昂贵又费时。 我们预计在未来几年中,无监督学习将取得突破。
10. 总结
在本章中,我们讨论了 MI 及其在解决无监督任务中有用的方式。 各种在线资源提供了有关 MI 的其他背景信息[4]。 当用于聚类时,最大化 MI 会强制使用线性分配或线性分类器将潜在代码向量聚类在适合轻松标记的区域中。
我们介绍了 MI 的两种度量:IIC 和 MINE。 我们可以通过对离散随机变量使用 IIC 来近似逼近 MI,从而导致分类器以较高的精度执行。 IIC 适用于离散概率分布。 对于连续随机变量,MINE 使用 KL 散度的 Donsker-Varadhan 形式对估计 MI 的深度神经网络进行建模。 我们证明了 MINE 可以近似逼近双变量高斯分布的 MI。 作为一种无监督的方法,MINE 在对 MNIST 数字进行分类时显示出可接受的表现。
11. 参考
Ji, Xu, João F. Henriques, and Andrea Vedaldi. Invariant Information Clustering for Unsupervised Image Classification and Segmentation. International Conference on Computer Vision, 2019.Simonyan, Karen, and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).Belghazi, Mohamed Ishmael, et al. Mutual Information Neural Estimation. International Conference on Machine Learning. 2018.https://en.wikipedia.org/wiki/Mutual_information.